Predictive Analysis in Network Function Virtualization
摘要
网络功能虚拟化(NFV)体系结构的最新部署获得了极大的关注。虚拟化虽然带来了诸如降低成本和简化网络功能部署之类的好处,但它增加了附加层,从而降低了较低层故障的透明度。为了改善虚拟网络功能(VNF)的故障分析和预测,我们构想了一个运行时预测分析系统,该系统与现有的反应式监视系统并行运行,以向网络运营商提供针对故障情况的及时警告。在本文中,我们提出了一种基于深度学习的方法,可从NFV系统日志中可靠地识别异常事件,并使用2016-2018年连续18个月的虚拟化提供商边缘路由器上的实际部署数据进行实证研究。我们的深度学习模型与定制和适应机制相结合,可以成功地识别与网络故障单相关的异常情况。分析这些异常可以帮助操作员优化故障单的生成和处理规则,以便针对故障情况采取快速甚至主动的措施。
1 INTRODUCTION
网络功能虚拟化(NFV)体系结构的最新部署[1]获得了极大的关注。 NFV允许将以前由硬件处理的网络功能实现为在商品服务器上运行的软件。其优势包括简化新功能的部署,简化管理
通过托管的虚拟机,并降低了使用商品硬件的成本。不利之处在于:1)与专用硬件相比,当今新实施的虚拟化网络功能(VNF)及其主机商用服务器更容易出现故障[11、12、23],以及2)虚拟化为下层事件引入了更多的层次和更少的可见性,例如故障。这些缺点可能会对NFV部署产生负面影响。例如,对于NFV系统来说,一个关键问题是它们是否可以提供与传统运营商级系统相似的可用性,最多可达9s(正常运行时间的99.999%)[5]。在本文中,我们描述了在美国最大的ISP的IP主干网络边缘部署的,迄今为止已知的最大NFV部署之一中,预测网络故障并减少停机时间的过程。我们专注于重要的VNF类型之一-vPE(虚拟化提供商边缘路由器)。我们探索了一种系统的设计和性能,该系统将深度学习模型(LSTM),模型定制和通过转移学习共享到syslog的组合相结合,从而使我们能够识别潜在故障特征,从而近乎实时地预测故障单。尽管将机器学习(包括深度学习模型)应用于故障预测本身并不新鲜[22、28、37],但我们的工作面临着三个挑战的独特组合。首先,由于故障相对较少,因此我们的数据极不平衡,因此很难训练监督学习模型来进行故障单预测。其次,由于每个VNF都有其自己的规格和流量特性,因此可能没有单个模型可以在VNF中很好地工作。第三,定期软件更新会不断更改数据平面上的系统功能和流量特性。因此,我们没有足够的精力来收集大量的培训资料来建立长期使用的模型。相反,必须使用短数据窗口快速构建模型,并在下一次软件更新或配置更改使它们过时之前将其部署。
我们的解决方案包括以下几种技术:
•为了解决数据不平衡问题,我们使用了无监督的异常检测方法来训练带有“正常”日志的长短期记忆(LSTM)网络[14]模型。 异常日志模式会触发对网络故障情况的预测。
•为了解决VNF多样性,我们使用聚类来识别具有相似配置和日志行为的VNF,并对其进行汇总(将它们作为合并后的系统日志作为一个单元进行处理)。
•为了解决基础架构更改的时间动态变化,我们使用类似于迁移学习的增量培训。 这有助于我们在软件更新后快速引导模型,而不会导致收集训练数据的时间延迟。
我们使用在生产环境中部署的vPE路由器上18个月内收集的网络故障单来评估我们的方法。 我们的评估结果表明,系统日志异常通常发生在生成网络故障单之前。 我们可以找出这些异常情况,以识别任何潜在的预警信号或预测性信号。
2 RELATED WORKS
NFV中的可靠性和故障管理。
