python — 线程
1.线程基础知识
1.1 进程与线程的区别
进程:
- 创建进程 时间开销大
- 销毁进程 时间开销大
- 进程之间切换 时间开销大
线程:
线程是进程中的一部分(不能脱离进程存在),每一个进程中至少有一个线程。
开销:
线程的创建,也需要一些开销(一个存储局部变量(临时变量)的结构,记录状态)
线程的创建、销毁、切换开销远远小于进程——开销小
进程是计算机中最小的资源分配单位(进程是负责圈资源)
线程是计算机中能被CPU调度的最小单位(线程是负责执行具体代码的)
线程是由 操作系统 调度,由操作系统负责切换的。
python中的线程比较特殊,所以进程也有可能被用到
注意:一般不建议开起多个进程,但一个进程可以开起多个线程,来减小开销。
特点:
- 进程 :数据隔离 开销大 同时执行几段代码
- 线程 :数据共享 开销小 同时执行几段代码
1.2 线程的理论
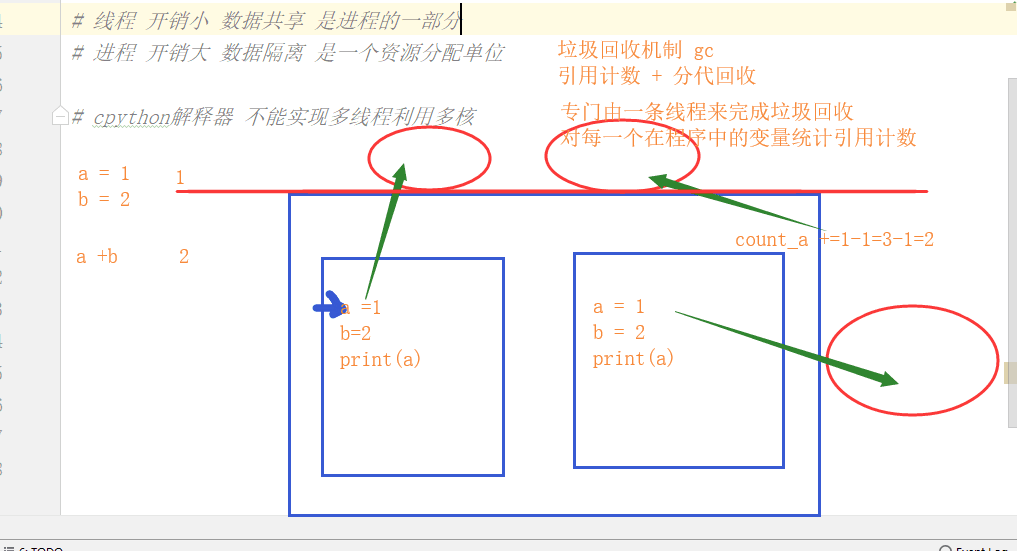
cpython解释器 — 不能实现多线程利用多核
python中垃圾回收机制 gc :引用计数 + 分代回收
专门有一条线程来完成垃圾回收,对每一个在程序中的变量统计引用计数
锁 :GIL 全局解释器锁
- 保证了整个python程序中,只能有一个线程被CPU执行
只能有一个线程被CPU执行原因:
- cpython解释器中特殊的垃圾回收机制
GIL锁导致了线程不能并行,但可以并发,所以使用多线程并不影响高io型的操作,只会对高计算型的程序有效率上的影响。
遇到高计算可以采用的方式:
- 多进程 + 多线程
- 分布式
cpython / pypy(pypython) 有垃圾回收机制,只能有一个线程被CPU执行,所以有全局解释器锁
jpython / iron python 没有垃圾回收机制,可以有多个线程被CPU执行,所以没有全局解释器锁
web框架 几乎都是多线程
总结:什么是GIL?
