TCP Socket 套接字 和 粘包问题
一、Scoket 套接字
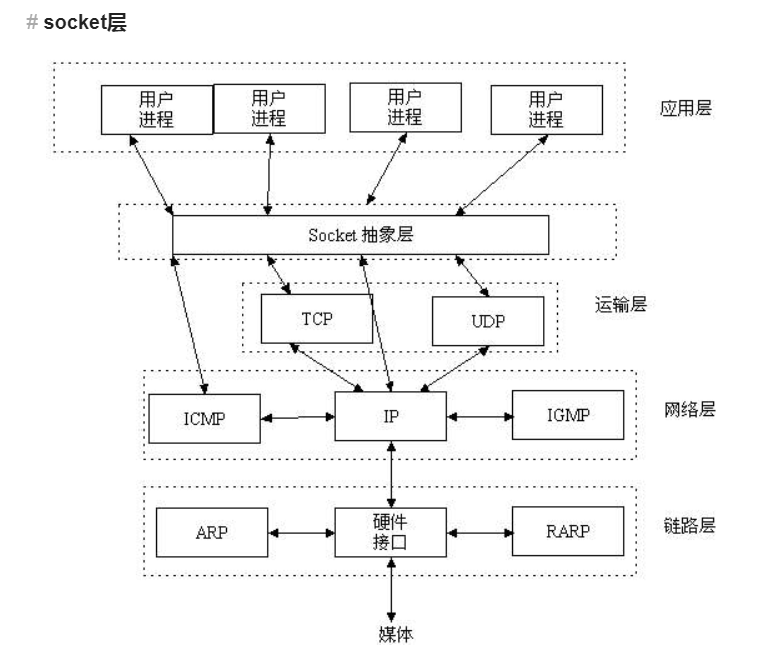
Scoket是应用层(应用程序)与TCP/IP协议通信的中间软件抽象层,它是一组接口。也可以理解为总共就三层:应用层,scoket抽象层,复杂的TCP/IP协议
基于TCP协议的scoket tcp是基于链接的,必须先启动服务端,然后再启动客户端去链接服务端
scoket 简单版本 send和recv是相辅相成的,必须要配对使用。recv是跟内存要数据,至于数据来源你无需考虑。
注意send和recv: send发送的数据只能是二进制数据,recv只能填写数字,表示接收数据大小 (******)
TCP特点会将数据量比较小的并且时间间隔比较短的数据一次性打包发送给对方
server端
import socket server = socket.socket() #创建一个服务端对象
server.bind(('127.0.0.1',8080)) # bind((host,port)) #绑定ip和端口
server.listen(5) 半连接 池限制客户端连接用户个数 conn, addr = server.accept() #等待数据 conn是传输通道(双向通道) addr是客户端地址
data = conn.recv(1024) #recv接收客户端传过来的数据,注意recv里面只能填数字
print(data)
conn.send(b'hello baby~') #send给客户端发送信息,二进制数据 conn.close() #关闭通道
server.close() #关闭服务端
client端
import socket client = socket.socket() #创建客户端对象
client.connect(('127.0.0.1',8080)) #连接服务端的ip和port client.send(b'hello world!') #send向服务端发送消息,二进制数据
data = client.recv(1024) #recv接收服务端的消息,recv只能接收数字,这个数字代表接收数据大小
print(data) client.close() #关闭客户端
二、解决通信循环的问题
服务端需要满足这两点:
1.要有固定的ip和port
2.24小时不间断提供服务
上面的简单版本的socket发送的信息是有限的,虽然它是满足了有固定的ip和port,但是它不是一直可以访问,所以在客户端和服务端分别写了循环,在客户端不断输入,在服务端不断接收打印。
server端 内层循环是不断接收从客户端传过来的数据 判断如果有客户端断开连接抛出异常 ConnectionRestError,然后break
import socket server = socket.socket() # 生成一个对象
server.bind(('127.0.0.1',8080)) # 绑定ip和port
server.listen(5) # 半连接池 while True:
conn, addr = server.accept() # 等到别人来 conn就类似于是双向通道
while True:
try:
data = conn.recv(1024)
print(data) # b''
if len(data) == 0:break #针对mac与linux 客户端异常退出之后 服务端不会报错 只会一直收b'',这步可写可不写
conn.send(data.upper())
except ConnectionResetError as e: #客户端异常退出错误接收
print(e)
break
conn.close()
client端
import socket client = socket.socket()
client.connect(('127.0.0.1',8080)) #连接服务端 while True:
msg = input('>>>:').encode('utf-8') #客户端输入
if len(msg) == 0:continue #判断如果输入为空,continue再一次输入
client.send(msg) #给服务端传送数据,msg必须是二进制格式数据
data = client.recv(1024) #接收服务端的传送数据
print(data)
三、TCP粘包问题
发生粘包:发送方执行发送命令(数据量过大),接收方得到的结果很可能只有一部分,在执行下次接收命令的时候又接收到之前执行的另外一部分结果,这种显现就是粘包。
官方解释会发生粘包的两种情况:
情况一:发送端需要等缓冲区满才发送出去,造成粘包(发送数据时间间隔很短,数据很小,会合到一起,产生粘包)
情况二:接收方不及时接收缓冲区的包,造成多个包接收(客户端发送了一段数据,服务端只收了一小部分,服务端下次在收的时候还是从缓冲区拿上次遗留的数据,产生粘包)
总结:粘包现在只发生在tcp协议中:
1、从表面上看,粘包问题主要是因为发送方和接收方的缓存机制、tcp协议面向流通信的特点。
2、实际上,主要还是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据造成的。
