Research Guide for Video Frame Interpolation with Deep Learning
Research Guide for Video Frame Interpolation with Deep Learning
This blog is from: https://heartbeat.fritz.ai/research-guide-for-video-frame-interpolation-with-deep-learning-519ab2eb3dda
In this research guide, we’ll look at deep learning papers aimed at synthesizing video frames within an existing video. This could be in between video frames, known as interpolation, or after them, known as extrapolation.
The better part of this guide will cover interpolation. Interpolation is useful in software editing tools as well as in generating video animations. It can also be used to generate clear video frames in sections where a video is blurred.
Video frame interpolation is a very common task, especially in film and video production. Optical flow is one of the common tactics used in solving this problem. Optical Flow Estimation is the process of estimating the motion of each pixel in a sequence of frames. In this paper, we’ll look at advanced methods of video frame interpolation using deep learning techniques.
Video Frame Interpolation via Adaptive Separable Convolution (ICCV, 2017)
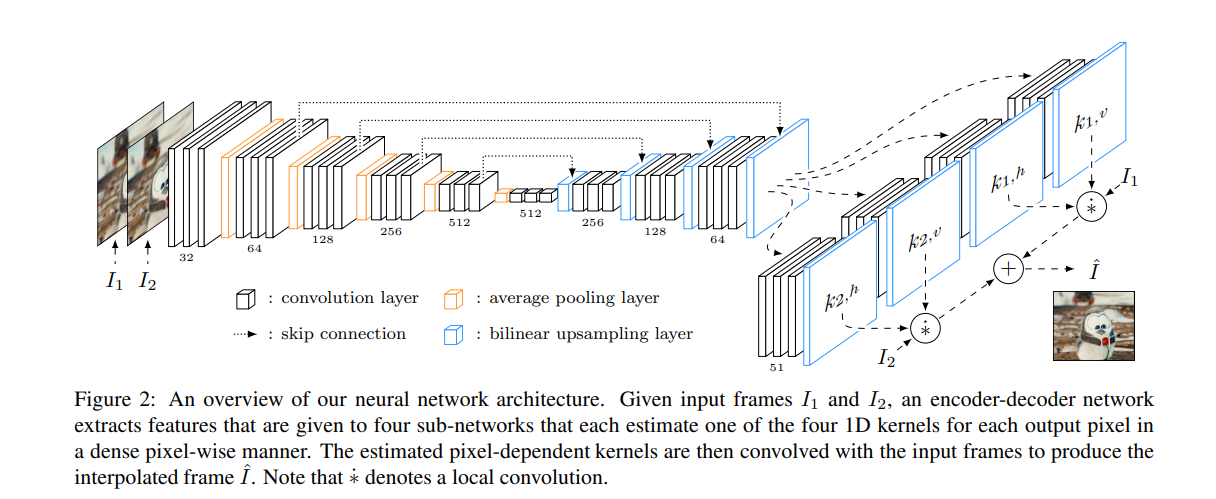
In this paper, the authors propose a deep fully convolutional neural network that’s fed with two input frames and estimates pairs of 1D kernels for all pixels. The method is capable of estimating kernels and synthesizing the entire video frame at once. This makes it possible to incorporate perceptual loss to train the neural network, in order to produce visually appealing frames.
The paper introduces a spatially-adaptive separable convolution technique, which aims to interpolate a new frame in the middle of two video frames. The convolution-based interpolation method then estimates a pair of 2D convolution kernels. This is then used to convolve the two video frames in order to compute the color of the output pixel.
The pixel-dependent kernels capture both motion and re-sampling information that’s required for interpolation. Four sets of 1D kernels are estimated by directing the information flow into four sub-networks. Each of the subnetworks estimates one kernel. The Rectified Linear Unit is used with the 3x3 convolutional layers.

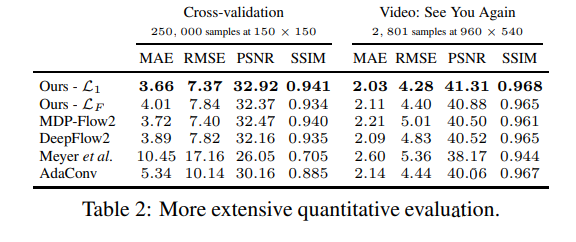
The network was trained using the AdaMax optimizer with a learning rate of 0.001 and a mini-batch size of 16 samples. Training videos were obtained from various YouTube channels such as “Tom Scott”, “Casey Neistat”, “Linus Tech Tips”, and “Austin Evans”.
Data augmentation was performed by random cropping to ensure that the network isn’t biased. Implementation of the convolutional neural network was done using Torch. Here’s how this model performs in comparison to other models.

Video Frame Interpolation via Adaptive Convolution (CVPR 2017)
This paper presents a method that combines motion estimation and pixel synthesis into a single process for video frame interpolation. A deep fully convolutional neural network is implemented to estimate a spatially-adaptive convolution kernel for each pixel.
For a pixel in the interpolated frame, the deep neural network takes two receptive field patches centered at that pixel as input and estimates the convolution kernel. The convolution kernel is used to convolve with the input patches to synthesize the output pixel. Given two video frames, this model aims at creating a temporarily frame in between them.