- 全局解释器锁
- 由Cpython解释器提供的
- 导致了一个进程中多个线程同一时刻只能有一个线程访问CPU
2 Thread 类
multiprocessing 是完全仿照这threading的类写的
创建线程有两种方式:面向函数、面向对象
线程中的几个方法:
2.1 启动线程 start
不需要写if __name__ = '__main__':
1.使用面向函数的方式启动线程
# 开启一个子线程import osimport timefrom threading import Threaddef func():print('start son thread')time.sleep(1)print('end son thread',os.getpid())Thread(target=func).start()print('start',os.getpid())time.sleep(0.5)print('end',os.getpid())# 开启多个子线程def func(i):print('start son thread',i)time.sleep(1)print('end son thread',i,os.getpid())for i in range(10):Thread(target=func,args=(i,)).start()print('main')
2.使用面向对象的方式启动线程
class MyThread(Thread):def __init__(self,i):self.i = isuper().__init__()def run(self):print('start',self.i,self.ident)time.sleep(1)print('end',self.i)for i in range(10):t = MyThread(i)t.start()print(t.ident)
t.ident 线程的id
2.2 结束进程 join
主线程什么时候结束?
- 主线程等待所有子线程结束之后才结束
- 主线程如果结束了,主进程也就结束了
join方法 阻塞 直到子线程执行结束
def func(i):print('start son thread',i)time.sleep(1)print('end son thread',i,os.getpid())t_l = []for i in range(10):t = Thread(target=func,args=(i,))t.start()t_l.append(t)for t in t_l:t.join()print('子线程执行完毕')
注意:
- terminate 结束进程
- 在线程中不能从主线程结束一个子线程
2.3 守护线程
t.daemon = True
守护线程一直等到所有的非守护线程都结束之后才结束
除了守护了主线程的代码之外也会守护子线程
非守护线程不结束,主线程也不结束;主线程结束了,主进程也结束。
结束顺序 :非守护线程结束 -->主线程结束-->主进程结束--> 守护线程也结束
import timefrom threading import Threaddef son1():while True:time.sleep(0.5)print('in son1')def son2():for i in range(5):time.sleep(1)print('in son2')t =Thread(target=son1)t.daemon = Truet.start()Thread(target=son2).start()time.sleep(3)
2.4 threading模块的函数
线程里的一些其他方法:
current_thread 在哪个线程中被调用,就返回当前线程的对象
活着的线程,包括主线程:
- enumerate 返回当前活着的线程的对象列表
- active_count 返回当前或者的线程的个数
from threading import current_thread,enumerate,active_countdef func(i):t = current_thread()print('start son thread',i,t.ident)time.sleep(1)print('end son thread',i,os.getpid())t = Thread(target=func,args=(1,))t.start()print(t.ident)print(current_thread().ident) # 水性杨花 在哪一个线程里,current_thread()得到的就是这个当前线程的信息print(enumerate())print(active_count()) # =====len(enumerate())
2.5 测试
1.进程和线程的效率都差,但线程的开启、关闭、切换效率比进程的更高。
def func(a,b):c = a+bimport timefrom multiprocessing import Processfrom threading import Threadif __name__ == '__main__':start = time.time()p_l = []for i in range(500):p = Process(target=func,args=(i,i*2))p.start()p_l.append(p)for p in p_l:p.join()print('process :',time.time() - start)start = time.time()p_l = []for i in range(500):p = Thread(target=func, args=(i, i * 2))p.start()p_l.append(p)for p in p_l: p.join()print('thread :',time.time() - start)# process : 11.76159143447876# thread : 0.12466692924499512
2.线程的数据共享的效果
from threading import Threadn = 100def func():global n # 不要在子线程里随便修改全局变量n-=1t_l = []for i in range(100):t = Thread(target=func)t_l.append(t)t.start()for t in t_l:t.join()print(n)
注意: 不要在子线程里随便修改全局变量
3 锁
线程中是不是会产生数据不安全?
