特征重要度 WoE、IV、BadRate
1.IV的用途
IV的全称是Information Value,中文意思是信息价值,或者信息量。
我们在用逻辑回归、决策树等模型方法构建分类模型时,经常需要对自变量进行筛选。比如我们有200个候选自变量,通常情况下,不会直接把200个变量直接放到模型中去进行拟合训练,而是会用一些方法,从这200个自变量中挑选一些出来,放进模型,形成入模变量列表。那么我们怎么去挑选入模变量呢?
挑选入模变量过程是个比较复杂的过程,需要考虑的因素很多,比如:变量的预测能力,变量之间的相关性,变量的简单性(容易生成和使用),变量的强壮性(不容易被绕过),变量在业务上的可解释性(被挑战时可以解释的通)等等。但是,其中最主要和最直接的衡量标准是变量的预测能力。
“变量的预测能力”这个说法很笼统,很主观,非量化,在筛选变量的时候我们总不能说:“我觉得这个变量预测能力很强,所以他要进入模型”吧?我们需要一些具体的量化指标来衡量每自变量的预测能力,并根据这些量化指标的大小,来确定哪些变量进入模型。IV就是这样一种指标,他可以用来衡量自变量的预测能力。类似的指标还有信息增益、基尼系数等等。
IV表示一个变量的预测能力:
<=0.02,没有预测能力,不可用
0.02~0.1 弱预测性
0.1~0.2 有一定预测能力
0.2+高预测性
2.对IV的直观理解
从直观逻辑上大体可以这样理解“用IV去衡量变量预测能力”这件事情:我们假设在一个分类问题中,目标变量的类别有两类:Y1,Y2。对于一个待预测的个体A,要判断A属于Y1还是Y2,我们是需要一定的信息的,假设这个信息总量是I,而这些所需要的信息,就蕴含在所有的自变量C1,C2,C3,……,Cn中,那么,对于其中的一个变量Ci来说,其蕴含的信息越多,那么它对于判断A属于Y1还是Y2的贡献就越大,Ci的信息价值就越大,Ci的IV就越大,它就越应该进入到入模变量列表中。
3.IV的计算
前面我们从感性角度和逻辑层面对IV进行了解释和描述,那么回到数学层面,对于一个待评估变量,他的IV值究竟如何计算呢?为了介绍IV的计算方法,我们首先需要认识和理解另一个概念——WOE,因为IV的计算是以WOE为基础的。
3.1WOE
WOE的全称是“Weight of Evidence”,即证据权重。WOE是对原始自变量的一种编码形式。
要对一个变量进行WOE编码,需要首先把这个变量进行分组处理(也叫离散化、分箱等等,说的都是一个意思)。分组后,对于第i组,WOE的计算公式如下:
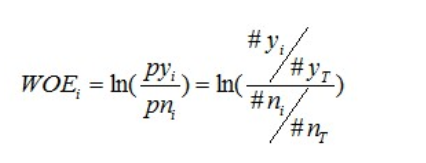
其中,pyi是这个组中响应客户(风险模型中,对应的是违约客户,总之,指的是模型中预测变量取值为“是”或者说1的个体)占所有样本中所有响应客户的比例,pni是这个组中未响应客户占样本中所有未响应客户的比例,#yi是这个组中响应客户的数量,#ni是这个组中未响应客户的数量,#yT是样本中所有响应客户的数量,#nT是样本中所有未响应客户的数量。
从这个公式中我们可以体会到,WOE表示的实际上是“当前分组中响应客户占所有响应客户的比例”和“当前分组中没有响应的客户占所有没有响应的客户的比例”的差异。
对这个公式做一个简单变换,可以得到:
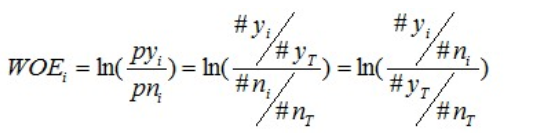
变换以后我们可以看出,WOE也可以这么理解,他表示的是当前这个组中响应的客户和未响应客户的比值,和所有样本中这个比值的差异。这个差异是用这两个比值的比值,再取对数来表示的。WOE越大,这种差异越大,这个分组里的样本响应的可能性就越大,WOE越小,差异越小,这个分组里的样本响应的可能性就越小。
关于WOE编码所表示的意义,大家可以自己再好好体会一下。
3.2 IV的计算公式
有了前面的介绍,我们可以正式给出IV的计算公式。对于一个分组后的变量,第i 组的WOE前面已经介绍过,是这样计算的:
