leetcode 学习心得 (4)
645. Set Mismatch
The set S originally contains numbers from 1 to n. But unfortunately, due to the data error, one of the numbers in the set got duplicated to another number in the set, which results in repetition of one number and loss of another number.
Given an array nums representing the data status of this set after the error. Your task is to firstly find the number occurs twice and then find the number that is missing. Return them in the form of an array.
Example 1:
Input: nums = [1,2,2,4]
Output: [2,3]
Note:
- The given array size will in the range [2, 10000].
- The given array's numbers won't have any order.
解题思路:
1. 将出现过的数字所对应数组中位置上的数字改写为负数,如果第二次访问到一个负数,说明当前位置对应的数字出现重复。
2. 顺序遍历数组,如果某个位置上的数不为负数,说明这个数字不存在。
刷题记录:
1. 一刷,使用比较复杂的方法做的,而且出现BUG
class Solution {
public:
vector<int> findErrorNums(vector<int>& nums) {
vector<int> ret(, );
for (int num : nums) {
if (nums[abs(num) - ] < ) {
ret[] = abs(num);
} else {
nums[abs(num) - ] = -nums[abs(num) - ];
}
}
for (int i = ; i < nums.size(); i++) {
if (nums[i] > ) {
ret[] = i + ;
break;
}
}
return ret;
}
};
646. Maximum Length of Pair Chain
You are given n pairs of numbers. In every pair, the first number is always smaller than the second number.
Now, we define a pair (c, d) can follow another pair (a, b) if and only if b < c. Chain of pairs can be formed in this fashion.
Given a set of pairs, find the length longest chain which can be formed. You needn't use up all the given pairs. You can select pairs in any order.
Example 1:
Input: [[1,2], [2,3], [3,4]]
Output: 2
Explanation: The longest chain is [1,2] -> [3,4]
Note:
- The number of given pairs will be in the range [1, 1000].
解题思路:
1. 思路与最长递增子序列的方式近似,不同的是在连接pair链时,需要存储的尾部数字为后部分数字,需要比较的数字为前一个数字。使用二分查找比较,最后根据high的值决定拓展长度还是更改下一链的长度。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
int findLongestChain(vector<vector<int>>& pairs) {
sort(pairs.begin(), pairs.end(), less<vector<int>>());
vector<int> minTail;
for (int i = ; i < pairs.size(); i++) {
int target = pairs[i][];
int low = , high = static_cast<int>(minTail.size()) - ;
while (low <= high) {
int mid = low + (high - low) / ;
if (target > minTail[mid]) {
low = mid + ;
} else {
high = mid - ;
}
}
if (high + < minTail.size()) {
minTail[high + ] = min(minTail[high + ], pairs[i][]);
} else {
minTail.push_back(pairs[i][]);
}
}
return minTail.size();
}
};
647. Palindromic Substrings
Given a string, your task is to count how many palindromic substrings in this string.
The substrings with different start indexes or end indexes are counted as different substrings even they consist of same characters.
Example 1:
Input: "abc"
Output: 3
Explanation: Three palindromic strings: "a", "b", "c".
Example 2:
Input: "aaa"
Output: 6
Explanation: Six palindromic strings: "a", "a", "a", "aa", "aa", "aaa".
Note:
- The input string length won't exceed 1000.
解题思路:
1. 对回文子串的中心点进行遍历,循环往两边扩展,找到以当前位置为中心的所有回文子串,注意中心点可以为某个字符,也可以为两个字符之间。
2. Manacher 算法,专门用来对求最长回文子字符串和子字符串的个数做优化。根据前面计算出的回文字符串的特性,迅速得到当前位置的信息。在每个字符之间加上'#'符号,使原字符串中所有的回文字符串在新字符串中都是以确定字符为中心。在开头和结尾加上不同的字符$ @,以防止下标溢出(可以不用下标检查,C语言中字符串以'\0'结尾,所以可以省去结尾的特殊字符)。
刷题记录:
1. 一刷 BUG FREE,但是使用动态规划方法。
class Solution {
public:
int countSubstrings(string s) {
vector<char> letter(, '$');
letter.push_back('#');
for (char a : s) {
letter.push_back(a);
letter.push_back('#');
}
letter.push_back('@');
int len = letter.size();
vector<int> length(len, );
int id = , mx = ;
for (int i = ; i < len - ; i++) {
if (length[ * id - i] < mx - i) {
length[i] = length[ * id - i];
continue;
}
length[i] = mx - i;
while (letter[i - length[i]] == letter[i + length[i]]) {
length[i]++;
}
if (i + length[i] > mx) {
id = i;
mx = i + length[i];
}
}
int count = ;
for (int i = ; i < len - ; i++) {
count += length[i] / ;
}
return count;
}
};
648. Replace Words
In English, we have a concept called root, which can be followed by some other words to form another longer word - let's call this word successor. For example, the root an, followed by other, which can form another word another.
Now, given a dictionary consisting of many roots and a sentence. You need to replace all the successor in the sentence with the root forming it. If a successor has many roots can form it, replace it with the root with the shortest length.
You need to output the sentence after the replacement.
Example 1:
Input: dict = ["cat", "bat", "rat"]
sentence = "the cattle was rattled by the battery"
Output: "the cat was rat by the bat"
Note:
- The input will only have lower-case letters.
- 1 <= dict words number <= 1000
- 1 <= sentence words number <= 1000
- 1 <= root length <= 100
- 1 <= sentence words length <= 1000
解题思路:
1. 使用Trie Tree去存储所有的前缀词,然后对sentence中的每个单词在树中查找,时间复杂度为O(N).
刷题记录:
1. 一刷,BUG FREE
class Node {
public:
Node* next[] = {NULL};
string prefix = "";
};
class Solution {
public:
string replaceWords(vector<string>& dict, string sentence) {
Node* root = new Node;
for (int i = ; i < dict.size(); i++) {
buildTrie(root, dict[i]);
}
stringstream in(sentence);
string word = "", res = "";
while (in >> word) {
res.append(find(root, word) + " ");
}
return res.substr(, (int)res.size() - );
}
void buildTrie(Node* root, string word) {
for (char a : word) {
if (!root->next[a - 'a']) {
root->next[a - 'a'] = new Node;
}
root = root->next[a - 'a'];
if (root->prefix != "") {
return;
}
}
root->prefix = word;
return;
}
string find(Node* root, string word) {
for (char a : word) {
if (!root->next[a - 'a']) {
return word;
}
root = root->next[a - 'a'];
if (root->prefix != "") {
return root->prefix;
}
}
return word;
}
};
649. Dota2 Senate
In the world of Dota2, there are two parties: the Radiant and the Dire.
The Dota2 senate consists of senators coming from two parties. Now the senate wants to make a decision about a change in the Dota2 game. The voting for this change is a round-based procedure. In each round, each senator can exercise one of the two rights:
Ban one senator's right:
A senator can make another senator lose all his rights in this and all the following rounds.Announce the victory:
If this senator found the senators who still have rights to vote are all from the same party, he can announce the victory and make the decision about the change in the game.
Given a string representing each senator's party belonging. The character 'R' and 'D' represent the Radiant party and the Dire party respectively. Then if there are n senators, the size of the given string will be n.