即便是线程,即便有GIL,也会出现数据不安全的问题。不安全问题存在于以下几种场景:
- 1.操作的是全局变量
- 2.做以下操作:
- += -= *= /+ 先计算再赋值才容易出现数据不安全的问题
- 包括 lst[0] += 1 dic['key']-=1
- 3.多个线程对同一个文件进行写操作
a = 0def func():global aa += 1import disdis.dis(func)a = 0def add_f():global afor i in range(200000):a += 1def sub_f():global afor i in range(200000):a -= 1from threading import Threadt1 = Thread(target=add_f)t1.start()t2 = Thread(target=sub_f)t2.start()t1.join()t2.join()print(a)a = 0def func():global aa -= 1import disdis.dis(func)
加锁会影响程序的执行效率,但是保证了数据的安全。
a = 0def add_f(lock):global afor i in range(200000):with lock:a += 1def sub_f(lock):global afor i in range(200000):with lock:a -= 1from threading import Thread,Locklock = Lock()t1 = Thread(target=add_f,args=(lock,))t1.start()t2 = Thread(target=sub_f,args=(lock,))t2.start()t1.join()t2.join()print(a)
线程的锁分为:递归锁 、互斥锁
3.1 互斥锁
互斥锁:在同一个线程中,同一把锁不能连续acquire多次,开销小,产生死锁的几率大。
同一把锁acquire一次就要release一次
from threading import Locklock = Lock()lock.acquire()print('*'*20)lock.release()lock.acquire()print('-'*20)lock.release()
两把锁可以同时acquire,如
from threading import Locklock1 = Lock()lock2 = Lock()lock1.acquire()print('*'*20)lock2.acquire()print('-'*20)lock1.release()lock2.release()
3.2 递归锁
递归锁:在一个线程中,同一把锁可以连续多次acquire不会死锁,但acquire多少次就需要release多少次,开销大,一把锁永远不死锁。
from threading import RLockrlock = RLock()rlock.acquire()print('*'*20)rlock.acquire()print('-'*20)rlock.acquire()print('*'*20)
优点:在同一个线程中多次acquire也不会发生阻塞
缺点:占用了更多资源
3.3 单例模式(多线程)
import timefrom threading import Lockclass A:__instance = Nonelock = Lock()def __new__(cls, *args, **kwargs):with cls.lock:if not cls.__instance:time.sleep(0.1)cls.__instance = super().__new__(cls)return cls.__instancedef __init__(self,name,age):self.name = nameself.age = agedef func():a = A('alex', 84)print(a)from threading import Threadfor i in range(10):t = Thread(target=func)t.start()
3.4 死锁现象
<1.> 死锁现象
在某一些线程中,出现陷入阻塞并且永远无法结束阻塞的情况就是死锁现象。
<2.> 死锁现象是怎么发生的?
- 1.有多把锁(一把以上)
- 2.多把锁交替使用
- 3.互斥锁在一个线程中连续acquire
import timefrom threading import Thread,Locknoodle_lock = Lock()fork_lock = Lock()def eat1(name,noodle_lock,fork_lock):noodle_lock.acquire()print('%s抢到面了'%name)fork_lock.acquire()print('%s抢到叉子了' % name)print('%s吃了一口面'%name)time.sleep(0.1)fork_lock.release()print('%s放下叉子了' % name)noodle_lock.release()print('%s放下面了' % name)def eat2(name,noodle_lock,fork_lock):fork_lock.acquire()print('%s抢到叉子了' % name)noodle_lock.acquire()print('%s抢到面了'%name)print('%s吃了一口面'%name)time.sleep(0.1)noodle_lock.release()print('%s放下面了' % name)fork_lock.release()print('%s放下叉子了' % name)lst = ['alex','wusir','taibai','yuan']Thread(target=eat1,args=(lst[0],noodle_lock,fork_lock)).start()Thread(target=eat2,args=(lst[1],noodle_lock,fork_lock)).start()Thread(target=eat1,args=(lst[2],noodle_lock,fork_lock)).start()Thread(target=eat2,args=(lst[3],noodle_lock,fork_lock)).start()
❤️.> 如何解决死锁现象?
