python语言(四)关键字参数、内置函数、导入第三方模块、OS模块、时间模块
一、可变参数
定义函数时,有时候我们不确定调用的时候会传递多少个参数(不传参也可以)。此时,可用包裹(packing)位置参数(*args),或者包裹关键字参数(**kwargs),来进行参数传递,会显得非常方便。
1、包裹位置传递
def send_sms(*args): # 可变参数,参数组
print('phones',args)
def say(word):
print(word)
say(word='nihao')
send_sms(110,138,119)
say('nihao')
#传入的参数是一个列表时,前面不加*号的情况下,当做一个参数值处理
#传入的参数是一个列表时,前面加*号的情况下,当做多个参数值处理

我们传进的所有参数都会被args变量收集,它会根据传进参数的位置合并为一个元组(tuple),args是元组类型,这就是包裹位置传递。
2、包裹关键字传递
kargs是一个字典(dict),收集所有关键字参数
# 关键字参数
def kwfunc(**info): # 两个星号传参数要输入key:value、key:value...
print(info)
kwfunc()
# kwfunc(age='123',name='小黑')
def t1(word,country='Chine',*args,**kwargs):
print(word)
print(country)
print(args)
print(kwargs)
t1('哈哈','Japan',138,120,name='小河',addr='北京')
这两个是Python中的可变参数。*args 表示任何多个无名参数,它是一个tuple;**kwargs 表示关键字参数,它是一个dict。并且同时使用*args和**kwargs时,必须*args参数列要在**kwargs前,像different(a=1, b='2', c=3, a', 1, None, )这样调用的话,会提示语法错误“SyntaxError: non-keyword arg after keyword arg”。
知道*args和**kwarg是什么了吧。还有一个很漂亮的用法,就是创建字典:
def kw_dict(**kwargs):
return kwargs
result = kw_dict(aa=1,bb=2,cc=3)
print(result)
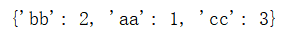
二、内置函数
input()print()len()type()str()tuple()set()dict()list()
1、sorted() 函数对所有可迭代的对象进行排序(默认升序)操作。
# 1、sorted() 排序,生成的是列表
l='dfdsafdsadafds'
sorted(l) # 排序函数
print(sorted(l))
# 对列表进行排序
print(sorted([1,2,5,30,4,22])) # [1, 2, 4, 5, 22, 30]
# 对字典进行排序
dict = {23:42,1:0,98:46,47:-28}
print( sorted(dict) ) # 只对key排序
# [1, 23, 47, 98]
print( sorted(dict.items()) ) # 默认按key进行排序
# [(1, 0), (23, 42), (47, -28), (98, 46)]
print( sorted(dict.items(),key=lambda x:x[1]) ) # 用匿名函数实现按value进行排序
# [(47, -28), (1, 0), (23, 42), (98, 46)]

2、map()帮你循环调用函数的,保存返回值,返回的是一个list。map接受一个函数名和序列
map()接收函数f和list,并通过把函数f依次作用在list的每个元素上,得到一个新的list并返回。
def inToStr(num):
return str(num).zfill(2)
l=range(1,7)
x=[1,2,3,4,5,6]
y=[1,2,3,4,5,6]
print(list(map(inToStr,l))) # 传函数名字和序列名字
print(list(map(inToStr,x)))
print(list(map(inToStr,y)))
l = [1,2,3,4,5,6,7,8,9,10]
def t(num):
if num%2 == 0:
return True
# l2 = list(filter(t,l))
l3 = list(map(t,l))
# print(l2)
print(l3)

3、filter()过滤器,帮你循环调用函数,如果函数返回false,那么就过滤掉这个值,是指从你传入这个list里面过滤