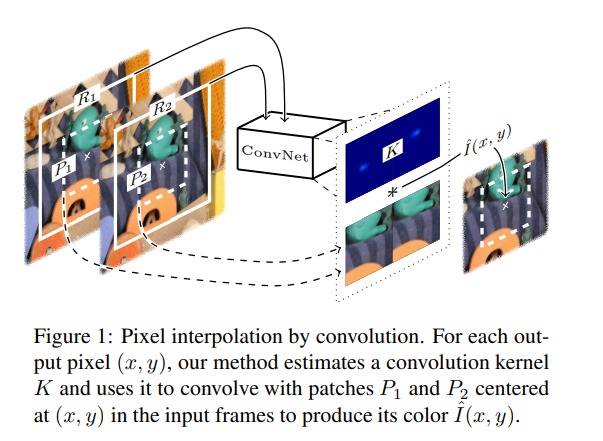
This method estimates a convolution kernel directly and uses that to convolve the two frames to interpolate the pixel color. Pixel synthesis is accomplished by the convolution kernel capturing motion and re-sampling coefficients. Pixel interpolation as convolution enables pixel synthesis to be done in a single step, which makes this approach more robust.

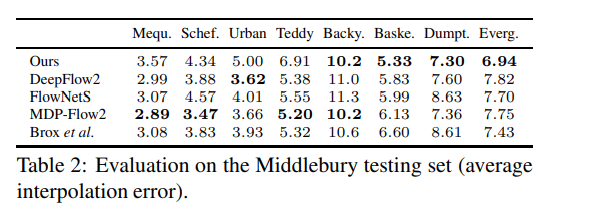
The convolutional neural network is made up of several convolutional layers and down convolutions as alternatives to max-pooling layers. For regularization, the authors use ReLUs as activations and batch normalization. The table below is an illustration of the architecture of this network.

The model is implemented using Torch. Here’s the performance of the model:
Video processing techniques like interpolation make many computer vision applications possible — not just on servers and in the cloud, but on mobile devices, too. Learn more about how Fritz can teach your mobile devices to see.
Video Frame Synthesis using Deep Voxel Flow (ICCV 2017)
The authors of this paper propose a deep neural network that learns to synthesize video frames by flowing pixel values from existing ones. This paper combines the strengths of generative convolutional neural networks and optical flow to solve this problem.
The network used in this model is trained in an unsupervised fashion. Pixels are generated by interpolating pixel values from frames that are close by. This network includes a voxel flow layer across space and time in the input video. Trilinear interpolation across the input video volume generates the final pixel. The network is trained on the UCF-101 dataset and tested on various videos.
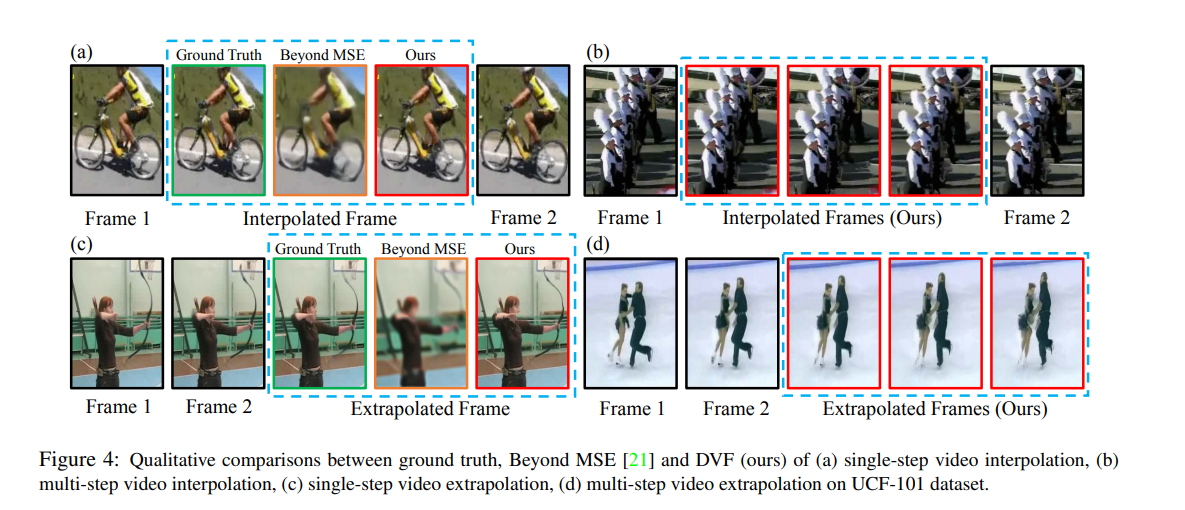
Their proposed model, Deep Voxel Flow (DVF), is an end-to-end, fully differentiable network for video frame synthesis. DVF adopts a fully-convolutional encoder-decoder architecture, containing three convolution layers, three deconvolution layers, and one bottleneck layer. In the training process of this model, two frames are provided as input and the remaining frame is used as a reconstruction target. The method is self-supervised and learns to reconstruct a frame by borrowing voxels from frames that are nearby. This leads to results that are sharper and more realistic.
