Efficient and Accurate Arbitrary-Shaped Text Detection with Pixel Aggregation Network(利用像素聚合网络进行高效准确的任意形状文本检测)
PSENet V2昨日刚出,今天翻译学习一下。
场景文本检测是场景文本阅读系统的重要一步,随着卷积神经网络的快速发展,场景文字检测也取得了巨大的进步。尽管如此,仍存在两个主要挑战,它们阻碍文字检测部署到现实世界的应用中。第一个问题是速度和准确性之间的平衡。第二个是对任意形状的文本实例进行建模。最近,已经提出了一些方法来处理任意形状的文本检测,但是它们很少去考虑算法的运行时间和效率,这可能在实际应用环境中受到限制。在本文中,我们提出了一种高效且准确的任意形状文本检测器,称为 PSENet V2,它配备了低计算成本的分割模块和可学习的后处理方法。
更具体地,分割模块由特征金字塔增强模块(Feature Pyramid Enhancement Module,FPEM)和特征融合模块(Feature Fusion Module,FFM)组成。FPEM 是一个可级联的 U 形模块,可以引入多级信息来指导更好的分割。FFM 可以将不同深度的 FPEM 给出的特征汇合到最终的分割特征中。可学习的后处理由像素聚合模块(Pixel Aggregation,PA)实现,其可以通过预测的相似性向量精确地聚合文本像素。几个标准基准测试的实验验证了所提出的 PSENet V2 的优越性。值得注意的是,我们的方法可以在 CTW1500 上以 84.2 FPS 实现 79.9%的 F-measure。据我们所知,PSENet V2 是第一种能够实时检测任意形状文本实例的方法。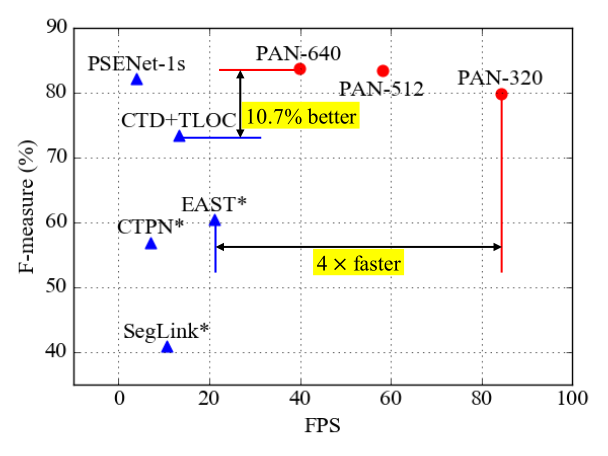
