ELK + kafka 分布式日志解决方案
概述
详细
本文介绍使用ELK(elasticsearch、logstash、kibana) + kafka来搭建一个日志系统。主要演示使用spring aop进行日志收集,然后通过kafka将日志发送给logstash,logstash再将日志写入elasticsearch,这样elasticsearch就有了日志数据了,最后,则使用kibana将存放在elasticsearch中的日志数据显示出来,并且可以做实时的数据图表分析等等。
为什么用ELK
以前不用ELK的做法
最开始我些项目的时候,都习惯用log4j来把日志写到log文件中,后来项目有了高可用的要求,我们就进行了分布式部署web,这样我们还是用log4j这样的方式来记录log的话,那么就有N台机子的N个log目录,这个时候查找log起来非常麻烦,不知道问题用户出错log是写在哪一台服务器上的,后来,想到一个办法,干脆把log直接写到数据库中去,这样做,虽然解决了查找异常信息便利性的问题了,但存在两个缺陷:
1,log记录好多,表不够用啊,又得分库分表了,
2,连接db,如果是数据库异常,那边log就丢失了,那么为了解决log丢失的问题,那么还得先将log写在本地,然后等db连通了后,再将log同步到db,这样的处理办法,感觉是越搞越复杂。
现在ELK的做法
好在现在有了ELK这样的方案,可以解决以上存在的烦恼,首先是,使用elasticsearch来存储日志信息,对一般系统来说可以理解为可以存储无限条数据,因为elasticsearch有良好的扩展性,然后是有一个logstash,可以把理解为数据接口,为elasticsearch对接外面过来的log数据,它对接的渠道,有kafka,有log文件,有redis等等,足够兼容N多log形式,最后还有一个部分就是kibana,它主要用来做数据展现,log那么多数据都存放在elasticsearch中,我们得看看log是什么样子的吧,这个kibana就是为了让我们看log数据的,但还有一个更重要的功能是,可以编辑N种图表形式,什么柱状图,折线图等等,来对log数据进行直观的展现。
ELK职能分工
logstash做日志对接,接受应用系统的log,然后将其写入到elasticsearch中,logstash可以支持N种log渠道,kafka渠道写进来的、和log目录对接的方式、也可以对reids中的log数据进行监控读取,等等。
elasticsearch存储日志数据,方便的扩展特效,可以存储足够多的日志数据。
kibana则是对存放在elasticsearch中的log数据进行:数据展现、报表展现,并且是实时的。
怎样用ELK
首先说明一点,使用ELK是不需要开发的,只需要搭建环境使用即可。搭建环境,可以理解为,下载XX软件,然后配置下XX端口啊,XX地址啊,XX日志转发规则啊等等,当配置完毕后,然后点击XX bat文件,然后启动。
Logstash配置
可以配置接入N多种log渠道,现状我配置的只是接入kafka渠道。
配置文件在\logstash-2.3.4\config目录下
要配置的是如下两个参数体:
input:数据来源。