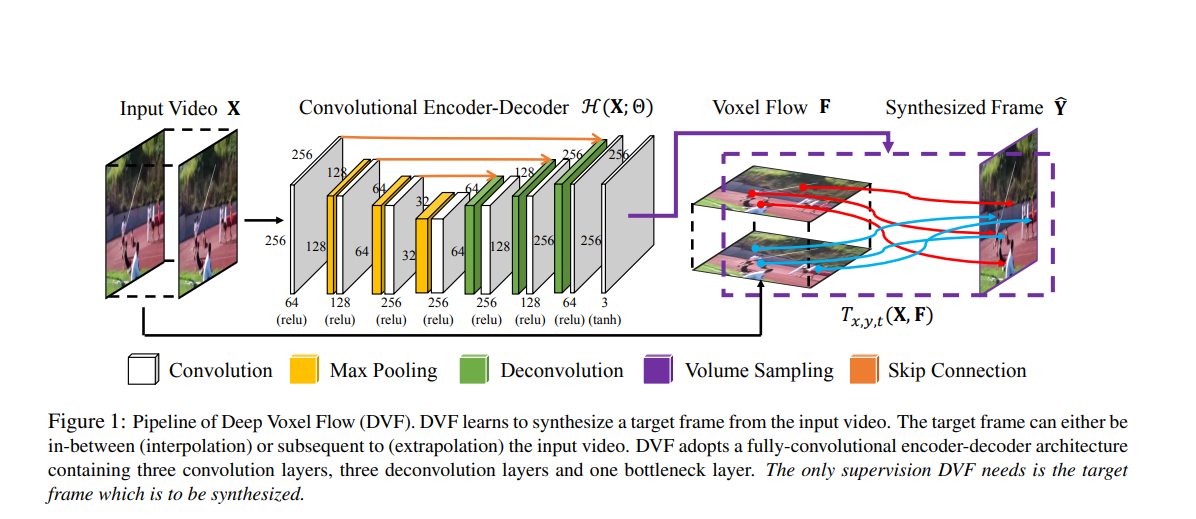
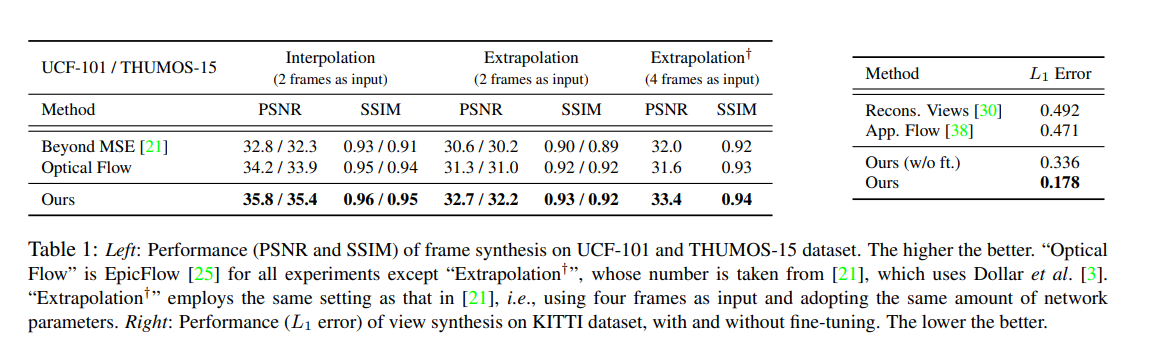
The authors use Peak Signal to Noise Ratio (PSN) and Structural Similarity Index (SSIM) for analyzing the quality of the interpolated image. Below are the results they achieved.
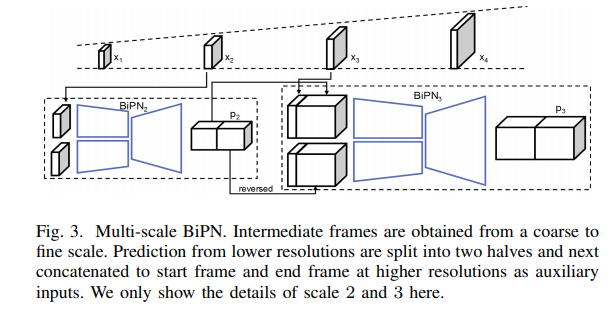
Long-Term Video Interpolation with Bidirectional Predictive Network (2017)
This paper addresses the challenge of generating multiple frames between two non-consecutive frames in videos. The authors present a deep bidirectional predictive network (BiPN) that predicts intermediate frames from two opposite directions.
The authors train a convolutional encoder-decoder network given two nonconsecutive frames. The network is trained to regress the missing intermediate frames from two opposite directions. The network consists of a bi-directional encoder-decoder that predicts the future-forward from the start frame and predicts the past-backward from the end frame all at the same time.
The model is evaluated on a synthetic dataset Moving 2D Shapes and a natural video dataset UCF101.

The BiPN architecture is an encoder-decoder pipeline with a bidirectional encoder and a single decoder. A latent frame representation is produced by the bidirectional encoder through encoding information from the start frame and end frame.
The multiple missing frames are predicted by the decoder after taking the feature representations as input. The forward and reverse encoders consist of several convolutional layers, each with a rectified linear unit (ReLU).
The decoder is composed of a series of up-convolutional layers and ReLUs. The decoder outputs a feature map with the size of l ×h×w ×c as the prediction of the target in-between frames, where l is the length of frames to be predicted, h, w and c are the height, width and the number of channels for each frame, respectively.