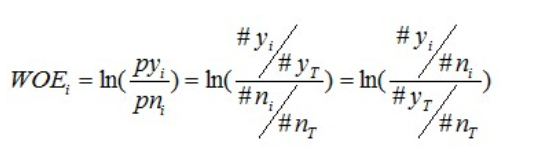
同样,对于分组i,也会有一个对应的IV值,计算公式如下:

有了一个变量各分组的IV值,我们就可以计算整个变量的IV值,方法很简单,就是把各分组的IV相加:
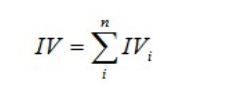
其中,n为变量分组个数。
原文链接:https://blog.csdn.net/kevin7658/article/details/50780391
==========================================
评分卡模型之特征工程中的BadRate单调与特征分箱之间的联系
Bad Rate:
坏样本率,指的是将特征进行分箱之后,每个bin下的样本所统计得到的坏样本率
bad rate 单调性与不同的特征场景:
在评分卡模型中,对于比较严格的评分模型,会要求连续性变量和有序性的变量在经过分箱后需要保证bad rate的单调性。
1. 连续性变量:
在严格的评分卡模型中,对于连续型变量就需要满足分箱后 所有的bin的 bad rate 要满足单调性,只有满足单调新的情况下,才能进行后续的WOE编码
2. 离散型变量:
离散化程度高,且无序的变量:
比如省份,职业等,我们会根据每个省份信息统计得到bad rate 数值对原始省份信息进行编码,这样就转化为了连续性变 量,进行后续的分箱操作,对于经过bad rate编码后的特征数据,天然单调。
只有当分箱后的所有的bin的bad rate 呈现单调性,才可以进行下一步的WOE编码
离散化程度低,且无序的变量:
比如婚姻状况,只有四五个状态值,因此就不需要专门进行bad rate数值编码,只要求出每个离散值对应的bin的bad rate比例是否出现0或者1的情况,若出现说明正负样本的分布存在极端情况,需要对该bin与其他bin进行合并, 合并过程完了之后 就可以直接进行后续的WOE编码
有序的离散变量:
对于学历这种情况,存在着小学,初中,高中,本科,硕士,博士等几种情况,而且从业务角度来说 这些离散值是有序的, 因此我们在分箱的时候,必须保证bin之间的有序性,再根据bad rate 是否为0 或者1的情况 决定是否进行合并,最终将合并的结果进行WOE编码
因此bad rate单调性只在连续性数值变量和有序性离散变量分箱的过程中会考虑。
bad rate要求单调性的原因分析:
1. 逻辑回归模型本身不要求特征对目标变量的单调性。之所以要求分箱后单调,主要是从业务角度考虑,解释、使用起来方便一点。如果有某个(分箱后的)特征对目标变量不单调,会加剧模型解释型的复杂化
2. 对于像年龄这种特征,其对目标变量往往是一个U型或倒U型的分布,有些公司/部门/团队是允许变量的bad rate呈(倒)U型的。
原文链接:https://blog.csdn.net/shenxiaoming77/article/details/79548807
特征重要度 WoE、IV、BadRate的更多相关文章
- 使用同一个目的port的p2p协议传输的tcp流特征相似度计算
结论: (1)使用同一个目的port的p2p协议传输的tcp流特征相似度高达99%.如果他们是cc通信,那么应该都算在一起,反之就都不是cc通信流. (2)使用不同目的端口的p2p协议传输的tcp流相 ...
- 特征工程中的IV和WOE详解
1.IV的用途 IV的全称是Information Value,中文意思是信息价值,或者信息量. 我们在用逻辑回归.决策树等模型方法构建分类模型时,经常需要对自变量进行筛选.比如我们有200个候选自变 ...
- 【转】风控中的特征评价指标(一)——IV和WOE
转自:https://zhuanlan.zhihu.com/p/78809853 1.IV值的用途 IV,即信息价值(Information Value),也称信息量. 目前还只是在对LR建模时用到过 ...