[9,30]解决了NFV中可靠性,弹性和故障管理的必要性和挑战,表明关键挑战之一是层之间的协作和延迟。 [18]研究了网络资源警报之间的相关性,并为根本原因分析制定了规则。 [21,24]利用基于自组织映射(SOM)的群集来基于SNMP测量来识别不同类型的网络故障,但是需要事先对每种故障类型进行充分的采样。 [31]从虚拟机管理程序和VM层收集指标,并应用随机森林对VNF行为进行分类。所有这些都评估了小型的,自定义的网络故障。
网络中的故障预测/检测。
现有的文献[16,20]基于关键性能指标(KPI)来实现故障检测,例如CPU利用率和数据包丢失,而我们的工作集中在VNF系统日志上。现有的大多数工作都通过建立经过正常和异常事件训练的二进制分类器来应用监督的故障预测/检测。 [10,19,29]根据故障事件的特征应用了简单的故障预测方法,并开发了隐马尔可夫模型(HMM)和浅层机器学习方法进行网络故障预测。为了捕获监视数据中的顺序模式,[37]设计了顺序功能,并应用了Random Forest来学习数据中心交换机硬件故障的预兆和非预兆模式。 [36]应用LSTM来检测服务器群集关闭的单一类型的故障。上述监督方法面临的主要挑战是,它们需要足够的异常数据来训练模型,这需要花费大量时间来收集,例如根据以上研究的多年。
为了减少数据收集的延迟,一些工作采用了无监督的方法。 [35]提取状态变量和标识符的特征,并应用PCA进行异常检测。 [8,17]将LSTM应用于Linux系统调用的网络入侵检测和CloudLab上的OpenStack实验。尽管我们也采用无监督的学习方法,但我们的工作与现有工作有所不同,其重点是对NFV系统故障的预测分析。
3 INITIAL ANALYSIS
使用来自实际NFV部署的数据,我们研究了网络故障的不同类型及其时空模式。 我们还检查了VNF层上syslog的模式,这些模式将用于预测网络故障。
3.1 Datasets
我们的数据集包括网络故障单和从38层vPE(虚拟化的提供商边缘路由器)收集的,由一级ISP的骨干网络在18个月内部署的VNF系统日志。 vPE降级会导致客户网络上的服务受损。 预测这些故障事件可以使操作员或闭环自动化在每次事件发生之前触发缓解措施,并最大程度地降低其影响。
网络故障单。
故障单捕获可操作的网络事件。每个故障单都包含发生时间,根本原因和故障单持续时间。我们的数据集包括这38个vPE上的全部故障单,并包含以下六类根本原因:
•维护:预期或计划的网络操作或更改;
•电路:两个设备之间(特定接口上)的连接断开。
•电缆:由于环境或人为因素造成的电缆断开连接。
•硬件:构成机箱系统的卡和构成卡的组件出现故障。
•软件:由于软件问题而导致的故障。
•重复:原始问题未解决时,后续操作失败。
对于每个故障单,我们同时跟踪故障单报告时间和维修结束时间。故障票证是由来自各种网络监视系统的信号通过一系列票证处理逻辑(例如模式匹配和事件相关性)与已知问题签名进行匹配而触发的。因此,票证报告时间通常在第一次出现网络故障症状时或之后。由于票证生成过程不完善,因此可能会遗漏早期症状,并在症状的首次出现和票证的实际生成之间引入明显的延迟。
VNF系统日志。
系统日志是系统生成的用于描述各种事件的复杂,无结构,自由格式的文本[26,35]。一部vPE每年可能有数百万条syslog消息。关键字和日志消息的不同类型之间的关系[8、17、26、37]定义了系统日志的关键结构模式。我们使用著名的签名树[26]方法将原始syslog转换为结构化表示形式,以方便进行关系建模。我们还将vPE系统日志与具有类似网络票证的pPE(物理提供商边缘路由器)的系统日志进行比较。我们观察到,vPE syslog的容量比pPE syslog少77%,并且在物理层上包含的日志消息少得多。这证实了我们的直觉,即NFV降低了每个vPE对较低层事件的可见性。