filter()用于过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象,可用list()来转换为列表。
注意: filter()接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判断,然后返回True或 False,最后将返回 True 的元素放到新列表中。
def abc(num):
if num%2==0:
return True
res2 = list(filter(abc,range(1,11)))
print(res2)
res = filter(lambda n:n>5,range(10)) # 过滤掉0-9中不符合n>5的数据
for i in res: # 循环打印符合n>5的数据
print(i)

4、max()函数返回给定参数的最大值,参数可以为序列。
print("max(10,20,30):" , max(10,20,30) )
# max(10,20,30): 30
print("max(10,-2,3.4):" , max(10,-2,3.4) )
# max(10,-2,3.4): 10
print("max({'b':2,'a':1,'c':0}):" , max({'b':2,'a':1,'c':0}) ) # 字典,默认按key排序
# max({'b':2,'a':1,'c':0}): c
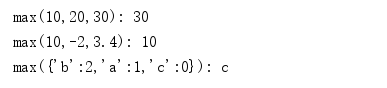
5、sum()函数对参数进行求和计算
print(sum([1,2,3,4,5])) # [15] print(sum(range(1,101))) # 1-100的和 # [5050] # [6] print( sum([1,2,3],4) ) # 列表计算总和后再加4,得到结果10 # [10] print( sum( (1,2,3),4 ) ) # 元组计算总和后再加4,得到结果10 # [10]
6、round()保留几位小数
round() 方法返回浮点数x的四舍五入值。(除非对精确度没什么要求,否则尽量避开用round()函数)
f=1.245344 print(round(f,2)) # 保留2位小数 # [1.25] print( round(4.3)) # 只有一个参数时,默认保留到整数 # [4] print( round(2.678,2)) # 保留2位小数 # [2.68] print( round(5/3,3)) # 运算表达式并保留3位小数 # [1.667]
7、chr()把数字转化成对应的ascii码表里对应的值
chr()函数用一个范围在range(256)内(即0~255)的整数作参数,返回一个对应的ASCII数值。
print(chr(65)) # [A]
8、ord()把字母转成对应的ascii码表里对应的数字
ord()函数是chr()的配对函数,它以一个字符(长度为1的字符串)作为参数,返回对应的ASCII数值,或者Unicode数值,如果所给的 Unicode 字符超出了定义范围,则会引发一个 TypeError 的异常。
print(ord('A'))
# [65]
9、dir()查看某个对象里有哪些方法
dir()函数不带参数时,返回当前范围内的变量、方法和定义的类型列表;带参数时,返回参数的属性、方法列表。
a=[] import random print(dir(a)) print(dir(random)) print( dir() ) # 获得当前模块的属性列表 # 返回:['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__'] print( dir([]) ) # 查看列表的方法 # 返回:['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', # '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__iter__', '__le__', '__len__', '__lt__', # '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', # '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', # 'sort']
10、bool()布尔类型的,返回True False
bool() 函数用于将给定参数转换为布尔类型,如果参数不为空或不为0,返回True;参数为0或没有参数,返回False。
a='jj'
b={}
c=[1,2]
d=0
print(bool(a)) # [True]
print(bool(b)) # [False]
print(bool(c)) # [True]