The round-based procedure starts from the first senator to the last senator in the given order. This procedure will last until the end of voting. All the senators who have lost their rights will be skipped during the procedure.
Suppose every senator is smart enough and will play the best strategy for his own party, you need to predict which party will finally announce the victory and make the change in the Dota2 game. The output should be Radiant or Dire.
Example 1:
Input: "RD"
Output: "Radiant"
Explanation: The first senator comes from Radiant and he can just ban the next senator's right in the round 1.
And the second senator can't exercise any rights any more since his right has been banned.
And in the round 2, the first senator can just announce the victory since he is the only guy in the senate who can vote.
Example 2:
Input: "RDD"
Output: "Dire"
Explanation:
The first senator comes from Radiant and he can just ban the next senator's right in the round 1.
And the second senator can't exercise any rights anymore since his right has been banned.
And the third senator comes from Dire and he can ban the first senator's right in the round 1.
And in the round 2, the third senator can just announce the victory since he is the only guy in the senate who can vote.
Note:
- The length of the given string will in the range [1, 10,000].
解题思路:
1. 此题是一个贪心算法问题,当一个阵营的人有机会使用权利时,最好的方式是ban掉对面阵营最近拥有权利的人。可以用一个整数代表两者之间的前面拥有权利的人的数量关系,也可以使用队列。
刷题记录:
1. 一刷,BUG FREE。
class Solution {
public:
string predictPartyVictory(string senate) {
int len = senate.size();
int R = , D = ;
for (auto a : senate) {
if (a == 'R') {
R++;
} else if (a == 'D') {
D++;
}
}
int i = , balance = ;
while (R > && D > ) {
if (senate[i] == 'R') {
if (balance++ < ) {
senate[i] = '#';
R--;
}
} else if (senate[i] == 'D') {
if (balance-- > ) {
senate[i] = '#';
D--;
}
}
i++;
if (i == len) {
i = ;
}
}
return R > ? "Radiant" : "Dire";
}
};
650. 2 Keys Keyboard
Initially on a notepad only one character 'A' is present. You can perform two operations on this notepad for each step:
Copy All: You can copy all the characters present on the notepad (partial copy is not allowed).Paste: You can paste the characters which are copied last time.
Given a number n. You have to get exactly n 'A' on the notepad by performing the minimum number of steps permitted. Output the minimum number of steps to get n 'A'.
Example 1:
Input: 3
Output: 3
Explanation:
Intitally, we have one character 'A'.
In step 1, we use Copy All operation.
In step 2, we use Paste operation to get 'AA'.
In step 3, we use Paste operation to get 'AAA'.
Note:
- The
nwill be in the range [1, 1000].
解题思路:
1. 此题可以用递归解,也可以用动态规划,到某个数值的操作个数等于得到比其小的数的操作数加上粘贴复制这个数需要的次数。
2. 最好的思路是观察特征,将一个粘贴复制的次数,分解为两段粘贴复制操作,使得pq次操作转换为p+q,在p、q>1的情况下,p+q恒小于pq。所以尽量将n因子分解。
刷题记录:
1. 一刷,BUG FREE,可以用最优方法再做一遍。
class Solution {
private:
map<int, int> steps;
public:
int minSteps(int n) {
if (n == ) {
steps[] = ;
return steps[];
}
int ret = INT_MAX;
for (int k = n / ; k > ; k--) {
if (n % k) {
continue;
}
if (!steps.count(k)) {
int temp = minSteps(k);
steps[k] = temp;
}
ret = min(steps[k] + n / k, ret);
}
steps[n] = ret;
return steps[n];
}
};
652. Find Duplicate Subtrees
Given a binary tree, return all duplicate subtrees. For each kind of duplicate subtrees, you only need to return the root node of any oneof them.
Two trees are duplicate if they have the same structure with same node values.
Example 1:
1
/ \
2 3
/ / \
4 2 4
/
4
The following are two duplicate subtrees:
2
/
4
and
4
Therefore, you need to return above trees' root in the form of a list.
解题思路:
1. 将二叉树中所有的子树进行序列化,后续遍历,这样的事件负责度为O(N^2),因为要遍历所有的N个结点。在每个结点为根结点的子树的序列化创建过程中的时间复杂度为O(N)。
2. 第二种方法采用hash的方式,将左子树、根结点和右子树的unique id组成的字符串进行hash,得到unique id。根据这个数来确定是否有过相同结构的子树。由于只需要将三个数拼接在一起,所以时间复杂度为O(N)。
刷题记录:
1. 一刷,BUG FREE
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {
map<string, bool> trees;
vector<TreeNode*> ret;
serialize(root, trees, ret);
return ret;
} string serialize(TreeNode* root, map<string, bool>& trees, vector<TreeNode*>& ret) {
if (!root) {
return "#";
}
string left = serialize(root->left, trees, ret);
string right = serialize(root->right, trees, ret);
string cur = to_string(root->val);
cur.append("," + left);
cur.append("," + right);
if (trees.count(cur)) {
if (!trees[cur]) {
ret.push_back(root);
trees[cur] = true;
}
} else {
trees[cur] = false;
}
return cur;
}
};
653. Two Sum IV - Input is a BST
Given a Binary Search Tree and a target number, return true if there exist two elements in the BST such that their sum is equal to the given target.
Example 1:
Input:
5
/ \
3 6
/ \ \
2 4 7 Target = 9 Output: True
Example 2:
Input:
5
/ \
3 6
/ \ \
2 4 7 Target = 28 Output: False
解题思路:
1. 将查找二叉树转换为递增的数列,然后采用two sum的方式求解,就是这个题最好的思路。
2. 其他依赖集合的数据结构,然后遍历树的方法不如以上。
刷题记录:
1. 一刷,BUG FREE
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
bool findTarget(TreeNode* root, int k) {
vector<int> nums;
preOrder(root, nums);
int low = , high = (int)nums.size() - ;
while (low < high) {
int sum = nums[low] + nums[high];
if (k == sum) {
return true;
} else if (k > sum) {
low++;
} else {
high--;
}
}
return false;
} void preOrder(TreeNode* root, vector<int>& nums) {
if (!root) {
return;
}
preOrder(root->left, nums);
nums.push_back(root->val);
preOrder(root->right, nums);
return;
}
};
654. Maximum Binary Tree
Given an integer array with no duplicates. A maximum tree building on this array is defined as follow:
- The root is the maximum number in the array.
- The left subtree is the maximum tree constructed from left part subarray divided by the maximum number.
- The right subtree is the maximum tree constructed from right part subarray divided by the maximum number.
Construct the maximum tree by the given array and output the root node of this tree.
Example 1:
Input: [3,2,1,6,0,5]
Output: return the tree root node representing the following tree: 6
/ \
3 5
\ /
2 0
\
1
Note:
- The size of the given array will be in the range [1,1000].