3.2 Trouble Ticket Analysis
为了帮助理解故障凭单的可预测性,我们将分析重点放在(1)故障凭单的时间分布/频率和(2)vPE之间的凭单模式相似性。
时间分布。
图1(a)显示了随时间推移具有不同根本原因的故障单。 我们发现维护是主要因素,但它们是可预测的(因为它们是预定事件)。 接下来的两个主要贡献者是重复票和巡回票。 总体而言,票证数据高度不对称。 图1(b)绘制了每个vPE的非重复故障单到达间隔时间的分布。 我们发现非重复的票证相隔40分钟以上到达。 连续票证之间的时间间隔的80%超过10小时,并且连续票证之间的25%的间隔时间超过1000小时(42天)。 最后,我们观察到重复的票证经常会突然到达。
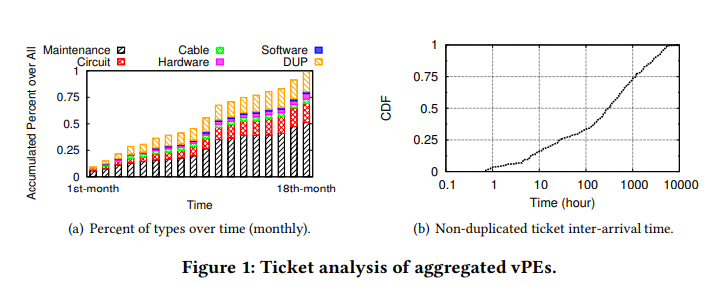
每个vPE tickets 行为。
图2显示了跨vPE的非维护故障凭单(按每个vPE的凭单数量排序)。 每个点表示对应的vPE(y)在给定的时间间隔(x)上具有票证。 显然,票证模式是非周期性的,并且与vPE有关-某些vPE具有比其他票证更多的票证。 时间或任何特定vPE都没有明显的偏差。 另一个观察结果是,有时,多个vPE在相同的时间间隔(竖线标记)中遇到网络故障情况。 对数据的更深入研究表明,这些票证是由导致所有连接的vPE中断的核心路由器问题触发的。 但是,这种情况很少见,只会造成很少的故障单.
3.3 VNF Syslog Analysis
我们对在vPE处收集的VNF系统日志进行时空分析。为了分析与网络故障事件无关的“正常”系统日志条目,我们会修剪日志以删除故障单有效期(故障单到达时间到标记为已解决之间的时间)之内三天内的所有条目。跨vPE的相关性。我们首先问一个问题:vPE的系统日志在正常运行期间是否显示类似的行为(即无故障)?我们计算每个vPEv的syslog分布的余弦相似度[32],以及所有vPEs V上聚合的syslog的余弦相似度[32],即
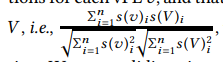
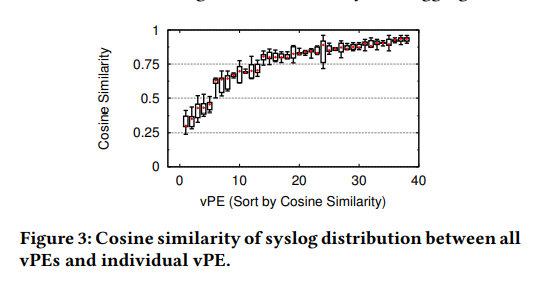
其中s(·)表示系统日志分布。我们在整个系统日志中使用一个月的滑动时间窗口,并计算归一化的频率分布。图3显示了整个时间的余弦相似度的分位数(0%,25%,50%,75%,100%)。只有三分之一的vPE具有相似的syslog分布(余弦相似度> 0.8),并且有5个vPE的余弦相似度<0.5。这可能是由于服务器角色,配置和流量的差异所致。因此,我们将需要针对每个vPE定制的模型来检测vPE syslog上的异常
系统更新的影响。
另一个关键发现是,某些vPE的系统日志在2017年底至2018年初之间突然发生了变化,这是由于系统更新改变了系统日志的分布而触发的。 我们计算连续两个月之间syslog分布的余弦相似度。 我们发现,在系统更新之前,余弦相似度始终高于0.8,但在系统更新后降至低于0.4。 这意味着我们需要快速更新vPE syslog的模型(使用短数据窗口),以使它们不会过时
4 PREDICTING TICKETS FROM SYSLOG
ANOMALIES
在本节中,我们将介绍确定vPE syslog中特定(或异常)模式的方法,这些模式可能用作(故障)tickets 状况的早期检测或警告签名.