print(bool(d)) # [False]
11、eval()执行一些简单的Python代码,运算、定义变量
eval() 函数用来执行一个字符串表达式,并返回表达式的值。
s ='{"a":"1"}'
res = eval(s)
print(res)
# [{'a': '1'}]
12、exec()执行一些复杂的代码,exec函数没有返回值就是none
exec() 执行储存在字符串或文件中的Python语句,相比于eval,exec可以执行更复杂的Python代码。
s2 = '''
for i in range(5):
print(i)'''
print(exec(s2))
exec("for i in range(5): print('iter time is %d'%i)") # 执行复杂的for循环
# iter time is 0
# iter time is 1
# iter time is 2
# iter time is 3
# iter time is 4
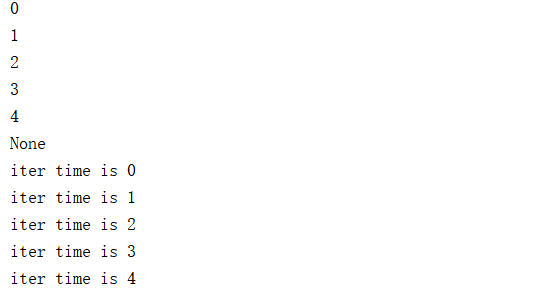
13、zip()把多个list揉到一起,把多个list变成了多维数组
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象,这样做的好处是节约了不少的内存。可以使用 list() 转换来输出列表。如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同。利用 * 号操作符,可以将元组解压为列表。
name = ['nhy','lyy','sss']
money = [22,30,40,333,4444,555]
print(list(zip(name,money)))
# [('nhy', 22), ('lyy', 30), ('sss', 40)]
a = [1,2,3]
b = [4,5,6]
c = [7,8,9,10]
for i in zip(a,b):
print(i)
# 返回结果:
# (1, 4)
# (2, 5)
# (3, 6)
print(list(zip(a,b))) # list() 转换为列表
# [(1, 4), (2, 5), (3, 6)]
print(list(zip(b,c))) # 元素个数与最短的列表一致
# [(4, 7), (5, 8), (6, 9)]
a1,a2 = zip(*zip(a,b)) # 用zip(*)解压
print(list(a1)) # [1, 2, 3]
print(list(a2)) # [4, 5, 6]
14、lambda:匿名函数,功能很简单的一个函数,用完一次就拉倒
a=lambda num:str(num).zfill(2) # 匿名函数,冒号前面是入参,冒号后面是返回值 print(a(1)) print(list(map(lambda num:str(num).zfill(2),range(1,7))))
三、导入第三方模块
<一>、模块、包
1、模块
模块实质上就是一个python文件。它是用来组织代码的,意思就是把python代码写到里面,文件名就是模块的名称,test.py test就是模块的名称
2、包
包,package本质就是一个文件夹,和文件夹不一样的是它有一个__init__.py文件。包是从逻辑上来组织模块的,也就是说它是用来存放模块的,如果想到如其他目录下的模块,那么这个目录必须是一个包才可以导入。
<二>、模块分类
1、标准模块、标准包
python自带的这些模块,直接import就能用的
import string,random,datetime,os,sys,json,hashlib
2、第三方模块
别人写好的一些模块,你要安装之后才可以用
想实现某个功能,可以先去百度搜一下有没有第三方模块
3、自己写的python文件
<三>、安装第三方模块
1、傻瓜式的
(1) 直接在命令行窗口输入命令 pip install pymysql 、pip install redis
pip在python3.4以上的版本是自带的。但这种方式需要保证pycharm中的Project Interpreter路径是Python安装路径,否则即使窗口显示下载安装成功,依然不能成功import
因为命令行下载下来的第三方安装包存储在Python安装路径\python3\Lib\site-packages
而pycharm import时,是从pycharm->File->Settings->Project Interpreter->设置的路径下\python\venv\Lib\site-packages去取第三方安装包
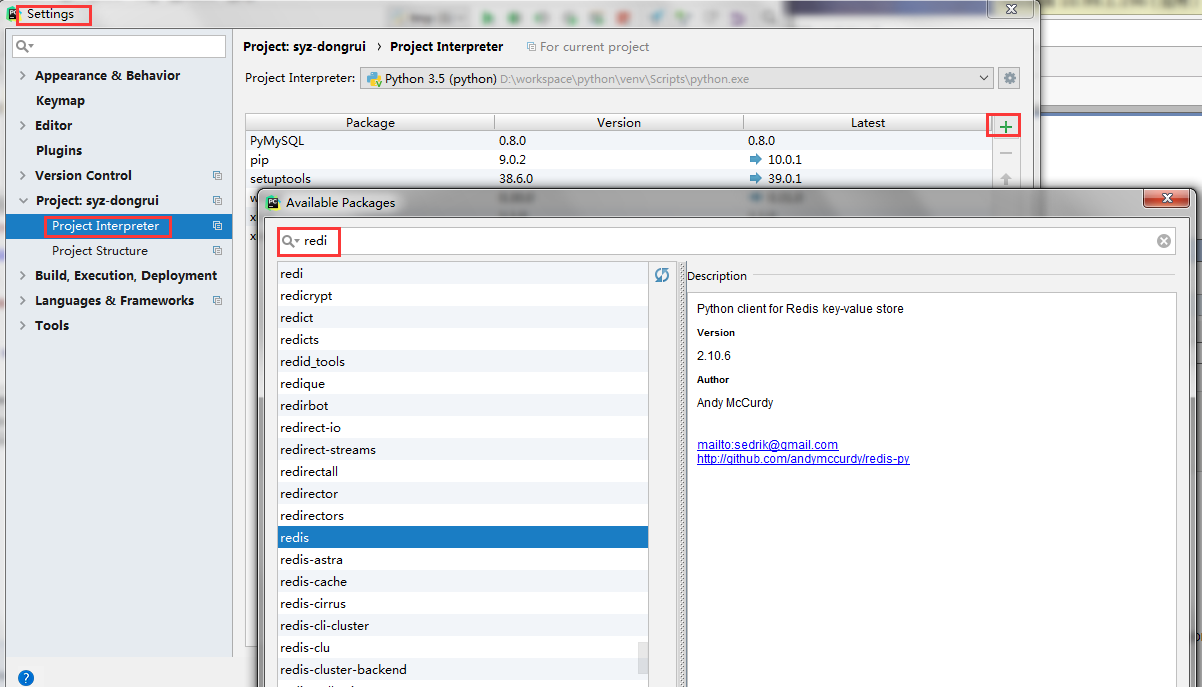