Figure 1. The performance and speed on curved text dataset CTW1500. PAN-640 is 10.7% better than CTD+TLOC, and PAN-320 is 4 times faster than EAST.
1.介绍
前面的一些介绍省略,看PAN:

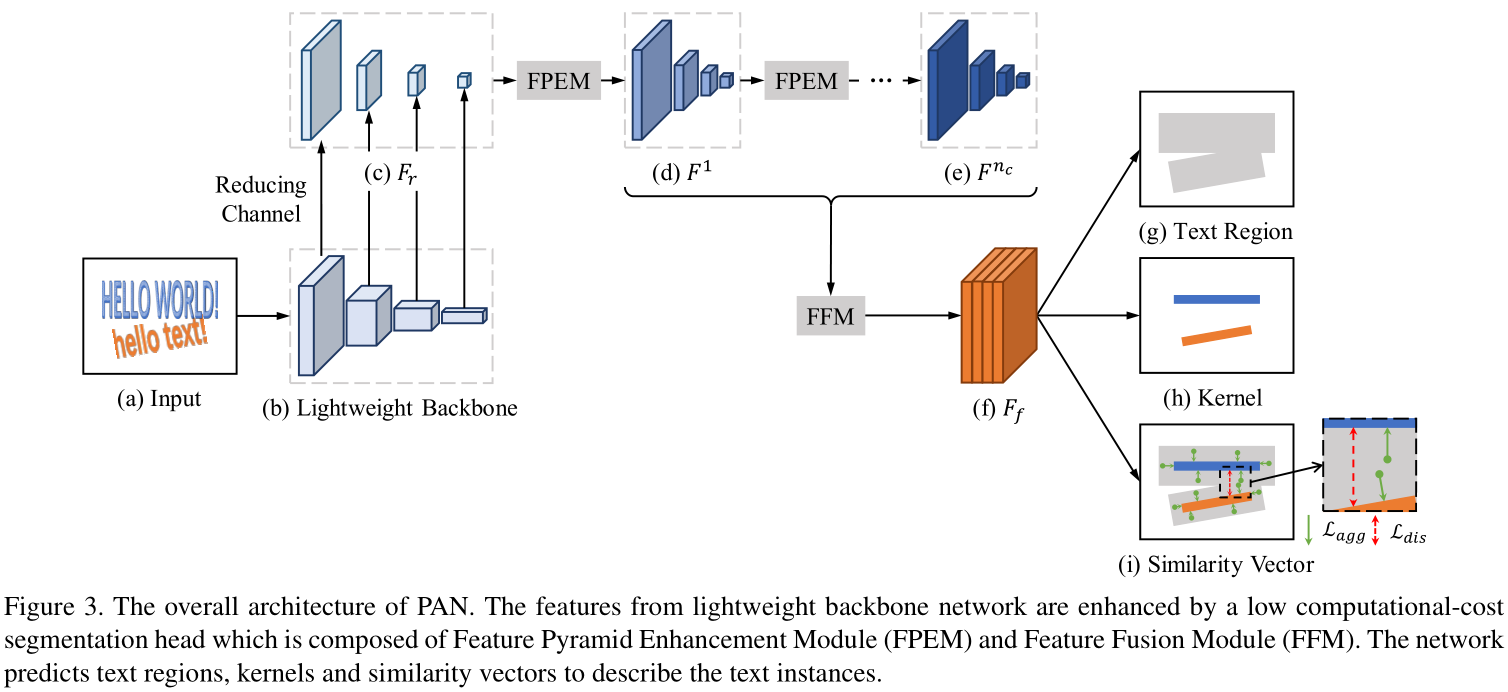
作者说提出一个任意形状的文本检测器,namely Pixel Aggression Network(像素聚合网络 ,PAN),可以平衡速度与性能。如图2所示,只有两步:1)通过分割网络预测文本区域, 内核和相似性向量. 2) 从预测的内核重建完整的文本实例. 为了实现高效性, 需要缩减这两个步骤的计算时间. 首先,分割需要轻量级主干. 文章使用ResNet18作为PAN的主干网络. 然而该轻量级主干在特征提取方面相对虚弱,因此因此,它的特征通常具有较小的感受域和较弱的表示能力。为了弥补这一缺陷,作者提出了一种低计算成本的分割主体, 包括两个模块: 特征金字塔增强模块(FPEM)和特征金字塔融合模块(FFM). FPEM是一个由可分离卷积层构建成的U型模块, 如图4.
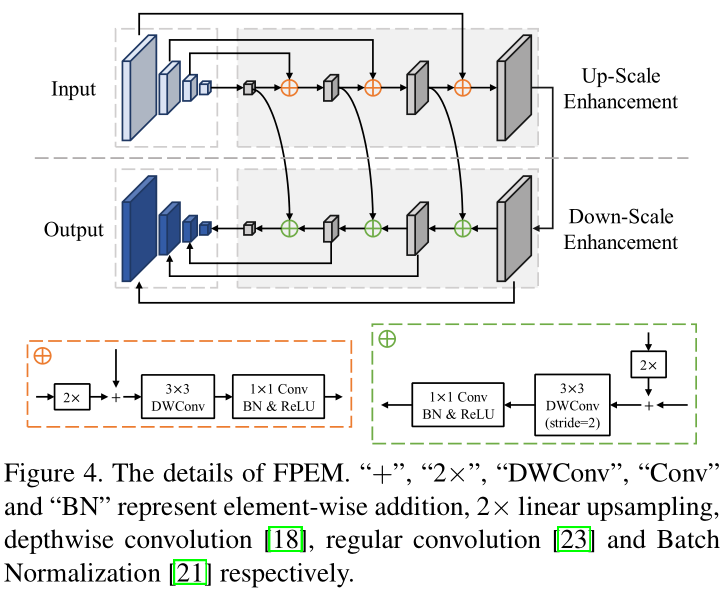
所以, FPEM能够以最小计算开销,通过融合高层和低层信息来增强不同尺度的特征.另外,FPEM是级联的,这允许我们通过在其后附加FPEM来补偿轻量级主干的深度. 见图3.