4.1方法论
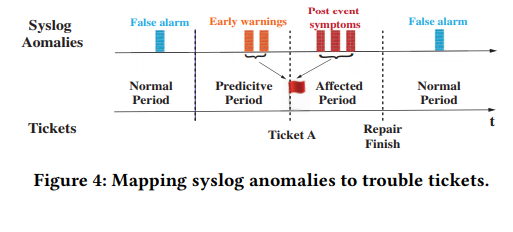
我们在§3中的经验分析确定了通过vPE syslog预测故障单的三个主要挑战。首先,在我们的vPE系统日志中,故障单相对较少。在这种不平衡的数据的情况下,很难训练用于故障预测的监督学习模型。其次,系统日志数据的数量和复杂性使得很难手动选择对日志行为进行ML模型训练所必需的功能集。第三,由于Syslog分布随vPE的不同而变化,因此随着时间的流逝,我们需要为每个vPE自定义机器学习模型,并在系统更新后对其进行重新培训。两者都会导致数据收集延迟方面的大量开销。为了解决前两个挑战,我们建立了一个长期短期记忆(LSTM)网络[14],该网络在正常运行期间自动学习系统日志模式(第4.2节)。代替有监督的训练,我们采用使用“正常” syslog数据训练的基线模型采取异常检测方法。因此,故障票事件的稀有性不会影响我们。每个检测到的异常都可能充当网络故障状况的指示器。为了解决数据收集延迟的第三个挑战,我们同时应用了群集和在线学习技术,以减少为单个vPE定制模型所需的训练数据量(第4.3节)。检测到异常后,我们将它们与相关故障单之间的映射关联起来。我们将票证生成之前的时间窗定义为预测期,并将票证报告与维修结束之间的时间作为预期期。如图4所示,如果在票证的预测或预期时间段内检测到异常,我们会将其与票证相关联。特别是,在机票的预测期内检测到的异常被视为“预警信号”,而在机票的预期时间内检测到的异常被视为“事后症状”。尽管有很多原因,在出票时间之前可能会发生异常,某些早期预警信号可能会转换为其他触发票的签名。与票证无关的异常将被视为错误警报。我们会更改预测期的长度,以查看第5节中的效果变化。
4.2基于LSTM的异常检测
作为用户/程序与系统之间通信的一种语言,vPE syslog显示顺序模式。准确的系统日志模型必须能够捕获那些顺序模式。因此,我们考虑了长期短期记忆(LSTM)网络,该网络以其捕获嵌入在顺序数据中的全面而复杂的模式1的能力而闻名。借助足够的培训数据,LSTM可以自动学习系统日志的正常模式,并且可以将异常情况作为正常情况进行偏离。实际上,LSTM在检测各种异常方面已显示出巨大的成功,例如分布式系统中的服务器故障或情感分析中的异常[8,17,33]。与传统的线性分类器不同,我们的方法不依赖特征工程。对于LSTM的输入,我们使用每个单独的logmi,它捕获特定时间间隔([ti,ti-1))的系统事件(mi出现在ti)。不仅使用原始日志条目,我们还使用上述签名树方法[26]从原始数据中提取特定的模板(或签名)并对其进行分类,并以(mi,ti -ti-1)元组标记,mi∈S,其中S是模板集合。给定k个syslog元组,我们训练LSTM模型来预测mk + 1。这是一个多类分类问题,其中输出是模板集S上的概率分布。
模型训练。
我们使用在“免票”网络操作期间产生的系统日志来训练LSTM网络。如第3.3节所述,我们修剪在实际工单的活动窗口周围3天时间内发生的syslog条目。我们还尝试了更大的窗口大小,但没有观察到明显的差异。
检测异常。
使用训练有素的LSTM模型,我们可以如下检测异常。为了确定传入的系统日志mk + 1是正常还是异常,我们将先前观察到的k个系统日志插入模型中,并得出第(k + 1)个对数的预测概率分布。如果mk + 1正常,则相应的对数似然值应较高(高于阈值),否则为异常。通过更改阈值,我们可以得出精确召回曲线(PRC),这是用于评估异常检测系统的最广泛的方法[6]。
学习少数Syslog模式。