(2) 也可以直接在pycharm中安装第三方模块,这样安装的模块会放在Project Interpreter->设置的路径下\python\venv\Lib\site-packages下,就可以直接使用。
(3) 若提示pip命令不存在
输入 where pip
若提示pip不是内部命令
pycharm External Libraries
备注:python 3.5以后 scripts自动加入到计算机环境变量
没有pip命令的怎么搞
a、pycharm里面点python console
b、找到python安装目录
c、然后把安装目录下的scripts目录,加入到环境变量里面即可
ps:环境变量在PATH里面加
(4) Unknown or unsupported command 'install' 出来这个问提怎么解决
a、打开 C:\strawberry\perl\bin\
b、把这个目录下的pip 都改成其他的名字,这个对其他的没有影响
2、手动安装
限制外网无法直接下载时,可以找别人下载好包然后手动安装
(1) 百度搜索:python redis
(2) 找到网址:https://pypi.python.org/pypi/redis#downloads,下载安装包
(3) 安装whl结尾的安装包
shift+右键,在此处打开命令行窗口(或者在地址栏中直接输入cmd)
pip install redis-2.10.6-py2.py3-none-any.whl
(4) 安装tar.gz结尾的安装包
a、解压这个压缩包
b、进入到这个解压之后的文件夹里面(shift+右键,在此处打开命令行窗口(或者在地址栏中直接输入cmd))
c、在命令行里面运行 python setup.py install
3、卸载模块
pip uninstall xxx #卸载
<四>、导入模块的顺序、实质
1、python导入模块时候的顺序:
(1) 从当前目录下找需要导入的python文件
(2) 从python的环境变量中找 sys.path
2、导入模块的实质:
就是把python文件从头到尾执行一次
举个例子:
(1) 自定义一个python模块 dr.py,放在当前目录下
name = 'hello'
def my():
print('python')
my()
(2) 新建一个tmp.py
import dr #导入文件的时候已经把python文件执行了一次,打印出python print(dr.name) #打印出hello dr.my() #打印出python
上面的代码还可以用下面这种方式写
from dr import name,my #这种调用自定义函数时不用再写“文件名.函数”,直接写函数或者变量名 print(name) my()
from dr import * #导入所有的 #from aa import * my() #尽量不要用,因为看源码的时候会很难看出来函数属于哪个文件
(3) 当把dr.py放在sys.path其中一个环境变量下后,dr.就可以点出函数了
(4) 当前目录和path环境变量下都有dr.py,会优先选择当前目录下的dr.py
四、导入模块
Python 模块(Module),是一个 Python 文件,以 .py 结尾,包含了 Python 对象定义和Python语句。
模块让你能够有逻辑地组织你的 Python 代码段。
把相关的代码分配到一个模块里能让你的代码更好用,更易懂。
模块能定义函数,类和变量,模块里也能包含可执行的代码。
例子
下例是个简单的模块 support.py:
def print_func( par ):
print "Hello : ", par
return
*******************************************************
name = 'tools文件'
def test():
print('test函数')
return 'abc'
if __name__ == '__main__':
# 如果本模块被导入了,通过__name == __main__防止执行下面的代码
test()
print(name)
*******************************************************
1、import 语句
模块的引入
模块定义好后,我们可以使用 import 语句来引入模块,语法如下:
import module1[, module2[,... moduleN]]
比如要引用模块 math,就可以在文件最开始的地方用 import math 来引入。在调用 math 模块中的函数时,必须这样引用:
模块名.函数名
当解释器遇到 import 语句,如果模块在当前的搜索路径就会被导入。
搜索路径是一个解释器会先进行搜索的所有目录的列表。如想要导入模块 support.py,需要把命令放在脚本的顶端:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 导入模块