为了聚合高级和低级语义信息, 文章在最终分割前, 引入FFM来融合由不同深度的FPEM生成的特征. 此外, 为了准确重建完整的文本实例, 作者提出了一个可学习的后处理方法, 即像素聚合( Pixel Aggregation (PA)), 改方法可以通过预测的相似性向量引导文本像素来校正内核。
文章为了证明PAN的有效性, 在四个基准数据集上进行了扩展实验, 这四个基准数据集是: CTW1500 , Total-Text , ICDAR 2015 and MSRA-TD500. 其中, CTW1500 , Total-Text 是为弯曲文本检测设计的新数据集.
总之呢, 作者说此文的贡献是三倍的. 首先, 提出了一个轻量级的segmentation neck,由特征金字塔增强模块(FPEM)和特征融合模块(FFM)组成,它们是两个可以改善网络特征表示的高效模块; 其次, 文章提出像素聚合, 其中文本相似性向量可以由网络学习并且用于选择性地聚合文本内核附近的像素。最后, 文章提出的方法可以在两个弯曲的文本基准测试中实现最先进的性能,同时仍然保持58 FPS的预测速度。
最后, 作者说, 迄今为止他们提出的这一算法是第一个可以实现实时准确检测弯曲文本的算法.
2.相关工作
这一部分略读.
基于深度学习的文本识别主要有两种方法: anchor-based methods和 anchor-free methods, 大致上, 前者受目标检测启发, 用到诸如Faster R-CNN, SSD等目标检测算法;后者将文本检测视为文本分割问题来处理,用到FCN等(语义)分割算法. 描述过于笼统和片面, 有兴趣可详细关注一下该历史.
3.本文算法
3.1 整体架构
特征聚合网络PAN遵循基于分割的pipeline去检测任意形状的文本实例, 见图2. 为了实现高效性, 分割网络的主干必须是轻量级的. 然而轻量级主干能够提供的特征往往具有较小的感受域和较弱的表示能力。鉴于此,作者提出能够通过有效计算来细化特征的segmentation head。包括两个模块:特征金字塔增强模块FPEM和特征融合模块FFM 分别见图3 和图4。FPEM是级联结构,如前所述,它能以最小计算开销,通过融合高层和低层信息来增强不同尺度的特征.另外,FPEM是级联的,这允许我们通过在其后附加FPEM来补偿轻量级主干的深度。然后,引入FFM来融合由不同深度的FPEM生成的特征。
如图3的g所示,像素聚合网络PAN预测文本区域,以描述文本实例的完整形状,并且预测kernels来区分不同的文本实例(如图3的h所示)。PAN也为每一个像素提供相似度向量(如图3的i)。so that 像素的相似度向量和来自同一文本的kernel之间的距离是很小的.
图3 展示了PAN的整体框架.作者使用轻量级模型ResNet-18作为PAN的主干网络.卷积层的2,3,4,5层的卷积阶段分别产生四个特征图, 注意, 这四步卷积操作对应于输入图片,分别采用4, 8, 16, 32的卷积步长. 作者使用1*1卷积将每个特征图的通道数减少到128,同时获取到一个薄(thin)的特征金字塔Fr. 该特征金字塔通过nc级联的FPEMs得以增强. 每一个 FPEM都产生一个增强的特征金字塔, 所以会有F1, F2, ......, Fnc个增强的特征金字塔. 特征融合模块FFM将这nc个增强的特征金字塔融合为一个特征图Ff, 其步长为4个pixels, 通道数为512. Ff用于预测文本区域, 内核kernels, 和相似度向量. 最后呢, 作者使用一个简单高效的后处理算法来获得最后的文本实例.