output:数据存储到哪里。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
input { kafka { zk_connect => "127.0.0.1:2181" topic_id => "mylog_topic" }}filter { #Only matched data are send to output.}output { #stdout{} # For detail config for elasticsearch as output, # See: https://www.elastic.co/guide/en/logstash/current/plugins-outputs-elasticsearch.html elasticsearch { action => "index" #The operation on ES hosts => "127.0.0.1:9200" #ElasticSearch host, can be array. index => "my_logs" #The index to write data to. }} |
Elasticsearch配置
配置文件在\elasticsearch-2.3.3\config目录下的elasticsearch.yml,可以配置允许访问的IP地址,端口等,但我这里是采取默认配置。
Kibana配置
配置文件在\kibana-4.5.4-windows\config目录下的kibana.yml,可以配置允许访问的IP地址,端口等,但我这里是采取默认配置。
这里有一个需要注意的配置,就是指定访问elasticsearch的地址。我这里是同一台机子做测试,所以也是采取默认值了。
|
1
2
|
# The Elasticsearch instance to use for all your queries.# elasticsearch.url: "http://localhost:9200" |
关于ELK的配置大致上,就这样就可以了,当然其实还有N多配置项可供配置的,具体可以google。这里就不展开说了。
具体的配置请下载运行环境,里面有具体的配置。
和spring aop日志对接
elk环境搭建完毕后,需要在应用系统做日志的aop实现。
部分spring配置
|
1
2
3
4
5
6
7
8
9
|
<aop:aspectj-autoproxy /><aop:aspectj-autoproxy proxy-target-class="true" /> <!-- 扫描web包,应用Spring的注解 --><context:component-scan base-package="com.demodashi"> <context:include-filter type="annotation" expression="org.springframework.stereotype.Controller" /> <context:exclude-filter type="annotation" expression="javax.inject.Named" /> <context:exclude-filter type="annotation" expression="javax.inject.Inject" /></context:component-scan> |