import support
# 现在可以调用模块里包含的函数了
support.print_func("Runoob")
一个模块只会被导入一次,不管你执行了多少次import。这样可以防止导入模块被一遍又一遍地执行。
# import tools # import模块的实质就是把模块从上到下执行一边
# result=tools.test()
#
# print(tools.namne)
# print('result',result)
import sys
sys.path.insert(0,r'E:\PycharmProjects\mjz\day4')
# print(sys.path)
import tools
print(tools.name)
二、from…import 语句
Python 的 from 语句让你从模块中导入一个指定的部分到当前命名空间中。语法如下:
from modname import name1[, name2[, ... nameN]]
例如,要导入模块 fib 的 fibonacci 函数,使用如下语句:
from fib import fibonacci
这个声明不会把整个 fib 模块导入到当前的命名空间中,它只会将 fib 里的 fibonacci 单个引入到执行这个声明的模块的全局符号表。
3、from…import* 语句
把一个模块的所有内容全都导入到当前的命名空间也是可行的,只需使用如下声明:
from modname import *
这提供了一个简单的方法来导入一个模块中的所有项目。然而这种声明不该被过多地使用。
例如我们想一次性引入 math 模块中所有的东西,语句如下:
from math import *
4、搜索路径
当你导入一个模块,Python 解析器对模块位置的搜索顺序是:
- 1、当前目录
- 2、如果不在当前目录,Python 则搜索在 shell 变量 PYTHONPATH 下的每个目录。
- 3、如果都找不到,Python会察看默认路径。UNIX下,默认路径一般为/usr/local/lib/python/。
模块搜索路径存储在 system 模块的 sys.path 变量中。变量里包含当前目录,PYTHONPATH和由安装过程决定的默认目录。
五、OS模块
操作系统相关的东西都在os模块里面:import os
import os
os.remove() # 删除文件
os.rename() # 重命名
os.mkdir(r'E:\besttest') # 创建文件夹,如果不指定绝对路径,在当前目录下创建;如果父目录不存在,会报错
os.makedirs(r'case/login') # 创建文件夹:makedirs父目录不存在,回创建父目录
os.path.getsize('products.json') # 获取文件大小
os.path.exists('products.json') # 判断是否存在,返回True或False
os.path.getatime('products.json') # 最近一次操作时间
os.path.getctime('products.json') # createtime
os.path.getmtime('products.json') # modifytime
os.path.split(r'E:\PycharmProjects\mjz\day4\products.json') # 分割文件路径和文件名
os.path.isfile(r'test\ly1\aaa') # 是否为文件,若文件不存在,也会返回False
os.path.isdir(r'test\ly1\aaa') # 是否为文件夹
os.path.dirname(r'test\ly1\aaa') # 取父目录
os.path.abspath('__file__') # 根据相对路径获取绝对路径 .一个点代表当前目录;..两个点代码上层目录
os.path.join('test','a.txt') # 拼接路径
os.getcwd() # 取当前路径
os.chdir() # 更改当前目录,可以写相对路径或者绝对路径 ..进入上一级目录 .代表当前目录
os.environ # 查看电脑的环境变量
os.popen('ipconfig').read() # 拿到返回的结果用popen
os.system('ipconfig') # 执行操作系统命令,返回0代表执行命令成功,1表示命令执行不成功
os.system('cale') # 执行操作系统命令
files=os.listdir(r'E:\PycharmProjects\mjz\day4') # 获取某个目录下的文件 print(files) print(os.path.isdir(r'E:\PycharmProjects\mjz\day3')) print(os.path.isfile(r'E:\PycharmProjects\mjz\day3')) os.chdir(r'E:\PycharmProjects\mjz\day3') print(os.getcwd()) # 获取当前路径