尽管LSTM旨在自动学习正常syslog条目的模式,但由于少数群体模式在训练数据中很少出现,因此通常很难学习。结果是较高的误报率。我们通过对少数(正常)模式进行过采样来解决此问题[4]。具体来说,我们使用第i个月的系统日志来训练LSTM模型,该模型将用于检测第i个月(i +1)内的异常情况。我们使用第i个月的正常syslog作为训练数据,对LSTM模型进行多次训练。在每轮训练之后,我们使用原始训练数据测试模型,并识别被误分类为异常的正常syslog模式。然后,我们对这些模式进行过度采样,并对所有其他模式进行随机采样,并使用所得数据调整模型权重。当假阳性率不能进一步提高时,该过程退出。
4.3定制和适应
由于syslog的分布在vPE之间有所不同,因此一般的LSTM模型可能会达到次优的精度。理想的解决方案是为每个vPE构建自定义模型,但是由此产生的训练开销和数据收集延迟是不可接受的。我们使用vPE分组解决了模型准确性和数据收集延迟之间的折衷[16]。我们将K-均值[13]应用于vPE组,并根据模块化选择K组的数量。同一群集中的vPE在syslog分布中显示相似的模式,并且它们的训练数据将汇总在一起以为该组建立统一模型。对于我们的数据集,我们产生了4个vPE簇,这导致了4个LSTM模型。
我们还使用在线(或增量)学习来减少训练数据收集的延迟。具体来说,每个月我们都会使用新到达的syslog条目更新模型权重,以进行一轮增量培训。由于系统日志分布相对稳定,因此我们没有观察到模型权重的显着变化。
唯一的例外是,在2017年底至2018年初之间,vPE网络进行了系统升级,并且对某些vPE的系统日志分发进行了重大修改。结果,错误警报的数量增加了14倍,表明该模型已过时且需要更新。天真的解决方案是重新训练整个模型,但是重建合理的训练数据集需要3个月以上的时间。我们需要一种可以在更短的时间范围内重新训练模型的解决方案。
为了解决这一挑战,我们考虑转移学习[27],其中使用有限的训练数据将预训练的神经网络模型(即在系统更新之前训练的“教师模型”)调整为可以响应新系统日志的学生模型。行为。具体而言,我们首先通过复制教师模型来构建学生模型,然后使用新的syslog数据训练学生模型以调整模型的顶层。对于我们的案例,在主要软件更新后,有足够的一周新的训练数据来快速更新模型。
5 EVALUATION
在本节中,我们评估基于LSTM的异常检测系统,以及将vPE syslog异常用作网络故障单的(早期)警告签名的可行性
5.1 Experimental Setup
我们使用Keras [2]和Tensor ow [3]作为后端实现了异常检测系统。对于模型优化,我们改变了模型参数以最小化分类交叉熵[15],但发现模型性能通常对参数选择不敏感。我们的最终LSTM模型由2个LSTM层和1个致密层组成。
估计系统日志异常的地面真相。评估我们的异常检测系统需要系统日志异常的地面真实性,我们可以使用故障单进行近似。对于每个故障单,我们将其生成时间之前的时间窗口定义为预测周期,并将其生成后直至报告的故障单修复时间(机票持续时间)的时间窗口定义为预期时间段。如图4所示,如果任何系统日志异常属于故障单的预测期或预期期,我们将其视为真正的异常。因此一张票可能具有多个(早期)签名。另一方面,在这些时间段之外的任何异常都被视为误报。我们尝试了从1小时到2天的多个预测周期值,发现检测性能在1天时收敛。另一个有趣的观察结果是,在将syslog异常与非重复故障单匹配之后,每个故障单都与至少两个异常相关联(在预测期内)。这些异常彼此接近,平均间隔不到1分钟。因此,我们配置了检测系统,以在检测到两个或多个异常的小簇时报告网络故障单的警告签名。
训练和测试。
我们使用18个月数据中第一个月的syslog数据进行初始模型训练。 在每个月末,我们使用上个月的最新数据更新LSTM模型,并使用下个月的数据测试更新后的模型。 初始模型训练和每月模型更新都在不到一小时的时间内完成。
5.2 Accuracy of Anomaly Detection