部分java代码
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
package com.demodashi.aop.annotation;import java.lang.annotation.*; /** *自定义注解 拦截service */ @Target({ElementType.PARAMETER, ElementType.METHOD}) @Retention(RetentionPolicy.RUNTIME) @Documented public @interface ServiceLogAnnotation { String description() default ""; } |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
package com.demodashi.aop.annotation;import java.lang.annotation.*; /** *自定义注解 拦截Controller */ @Target({ElementType.PARAMETER, ElementType.METHOD}) @Retention(RetentionPolicy.RUNTIME) @Documented public @interface ControllerLogAnnotation { String description() default ""; } |
代码截图
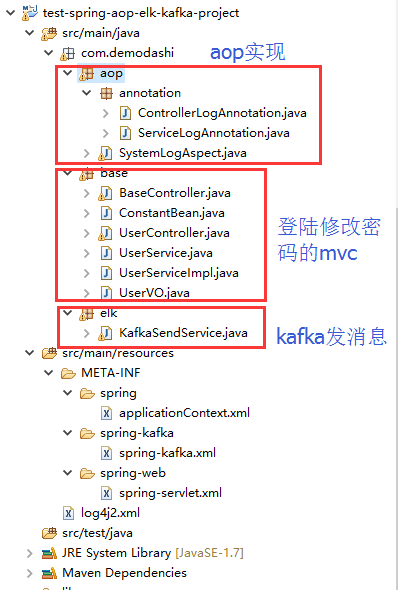
日志和kafka、和logstash、elasticsearch、kibana直接的关系
ELK,kafka、aop之间的关系
1、aop对日志进行收集,然后通过kafka发送出去,发送的时候,指定了topic(在spring配置文件中配置为 topic="mylog_topic")
2、logstash指定接手topic为 mylog_topic的kafka消息(在config目录下的配置文件中,有一个input的配置)
3、然后logstash还定义了将接收到的kafka消息,写入到索引为my_logs的库中(output中有定义)
4、再在kibana配置中,指定要连接那个elasticsearch(kibana.yml中有配置,默认为本机)
5、最后是访问kibana,在kibana的控制台中,设置要访问elasticsearch中的哪个index。
部署ELK + kafka环境
我本机的环境是jdk8.0,我记得测试的过程中,elasticsearch对jdk有特别的要求,必须是jdk7或者以上。
下载运行环境附件,并解压后,看到如下:

这些运行环境,在每个软件里面,都有具体的启动说明,如kafka的目录下,这样:
按照启动说明的命令来执行,即可启动。