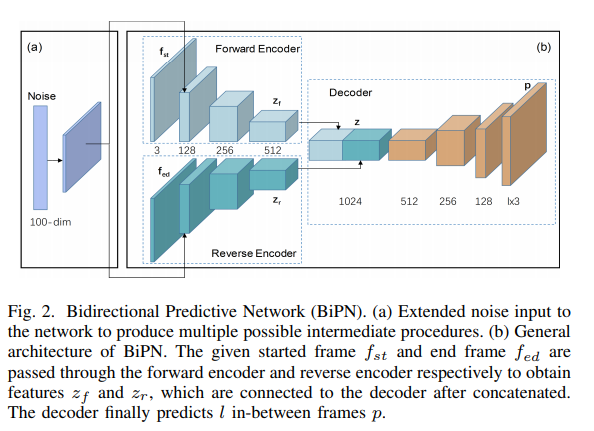
The model is implemented using TensorFlow and deployed on the Tesla K80 GPU. The model has been tested using the UCF101 dataset for natural high-resolution videos.

The authors use Peak Signal to Noise Ratio (PSN) and Structural Similarity Index (SSIM) for analyzing the quality of the interpolated frames. Below are the results they achieved.
![]()
PhaseNet for Video Frame Interpolation (CVPR 2018)
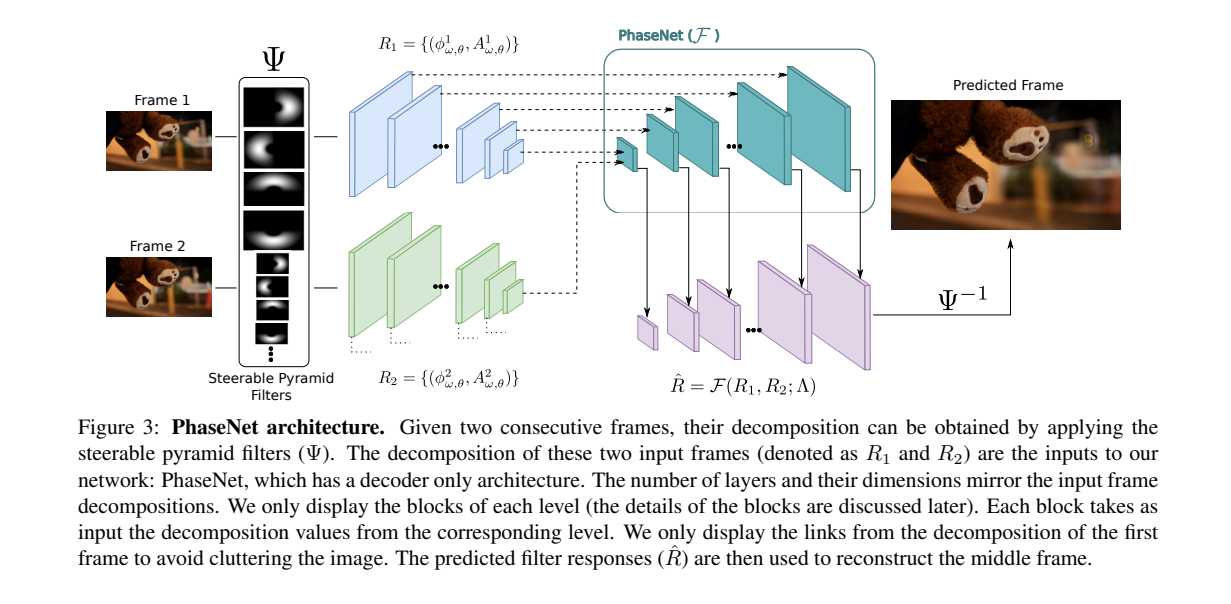
PhaseNet consists of a neural network decoder that estimates the phase decomposition of the intermediate frame. The architecture is a neural network that combines the phase-based approach with a learning framework. The network proposed in this paper aims to synthesize an intermediate image given two neighboring images as input.

PhaseNet is designed as a decoder-only network, hence increasing its resolution level by level. At each level, the corresponding decomposition information is incorporated. Apart from the lowest level, all other levels are structurally identical. Information from the previous level is also included at each level.
The input to the network is the response from the steerable pyramid decomposition of the two input frames, consisting of the phase and amplitude values for each pixel at each level. These values are normalized before being passed through the network.
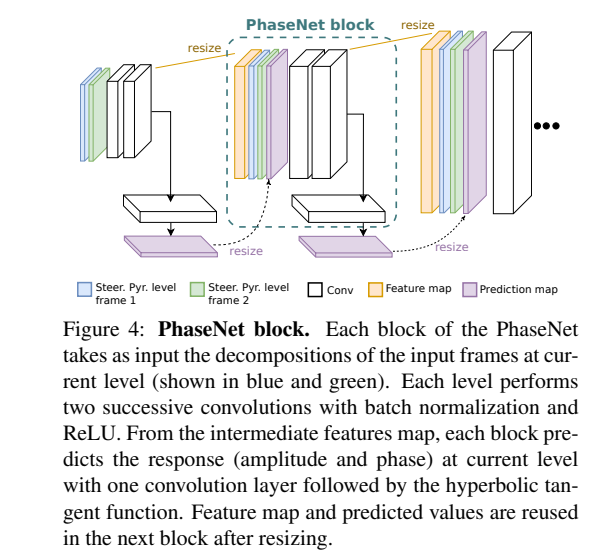
Each resolution level has a PhaseNet block that takes the decomposition values from the input images as its input. It also takes in the resized feature maps and the resized predicted values from the previous level. This information is then passed through two convolution layers, each followed by batch normalization and ReLU nonlinearity.