粘包的解决方案:
问题根源在于,接收端不知道发送端将要传送的字节流的长度,所以解决粘包的方法就是围绕如何让发送端在发送数据前,把要发送数据的大小让接收端知道,然后接收端来一个死循环接收所有数据。我们可以借助struct模块,这个模块可以把要发送的数据长度转换成固定长度的字节。这样客户端每次接收消息之前只要先接收这个固定长度字节的内容看一看接下来要接收的信息大小,,那么最终接收的数据只要达到这个值就停止,就能刚好不多不少的接收完整的数据。
我们还可以把struct创建的报头做成字典,把真实数据存在字典里面,然后json序列化,然后用struct将序列化后的数据长度打包。
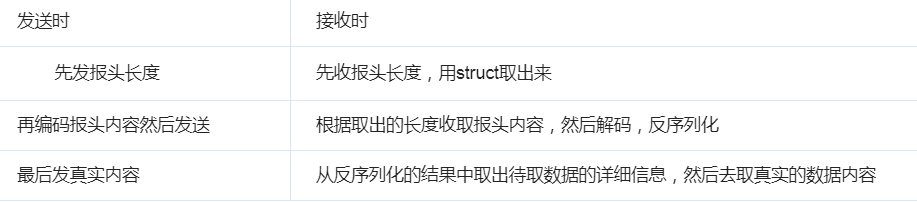
解决粘包问题思路:
服务端:
1.先制作一个发送给客户端的字典(这个字典里面包括要传输数据的大小)
2.制作字典的报头(使用struct.pack)
3.发送字典的报头
4.发送字典
5.发送真实数据
import socket
import subprocess
import struct
import json server = socket.socket() #创建一个对象
server.bind(('127.0.0.1',8080)) #绑定ip和端口
server.listen(5) #半连接池 限制请求用户个数 while True:
conn, addr = server.accept() #等待 conn是传输通道(双向通道) addr是客户端的地址
while True:
try:
cmd = conn.recv(1024) #recv(第一次接收)
if len(cmd) == 0:break #针对mac和linux客户端异常退出之后 服务端不会报错 只会一直接受 b''
cmd = cmd.decode('utf-8') #网络传输的是二进制数据,需要decode转换成字符串数据
#获取数据
obj = subprocess.Popen(cmd,shell=True,stdout=subprocess.PIPE,stderr=subprocess.PIPE)
res = obj.stdout.read() + obj.stderr.read()
d = {'name':'jason','file_size':len(res),'info':'asdhjkshasdad'}
# dumps成字符串,后面好变成二进制数据传输
json_d = json.dumps(d)
# 1.先制作一个字典的报头
header = struct.pack('i',len(json_d))
# 2.发送字典报头
conn.send(header) #send(第一次传)
# 3.发送字典
conn.send(json_d.encode('utf-8'))
# 4.再发真实数据
conn.send(res) except ConnectionResetError:
break
conn.close()
客户端:
1.先接收字典的报头
2.解析拿到字典的数据长度
3.接收字典
4.从字典中获取真实数据的长度
5.接收真实数据
import socket
import struct
import json client = socket.socket() #创建一个对象
client.connect(('127.0.0.1',8080)) #连接服务端的ip和端口 while True:
msg = input('>>>:').encode('utf-8') #客户端手动输入
if len(msg) == 0:continue #判断如果用户没有输入,返回继续让用户输入
client.send(msg) #把输入的传给服务端 send(第一次传)
# 1.先接受字典报头
header_dict = client.recv(4) # recv (第一次接受)
# 2.解析报头 获取字典的长度
dict_size = struct.unpack('i',header_dict)[0] # 解包的时候一定要加上索引0
# 3.接收字典数据
dict_bytes = client.recv(dict_size)
dict_json = json.loads(dict_bytes.decode('utf-8'))
# 4.从字典中获取信息
print(dict_json)
recv_size = 0
real_data = b''
while recv_size < dict_json.get('file_size'): # real_size = 102400
data = client.recv(1024)
real_data += data
recv_size += len(data)
print(real_data.decode('gbk'))
TCP Socket 套接字 和 粘包问题的更多相关文章
- 网络编程——TCP协议、UDP协议、socket套接字、粘包问题以及解决方法
网络编程--TCP协议.UDP协议.socket套接字.粘包问题以及解决方法 TCP协议(流式协议) 当应用程序想通过TCP协议实现远程通信时,彼此之间必须先建立双向通信通道,基于该双向通道实现数 ...