解题思路:
1. 递归将数组中的不同部分构成树。
刷题记录:
1. 一刷,BUG FREE
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
TreeNode* constructMaximumBinaryTree(vector<int>& nums) {
return constructHelper(nums, , (int)nums.size() - );
} TreeNode* constructHelper(vector<int>& nums, int begin, int end) {
if (begin > end) {
return NULL;
}
int maxIndex = begin;
for (int i = begin + ; i <= end; i++) {
if (nums[i] > nums[maxIndex]) {
maxIndex = i;
}
}
TreeNode* root = new TreeNode(nums[maxIndex]);
root->left = constructHelper(nums, begin, maxIndex - );
root->right = constructHelper(nums, maxIndex + , end);
return root;
}
};
655. Print Binary Tree
Print a binary tree in an m*n 2D string array following these rules:
- The row number
mshould be equal to the height of the given binary tree. - The column number
nshould always be an odd number. - The root node's value (in string format) should be put in the exactly middle of the first row it can be put. The column and the row where the root node belongs will separate the rest space into two parts (left-bottom part and right-bottom part). You should print the left subtree in the left-bottom part and print the right subtree in the right-bottom part. The left-bottom part and the right-bottom part should have the same size. Even if one subtree is none while the other is not, you don't need to print anything for the none subtree but still need to leave the space as large as that for the other subtree. However, if two subtrees are none, then you don't need to leave space for both of them.
- Each unused space should contain an empty string
"". - Print the subtrees following the same rules.
Example 1:
Input:
1
/
2
Output:
[["", "1", ""],
["2", "", ""]]
Example 2:
Input:
1
/ \
2 3
\
4
Output:
[["", "", "", "1", "", "", ""],
["", "2", "", "", "", "3", ""],
["", "", "4", "", "", "", ""]]
Example 3:
Input:
1
/ \
2 5
/
3
/
4
Output: [["", "", "", "", "", "", "", "1", "", "", "", "", "", "", ""]
["", "", "", "2", "", "", "", "", "", "", "", "5", "", "", ""]
["", "3", "", "", "", "", "", "", "", "", "", "", "", "", ""]
["4", "", "", "", "", "", "", "", "", "", "", "", "", "", ""]]
Note: The height of binary tree is in the range of [1, 10].
解题思路:
1. 首先采用层序遍历的方式得出所需存储空间的尺寸,然后递归将结点的值填入对应的位置中。注意层序遍历队列时一次循环需要将当前层的所有结点出队。
刷题记录:
1. 一刷,层序遍历出错
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
vector<vector<string>> printTree(TreeNode* root) {
if (!root) {
return vector<vector<string>>(, vector<string>(, ""));
}
int m = , n = ;
queue<TreeNode*> node;
node.push(root);
while (!node.empty()) {
m++;
n = * n + ;
int len = node.size();
for (int i = ; i < len; i++) {
TreeNode* p = node.front();
if (p->left) {
node.push(p->left);
}
if (p->right) {
node.push(p->right);
}
node.pop();
}
}
vector<vector<string>> ret(m, vector<string>(n, ""));
fillHelper(root, ret, , , n - );
return ret;
} void fillHelper(TreeNode* root, vector<vector<string>>& ret, int row, int begin, int end) {
int mid = begin + (end - begin) / ;
ret[row][mid] = to_string(root->val);
if (root->left) {
fillHelper(root->left, ret, row + , begin, mid - );
}
if (root->right) {
fillHelper(root->right, ret, row + , mid + , end);
}
return;
}
};
657. Judge Route Circle
Initially, there is a Robot at position (0, 0). Given a sequence of its moves, judge if this robot makes a circle, which means it moves back to the original place.
The move sequence is represented by a string. And each move is represent by a character. The valid robot moves are R (Right), L(Left), U (Up) and D (down). The output should be true or false representing whether the robot makes a circle.
Example 1:
Input: "UD"
Output: true
Example 2:
Input: "LL"
Output: false
解题思路:
1. 回到原点的充分必要条件是向上和向下走的次数一样,向左和向右走的次数一样。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
bool judgeCircle(string moves) {
int vertical = , horizen = ;
for (char a : moves) {
switch (a) {
case 'U':
vertical++;
break;
case 'D':
vertical--;
break;
case 'L':
horizen--;
break;
case 'R':
horizen++;
break;
default:
break;
}
}
return vertical == && horizen == ;
}
};
658. Find K Closest Elements
Given a sorted array, two integers k and x, find the k closest elements to x in the array. The result should also be sorted in ascending order. If there is a tie, the smaller elements are always preferred.
Example 1:
Input: [1,2,3,4,5], k=4, x=3
Output: [1,2,3,4]
Example 2:
Input: [1,2,3,4,5], k=4, x=-1
Output: [1,2,3,4]
Note:
- The value k is positive and will always be smaller than the length of the sorted array.
- Length of the given array is positive and will not exceed 104
- Absolute value of elements in the array and x will not exceed 104
解题思路:
1. 使用二分查找找到最接近于目标数的数在数组中的位置,然后使用左右指针找到离它最近的k个数。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
vector<int> findClosestElements(vector<int>& arr, int k, int x) {
vector<int> ret;
int len = arr.size();
int low = , high = len - , mid;
while (low <= high) {
mid = low + (high - low) / ;
if (arr[mid] == x) {
break;
} else if (arr[mid] < x) {
low = mid + ;
} else {
high = mid - ;
}
}
if (arr[mid] == x) {
high = mid;
low = mid - ;
} else {
swap(low, high);
}
for (int i = ; i < k; i++) {
int left = low >= ? x - arr[low] : INT_MAX;
int right = high < len ? arr[high] - x : INT_MAX;
if (left <= right) {
ret.push_back(arr[low--]);
} else {
ret.push_back(arr[high++]);
}
}
sort(ret.begin(), ret.end());
return ret;
}
};
659. Split Array into Consecutive Subsequences
You are given an integer array sorted in ascending order (may contain duplicates), you need to split them into several subsequences, where each subsequences consist of at least 3 consecutive integers. Return whether you can make such a split.
Example 1:
Input: [1,2,3,3,4,5]
Output: True
Explanation:
You can split them into two consecutive subsequences :
1, 2, 3
3, 4, 5
Example 2:
Input: [1,2,3,3,4,4,5,5]
Output: True
Explanation:
You can split them into two consecutive subsequences :
1, 2, 3, 4, 5
3, 4, 5
Example 3:
Input: [1,2,3,4,4,5]
Output: False
Note:
- The length of the input is in range of [1, 10000]
解题思路:
1. 对于每一个数,要么接在已经形成连续序列的尾部。要么重新作为序列开始。在能够接在序列尾部的情况下,比起作为开头会更灵活。统计序列中所有数的频率,然后实时记录前面的连续子序列可以接的数已经其个数。
刷题记录:
1. 一刷,没有思路。
class Solution {
public:
bool isPossible(vector<int>& nums) {
map<int, int> freq, appendNeed;
for (int num : nums) {
freq[num]++;
}
for (int num : nums) {
if (freq[num] == ) {
continue;
}
freq[num]--;
if (appendNeed[num] > ) {
appendNeed[num]--;
appendNeed[num + ]++;
} else if (freq[num + ] > && freq[num + ] > ) {
freq[num + ]--;
freq[num + ]--;
appendNeed[num + ]++;
} else {
return false;
}
}
return true;
}
};
661. Image Smoother
Given a 2D integer matrix M representing the gray scale of an image, you need to design a smoother to make the gray scale of each cell becomes the average gray scale (rounding down) of all the 8 surrounding cells and itself. If a cell has less than 8 surrounding cells, then use as many as you can.