3.2 特征金字塔增强模块FPEM
如图4, FPEM是一个u型模块. 包括两个阶段, 上采样增强和下采样增强. 上采样增强作用于输入特征金字塔, 在这一阶段, FPEM在具有32,16,8,4像素的步长的特征图上迭代地执行增强。在下采样阶段, 输入是通过放大增强产生的特征金字塔,并且下采样增强从4步到32步进行实施。
同时, 下采样增强阶段的输出特征金字塔是FPEM的最终输出结果. 作者使用了分离的卷积(3*3深度的卷积后跟1*1投影)而不是常规卷积去构建FPEM的连接部分(见图4虚线部分). 因此, 因此,FPEM能够以较小的计算开销扩大感受野(3×3深度卷积)和加深网络(1×1卷积)。
类似于特征金字塔网络, FPEM能够通过融合低级和高级信息来增强不同尺度的特征.此外,与FPN不同, FPEM有两外两个优势,首先,FPEM是一个级联的模块,随着级联数量nc的增加,不同尺度的特征图更加融合,特征的感知领域变得更大。其次, FPEM的计算开销很小,它建立在分离卷积的基础上, 这只需要很小的计算开销, FPEM每秒所执行的浮点运算次数(FLOPS)只有FPN的五分之一.
3.3 特征融合模块FFM
FFN用于融合不同深度的特征金字塔F1, F2, ......, Fnc, 因为对于语义分割来说, 低级语义信息和高级语义信息都是重要的. 组合这些特征金字塔的直接有效方法是对它们进行上采样和级联。然而, 但是,此方法给出的融合特征图具有较大的通道数量(4*128*nc), 这拖慢了最终预测的进度. 因此, 作者提出了其他的融合方法, 如图5所示. 首先通过逐元素增加的方法组合相应比例的特征图。 然后,对添加后的特征图进行上采样并连接成仅具有4×128个通道的最终特征图。
3.4 像素聚合PA
文本区域保持了文本实例的完整形状, 但是如图3 g, 这些紧密相关的文本区域通常是重叠的, 相反, 使用kernels可以区分文本实例(图3 h).然而, kernel并非完整的文本实例. 为了重建完整的文本实例, 需要将文本区域中的像素合并到kernel中, 作者提出了一个可学习的算法, 即像素聚合, 来引导文本像素朝向正确的内核发展。
在像素聚合阶段, 作者借鉴聚类的思路从kernel中重建完整的文本实例. 文本实例的kernel为聚类中心. 需要被聚类的样本是文本像素. 当然,为了将文本像素聚合到相应的内核,文本像素和同一文本实例的内核之间的距离应该很小。在训练阶段, 作者使用下面的聚合损失去实现这一规则.
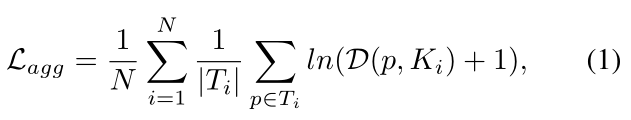
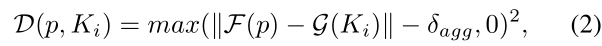
其中N是文本实例的个数,Ti是第i个文本实例, 定义了像素p和第Ti个文本实例的kernel Ki之间的距离。
定义了像素p和第Ti个文本实例的kernel Ki之间的距离。 是一个常量,根据经验设置为0.5,用于过滤容易样本。
是一个常量,根据经验设置为0.5,用于过滤容易样本。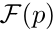 是像素p的相似度向量。
是像素p的相似度向量。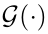 是kernel Ki的相似度向量,可以通过
是kernel Ki的相似度向量,可以通过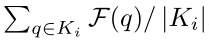 来计算。
来计算。
另外,聚类中心需要保持区分度,因此不同文本实例的kernel应该保持足够的距离。作者使用公式(3)所示的判别损失来描述数据训练过程中的这一规则:
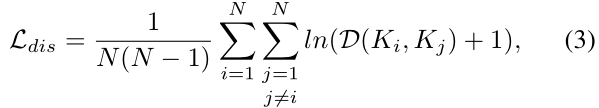
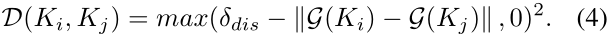
 试图保持内核之间的距离不小于
试图保持内核之间的距离不小于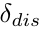 在所有实验中设置为3的距离。
在所有实验中设置为3的距离。
在测试阶段,作者使用预测到的相似性向量来引导文本区域中的像素到相应的内核。后处理步骤细节:
1)在kernel的分割结果中查找连接部分,每个连接部分都是单个kernel。
2)对于每一个kernel Ki,在预测文本区域中有条件地合并其相邻文本像素(4-way)p,而其相似向量的欧几里德距离小于d(文中经过测试设置为6).