精度,召回率,F量度。
我们从异常检测的三个标准指标开始[25]。 精度显示所有检测到的异常中真实异常的百分比; 召回率用于测量所检测到的数据集中异常的百分比(门票为地面)。 F-measure是两者的谐波均值。 图5绘制了通过调整LSTM对数概率(第4.2节)中的上述阈值而产生的精确召回曲线(PRC)。 我们的最终工作点是最大化Fmeasure的工作点,精度为0.8,召回率为0.81。 在这种情况下,我们的系统可以有效地识别异常,同时为所有vPE每天实现0.6%的低误报率。
与现有方法的比较。
我们考虑了两种用于异常检测的现有方法:•自动编码器[7]是前馈多层神经网络,其中所需的输出是输入本身。用正常数据训练自动编码器后,重建错误可以用作异常指示。我们使用TF-IDF(项频,文档逆频)功能[36]作为自动编码器的输入。 •一类SVM [34]使用浅层学习来构建正常syslog训练数据的模型,这需要特征工程(通过内核将数据映射到高维特征空间中)。如果新的系统日志条目明显偏离模型,则将其标记为异常。为了公平地比较,我们在所有三种方法上都应用了相同的自定义和适应机制(第4.3节)。图6显示了这三种方法的性能。两种深度学习方法(LSTM,自动编码器)在很大程度上优于传统的分类方法(一类SVM),因为鉴于vPE syslog的数量和复杂性,功能工程非常具有挑战性。通过捕获syslog的顺序模式,LSTM略胜于Autoencoder(精度为0.82 vs. 0.77)。
定制和适应的收益。
我们使用微基准来了解模型自定义(所有vPE的单个模型与每个vPE的自定义模型)和快速模型适应(在系统更新之后)的作用。图7绘制了18个月期间的模型F量度。模型定制可以显着改善模型F度量和精度(由于空间限制,结果未显示)。我们的模型自适应组件允许系统仅用1周的训练数据即可从软件更新造成的破坏中快速恢复。使用超过1周的训练数据不会产生明显的改善。
减少培训费用。我们的设计同时使用vPE群集和转移学习来减少syslog训练数据量(用于构建和调整LSTM模型)。我们通过将它们与相应的基准进行比较来评估其有效性。使用vPE群集,我们可以将(初始)培训数据的数量从3个月减少到1个月。使用转移学习,我们将恢复时间(从软件更新)从3个月减少到1周。这意味着我们可以建立和维护高质量的预测模型,而不会因收集训练数据而造成昂贵的延迟。
5.3基于故障单的评估
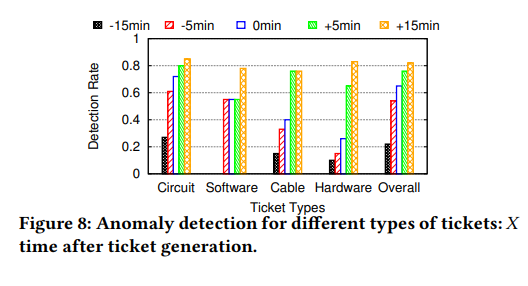
我们使用故障单作为近似的地面真实性来评估我们的方法如何有效地发现异常的系统日志条件。图8显示了针对每个人(非票证)(至少在票证到达前15分钟,在票证之前至少5分钟,在票证之前0分钟,在票证之后5分钟以及在票证之后15分钟)检测到任何异常的可能性。 (重复)票证类型,以及所有票证。
我们寻求回答以下问题:
Q1:哪些类型的网络故障单在VNF Syslog中显示早期迹象?答:我们发现VNF系统日志出现在多种故障单类型(例如,电路,软件,电缆和硬件)之前。与电路故障故障单相关的系统日志在故障单生成之前发生的可能性最高(74%),其次是软件(55%),电缆(40%)和硬件(28%)。这表明尽管对由虚拟化导致的较低故障的可见性降低了,但VNF syslog确实捕获了与网络故障单相关的异常情况。
问题2:对于在故障单生成之前未显示syslog异常的故障,它们的任何异常会很快出现在syslog上吗?答:是的,对于大多数票证(80%),vPE syslog将在票证生成后的15分钟内显示异常模式。这意味着故障模式在短暂的延迟后就可以在NFV层上看到,NFV可以利用它来进行故障单分析,诊断和管理。