- 评分卡模型剖析之一(woe、IV、ROC、信息熵)
信用评分卡模型在国外是一种成熟的预测方法,尤其在信用风险评估以及金融风险控制领域更是得到了比较广泛的使用,其原理是将模型变量WOE编码方式离散化之后运用logistic回归模型进行的一种二分类变量的广 ...
- 笔记+R︱风控模型中变量粗筛(随机森林party包)+细筛(woe包)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 本内容来源于CDA-DSC课程内容,原内容为& ...
- 模型稳定度指标PSI与IV
由于模型是以特定时期的样本所开发的,此模型是否适用于开发样本之外的族群,必须经过稳定性测试才能得知.稳定度指标(population stability index ,PSI)可衡量测试样本及模型开发 ...
- 对数据集进行最优分箱和WOE转换
对数据集分箱的方式三种,等宽等频最优,下面介绍对数据集进行最优分箱,分箱的其他介绍可以查看其他的博文,具体在这就不细说了: 大体步骤: 加载数据: 遍历所有的feature, 分别处理离散和连续特征: ...
- 使用sklearn做单机特征工程
目录 1 特征工程是什么?2 数据预处理 2.1 无量纲化 2.1.1 标准化 2.1.2 区间缩放法 2.1.3 标准化与归一化的区别 2.2 对定量特征二值化 2.3 对定性特征哑编码 2.4 缺 ...
- 【转】使用sklearn做单机特征工程
这里是原文 说明:这是我用Markdown编辑的第一篇随笔 目录 1 特征工程是什么? 2 数据预处理 2.1 无量纲化 2.1.1 标准化 2.1.2 区间缩放法 2.1.3 无量纲化与正则化的区别 ...
随机推荐
- 4.kafka API producer
1.Producer流程首先构建待发送的消息对象ProducerRecord,然后调用KafkaProducer.send方法进行发送.KafkaProducer接收到消息后首先对其进行序列化,然后结 ...
- (备忘)cron表达式的用法
一.结构 cron表达式用于配置cronTrigger的实例,实现任务调度的功能. Cron表达式是一个字符串,字符串以5或6个空格隔开,分为6或7个域,每一个域代表一个含义,Cron有如下两种语法格 ...
- web中cookie和session_转
转自:Python爬虫番外篇之Cookie和Session python修行路 关于cookie和session估计很多程序员面试的时候都会被问到,这两个概念在写web以及爬虫中都会涉及,并且两者可 ...
- Linux系统运维相关的面试题 (问答题)
这里给大家整理了一些Linux系统运维相关的面试题,有些问题没有标准答案,希望要去参加Linux运维面试的朋友,可以先思考下这些问题. 一.Linux操作系统知识 1.常见的Linux发行版本都有 ...
- Linux下安装zookeeper和启动
原文:https://yq.aliyun.com/articles/662422 1.zookeeper官网下载安装包http://mirrors.hust.edu.cn/apache/zookeep ...
- 《奋斗吧!菜鸟》 第九次作业:Beta冲刺 Scrum meeting 3
项目 内容 这个作业属于哪个课程 任课教师链接 作业要求 https://www.cnblogs.com/nwnu-daizh/p/11012922.html 团队名称 奋斗吧!菜鸟 作业学习目标 掌 ...
- used to do 与be used to doing /n.
1.used to do:表示过去的习惯性动作,过去如此,现在不再这样了.常译作“过去常常”.(过去时+动词不定式) He used to play basketball when he was yo ...
- java设计模式解析(11) Chain责任链模式
设计模式系列文章 java设计模式解析(1) Observer观察者模式 java设计模式解析(2) Proxy代理模式 java设计模式解析(3) Factory工厂模式 java设计模式解析(4) ...
- Eclipse下,Maven+JRebel安装破解手记
Java开发中,Maven已经是标配,使用JRebel能大大地提高工作效率,特别是在Web开发中,不用重启tomcat,大大地提高了工作效率. 1.前提条件 安装JDK 8 安装eclipse, ec ...
- Hi,this is May.
“山有木兮木有枝 心悦君兮君不知” 当一个现在的人正在思念过去的人,世间的一切也都会变成过去的样子. 声色的娱乐,本来就如闪电的光.击石的火.男女欢合不过埋香葬玉.赋别鹤离鸾之曲,臂膀一曲一伸的工夫罢 ...