Example 1:
Input:
[[1,1,1],
[1,0,1],
[1,1,1]]
Output:
[[0, 0, 0],
[0, 0, 0],
[0, 0, 0]]
Explanation:
For the point (0,0), (0,2), (2,0), (2,2): floor(3/4) = floor(0.75) = 0
For the point (0,1), (1,0), (1,2), (2,1): floor(5/6) = floor(0.83333333) = 0
For the point (1,1): floor(8/9) = floor(0.88888889) = 0
Note:
- The value in the given matrix is in the range of [0, 255].
- The length and width of the given matrix are in the range of [1, 150].
解题思路:
1. 对每一个元素周围的元素进行循环遍历,得到当前经过平滑后的值。可以采用将计算得到的值左移8位后与原数bit 或的方式优化存储。因为原值储存在低8位。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
vector<vector<int>> imageSmoother(vector<vector<int>>& M) {
int m = M.size(), n = M[].size();
vector<vector<int>> ret(m, vector<int>(n, ));
int row[] = {-, , }, col[] = {-, , };
for (int i = ; i < m; i++) {
for (int j = ; j < n; j++) {
int count = , sum = ;
for (int k = ; k < ; k++) {
for (int p = ; p < ; p++) {
int x = i + row[k], y = j + col[p];
if (x < || x >= m || y < || y >= n) {
continue;
}
count++;
sum += M[x][y];
}
}
ret[i][j] = sum / count;
}
}
return ret;
}
};
662. Maximum Width of Binary Tree
Given a binary tree, write a function to get the maximum width of the given tree. The width of a tree is the maximum width among all levels. The binary tree has the same structure as a full binary tree, but some nodes are null.
The width of one level is defined as the length between the end-nodes (the leftmost and right most non-null nodes in the level, where the null nodes between the end-nodes are also counted into the length calculation.
Example 1:
Input:
1
/ \
3 2
/ \ \
5 3 9
Output: 4
Explanation: The maximum width existing in the third level with the length 4 (5,3,null,9).
Example 2:
Input:
1
/
3
/ \
5 3
Output: 2
Explanation: The maximum width existing in the third level with the length 2 (5,3).
Example 3:
Input:
1
/ \
3 2
/
5
Output: 2
Explanation: The maximum width existing in the second level with the length 2 (3,2).
Example 4:
Input:
1
/ \
3 2
/ \
5 9
/ \
6 7
Output: 8
Explanation:The maximum width existing in the fourth level with the length 8 (6,null,null,null,null,null,null,7).
Note: Answer will in the range of 32-bit signed integer.
解题思路:
1. 给每个结点在数组中对应的下标,就可以根据下标计算在每一层中leftmost和rightmost之间的距离。用层序遍历的方式就是用每一层最右边的点减去最左边的。深度优先遍历的方式就是存储每一层最左边的节点对应下标,记录当前节点的层数,在每一次遍历到当前层时就减去最左边节点的下标得到距离。
刷题记录:
1. 一刷,BUG FREE
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
int widthOfBinaryTree(TreeNode* root) {
if (!root) {
return ;
}
int width = ;
queue<pair<TreeNode*, int>> nodes;
nodes.push(pair<TreeNode*, int>(root, ));
while (!nodes.empty()) {
int len = nodes.size();
int left, right;
for (int i = ; i < len; i++) {
pair<TreeNode*, int> p = nodes.front();
nodes.pop();
if (i == ) {
left = p.second;
}
if (i == len - ) {
right = p.second;
}
if (p.first->left) {
nodes.push(pair<TreeNode*, int>(p.first->left, p.second << ));
}
if (p.first->right) {
nodes.push(pair<TreeNode*, int>(p.first->right, (p.second << ) + ));
}
}
width = max(width, right - left + );
}
return width;
}
};
664. Strange Printer
There is a strange printer with the following two special requirements:
- The printer can only print a sequence of the same character each time.
- At each turn, the printer can print new characters starting from and ending at any places, and will cover the original existing characters.
Given a string consists of lower English letters only, your job is to count the minimum number of turns the printer needed in order to print it.
Example 1:
Input: "aaabbb"
Output: 2
Explanation: Print "aaa" first and then print "bbb".
Example 2:
Input: "aba"
Output: 2
Explanation: Print "aaa" first and then print "b" from the second place of the string, which will cover the existing character 'a'.
Hint: Length of the given string will not exceed 100.
解题思路:
1. 根据第一笔画多长来分类递归,假设第一笔画到与首字母不同的地方,其实与第一笔画到最后一个与首字母相同的地方比划一样。因此对第一笔画到不同的与首字母相同的地方分类递归。
刷题记录:
1. 一刷,按照连续字符作为最后一笔递归时间复杂度太高。
class Solution {
public:
int strangePrinter(string s) {
if (s.empty()) {
return ;
}
int len = s.size();
vector<vector<int>> dp(len, vector<int>(len, -));
return helper(dp, s, , len - );
}
int helper(vector<vector<int>>& dp, string& s, int i, int j) {
if (i > j) {
return ;
}
if (dp[i][j] == -) {
int times = + helper(dp, s, i + , j);
for (int k = i + ; k <= j; k++) {
if (s[i] == s[k]) {
times = min(times, helper(dp, s, i, k - ) + helper(dp, s, k + , j));
}
}
dp[i][j] = times;
}
return dp[i][j];
}
};
665. Non-decreasing Array
Given an array with n integers, your task is to check if it could become non-decreasing by modifying at most 1 element.
We define an array is non-decreasing if array[i] <= array[i + 1] holds for every i (1 <= i < n).
Example 1:
Input: [4,2,3]
Output: True
Explanation: You could modify the first4to1to get a non-decreasing array.
Example 2:
Input: [4,2,1]
Output: False
Explanation: You can't get a non-decreasing array by modify at most one element.
Note: The n belongs to [1, 10,000].
解题思路:
1. 用贪心算法,出现元素下降的情况,改写的目的是尽可能让后续元素容易满足条件。如果后面元素和前面元素之间存在空间,就改写当前元素,使后面元素最小;否则只能增大后面元素为与当前元素相同。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
bool checkPossibility(vector<int>& nums) {
bool modify = false;
int len = nums.size();
for (int i = ; i < len - ; i++) {
if (nums[i] <= nums[i + ]) {
continue;
}
if (modify) {
return false;
} else {
if (i - >= && nums[i + ] < nums[i - ]) {
nums[i + ] = nums[i];
}
modify = true;
}
}
return true;
}
};
667. Beautiful Arrangement II
Given two integers n and k, you need to construct a list which contains n different positive integers ranging from 1 to n and obeys the following requirement:
Suppose this list is [a1, a2, a3, ... , an], then the list [|a1 - a2|, |a2 - a3|, |a3 - a4|, ... , |an-1 - an|] has exactly k distinct integers.
If there are multiple answers, print any of them.