Each convolution produces 64 feature maps. After each PhaseNet block, values of the in-between frame decomposition are predicted. This is done by passing the output feature maps of the PhaseNet block through one convolution layer with size 1 x 1.
This is followed by the hyperbolic tangent function to predict output values. The decomposition values of the intermediate image are then computed from these values. Now the intermediate image can be reconstructed.
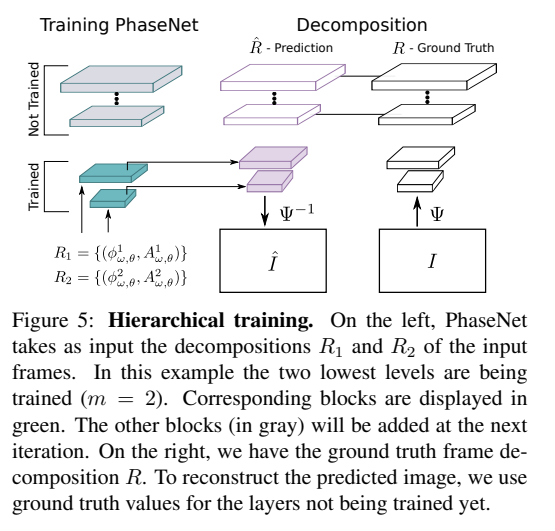
Training of this network is done using triplets of frames from the DAVIS video dataset.
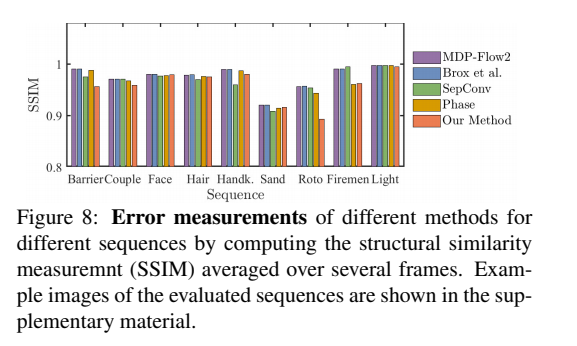
Here are some of the error measurements obtained for this model.
Don’t have time to scour the Internet for the latest in deep learning? Don’t worry, we’ve got you covered. Subscribe for our weekly list of updates from the deep learning world.
Super SloMo: High Quality Estimation of Multiple Intermediate Frames for Video Interpolation (CVPR 2018)
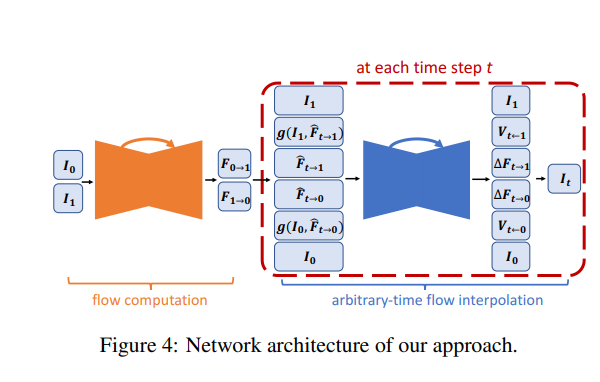
The authors of this paper propose an end-end-end convolution neural network for variable-length multi-frame video interpolation. In this model, motion interception and occlusion reasoning are jointly modeled.
Bidirectional optical flows between input images are computed using a U-Net architecture. The flows are then linearly combined at each time step to approximate the intermediate bi-directional optical flows. The approximated optical flows are refined using another U-Net.
This U-Net also predicts soft visibility maps. The two input images are then warped and linearly joined to form each intermediate frame. This approach is able to produce many intermediate frames as needed because the learned network parameters are time-independent.
In this network, a flow computation CNN is used to first estimate the bi-directional optical flow between the two input images. This is then linearly joined to approximate the required intermediate optical flow in order to warp input images.
The network is trained by collecting 240-FPS videos from YouTube and hand-held cameras. The trained model is evaluated on several datasets including the Middlebury, UCF101, slow flow dataset, and high-frame-rate MPI Sintel. The unsupervised optical flow results were also evaluated on the KITTI 2012 optical flow benchmark.

The U-Net used in this architecture is fully convolutional and consists of an encoder and a decoder. There are skip connections between the encoder and the decoder features at the same spatial resolution. There are six hierarchies in the encoder made up of two convolutional and Leaky ReLU layers.
An average pooling layer with a stride of 2 is used to decrease the spatial dimension at each hierarchy, except the last one. The decoder section has five hierarchies. The beginning of each hierarchy is a bilinear upsampling layer that’s used to increase the spatial dimension by a factor of 2. This is followed by two convolutional and Leaky ReLU layers. 7 x 7 kernels are used in the first two convolutional layers and 5 x 5 layers in the second hierarchy. The remaining part of the network uses 3 x 3 convolution kernels.