Q3:与故障单代相比,我们多早观察到系统日志异常情况?答:大多数检测到的系统日志异常都在故障单生成之前5分钟。对于Circuit,系统日志异常的36%提前15分钟出现,对于电缆(39%)和硬件(38%)类别,该比率甚至更高。尽管需要进行更深入的调查,但这些结果表明,运营商可能能够利用这些系统日志异常来改善其票务流程,或者识别出指示网络故障的预测性或早期状况。
问题4:单个或一组异常是否可以作为一组近期故障单的警告信号?答案:这与是否可以将单个系统日志异常(或系统日志异常集群)与多个故障单关联的问题有关。根据我们当前的数据集,这从未发生过,这主要是因为票证稀少且分隔良好。我们计划将来使用更大规模的研究来证实这一发现。
运营结果。
我们的模型识别出的异常可以分为四种情况。首先,检测到的情况可能是近期网络问题的真实预测信号。例如,我们确定了一个条件,该条件涉及与特定控制器的某些对等会话连接失败有关的管理守护程序错误消息(“来自对等机箱控制的无效响应”)。当观察到这种情况的异常时,通常会在一段时间后发出故障单。我们需要进一步研究这种明显的预测性特征,以了解潜在的vPE行为。其次,可以分析检测到的状况,并在出现故障状况时将其转变为早期检测特征。例如,我们发现,在短时间间隔内跨多个对等方的协议会话aps(“ BGP UNUSABLE ASPATH:bgp拒绝路径”)风暴可以转变为快速检测签名(误报最少)。这种异常检测的性能优于现有的服务水平监视器,后者通常具有更长的检测延迟。第三,检测到的情况可能是触发故障单的事件的一部分。这可能是由于现有票务流程中的事件响应过程所致,例如为抑制瞬态问题而添加的故意延迟。我们的发现可能有助于运营进一步优化票务流程。第四,检测到的条件与故障单是巧合的(即,涉及无关的系统日志异常)。这种情况是相对罕见的,应谨慎管理,例如,通过在票证处理流中添加抑制规则。在以后的工作中,我们将检测到的情况进一步分为这四种情况。
6 结论
我们在实际部署中使用系统日志和网络故障单来研究NFV网络中的故障预测问题。 我们提出了一种从NFV系统日志中检测异常的新方法,该方法有可能用作网络问题的早期指示器,这些问题通常会导致故障单。 我们使用在生产NFV环境中在虚拟化提供商边缘(vPE)路由器上收集了18个月以上的样本数据集来验证我们的方法。 我们观察到,基于LSTM的异常检测系统发现了通常在故障单之前发生的系统日志异常情况。 我们相信,我们的方法可以帮助网络运营团队(a)识别预测性或早期预警信号,或(b)改进当前的票务流程,从而能够及时响应NFV故障。
Predictive Analysis in Network Function Virtualization的更多相关文章
- Network Function Virtualization for a Network Device
An apparatus for performing network function virtualization (NFV), comprising: a memory, a processor ...
- NFV-Bench A Dependability Benchmark for Network Function Virtualization Systems
文章名称:NFV-Bench A Dependability Benchmark for Network Function Virtualization Systems 发表时间:2017 期刊来源: ...
- Network Function Virtualization: Challenges and Opportunities for Innovations
年份:2015 ABSTRACT 最近提出了网络功能虚拟化,以提高网络服务供应的灵活性并减少新服务的上市时间. 通过利用虚拟化技术和通用的商用可编程硬件(例如通用服务器,存储和交换机),NFV可以将网 ...