Example 1:
Input: n = 3, k = 1
Output: [1, 2, 3]
Explanation: The [1, 2, 3] has three different positive integers ranging from 1 to 3, and the [1, 1] has exactly 1 distinct integer: 1.
Example 2:
Input: n = 3, k = 2
Output: [1, 3, 2]
Explanation: The [1, 3, 2] has three different positive integers ranging from 1 to 3, and the [2, 1] has exactly 2 distinct integers: 1 and 2.
Note:
- The
nandkare in the range 1 <= k < n <= 104.
解题思路:
1. 1~n最多构造n-1个不同的相邻差别绝对值,为1, n, 2, n-1, 3, ......。因此当指定k个不同的差值时,可以将前k个数按照这种方式排列,构成k-1个不同差值,剩下的数以1递增或递减。
刷题记录:
1. 一刷,没有思路
class Solution {
public:
vector<int> constructArray(int n, int k) {
vector<int> ret;
for (int i = ; i < k / ; i++) {
ret.push_back( + i);
ret.push_back(n - i);
}
if (k % ) {
for (int num = + k / ; num <= n - k / ; num++) {
ret.push_back(num);
}
} else {
for (int num = n - k / ; num >= + k / ; num--) {
ret.push_back(num);
}
}
return ret;
}
};
668. Kth Smallest Number in Multiplication Table
Nearly every onehave used the Multiplication Table. But could you find out the k-th smallest number quickly from the multiplication table?
Given the height m and the length n of a m * n Multiplication Table, and a positive integer k, you need to return the k-th smallest number in this table.
Example 1:
Input: m = 3, n = 3, k = 5
Output:
Explanation:
The Multiplication Table:
1 2 3
2 4 6
3 6 9 The 5-th smallest number is 3 (1, 2, 2, 3, 3).
Example 2:
Input: m = 2, n = 3, k = 6
Output:
Explanation:
The Multiplication Table:
1 2 3
2 4 6 The 6-th smallest number is 6 (1, 2, 2, 3, 4, 6).
Note:
- The
mandnwill be in the range [1, 30000]. - The
kwill be in the range [1, m * n]
解题思路:
1. 把它当作一个简单的求第k个数的问题,目标数在1~m*n之间,进行二分查找。根据小于等于目标数的个数进行逼近,直到上界和下界相等。
刷题记录:
1. 一刷,用优先级队列比较复杂,没有二分查找的思路。
class Solution {
public:
int findKthNumber(int m, int n, int k) {
int low = , high = m * n;
while (low < high) {
int mid = low + (high - low) / ;
int countNum = count(m, n, mid);
if (countNum <= k - ) {
low = mid + ;
} else {
high = mid;
}
}
return low;
}
int count(int m, int n, int num) {
int j = n, count = ;
for (; j >= ; j--) {
int temp = num / j;
if (temp >= m) {
break;
} else {
count += temp;
}
}
count += j * m;
return count;
}
};
669. Trim a Binary Search Tree
Given a binary search tree and the lowest and highest boundaries as L and R, trim the tree so that all its elements lies in [L, R] (R >= L). You might need to change the root of the tree, so the result should return the new root of the trimmed binary search tree.
Example 1:
Input:
1
/ \
0 2 L = 1
R = 2 Output:
1
\
2
Example 2:
Input:
3
/ \
0 4
\
2
/
1 L = 1
R = 3 Output:
3
/
2
/
1
解题思路:
1. 如果根结点的值在给定范围内,那么递归trim其左右子树。如果根结点的值大于右值,那么返回其左子树的修剪结果;如果根结点的值小于左值,那么返回其右子树的修剪结果。
刷题记录:
1. 一刷,BUG FREE
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
TreeNode* trimBST(TreeNode* root, int L, int R) {
if (!root) {
return root;
}
if (root->val < L) {
return trimBST(root->right, L, R);
} else if (root->val > R) {
return trimBST(root->left, L, R);
} else {
root->left = trimBST(root->left, L, R);
root->right = trimBST(root->right, L, R);
return root;
}
}
};
670. Maximum Swap
Given a non-negative integer, you could swap two digits at most once to get the maximum valued number. Return the maximum valued number you could get.
Example 1:
Input: 2736
Output: 7236
Explanation: Swap the number 2 and the number 7.
Example 2:
Input: 9973
Output: 9973
Explanation: No swap.
Note:
- The given number is in the range [0, 108]
解题思路:
1. 从左到右找到数字出现增大的位置,然后选择右边最大的数替换最左比其小的数。
刷题记录:
1. 一刷,思路出错
class Solution {
public:
int maximumSwap(int num) {
if (num == ) {
return num;
}
vector<int> digits;
while (num > ) {
digits.push_back(num % );
num /= ;
}
int len = digits.size();
int index = len - ;
while (index >= && digits[index] <= digits[index + ]) {
index--;
}
if (index >= ) {
int maxIndex = index;
for (int j = maxIndex - ; j >= ; j--) {
if (digits[j] >= digits[maxIndex]) {
maxIndex = j;
}
}
index++;
while (index + < len && digits[index + ] < digits[maxIndex]) {
index++;
}
swap(digits[maxIndex], digits[index]);
}
num = ;
for (int j = len - ; j >= ; j--) {
num = * num + digits[j];
}
return num;
}
};
671. Second Minimum Node In a Binary Tree
Given a non-empty special binary tree consisting of nodes with the non-negative value, where each node in this tree has exactly twoor zero sub-node. If the node has two sub-nodes, then this node's value is the smaller value among its two sub-nodes.
Given such a binary tree, you need to output the second minimum value in the set made of all the nodes' value in the whole tree.
If no such second minimum value exists, output -1 instead.
Example 1:
Input:
2
/ \
2 5
/ \
5 7 Output: 5
Explanation: The smallest value is 2, the second smallest value is 5.
Example 2:
Input:
2
/ \
2 2 Output: -1
Explanation: The smallest value is 2, but there isn't any second smallest value.
解题思路:
1. 递归调用原函数求左右子树的第二小的结点,然后取其中的最小值。如果子结点的值比根结点大,那么将其作为候选。
刷题记录:
1. 一刷,BUG FREE
672. Bulb Switcher II
There is a room with n lights which are turned on initially and 4 buttons on the wall. After performing exactly m unknown operations towards buttons, you need to return how many different kinds of status of the n lights could be.
Suppose n lights are labeled as number [1, 2, 3 ..., n], function of these 4 buttons are given below:
- Flip all the lights.
- Flip lights with even numbers.
- Flip lights with odd numbers.
- Flip lights with (3k + 1) numbers, k = 0, 1, 2, ...
Example 1:
Input: n = 1, m = 1.
Output: 2
Explanation: Status can be: [on], [off]
Example 2:
Input: n = 2, m = 1.
Output: 3
Explanation: Status can be: [on, off], [off, on], [off, off]
Example 3:
Input: n = 3, m = 1.
Output: 4
Explanation: Status can be: [off, on, off], [on, off, on], [off, off, off], [off, on, on].
Note: n and m both fit in range [0, 1000].