1.递归锁 —— 将多把互斥锁变成了一把递归锁
递归锁本质:只有一把锁
优点:快速解决问题
缺点:效率差
***递归锁也会发生死锁现象,多把锁交替使用的时候
2.优化代码逻辑
优点:
- 可以使用互斥锁解决问题
- 效率相对好
缺点:
- 解决问题的效率相对低(解决问题慢)
# 递归锁解决死锁问题import timefrom threading import RLock,Thread# noodle_lock = RLock()# fork_lock = RLock() # 错误写法noodle_lock = fork_lock = RLock()print(noodle_lock,fork_lock)def eat1(name,noodle_lock,fork_lock):noodle_lock.acquire()print('%s抢到面了'%name)fork_lock.acquire()print('%s抢到叉子了' % name)print('%s吃了一口面'%name)time.sleep(0.1)fork_lock.release()print('%s放下叉子了' % name)noodle_lock.release()print('%s放下面了' % name)def eat2(name,noodle_lock,fork_lock):fork_lock.acquire()print('%s抢到叉子了' % name)noodle_lock.acquire()print('%s抢到面了'%name)print('%s吃了一口面'%name)time.sleep(0.1)noodle_lock.release()print('%s放下面了' % name)fork_lock.release()print('%s放下叉子了' % name)lst = ['alex','wusir','taibai','yuan']Thread(target=eat1,args=(lst[0],noodle_lock,fork_lock)).start()Thread(target=eat2,args=(lst[1],noodle_lock,fork_lock)).start()Thread(target=eat1,args=(lst[2],noodle_lock,fork_lock)).start()Thread(target=eat2,args=(lst[3],noodle_lock,fork_lock)).start()
# 互斥锁解决死锁问题import timefrom threading import Lock,Threadlock = Lock()def eat1(name,noodle_lock,fork_lock):lock.acquire()print('%s抢到面了'%name)print('%s抢到叉子了' % name)print('%s吃了一口面'%name)time.sleep(0.1)print('%s放下叉子了' % name)print('%s放下面了' % name)lock.release()def eat2(name,noodle_lock,fork_lock):lock.acquire()print('%s抢到叉子了' % name)print('%s抢到面了'%name)print('%s吃了一口面'%name)time.sleep(0.1)print('%s放下面了' % name)print('%s放下叉子了' % name)lock.release()lst = ['alex','wusir','taibai','yuan']Thread(target=eat1,args=(lst[0],noodle_lock,fork_lock)).start()Thread(target=eat2,args=(lst[1],noodle_lock,fork_lock)).start()Thread(target=eat1,args=(lst[2],noodle_lock,fork_lock)).start()Thread(target=eat2,args=(lst[3],noodle_lock,fork_lock)).start()
<4.> 如何避免死锁?
在一个线程中只有一把锁,并且每一次acquire之后都要release
4 队列
线程之间的通信——线程是安全的
1.先进先出队列
写一个server,所有的用户的请求放在队列里——先来先服务的思想
import queuefrom queue import Queue # 先进先出队列q = Queue(3)q.put(0)q.put(1)q.put(2)print('22222')print(q.get())print(q.get())print(q.get())
2.后进先出队列
与算法相关的(如:递归)
from queue import LifoQueue # 后进先出队列# last in first out 栈lfq = LifoQueue(4)lfq.put(1)lfq.put(3)lfq.put(2)print(lfq.get())print(lfq.get())print(lfq.get())
3.优先级队列
优先级队列的好处:
(可以做)自动的排序
抢票的用户级别
如:vip用户在1000-10000之间,普通用户是10001-……,只要是在VIP之间的数就会比普通用户的数优先服务
告警级别
from queue import PriorityQueuepq = PriorityQueue()pq.put((10,'alex'))pq.put((6,'wusir'))pq.put((20,'yuan'))print(pq.get())print(pq.get())print(pq.get())
python — 线程的更多相关文章
- python——线程与多线程进阶
之前我们已经学会如何在代码块中创建新的线程去执行我们要同步执行的多个任务,但是线程的世界远不止如此.接下来,我们要介绍的是整个threading模块.threading基于Java的线程模型设计.锁( ...
- python——线程与多线程基础
我们之前已经初步了解了进程.线程与协程的概念,现在就来看看python的线程.下面说的都是一个进程里的故事了,暂时忘记进程和协程,先来看一个进程中的线程和多线程.这篇博客将要讲一些单线程与多线程的基础 ...
- [python] 线程简介
参考:http://www.cnblogs.com/aylin/p/5601969.html 我是搬运工,特别感谢张岩林老师! python 线程与进程简介 进程与线程的历史 我们都知道计算机是由硬件 ...