Here’s the performance of the said model on the UCF101 and Adobe datasets:

Depth-Aware Video Frame Interpolation (CVPR 2019)
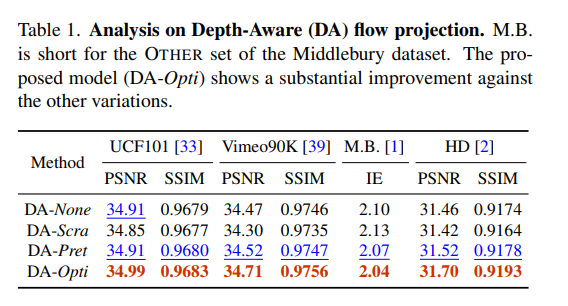
This paper proposes a video frame interpolation method that detects occlusion by exploring depth information. The authors develop a depth-aware flow projection layer that synthesizes immediate flows that sample closer objects than ones that are far away.
Learning of hierarchical features is done by gathering contextual information from neighboring pixels. The output frame is then generated by warping the input frames, depth maps, and contextual features based on the optical flow and local interpolation kernels.
The authors propose a Depth-Aware video frame INterpolation (DAIN) model that effectively exploits the optical flow, local interpolation kernels, depth maps, and contextual features to generate high-quality video frames.
The model uses PWC-Net as its flow estimation network. The flow estimation network is initialized from the pre-trained PWC-Net. For the depth estimation network, the authors use the hourglass architecture. The depth estimation network is also initialized from a pre-trained version. Contextual information is obtained by using a pre-trained ResNet.
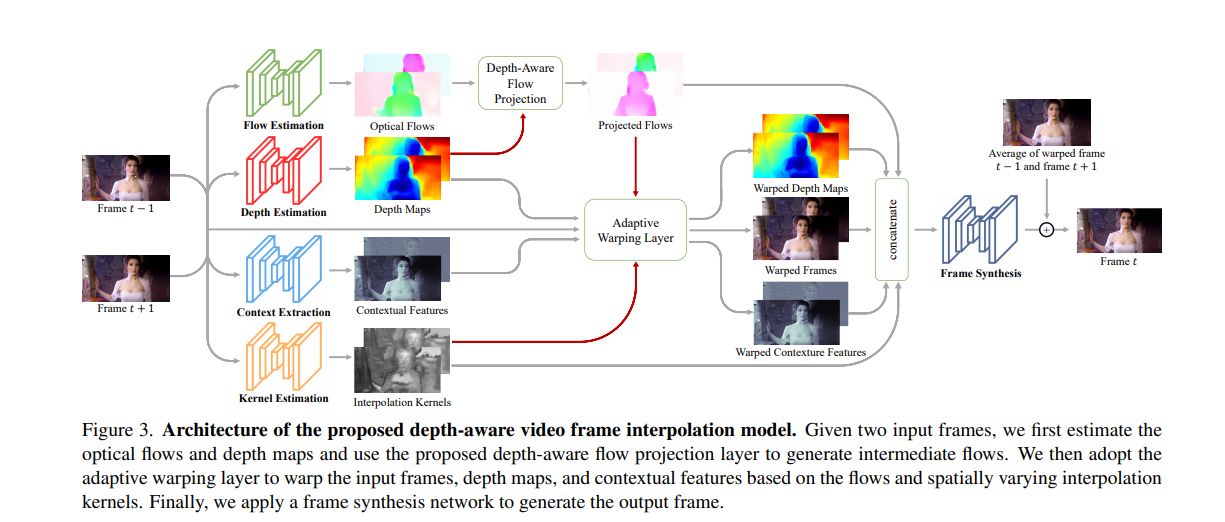
The authors build a context extraction network with one 7x 7 convolutional layer and two residual blocks without any normalization layer. A hierarchical feature is then obtained by concatenating the features from the first convolution layer and the two residual blocks. Training the context extraction network from scratch ensures that it learns effective contextual features for video frame interpolation.
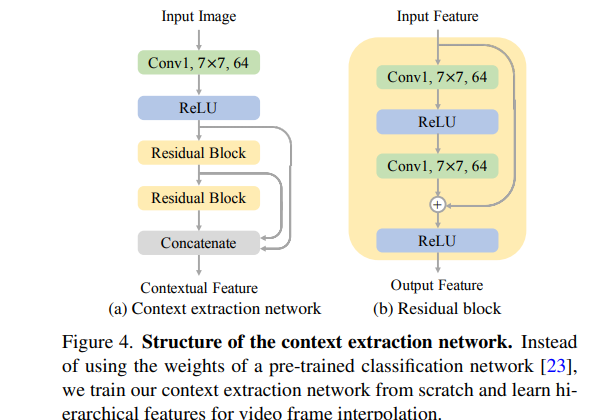
For the kernel estimation and adaptive warping layers, the authors use a U-Net architecture to estimate 4 x 4 local kernels for each pixel. The depth-aware flow projection layer generates the interpolation kernels and intermediate flows. The adaptive warping layer is adopted to warp the input frames, depth maps, and contextual features.
The final frame output is generated from a frame synthesis network. The network takes the warped input frames, warped depth maps, contextual features, projected flows, and interpolation kernels as its input. In order to ensure that the network predicts residuals between the ground-truth frame and the blended frame, the two warped frames are linearly blended.
The model is trained on the Vimeo90K dataset with AdaMax as the optimization strategy. The results obtained are shown below.