解题思路:
1. 由于每个按钮按两次的效果等同于没按,因此每个按钮的作用分为不按和按一次两种。可以用一个4位二进制数(0~15)来表示各个按钮的作用。(当bit位1的个数小于总次数,且对2取余相同为有效,根据bit位置对对应bit位进行操作)。
2. 按钮操作的周期数为6,因此最多只需要对6个bulb的情况进行探讨即可。
刷题记录:
1. 一刷,没有思路。
class Solution {
public:
int flipLights(int n, int m) {
n = min(n, );
int shift = max( - n, );
set<int> status;
for (int cand = ; cand < ; cand++) {
int operations = bitCount(cand);
int bulbs = ;
if (operations <= m && operations % == m % ) {
if ((cand >> ) & > ) bulbs ^= 0b111 >> shift;
if ((cand >> ) & > ) bulbs ^= 0b010 >> shift;
if ((cand >> ) & > ) bulbs ^= 0b101 >> shift;
if (cand & > ) bulbs ^= 0b100 >> shift;
status.insert(bulbs);
}
}
return (int)status.size();
}
int bitCount(int num) {
int count = ;
while (num > ) {
num &= num - ;
count++;
}
return count;
}
};
673. Number of Longest Increasing Subsequence
Given an unsorted array of integers, find the number of longest increasing subsequence.
Example 1:
Input: [1,3,5,4,7]
Output: 2
Explanation: The two longest increasing subsequence are [1, 3, 4, 7] and [1, 3, 5, 7].
Example 2:
Input: [2,2,2,2,2]
Output: 5
Explanation: The length of longest continuous increasing subsequence is 1, and there are 5 subsequences' length is 1, so output 5.
Note: Length of the given array will be not exceed 2000 and the answer is guaranteed to be fit in 32-bit signed int.
解题思路:
1. 使用动态规划的方法,记录以数组中每个元素为结尾的最大长度和对应的子序列个数。循环对当前元素讨论,比较前面所有元素在其之前的可能性。
刷题记录:
1. 一刷,没有思路。
class Solution {
public:
int findNumberOfLIS(vector<int>& nums) {
if (nums.empty()) {
return ;
}
int N = nums.size(), maxLen = , count = ;
vector<int> lengths(N, ), counts(N, );
for (int j = ; j < N; j++) {
for (int i = ; i < j; i++) {
if (nums[i] < nums[j] && lengths[j] <= lengths[i] + ) {
if (lengths[j] < lengths[i] + ) {
lengths[j] = lengths[i] + ;
counts[j] = ;
}
counts[j] += counts[i];
}
}
if (maxLen > lengths[j]) {
continue;
} else if (maxLen < lengths[j]) {
maxLen = lengths[j];
count = ;
}
count += counts[j];
}
return count;
}
};
674. Longest Continuous Increasing Subsequence
Given an unsorted array of integers, find the length of longest continuous increasing subsequence (subarray).
Example 1:
Input: [1,3,5,4,7]
Output: 3
Explanation: The longest continuous increasing subsequence is [1,3,5], its length is 3.
Even though [1,3,5,7] is also an increasing subsequence, it's not a continuous one where 5 and 7 are separated by 4.
Example 2:
Input: [2,2,2,2,2]
Output: 1
Explanation: The longest continuous increasing subsequence is [2], its length is 1.
Note: Length of the array will not exceed 10,000.
解题思路:
1. 最长连续递增序列,如果出现非递增情况则重新计数。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
int findLengthOfLCIS(vector<int>& nums) {
if (nums.empty()) {
return ;
}
int maxLen = , cur = ;
for (int i = ; i < nums.size(); i++) {
if (nums[i] > nums[i - ]) {
cur++;
maxLen = max(maxLen, cur);
}
else {
cur = ;
}
}
return maxLen;
}
};
675. Cut Off Trees for Golf Event
You are asked to cut off trees in a forest for a golf event. The forest is represented as a non-negative 2D map, in this map:
0represents theobstaclecan't be reached.1represents thegroundcan be walked through.The place with number bigger than 1represents atreecan be walked through, and this positive number represents the tree's height.
You are asked to cut off all the trees in this forest in the order of tree's height - always cut off the tree with lowest height first. And after cutting, the original place has the tree will become a grass (value 1).
You will start from the point (0, 0) and you should output the minimum steps you need to walk to cut off all the trees. If you can't cut off all the trees, output -1 in that situation.
You are guaranteed that no two trees have the same height and there is at least one tree needs to be cut off.
Example 1:
Input:
[
[1,2,3],
[0,0,4],
[7,6,5]
]
Output: 6
Example 2:
Input:
[
[1,2,3],
[0,0,0],
[7,6,5]
]
Output: -1
Example 3:
Input:
[
[2,3,4],
[0,0,5],
[8,7,6]
]
Output: 6
Explanation: You started from the point (0,0) and you can cut off the tree in (0,0) directly without walking.
Hint: size of the given matrix will not exceed 50x50.
解题思路:
1. 自定义排序函数无法直接访问函数参数变量,如果涉及需要包含多个信息的,可以用向量来替换pair使代码更简洁。
2. 用bool向量替换集合可以降低时间复杂度。
刷题记录:
1. 一刷,题目意思理解不清楚,使用集合来存储已经访问过的变量超时。
class Solution {
public:
int cutOffTree(vector<vector<int>>& forest) {
int row = forest.size(), col = forest[].size();
vector<vector<int>> path;
for (int i = ; i < row; i++) {
for (int j = ; j < col; j++) {
if (forest[i][j] > ) {
path.push_back(vector<int>({i, j, forest[i][j]}));
}
}
}
sort(path.begin(), path.end(), [](vector<int>& pos1, vector<int>& pos2) {return pos1[] < pos2[];});
int steps = ;
pair<int, int> start(, );
int len = path.size();
for (int i = ; i < len; i++) {
int distance = minDistance(forest, start, pair<int, int>(path[i][], path[i][]));
if (distance == -) {
return -;
}
steps += distance;
start = pair<int, int>(path[i][], path[i][]);
}
return steps;
}
int minDistance(vector<vector<int>>& forest, pair<int, int> start, pair<int, int> end) {
int dir[][] = {{-, }, {, }, {, -}, {, }};
int distance = , row = forest.size(), col = forest[].size();
if (start == end) {
return distance;
}
queue<pair<int, int>> nodes;
nodes.push(start);
vector<vector<bool>> visited(row, vector<bool>(col, false));
visited[start.first][start.second] = true;
while (!nodes.empty()) {
distance++;
int len = nodes.size();
for (int i = ; i < len; i++) {
pair<int, int> cur(nodes.front());
nodes.pop();
for (int k = ; k < ; k++) {
pair<int, int> temp(pair<int, int>(cur.first + dir[k][], cur.second + dir[k][]));
if (temp == end) {
return distance;
}
if (temp.first < || temp.first >= row || temp.second < || temp.second >= col || visited[temp.first][temp.second] || forest[temp.first][temp.second] == ) {
continue;
}
nodes.push(temp);
visited[temp.first][temp.second] = true;
}
}
}
return -;
}
};
676. Implement Magic Dictionary
Implement a magic directory with buildDict, and search methods.
For the method buildDict, you'll be given a list of non-repetitive words to build a dictionary.