搜索目录下“.vep”格式文件
name = 'vep'
def search_file(path,name):
for cur_dir,dirs,files in os.walk(r'E:\PycharmProjects\mjz\day4'):
for file in files:
if name in file:
abs_path = cur_dir+'/'+file
print('找到%s,路径是%s' %(file,abs_path))
print(cur_dir,dirs,files)
print('==============')
search_file('/',name)

六、时间模块
time模块可以用于格式化日期和时间,时间间隔是以秒为单位的浮点小数。每个时间戳都以自从1970年1月1日午夜(历元)经过了多长时间来表示。
下面是time模块常用的一些时间格式转换的函数。时间戳可以直接比较大小。
1、时间戳
#想时间戳和格式化好的时间互相转换的话,都要先转成时间元组,然后才能转
print(time.time()) # 获取当前时间戳
# [1571581554.5838938]
print(time.strftime('%Y-%m-%d %H:%M:%S')) # 当前格式化好的时间
# [2019-10-20 22:25:54]
2、从计算机诞生那一秒到现在过了多少秒
# 1、时间戳转成时间元组 timestamp = 1571476513 time_tuple = time.localtime(timestamp) # 以当前时间时区转化 print(time_tuple) # 时间元组 # [time.struct_time(tm_year=2019, tm_mon=10, tm_mday=19, tm_hour=17, tm_min=15, tm_sec=13, tm_wday=5, tm_yday=292, tm_isdst=0)] # tm_开头的元组
# time_tuple = time.gmtime(timestamp) # 以标准时区的时间转换 默认取标准时区的时间元组,如果传入了一个时间戳,那么就把时间戳转化成时间元组
result = time.strftime('%Y-%m-%d %H:%M:%S',time_tuple) # 把时间元组转换成格式化好的时间
print(result)
# [2019-10-20 22:25:54]
def timestamp_to_str(timestamp=None,format='%Y-%m-%d %H:%M:%S'):
"""时间戳转格式化好的时间,默认返回当前时间"""
if timestamp:
time_tuple = time.localtime(timestamp) # 以当前时区的时间转换
result =time.strftime(format,time_tuple)
else:
result = time.strftime(format)
return result
# 2、时间转成时间戳
s = '2019-10-20 22:25:54'
time_tuple = time.strptime(s,'%Y-%m-%d %H:%M:%S') # 格式化好的时间,转时间元组的
result = time.mktime(time_tuple) # 把时间元组转成时间
print(result)
def str_to_timestamp(string=None,format='%Y-%m-%d %H:%M:%S'):
'''格式化好的字符串转时间戳,默认返回当前时间戳'''
if string:
time_tuple = time.strptime(string,format)
result =time.mktime(time_tuple)
else:
result = time.time()
return int(result)
# 3、获取10天后的时间 t1 = str_to_timestamp() + 60*60*24*10 result = timestamp_to_str(t1) print(result) # [2019-10-30 22:49:06]
python语言(四)关键字参数、内置函数、导入第三方模块、OS模块、时间模块的更多相关文章
- python 迭代器(一):迭代器基础(一) 语言内部使用 iter(...) 内置函数处理可迭代对象的方式
简介 在 Python 中,所有集合都可以迭代.在 Python 语言内部,迭代器用于支持: 1.for 循环2.构建和扩展集合类型3.逐行遍历文本文件4.列表推导.字典推导和集合推导5.元组拆包6. ...