这里需要说明一点,最先启动,应该是zookeeper,然后才是其他的,其他几个没有严格区分启动顺序。
直接在window下面,同一台机子启动即可。除了kibana-4.5.4-windows外,其他几个也是可以在linux下运行的。
运行效果
项目导入到eclipse后,启动,然后访问如下地址:

用户名为 1001 密码为 123
登陆后能看到如下:
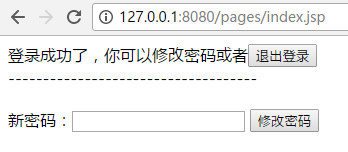
本例子是对修改密码做了日志拦截。所以修改密码的动作,能看到打印如下信息:

然后是观察一下aop日志拦截,是否被kafka发送给logstash了,是否被写入了elasticsearch了。
访问elasticsearch,http://127.0.0.1:9200/_plugin/head/ 如下:
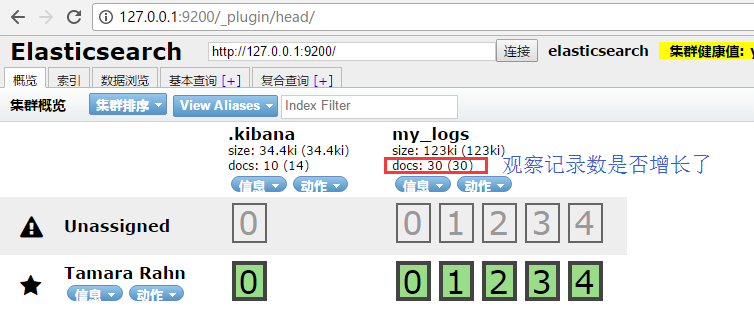
注意观察我们定义的my_logs这个索引库是否增加记录了。
访问kibana:
http://127.0.0.1:5601/app/kibana
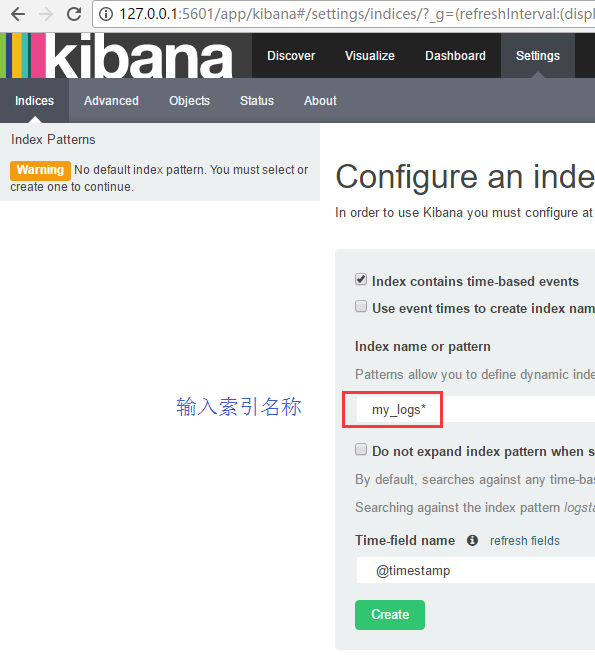
在输入索引名称后,再点击 create按钮,即可得到如下界面:
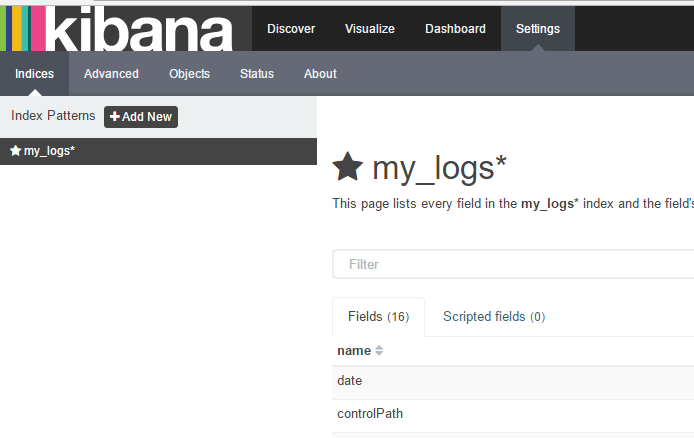
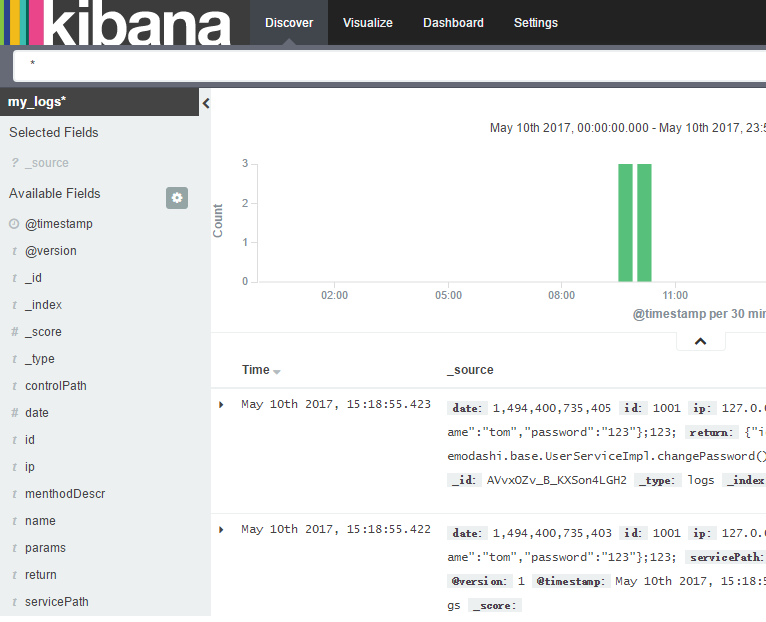
然后再点击Discover,界面如下:
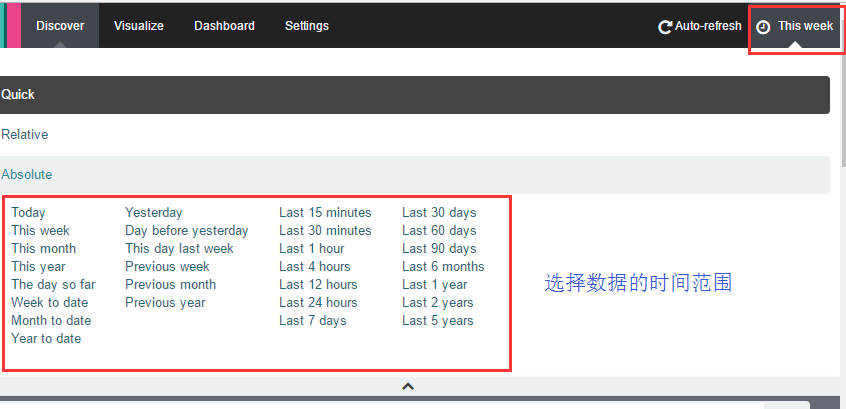
如果你看不到数据,记得点击右上角的按钮来选择数据的时间范围:
到这里就完成了,日志的AOP收集,日志的流转,并写入到elasticsearch,并用kibana看数据。
当然kibana还有很重要的一个功能是数据分析图表的配置,主要是通过向导来完成。
高可用实现
现在实现的是一个最基本的日志收集,日志传输,日志存储以及日志展示的一条链路的功能,如果系统上线,还需要做一定的集群,如kafka集群,zookeeper集群,还有elasticsearch集群
ELK + kafka 分布式日志解决方案的更多相关文章
- SpringBoot 整合 Elastic Stack 最新版本(7.14.1)分布式日志解决方案,开源微服务全栈项目【有来商城】的日志落地实践
一. 前言 日志对于一个程序的重要程度不用过多的言语修饰,本篇将以实战的方式讲述开源微服务全栈项目 有来商城 是如何整合当下主流日志解决方案 ELK +Filebeat . 话不多说,先看实现的效果图 ...
- ELK+kafka构建日志收集系统
ELK+kafka构建日志收集系统 原文 http://lx.wxqrcode.com/index.php/post/101.html 背景: 最近线上上了ELK,但是只用了一台Redis在 ...
- ELK+Kafka 企业日志收集平台(一)
背景: 最近线上上了ELK,但是只用了一台Redis在中间作为消息队列,以减轻前端es集群的压力,Redis的集群解决方案暂时没有接触过,并且Redis作为消息队列并不是它的强项:所以最近将Redis ...