- In-band Network Function Telemetry
文章名称:In-band Network Function Telemetry 发表时间:2018 期刊来源:SIGCOMM I Introduction (介绍) NFV运行在商品服务器上,在网络功 ...
- Improving the Safety, Scalability, and Efficiency of Network Function State Transfers
Improving the Safety, Scalability, and Efficiency of Network Function State Transfers 来源:ACM SIGCOMM ...
- OpenStack for NFV applications: enabling Single Root I/O virtualization and PCI-Passthrough
http://superuser.openstack.org/articles/openstack-for-nfv-applications-enabling-single-root-i-o-virt ...
- 论文阅读:Elastic Scaling of Stateful Network Functions
摘要: 弹性伸缩是NFV的核心承诺,但在实际应用中却很难实现.出现这种困难的原因是大多数网络函数(NFS)是有状态的,并且这种状态需要在NF实例之间共享.在满足NFS上的吞吐量和延迟要求的同时实现状态 ...
- SDN与NFV技术在云数据中心的规模应用探讨
Neo 2016-1-29 | 发表评论 编者按:以云数据中心为切入点,首先对SDN领域中的叠加网络.SDN控制器.VxLAN 3种重要技术特点进行了研究,接下来对NFV领域中的通用服务器性能.服务链 ...
- 深度解析SDN——利益、战略、技术、实践(实战派专家力作,业内众多专家推荐)
深度解析SDN——利益.战略.技术.实践(实战派专家力作,业内众多专家推荐) 张卫峰 编 ISBN 978-7-121-21821-7 2013年11月出版 定价:59.00元 232页 16开 ...
随机推荐
- 使用 Create-React-App 开发 Chrome 扩展
整理 Kindle 标注.书签和笔记从未如此简单! Kindle 标注管理应用 Kindle Mate 只支持 Windows,不支持 Mac.标注只是解析我的剪贴文本文件,配合 FileReader ...
- nginx-ingress之server-snippet用法
apiVersion: extensions/v1beta1 kind: Ingress metadata: annotations: nginx.ingress.kubernetes.io/serv ...
- java自定义注释及其信息提取
转自:https://xuwenjin666.iteye.com/blog/1637247 1. 自定义注解 import java.lang.annotation.Retention; import ...
- 一个工作13年的SAP开发人员的回忆:电子科技大学2000级新生入学指南
让我们跟着Jerry的文章,一起回到本世纪初那个单纯美好的年代. 2000年9月,Jerry告别了自己的高中时代,进入到自己心目中的电子游戏大学,开始了四年的本科生活.每个新生,都拿到了这样一本薄薄的 ...
- zookeeper的安装使用
转载从:https://blog.csdn.net/shenlan211314/article/details/6170717 一.zookeeper 介绍 ZooKeeper 是一个为分布式应用所设 ...
- php无限分类方法类
创建数据库以及表 CREATE DATABASE `sortclass`DEFAULT CHARSET utf8; CREATE TABLE IF NOT EXISTS `class` ( `cid` ...
- MySQL--使用mysqldump进行数据库版本升级
在MySQL跨版本升级时,建议使用mysqldump方式导出用户权限和用户数据,即使是小版本升级,导出过程中也应忽略系统数据库,避免系统表不兼容. 导出用户数据库脚本和用户创建脚本 ##======= ...
- Pyspark中遇到的 java.io.IOException: Not a file 和 pyspark.sql.utils.AnalysisException: 'Table or view not found
最近执行pyspark时,直接读取hive里面的数据,经常遇到几个问题: 1. java.io.IOException: Not a file —— 然而事实上文件是存在的,是 hdfs 的默认路径 ...
- python中str和byte的相互转化
在涉及到网络传输的时候,数据需要从str转换成btye才能进行传输. python byte 转 str , str 转 byte 其实很简单:原理图如下:在这里插入图片描述案例: a: str = ...
- java 获取最近7天 最近今天的日期
private static Date getDateAdd(int days){ SimpleDateFormat sf = new SimpleDateFormat("yyyy-MM-d ...