- python基础12_匿名_内置函数
一个二分查找的示例: # 二分查找 示例 data = [1, 3, 6, 7, 9, 12, 14, 16, 17, 18, 20, 21, 22, 23, 30, 32, 33, 35, 36, ...
- Python学习(八) —— 内置函数和匿名函数
一.递归函数 定义:在一个函数里调用这个函数本身 递归的最大深度:997 def func(n): print(n) n += 1 func(n) func(1) 测试递归最大深度 import sy ...
- 【python】dir(__builtins__)查看python中所用BIF(内置函数)
dir(__builtins__)查看python中所用BIF(内置函数)
- python学习笔记(四):生成器、内置函数、json
一.生成器 生成器是什么?其实和list差不多,只不过list生成的时候数据已经在内存里面了,而生成器中生成的数据是当被调用时才生成呢,这样就节省了内存空间. 1. 列表生成式,在第二篇博客里面我写了 ...
- 【python基础语法】常用内置函数、关键字、方法和之间的区别(小结)
''' 关键字: False:bool数据类型 True:bool数据类型 None:表示数据的内容为空 and:逻辑运算符:与 or:逻辑运算符:或 not:逻辑运算符:非 in:身份运算符,判断变 ...
- Python学习笔记——常用的内置函数
一.yield def EricReadlines(): seek = 0 while True: with open('D:/temp.txt','r') as f: f.seek(seek) da ...
- python补充最常见的内置函数
最常见的内置函数是: print("Hello World!") 数学运算 abs(-5) # 取绝对值,也就是5 round(2. ...
- python全栈开发-Day13 内置函数
一.内置函数 注意:内置函数id()可以返回一个对象的身份,返回值为整数. 这个整数通常对应与该对象在内存中的位置,但这与python的具体实现有关,不应该作为对身份的定义,即不够精准,最精准的还是以 ...
随机推荐
- 7. Scala面向对象编程(中级部分)
7.1 包 7.1.1 看一个应用场景 现在有两个程序员共同开发一个项目,程序员xiaoming希望定义一个类取名Dog,程序员xiaohong也想定一个类也叫Dog,两个程序员还为此吵了起来,该怎么 ...
- NodeJS 使用内容以及模拟一个接口
1.结合上一篇 安装完Nodejs之后 通过手动创建一个完整的NodeJs项目 2.https://www.jianshu.com/p/7b0a5d4491ba 创建一个完整的项目之后 3.下面是一个 ...
- 【在 Nervos CKB 上做开发】Nervos CKB 脚本编程简介[4]:在 CKB 上实现 WebAssembly
作者:Xuejie 原文链接:https://xuejie.space/2019_10_09_introduction_to_ckb_script_programming_wasm_on_ckb/ N ...
- SQL系列(七)—— 相似(like)
在看like之前先了解下通配符和搜索模式: 通 配 符 ( wildcard) 用来匹配值的一部分的特殊字符. 搜索模式(search pattern) 由字面值.通配符或两者组合构成的搜索条件. 目 ...
- 打印出三位数的水仙花数Python
水仙花数计算 ...
- FindWindow和FindWindowEx函数使用
FindWindow( lpClassName, {窗口的类名} lpWindowName: PChar {窗口的标题} ): HWND; {返回窗口的 ...
- .NET CORE webapi epplus 导入导出 (实习第一个月的笔记)
最近有个需求就是网页表格里面的数据导出到excel 于是从各位前辈的博客园搜了搜demo 大部分非为两类 都是用的插件NPOI和Eppluse ,因此在这里就介绍Eppluse 用法,还有就是在博 ...
- 防止用iframe调用网页dom元素
<system.webServer> <httpProtocol> <customHeaders> <add name="X-Frame-Optio ...
- Spring Boot 的自动配置探究、自制一个starter pom
//TODO @Conditional @Condition
- C# 调用JS Eval,高效率
/// <summary> /// 动态计算表达式 /// </summary> class JSCaller { /// <summary> /// 动态计算表达 ...