hive 整合ranger
一、安装hive插件
1、解压安装
# tar zxvf ranger-2.0.0-SNAPSHOT-hive-plugin.tar.gz -C /data1/hadoop/
2、修改install.properties
POLICY_MGR_URL=http://192.168.4.50:6080
REPOSITORY_NAME=hivedev
COMPONENT_INSTALL_DIR_NAME=/data1/hadoop/hive #hive安装目录
XAAUDIT.SOLR.ENABLE=true
XAAUDIT.SOLR.URL=http://192.168.4.50:6083/solr/ranger_audits
CUSTOM_USER=hduser
CUSTOM_GROUP=hduser
3、启动hive插件
# sudo ./enable-hive-plugin.sh
启动hive插件以后,默认生成hiveserver2-site.xml文件,或者在已经存在的该文件下添加如下信息:
<property>
<name>hive.security.authorization.enabled</name>
<value>true</value>
</property>
<property>
<name>hive.security.authorization.manager</name>
<value>org.apache.ranger.authorization.hive.authorizer.RangerHiveAuthorizerFactory</value>
</property>
<property>
<name>hive.security.authenticator.manager</name>
<value>org.apache.hadoop.hive.ql.security.SessionStateUserAuthenticator</value>
</property>
<property>
<name>hive.conf.restricted.list</name>
<value>hive.security.authorization.enabled,hive.security.authorization.manager,hive.security.authenticator.manager</value>
</property>
4、前台界面配置policy

点击加号添加服务

如果测试连接ok,说明配置成功。
注:我在配置的时候,这里测试连接失败,集群的hiveserver2服务启动,端口也正常监听,在集群内部使用beeline方式连接到集群进行操作时,提示如下错误:
Caused by: java.lang.NoSuchFieldError: REPLLOAD
最后发现是由于hive的版本与ranger hive里面的包版本不一致导致,我使用的hive版本是hive2.x,而ranger2.x对于的hive版本是3.x,所以,在使用的时候要注意版本的问题。
5、配置策略
当创建好服务以后,ranger默认就创建了一些policy,如下:
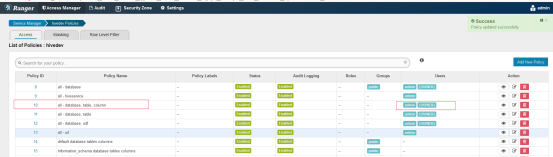
如果想要添加策略,可以添加右上角的add
6、测试
注意:ranger权限对应hive客户端是没有任何作用的,如果想要对hive客户端做权限认证,则可以使用hive基于sql的安全认证,ranger只是对hiveserver2方式进行权限控制。
(1) 首先使用beeline -u jdbc:hive2://localhost:10000 -n hduser 连接到hive
- 创建数据库(shanghai),该条语句可以正常执行。
- 在shanghai库里面创建表(test),则会创建失败,如下:
0: jdbc:hive2://192.168.0.230:10000> create table test(a string);
Error: Error while compiling statement: FAILED: HiveAccessControlException Permission denied: user [hduser] does not have [CREATE] privilege on [shanghai/test] (state=42000,code=40000)
提示没有权限
(2) 添加策略,在上图policy ID为10的这条策略里面修改如下:

上述的hduser的新添加的。添加完保存,格一小会,在再beeline模式下执行创建表的测试,看是否成功,当然,这里给了该用户所有的权限,所以,该用户还可以进行insert等操作。

(3) 测试其他用户,比如当前的操作系统上面有一个yjt用户,我想该用户对test表有查询权限,先在beeline模式下测试改用户是否有select权限,如下:
[hduser@yjt ~]$ beeline -u jdbc:hive2://192.168.0.230:10000 -n yjt #指定登录用户为yjt
0: jdbc:hive2://192.168.0.230:10000> select * from shanghai.test;
Error: Error while compiling statement: FAILED: HiveAccessControlException Permission denied: user [yjt] does not have [SELECT] privilege on [shanghai/test/*] (state=42000,code=40000)
可以发现,yjt这个用户对于shanghai数据库下的test这个表是没有select权限的,添加权限:
还是在上述的策略10里面添加,如下:

上述保存以后,如下:

策略添加完以后,需要等待策略的下发,权限控制才生效。
注意:策略修改完以后,不用重新启动beeline。
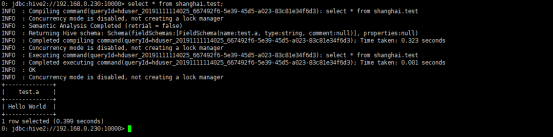
说明策略配置成功,那么上述配置了yjt这个用户的select权限,是否该用户真的只有select权限呢?继续测试改用户是否真的只有select权限,所以这里使用该用户insert 一条数据到test表,如下:

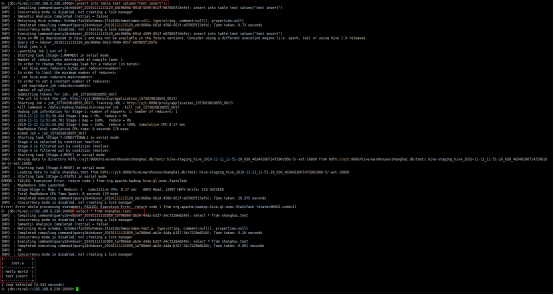
额,这还没到权限认证就开始报错了,上述的错误可以看到该用户对应hdfs的目录或者文件没有写权限,从这里也可以看到,还可以使用hdfs的权限认证限制hive用户。修改上述目录或者文件的权限为777(主要为了测试用户是否被hive ranger控制,所以这里设置为777,以排除其他干扰。)
[hduser@yjt conf]$ hadoop fs -setfacl -m user:yjt:rwx hdfs://yjt:9000/hive/warehouse/shanghai.db/test/
上述添加一条ACL。允许yjt所有操作
0: jdbc:hive2://192.168.0.230:10000> insert into table test values("test insert");
Error: Error while compiling statement: FAILED: HiveAccessControlException Permission denied: user [yjt] does not have [UPDATE] privilege on [shanghai/test] (state=42000,code=40000)
这里发现用户没有UPDATE权限,说明配置成功(在ranger里面,其实没有insert权限,只有update权限),接下来,在policy里面添加update权限,看是否可以成功的insert数据。

借鉴:
https://www.jianshu.com/p/d9941b8687b7
hive 整合ranger的更多相关文章
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
- hive整合hbase
Hive整合HBase后的好处: 通过Hive把数据加载到HBase中,数据源可以是文件也可以是Hive中的表. 通过整合,让HBase支持JOIN.GROUP等SQL查询语法. 通过整合,不仅可完成 ...
- 四 Hive整合HBase
安装环境: hbase版本:hbase-1.4.0-bin.tar.gz hive版本: apache-hive-1.2.1-bin.tar 注意请使用高一点的hbase版本,不然就算hive和h ...
- 创建hive整合hbase的表总结
[Author]: kwu 创建hive整合hbase的表总结.例如以下两种方式: 1.创建hive表的同步创建hbase的表 CREATE TABLE stage.hbase_news_compan ...
- Hbase与hive整合
//hive与hbase整合create table lectrure.hbase_lecture10(sname string, score int) stored by 'org.apache.h ...
- 安装hue及hadoop和hive整合
环境: centos7 jdk1.8.0_111 Hadoop 2.7.3 Hive1.2.2 hue-3.10.0 Hue安装: 1.下载hue-3.10.0.tgz: https://dl.dro ...
- Hive 整合Hbase
摘要 Hive提供了与HBase的集成,使得能够在HBase表上使用HQL语句进行查询 插入操作以及进行Join和Union等复杂查询.同时也可以将hive表中的数据映射到Hbase中. 应用 ...
- Hbase 与Hive整合
HBase与Hive的对比 25.1.Hive 25.1.1.数据仓库 Hive的本质其实就相当于将HDFS中已经存储的文件在Mysql中做了一个双射关系,以方便使用HQL去管理查询. 25.1.2. ...
随机推荐
- 2019 完美世界java面试笔试题 (含面试题解析)
本人3年开发经验.18年年底开始跑路找工作,在互联网寒冬下成功拿到阿里巴巴.今日头条.完美世界等公司offer,岗位是Java后端开发,最终选择去了完美世界. 面试了很多家公司,感觉大部分公司考察的点 ...
- 2019 快乐阳光java面试笔试题 (含面试题解析)
本人3年开发经验.18年年底开始跑路找工作,在互联网寒冬下成功拿到阿里巴巴.今日头条.快乐阳光等公司offer,岗位是Java后端开发,最终选择去了快乐阳光. 面试了很多家公司,感觉大部分公司考察的点 ...
- string 转stream和stream转string
string test = “Testing 1-2-3″; // convert string to stream MemoryStream stream = new MemoryStream(); ...
- CSS-服务器端字体笔记
服务器端字体 在CSS3中可以使用@font-face属性来利用服务器端字体. @font-face 属性的使用方法: @font-face{ font-family:webFont; src:ur ...
- CSS 滑动门案例
一.什么是滑动门特效 为了使各种特殊形状的背景能够自适应元素中文本内容的多少,出现了CSS滑动门技术.它从新的角度构建页面,使各种特殊形状的背景能够自由拉伸滑动,以适应元素内部的文本内容,可用性更强. ...
- C/C++ 关于数组和指针的总结
1.数组的声明形如a[d],其中a是数组的名字,d是数组的维度,编译的时候数组的维度应该是已知的,所以维度d必须是一个常量.如果要定义一个不知道元素个数的以为数组,那么请使用vector容器: uns ...
- 巧用浏览器F12调试器定位系统前后端bug-转载
做测试的小伙伴可能用过httpwatch,firebug,fiddler,charles等抓包(数据包)工具,但实际上除了这些还有一个简单实用并的抓包工具,那就是浏览器的F12调试器. httpwat ...
- TOML配置文件
Toml是一种易读.mini语言,由github前CEO,Tom创建.Tom's Obvious, Minimal Language. TOML致力于配置文件的小型化和易读性.wiki:https:/ ...
- javascript数据结构与算法——列表
前言: 1. 数据的存储结构顺序不重要,也不必对数据进行查找,列表就是一种很好的数据存储结构; 2.此列表采用仿原生数组的原型链上的方法来写,具体可以参考MDN数组介绍,并么有用prototype来构 ...
- spring cloud (二) 服务提供者 EuekaClient
1 创建一个springboot项目 spring-cloud-service-a 注册到eureka服务注册中心中 项目添加依赖 <dependency> <groupId&g ...