- 网络编程 TCP协议:三次握手,四次回收,反馈机制 socket套接字通信 粘包问题与解决方法
TCP协议:传输协议,基于端口工作 三次握手,四次挥手 TCP协议建立双向通道. 三次握手, 建连接: 1:客户端向服务端发送建立连接的请求 2:服务端返回收到请求的信息给客户端,并且发送往客户端建立 ...
- socket套接字及粘包问题
socket套接字 1.什么是socket socket是一个模块,又称套接字,用来封装互联网协议(应用层以下的层) 2.为什么要有socket 实现应用层以下的层的工作,提高开发效率 3.怎么使用s ...
- python开发socket套接字:粘包问题&udp套接字&socketserver
一,发生粘包 服务器端 from socket import * phone=socket(AF_INET,SOCK_STREAM) #套接字 phone.setsockopt(SOL_SOCKET, ...
- python基础--socket套接字、粘包问题
本地回环地址:127.0.0.1 简易版服务端: import socket server = socket.socket() # 就比如买了一个手机 server.bind(("127 ...
- 传输模型, tcp socket套接字
osi七层模型 tcp/ip四层模型 socket套接字 tcp 协议是可靠的 包括 三次握手 四次挥手 import socket # server server = socket.socket( ...
- day34 基于TCP和UDP的套接字方法 粘包问题 丢包问题
TCP 基于流的协议 又叫可靠性传输协议 通过三次握手 四次挥手 来保证数据传输完毕 缺点效率低 正因为是基于流的协议 所以会出现粘包问题粘包问题:原因一:是应为数据是先发送给操作系统,在操作系统中有 ...
- 基于UDP的套接字、粘包问题
一.基于UDP的套接字 UDP服务端 ss = socket() #创建一个服务器的套接字 ss.bind() #绑定服务器套接字 inf_loop: #服务器无限循环 cs = ss.recvfro ...
- python TCP socket套接字编程以及注意事项
TCPServer.py #coding:utf-8 import socket #s 等待链接 #c 实时通讯 s = socket.socket(socket.AF_INET,socket.SOC ...
随机推荐
- Ubuntu 14.04 安装python3.7
下载: https://www.python.org/ftp/python/3.7.4/ .tgz文件,解压后,进入该文件夹 编译./configuremakesudo make install 当 ...
- shell之批量新增用户脚本(http-basic-auth)
user.txt(用户名记录文件) test001@.com test002@.com user.sh(shell脚本): for line in `cat user.txt` do echo $li ...
- [技术博客] 如何避免在代码中多重render
目录 问题发现 方案1 extracted_method and return(父函数and return法) 方案2 子函数yield,父函数调用后{return} 方案3 extracted_me ...
- 自顶向下深入分析Netty(七)--ChannelPipeline和ChannelHandler总述
自顶向下深入分析Netty(七)--ChannelPipeline和ChannelHandler总述 自顶向下深入分析Netty(七)--ChannelPipeline源码实现 自顶向下深入分析Net ...
- Java编程思想之三 操作符
在底层,Java中的数据是通过使用操作符来操作的. 3.2 使用Java操作符 操作符接收一个或多个参数,并生成一个新值. 操作符作用于操作数,生成一个新值.有些操作符可能会改变操作数自身的值,这被称 ...
- enable device: BAR 0 [mem 0x00000000-0x003fffff] not claimed
/******************************************************************************* * enable device: BA ...
- Android 自己实现更新下载自动安装
1.一些公司开发完一款App之后可能并不会去上架App商店,但事后期也需要定时进行维护更新,所以会选择把打包好的apk 发布到自己的服务器,然后在数据库建一个版本号的表,然后剩下的就交给你androi ...
- C#反射方式调用泛型方法
using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; usin ...
- 基于webpack4的react开发环境配置
一.基础配置 1.init项目 mkdir react-webpack4-cook cd react-webpack4-cook mkdir src mkdir dist npm init -y 复制 ...
- (转)SpringBoot使用@Value给静态变量注入
Spring boot之@Value注解的使用总结 https://blog.csdn.net/hunan961/article/details/79206291