- PYTHON线程知识再研习A
前段时间看完LINUX的线程,同步,信息号之类的知识之后,再在理解PYTHON线程感觉又不一样了. 作一些测试吧. thread:模块提供了基本的线程和锁的支持 threading:提供了更高级别,功 ...
- Python 线程(threading) 进程(multiprocessing)
*:first-child { margin-top: 0 !important; } body>*:last-child { margin-bottom: 0 !important; } /* ...
- Python线程:线程的调度-守护线程
Python线程:线程的调度-守护线程 守护线程与普通线程写法上基本么啥区别,调用线程对象的方法setDaemon(true),则可以将其设置为守护线程.在python中建议使用的是thread. ...
- python 线程(一)理论部分
Python线程 进程有很多优点,它提供了多道编程,可以提高计算机CPU的利用率.既然进程这么优秀,为什么还要线程呢?其实,仔细观察就会发现进程还是有很多缺陷的. 主要体现在一下几个方面: 进程只能在 ...
- python线程同步原语--源码阅读
前面两篇文章,写了python线程同步原语的基本应用.下面这篇文章主要是通过阅读源码来了解这几个类的内部原理和是怎么协同一起工作来实现python多线程的. 相关文章链接:python同步原语--线程 ...
- Python学习——Python线程
一.线程创建 #方法一:将要执行的方法作为参数传给Thread的构造方法 import threading import time def show(arg): time.sleep(2) print ...
- Python 线程和进程和协程总结
Python 线程和进程和协程总结 线程和进程和协程 进程 进程是程序执行时的一个实例,是担当分配系统资源(CPU时间.内存等)的基本单位: 进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其 ...
随机推荐
- git工作总结
一.简单介绍 简介:Git是一个开源的分布式版本控制系统,可以有效.高速地处理项目版本管理. 发展史:CSV -> SVN -> Git 优点:Git速度快.开源.完全分布式管理系统 相关 ...
- SQL学习笔记(一)
逻辑删除 所谓的逻辑删除其实并不是真正的删除,而是在表中将对应的是否删除标识或者字段做修改操作.在逻辑上数据是被删除的,但数据本身依然存在库中 例如 update students3 set isde ...
- Linux tar: Cannot change ownership to [..]: Permission denied
tar xzf $INPUT_FOLDER/archive.tar.gz --no-same-owner -C /mnt/test-nas/
- 经管/管理/团队经典电子书pdf下载
卓有有效的管理者 管理的本质 只有偏执狂才能生存 格鲁夫给经理人的第一课 影响力: 你为什么会说“是” 关键影响力:如何调动团队力量 执行 如何完成任务的学问
- MQTT教學(一):認識MQTT
http://swf.com.tw/?p=1002 本系列文章旨在補充<超圖解物聯網IoT實作入門>,採用Arduino.ESP8266和Node.js實作MQTT物聯網通訊實驗. MQT ...
- eclipse连接夜神模拟器方法
用eclipse 进行安卓开发的时候我们会遇到安卓自带的模拟器启动时间过长,反应慢等的问题,这个时候我们就希望使用别的安卓模拟器,而我自己喜欢使用夜神模拟器.1.首先我们启动eclipse 和夜神模拟 ...
- [转]【Windows小技巧】批量重命名文件
注:如果文件名包含空格,命令应写成ren "s0 (1).gif" s001.gif,简而言之,就是加上双引号!!!原因:系统将s0和(1).gif认为是两个参数,再加上后面的s0 ...
- textEdit
textEdit可以添加背景图片.渐变色.文字颜色.大小等等 <?xml version="1.0" encoding="utf-8"?> < ...
- ISO/IEC 9899:2011 条款5——5.2 环境上的考虑
5.2 环境上的考虑 5.2.1 字符集 5.2.2 字符显示语义 5.2.3 信号与中断 5.2.4 环境限制
- VPB编译日志1
1>------ 已启动全部重新生成: 项目: ZERO_CHECK, 配置: Release x64 ------1> Checking Build System1> CMake ...