3)重复第二步,直到没有符合条件的相邻文本像素。
3.5 损失函数
本文损失函数:
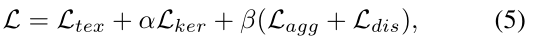
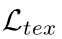 是文本区域的损失,
是文本区域的损失,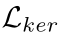 是kernel的损失,α和β用于平衡
是kernel的损失,α和β用于平衡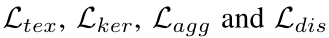 四者之间的损失,文章分别将其设置为0.5和0.25。
四者之间的损失,文章分别将其设置为0.5和0.25。
考虑到文本像素和非文本像素的极端不平衡性,作者借鉴psenet,使用dice loss去监督文本区域的分割结果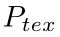 和kernels的分割结果
和kernels的分割结果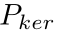 。因此,
。因此,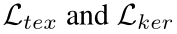 可分别用下列式子表示:
可分别用下列式子表示:
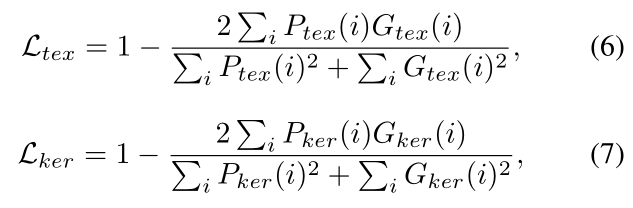
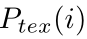 表示分割结果中第i个像素的值,
表示分割结果中第i个像素的值,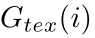 表示文本区域的ground truth。文本区域的ground truth是一个二进制图像,该二进制图像中文本像素为1 ,非文本像素为0。
表示文本区域的ground truth。文本区域的ground truth是一个二进制图像,该二进制图像中文本像素为1 ,非文本像素为0。
同样的,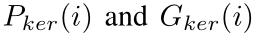 分别表示预测结果中第i个像素的值和kernels的ground truth。通过缩小ground truth多边形来生成kernels的ground truth。作者使用psenet的方法通过设置比率r缩小原始多边形。在计算
分别表示预测结果中第i个像素的值和kernels的ground truth。通过缩小ground truth多边形来生成kernels的ground truth。作者使用psenet的方法通过设置比率r缩小原始多边形。在计算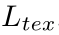 的时候,作者也使用 Online Hard Example Mining (OHEM)以忽略简单的非文本像素。在计算
的时候,作者也使用 Online Hard Example Mining (OHEM)以忽略简单的非文本像素。在计算 时,作者只考虑ground truth中的文本像素。
时,作者只考虑ground truth中的文本像素。
4. 实验
4.1 数据集
4.2 实施细节
4.3 消融研究
4.4 与 State-of-the-Art Methods作比较
4.5 结果可视化与速度分析
5. 结论
本文提出了一种有效的框架来实时检测任意形状的文本。首先介绍了一个由特征金字塔增强模块和特征融合模块组成的轻量级分割head,它有利于特征提取,同时带来一些额外的计算。 此外,提出Pixel Aggregation预测文本kernels和周围像素之间的相似性向量。这两个优点使PAN成为一种高效准确的任意形状的文本检测器。 与以前最先进的文本检测器相比,Total-Text和CTW1500的大量实验证明了其在速度和准确性方面的优势。
Efficient and Accurate Arbitrary-Shaped Text Detection with Pixel Aggregation Network(利用像素聚合网络进行高效准确的任意形状文本检测)的更多相关文章
- 【论文速读】Fangfang Wang_CVPR2018_Geometry-Aware Scene Text Detection With Instance Transformation Network
Han Hu--[ICCV2017]WordSup_Exploiting Word Annotations for Character based Text Detection 作者和代码 caffe ...
- 论文阅读(Weilin Huang——【TIP2016】Text-Attentional Convolutional Neural Network for Scene Text Detection)
Weilin Huang--[TIP2015]Text-Attentional Convolutional Neural Network for Scene Text Detection) 目录 作者 ...