For the method search, you'll be given a word, and judge whether if you modify exactly one character into another character in this word, the modified word is in the dictionary you just built.
Example 1:
Input: buildDict(["hello", "leetcode"]), Output: Null
Input: search("hello"), Output: False
Input: search("hhllo"), Output: True
Input: search("hell"), Output: False
Input: search("leetcoded"), Output: False
Note:
- You may assume that all the inputs are consist of lowercase letters
a-z. - For contest purpose, the test data is rather small by now. You could think about highly efficient algorithm after the contest.
- Please remember to RESET your class variables declared in class MagicDictionary, as static/class variables are persisted across multiple test cases. Please see here for more details.
解题思路:
1. 这个题可以使用键值表(长度-string list)的方式来存储,长度可以作为第一轮的筛选。
2. 使用Trie树,在查找时需要分为已经对字母做修改和未做修改两种情况讨论。
刷题记录:
1. 一刷,BUG FREE
struct node {
node* letters[] = {NULL};
bool isWord = false;
};
class MagicDictionary {
public:
node* root;
/** Initialize your data structure here. */
MagicDictionary() {
root = new node;
}
/** Build a dictionary through a list of words */
void buildDict(vector<string> dict) {
for (auto word : dict) {
node* p = root;
for (auto letter : word) {
if (!p->letters[letter - 'a']) {
p->letters[letter - 'a'] = new node;
}
p = p->letters[letter - 'a'];
}
p->isWord = true;
}
}
/** Returns if there is any word in the trie that equals to the given word after modifying exactly one character */
bool search(string word) {
return searchHelper(root, word, , false);
}
bool searchHelper(node* p, string& word, int begin, bool modify) {
if (begin == (int)word.size()) {
return p->isWord && modify;
}
if (modify) {
for (int i = begin; i < word.size(); i++) {
if (!p->letters[word[i] - 'a']) {
return false;
}
p = p->letters[word[i] - 'a'];
}
return p->isWord;
} else {
for (int i = ; i < ; i++) {
if (p->letters[i]) {
if (word[begin] == 'a' + i) {
if (searchHelper(p->letters[i], word, begin + , modify)) {
return true;
}
} else if (searchHelper(p->letters[i], word, begin + , !modify)) {
return true;
}
}
}
}
return false;
}
};
/**
* Your MagicDictionary object will be instantiated and called as such:
* MagicDictionary obj = new MagicDictionary();
* obj.buildDict(dict);
* bool param_2 = obj.search(word);
*/
677. Map Sum Pairs
Implement a MapSum class with insert, and sum methods.
For the method insert, you'll be given a pair of (string, integer). The string represents the key and the integer represents the value. If the key already existed, then the original key-value pair will be overridden to the new one.
For the method sum, you'll be given a string representing the prefix, and you need to return the sum of all the pairs' value whose key starts with the prefix.
Example 1:
Input: insert("apple", 3), Output: Null
Input: sum("ap"), Output: 3
Input: insert("app", 2), Output: Null
Input: sum("ap"), Output: 5
解题思路:
1. 维护一个Trie Tree,结点里存储当前字符串前缀包含单词的sum值。
刷题记录:
1. 一刷,BUG FREE
struct TrieNode {
TrieNode* letters[] = { NULL };
int sum = ;
};
class MapSum {
public:
TrieNode* root;
map<string, int> kv;
/** Initialize your data structure here. */
MapSum() {
root = new TrieNode;
}
void insert(string key, int val) {
if (!kv.count(key)) {
kv[key] = ;
}
insertHelper(key, val - kv[key]);
kv[key] = val;
return;
}
void insertHelper(string key, int val) {
TrieNode* p = root;
p->sum += val;
for (auto letter : key) {
if (!p->letters[letter]) {
p->letters[letter] = new TrieNode;
}
p = p->letters[letter];
p->sum += val;
}
return;
}
int sum(string prefix) {
TrieNode* p = root;
for (auto letter : prefix) {
if (!p->letters[letter]) {
return ;
}
p = p->letters[letter];
}
return p->sum;
}
};
/**
* Your MapSum object will be instantiated and called as such:
* MapSum obj = new MapSum();
* obj.insert(key,val);
* int param_2 = obj.sum(prefix);
*/
678. Valid Parenthesis String
Given a string containing only three types of characters: '(', ')' and '*', write a function to check whether this string is valid. We define the validity of a string by these rules:
- Any left parenthesis
'('must have a corresponding right parenthesis')'. - Any right parenthesis
')'must have a corresponding left parenthesis'('. - Left parenthesis
'('must go before the corresponding right parenthesis')'. '*'could be treated as a single right parenthesis')'or a single left parenthesis'('or an empty string.- An empty string is also valid.
Example 1:
Input: "()"
Output: True
Example 2:
Input: "(*)"
Output: True
Example 3:
Input: "(*))"
Output: True
Note:
- The string size will be in the range [1, 100].
解题思路:
1. 可以左右遍历字符串,尽量让处在前面的'*'优先替换。所以可以采用队列的存储结构。
2. 用low和high来存储左括号多的范围。
刷题记录:
1. 一刷,思路比较不清晰,BUG FREE
class Solution {
public:
bool checkValidString(string s) {
if (s.empty()) {
return true;
}
queue<int> index;
int len = s.size();
int balance = ;
for (int i = ; i < len; i++) {
if (s[i] == '(') {
balance++;
} else if (s[i] == '*') {
index.push(i);
} else {
if (balance > ) {
balance--;
} else if (!index.empty()) {
s[index.front()] = '(';
index.pop();
} else {
return false;
}
}
}
balance = ;
while (!index.empty()) {
index.pop();
}
for (int i = len - ; i >= ; i--) {
if (s[i] == ')') {
balance++;
} else if (s[i] == '*') {
index.push(i);
} else {
if (balance > ) {
balance--;
} else if (!index.empty()) {
s[index.front()] = ')';
index.pop();
} else {
return false;
}
}
}
return true;
}
};
679. 24 Game
You have 4 cards each containing a number from 1 to 9. You need to judge whether they could operatedthrough *, /, +, -, (, )to get the value of 24.
Example 1:
Input: [4, 1, 8, 7]
Output: True
Explanation: (8-4) * (7-1) = 24
Example 2:
Input: [1, 2, 1, 2]
Output: False
Note:
- The division operator
/represents real division, not integer division. For example, 4 / (1 - 2/3) = 12. - Every operation done is between two numbers. In particular, we cannot use
-as a unary operator. For example, with[1, 1, 1, 1]as input, the expression-1 - 1 - 1 - 1is not allowed. - You cannot concatenate numbers together. For example, if the input is
[1, 2, 1, 2], we cannot write this as 12 + 12.