Frame Interpolation with Multi-Scale Deep Loss Functions and Generative Adversarial Networks (2019)
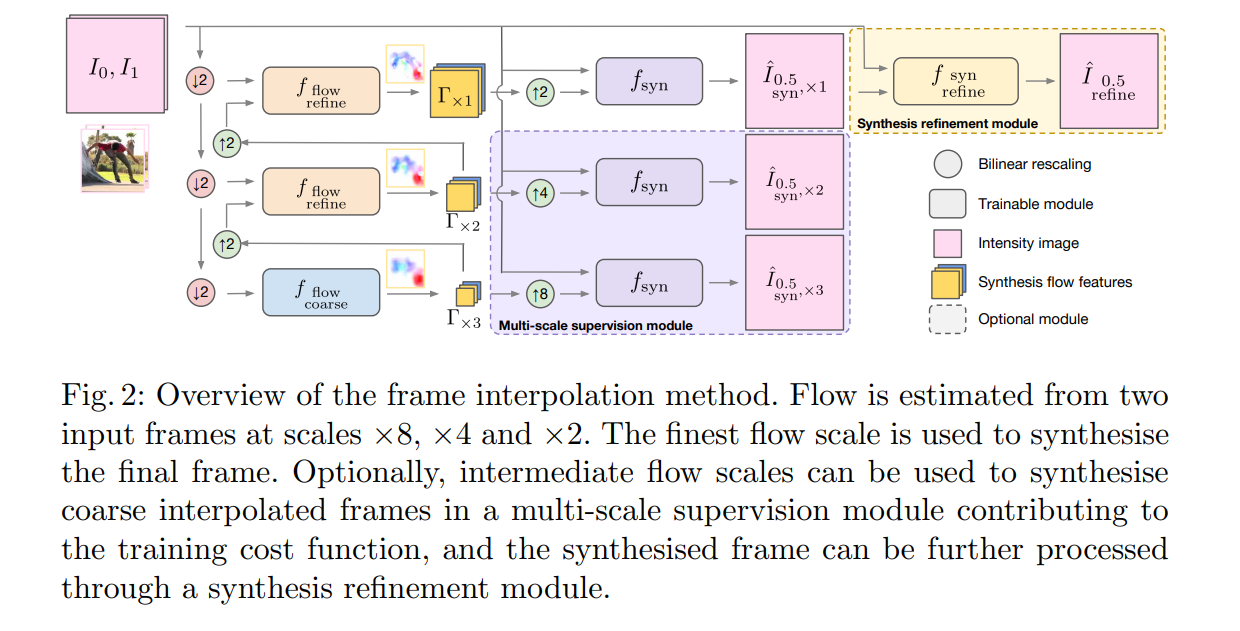
In this paper, the authors propose a multi-scale generative adversarial network for frame interpolation (FIGAN). The efficiency of this network is maximized by a multiscale residual estimation module, where the predicted flow and synthesized frame are constructed in a corse-to-fine fashion.
The quality of the synthesized intermediate video frames is improved by the fact that the network is jointly supervised at different levels with a perceptual loss that’s made up of an adversarial and two content losses. The network is evaluated on 60fps videos from YouTube.

The proposed model is made up of a trainable CNN architecture that directly estimates an interpolated frame from two input frames. Synthesis features are obtained by building a pyramidal structure and estimating optical flow between two frames at different scales. The synthesis refinement module is made up of a CNN that enables the joint processing of the synthesized image with the original input frames that produced it.
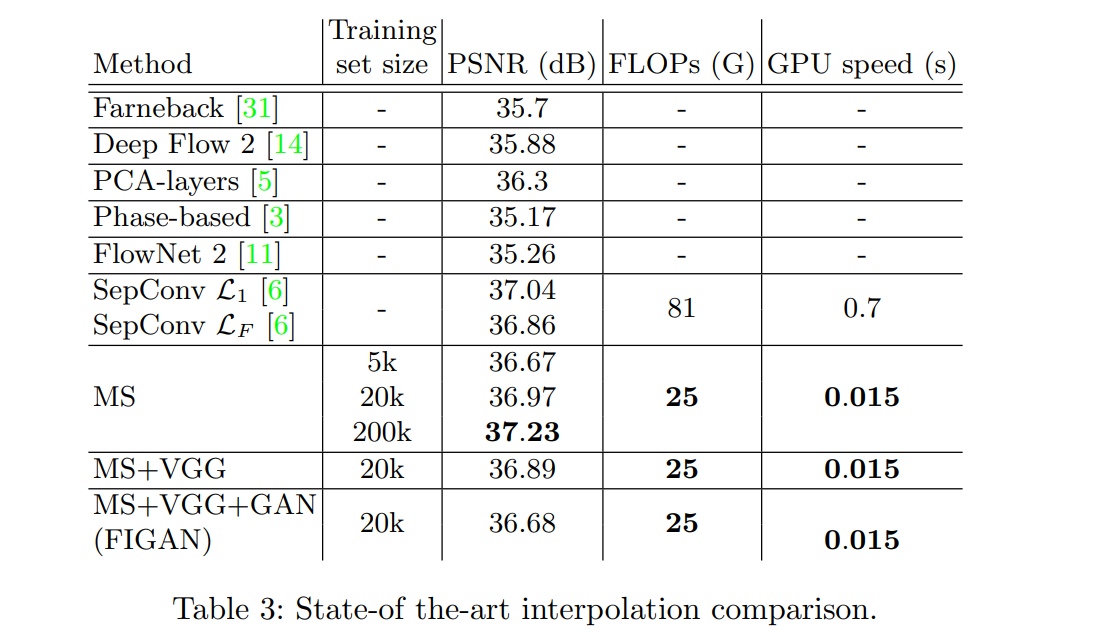
Some of the results obtained from this network are shown below.