- ELK +Nlog 分布式日志系统的搭建 For Windows
前言 我们为啥需要全文搜索 首先,我们来列举一下关系型数据库中的几种模糊查询 MySql : 一般情况下LIKE 模糊查询 SELECT * FROM `LhzxUsers` WHERE UserN ...
- ELK集中化日志解决方案——看这一篇全搞定
一.前言 在软件发开技术管理里有两个永恒经典的问题,适合我们初到一家软件企业或一家公司的科技团队,来判断自己该从哪里入手帮助整个团队提升科技水平和产能.问题一是"在我们团队里,只涉及一行代码 ...
- JavaWeb项目架构之Kafka分布式日志队列
架构.分布式.日志队列,标题自己都看着唬人,其实就是一个日志收集的功能,只不过中间加了一个Kafka做消息队列罢了. kafka介绍 Kafka是由Apache软件基金会开发的一个开源流处理平台,由S ...
- 利用开源架构ELK构建分布式日志系统
问题导读 1.ELK产生的背景?2.ELK的基本组成模块以及各个模块的作用?3.ELK的使用总计有哪些? 背景 日志,对每个系统来说,都是很重要,又很容易被忽视的部分.日志里记录了程序执行的关键信息, ...
- springboot集成elk实现分布式日志管理
1.安装elk https://www.cnblogs.com/xuaa/p/10769759.html 2.idea创建springboot项目 File -> New -> Proje ...
- ELK+Filebeat 集中式日志解决方案详解
链接:https://www.ibm.com/developerworks/cn/opensource/os-cn-elk-filebeat/index.html?ca=drs- ELK Stack ...
随机推荐
- net core 2 读取appsettings.json
问: .Net Core: Application startup exception: System.IO.FileNotFoundException: The configuration file ...
- Dubbo启动,调用方法失败【问题:调用超时】
今天,启动dubbo,开始写项目. 在一个调用dubbo里面的一个方法时,程序一直调用,每次显示报红. 很难搞. 问题代码 com.alibaba.dubbo.rpc.RpcException: Fa ...
- 002-Zabbix 前端配置
Zabbix 前端配置 [基于此文章的环境]点我快速打开文章 [官方地址]点我快速打开文章 第 1 步 在浏览器中,打开 Zabbix URL:http:// <server_ip_or_nam ...
- google v8
https://github.com/tongbai168/v8 https://iwebing.lofter.com/tag/chromium 编译动态库 gyp mylib.gyp --dept ...
- Maven 依赖范围 scope 属性详解
依赖范围就是用来控制依赖与三种 classpath(编译 classpath.测试 classpath.运行 classpath)的关系. 依赖范围(scope) 对于编译 classpath 有效 ...
- .NET三种异步模式(APM、EAP、TAP)
APM模式: .net 1.0时期就提出的一种异步模式,并且基于IAsyncResult接口实现BeginXXX和EndXXX类似的方法. .net中有很多类实现了该模式(比如HttpWebReque ...
- wal2json docker 试用
基于官方的release 构建了一个docker 镜像,以下是测试使用 环境准备 docker-compose 文件 version: "3" services: mypg: ...
- 数据结构——顺序队列(sequence queue)
/* sequenceQueue.c */ /* 顺序队列 */ #include <stdio.h> #include <stdlib.h> #include <std ...
- ORB-SLAM2初步(跟踪模块)
一.跟踪模块简介 在ORB-SLAM或其他SLAM系统中,跟踪的主要任务是根据相机或视频输入的图像帧实时输出相机位姿.在ORB-SLAM中,跟踪模块的主要任务是实时输出相机位姿和筛选关键帧,完成一个没 ...
- 【转】使用Hibernate的好处是什么?
一.Hibernate是JDBC的轻量级的对象封装,它是一个独立的对象持久层框架,和App Server,和EJB没有什么必然的联系.Hibernate可以用在任何JDBC可以使用的场合,例如Java ...