- 论文阅读(Xiang Bai——【TIP2014】A Unified Framework for Multi-Oriented Text Detection and Recognition)
Xiang Bai--[TIP2014]A Unified Framework for Multi-Oriented Text Detection and Recognition 目录 作者和相关链接 ...
- 论文阅读(Zhuoyao Zhong——【aixiv2016】DeepText A Unified Framework for Text Proposal Generation and Text Detection in Natural Images)
Zhuoyao Zhong--[aixiv2016]DeepText A Unified Framework for Text Proposal Generation and Text Detecti ...
- 论文速读(Chuhui Xue——【arxiv2019】MSR_Multi-Scale Shape Regression for Scene Text Detection)
Chuhui Xue--[arxiv2019]MSR_Multi-Scale Shape Regression for Scene Text Detection 论文 Chuhui Xue--[arx ...
- 【论文速读】XiangBai_CVPR2018_Rotation-Sensitive Regression for Oriented Scene Text Detection
XiangBai_CVPR2018_Rotation-Sensitive Regression for Oriented Scene Text Detection 作者和代码 caffe代码 关键词 ...
- 论文阅读(Xiang Bai——【arXiv2016】Scene Text Detection via Holistic, Multi-Channel Prediction)
Xiang Bai--[arXiv2016]Scene Text Detection via Holistic, Multi-Channel Prediction 目录 作者和相关链接 方法概括 创新 ...
- 论文阅读(Xiang Bai——【CVPR2016】Multi-Oriented Text Detection with Fully Convolutional Networks)
Xiang Bai--[CVPR2016]Multi-Oriented Text Detection with Fully Convolutional Networks 目录 作者和相关链接 方法概括 ...
- 【论文速读】Chuhui Xue_ECCV2018_Accurate Scene Text Detection through Border Semantics Awareness and Bootstrapping
Chuhui Xue_ECCV2018_Accurate Scene Text Detection through Border Semantics Awareness and Bootstrappi ...
随机推荐
- Redis的入门
什么是NOSQL? NOSQL(Not Only SQL)不仅仅是数据库,是一种全新的理念,泛指非关系型的数据库. 为什么需要NOSQL? 随着互联网的高速崛起,网站的用户群的增加,访问量的上升,传统 ...
- ubuntu18docker下安装MySQL
sudo docker run –name mysqldb -p 3306:3306 -e MYSQL_ROOT_PASSWORD=root-d mysql:latest 这里的容器名字叫:mysql ...
- Spring,Spring MVC,Spring Boot 三者比较
Spring,Spring MVC,Spring Boot 三者比较 Spring 框架就像一个家族,有众多衍生产品例如 boot.security.jpa等等.但他们的基础都是Spring 的 io ...
- trait Monad:函数式编程类型系统本博客搜索关键字--类型升降
trait Monad:函数式编程类型系统本博客搜索关键字--类型升降
- python--简单的文件断点续传实例
一.程序说明 1.文件上传目标路径:home/file 2.目标文件:putfile.png 3.服务端代码:put_server.py 4.客户端代码:put_client.py 二.各部分代码 1 ...
- LeetCode 752. Open the Lock
原题链接在这里:https://leetcode.com/problems/open-the-lock/ 题目: You have a lock in front of you with 4 circ ...
- 在windbg调试会话中查找.NET版本
如何在调试会话中找到调试对象中使用的.NET运行时版本?以自动/脚本方式,不使用调试器扩展或符号? 答案: !for_each_module .if ( ($sicmp( "@#Module ...
- vuex传递数据的流程
当组件修改数据的时候必须通过store.dispatch来调用actions中的方法,当actions中的方法被触发的时候通过调用commit的方法来触发mutations里面的方法,mutation ...
- Centos pip 安装uwsgi 报错“fatal error: Python.h: No such file or directory”
解决方法: 安装python-devel即可,注意,不是python-dev yum -y install python-devel
- 【09NOIP提高组】Hankson 的趣味题(信息学奥赛一本通 1856)(洛谷 1072)
题目描述 Hanks 博士是BT (Bio-Tech,生物技术) 领域的知名专家,他的儿子名叫Hankson.现在,刚刚放学回家的Hankson 正在思考一个有趣的问题.今天在课堂上,老师讲解了如何求 ...