Conclusion
We should now be up to speed on some of the most common — and a couple of very recent — techniques for performing video frame interpolation in a variety of contexts.
The papers/abstracts mentioned and linked to above also contain links to their code implementations. We’d be happy to see the results you obtain after testing them.
Editor’s Note: Heartbeat is a contributor-driven online publication and community dedicated to exploring the emerging intersection of mobile app development and machine learning. We’re committed to supporting and inspiring developers and engineers from all walks of life.
Editorially independent, Heartbeat is sponsored and published by Fritz, the machine learning platform that helps developers teach devices to see, hear, sense, and think. We pay our contributors, and we don’t sell ads.
If you’d like to contribute, head on over to our call for contributors. You can also sign up to receive our weekly newsletters (Deep Learning Weekly and Heartbeat), join us on Slack, and follow Fritz on Twitter for all the latest in mobile machine learning.
Research Guide for Video Frame Interpolation with Deep Learning的更多相关文章
- Video Frame Synthesis using Deep Voxel Flow 论文笔记
Video Frame Synthesis using Deep Voxel Flow 论文笔记 arXiv 摘要:本文解决了模拟新的视频帧的问题,要么是现有视频帧之间的插值,要么是紧跟着他们的探索. ...
- 深度学习研究组Deep Learning Research Groups
Deep Learning Research Groups Some labs and research groups that are actively working on deep learni ...
- What are some good books/papers for learning deep learning?
What's the most effective way to get started with deep learning? 29 Answers Yoshua Bengio, ...
- [C3] Andrew Ng - Neural Networks and Deep Learning
About this Course If you want to break into cutting-edge AI, this course will help you do so. Deep l ...
- Deep Learning: Assuming a deep neural network is properly regulated, can adding more layers actually make the performance degrade?
Deep Learning: Assuming a deep neural network is properly regulated, can adding more layers actually ...
- Deep Learning and the Triumph of Empiricism
Deep Learning and the Triumph of Empiricism By Zachary Chase Lipton, July 2015 Deep learning is now ...
- (转) Deep Learning Research Review Week 2: Reinforcement Learning
Deep Learning Research Review Week 2: Reinforcement Learning 转载自: https://adeshpande3.github.io/ad ...
- A Full Hardware Guide to Deep Learning深度学习电脑配置
https://study.163.com/provider/400000000398149/index.htm?share=2&shareId=400000000398149( 欢迎关注博 ...
- A Full Hardware Guide to Deep Learning
A Full Hardware Guide to Deep Learning Deep Learning is very computationally intensive, so you will ...
随机推荐
- 缓冲区溢出漏洞 ms04011
DSScan使用 扫描目标主机是否存在ms04011漏洞 getos使用 获取操作系统类型 > getos.exe 192.168.1.101 ------------------------- ...
- 实战FFmpeg + OpenGLES--iOS平台上视频解码和播放
一个星期的努力终于搞定了视频的播放,利用FFmpeg解码视频,将解码的数据通过OpenGLES渲染播放.搞清楚了自己想知道的和完成了自己的学习计划,有点小兴奋.明天就是“五一”,放假三天,更开心啦. ...
- EF 批量增删改 EntityFramework.Extensions
EntityFramework.Extensions 1.官方网站 http://entityframework-extensions.net/ 2 破解版 Z.EntityFramework.E ...
- JWT生成token及过期处理方案
业务场景 在前后分离场景下,越来越多的项目使用token作为接口的安全机制,APP端或者WEB端(使用VUE.REACTJS等构建)使用token与后端接口交互,以达到安全的目的.本文结合stacko ...
- 线性回归-API
线性回归的定义 利用回归方程(函数)对一个或多个自变量(特征值)和因变量(目标值)之间关系进行建模的一种分析方式 线性回归的分类 线性关系 非线性关系 损失函数 最小二乘法 线性回归优化方法 正规方程 ...
- 【笔记】MAML-模型无关元学习算法
目录 论文信息: Finn C, Abbeel P, Levine S. Model-agnostic meta-learning for fast adaptation of deep networ ...
- Kotlin中Range与异常体系剖析
好用的集合扩展方法: 下面来看一下对于集合中好用的一些扩展方法,直接上代码: 如果我们想取出集合中的第一个值和最后一个值,用Java方式是get(0)和get(size-1),但是在Kotlin中提供 ...
- 一道面试题关于js中逗号
一.今天遇到一个面试题,自我感觉是会,但是却做错了.人都是这样,自我感觉良好,其实也就预警自己已经忽视一些细节以及一些自我感知. 面试题: ,j=,k; ,j<;i++,j++){ k=i+j; ...
- 将照片转成base64时候,使用下面的这个包更加安全一些
import org.apache.commons.net.util.Base64; 在项目中将照片转成base64时候,使用下面的这个包更加安全一些
- c#3.0 Lambda 表达式
使用c# 2.0 中的匿名方法查找“内部包含abc子串的所有字符串”: list.FindAll( delegate(string s) { renturn s.indexof("abc&q ...