解题思路:
1. 优先挑选先进行运算的两个数,遍历所有可能的情况。得到一个数与剩下的数继续组合计算。注意加号和乘号满足结合律可简化运算。不满足的结合律的用重复选择可交换顺序。
刷题记录:
1. 一刷,没有思路。
class Solution {
public:
bool judgePoint24(vector<int>& nums) {
if (nums.size() != ) {
return false;
}
vector<double> temp;
for (auto num : nums) {
temp.push_back((double)num);
}
return helper(temp);
}
bool helper(vector<double>& nums) {
int len = nums.size();
if (len == ) return false;
if (len == ) {
return abs(nums[] - ) <= 1e-;
}
for (int i = ; i < len; i++) {
for (int j = ; j < len; j++) {
if (i == j) {
continue;
}
vector<double> temp;
for (int k = ; k < len; k++) {
if (k != i && k != j) {
temp.push_back(nums[k]);
}
}
for (int k = ; k < ; k++) {
if (k < && i > j) continue;
if (k == ) temp.push_back(nums[i] + nums[j]);
if (k == ) temp.push_back(nums[i] * nums[j]);
if (k == ) temp.push_back(nums[i] - nums[j]);
if (k == ) {
if (nums[j] != ) {
temp.push_back(nums[i] / nums[j]);
} else {
continue;
}
}
if (helper(temp)) {
return true;
}
temp.pop_back();
}
}
}
return false;
}
};
680. Valid Palindrome II
Given a non-empty string s, you may delete at most one character. Judge whether you can make it a palindrome.
Example 1:
Input: "aba"
Output: True
Example 2:
Input: "abca"
Output: True
Explanation: You could delete the character 'c'.
Note:
- The string will only contain lowercase characters a-z. The maximum length of the string is 50000.
解题思路:
1. 使用贪心算法,直到头尾字符不同时考虑删除一个字符。有两种可能,第一种是删除前面字符,第二种是删除后面字符,分别进行讨论删除后未遍历的部分是否为回文。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
bool validPalindrome(string s) {
int low = , high = (int)s.size() - ;
while (low < high) {
if (s[low] != s[high]) {
return isPalindrome(s, low + , high) || isPalindrome(s, low, high - );
} else {
low++;
high--;
}
}
return true;
}
bool isPalindrome(string& s, int low, int high) {
while (low < high) {
if (s[low++] != s[high--]) {
return false;
}
}
return true;
}
};
682. Baseball Game
You're now a baseball game point recorder.
Given a list of strings, each string can be one of the 4 following types:
Integer(one round's score): Directly represents the number of points you get in this round."+"(one round's score): Represents that the points you get in this round are the sum of the last twovalidround's points."D"(one round's score): Represents that the points you get in this round are the doubled data of the lastvalidround's points."C"(an operation, which isn't a round's score): Represents the lastvalidround's points you get were invalid and should be removed.
Each round's operation is permanent and could have an impact on the round before and the round after.
You need to return the sum of the points you could get in all the rounds.
Example 1:
Input: ["5","2","C","D","+"]
Output: 30
Explanation:
Round 1: You could get 5 points. The sum is: 5.
Round 2: You could get 2 points. The sum is: 7.
Operation 1: The round 2's data was invalid. The sum is: 5.
Round 3: You could get 10 points (the round 2's data has been removed). The sum is: 15.
Round 4: You could get 5 + 10 = 15 points. The sum is: 30.
Example 2:
Input: ["5","-2","4","C","D","9","+","+"]
Output: 27
Explanation:
Round 1: You could get 5 points. The sum is: 5.
Round 2: You could get -2 points. The sum is: 3.
Round 3: You could get 4 points. The sum is: 7.
Operation 1: The round 3's data is invalid. The sum is: 3.
Round 4: You could get -4 points (the round 3's data has been removed). The sum is: -1.
Round 5: You could get 9 points. The sum is: 8.
Round 6: You could get -4 + 9 = 5 points. The sum is 13.
Round 7: You could get 9 + 5 = 14 points. The sum is 27.
Note:
- The size of the input list will be between 1 and 1000.
- Every integer represented in the list will be between -30000 and 30000.
解题思路:
1. 使用一个向量来模拟栈操作即可。使用向量来替代是方便访问最后的多个元素而不用进行出栈操作。
刷题记录:
1. 一刷,switch只能针对整数或者枚举等能够转化为整数的类型。BUG FREE
class Solution {
public:
int calPoints(vector<string>& ops) {
vector<int> records;
for (string op : ops) {
if (op == "+") {
records.push_back(records[(int)records.size() - ] + records.back());
} else if (op == "D") {
records.push_back( * records.back());
} else if (op == "C") {
records.pop_back();
} else {
records.push_back(stoi(op));
}
}
int sum = ;
for (auto record : records) {
sum += record;
}
return sum;
}
};
684. Redundant Connection
In this problem, a tree is an undirected graph that is connected and has no cycles.
The given input is a graph that started as a tree with N nodes (with distinct values 1, 2, ..., N), with one additional edge added. The added edge has two different vertices chosen from 1 to N, and was not an edge that already existed.
The resulting graph is given as a 2D-array of edges. Each element of edges is a pair [u, v] with u < v, that represents an undirected edge connecting nodes u and v.
Return an edge that can be removed so that the resulting graph is a tree of N nodes. If there are multiple answers, return the answer that occurs last in the given 2D-array. The answer edge [u, v] should be in the same format, with u < v.
Example 1:
Input: [[1,2], [1,3], [2,3]]
Output: [2,3]
Explanation: The given undirected graph will be like this:
1
/ \
2 - 3
Example 2:
Input: [[1,2], [2,3], [3,4], [1,4], [1,5]]
Output: [1,4]
Explanation: The given undirected graph will be like this:
5 - 1 - 2
| |
4 - 3
Note:
- The size of the input 2D-array will be between 3 and 1000.
- Every integer represented in the 2D-array will be between 1 and N, where N is the size of the input array.
解题思路:
1. 可以转化为一个并查集问题,用一个数组记录每个点对应的父结点的下标代表其处于的集合。在查找的过程中顺便更改。如果遇到两个点处于不用的集合,那么将其中一个根结点指向另一个根结点以将其Union成一个集合。
刷题记录:
1. 一刷,没有思路
class Solution {
public:
vector<int> findRedundantConnection(vector<vector<int>>& edges) {
int N = edges.size();
vector<int> parent( + N, );
for (int i = ; i <= N; i++) {
parent[i] = i;
}
for (int i = ; i < edges.size(); i++) {
int point1 = edges[i][], point2 = edges[i][];
if (find(parent, point1) == find(parent, point2)) {
return edges[i];
}
parent[find(parent, point1)] = find(parent, point2);
}
return vector<int>();
}
int find(vector<int>& parent, int x) {
if (x != parent[x]) {
parent[x] = find(parent, parent[x]);
}
return parent[x];
}
};
685. Redundant Connection II
In this problem, a rooted tree is a directed graph such that, there is exactly one node (the root) for which all other nodes are descendants of this node, plus every node has exactly one parent, except for the root node which has no parents.
The given input is a directed graph that started as a rooted tree with N nodes (with distinct values 1, 2, ..., N), with one additional directed edge added. The added edge has two different vertices chosen from 1 to N, and was not an edge that already existed.
The resulting graph is given as a 2D-array of edges. Each element of edges is a pair [u, v] that represents a directed edge connecting nodes u and v, where u is a parent of child v.
Return an edge that can be removed so that the resulting graph is a rooted tree of N nodes. If there are multiple answers, return the answer that occurs last in the given 2D-array.
Example 1:
Input: [[1,2], [1,3], [2,3]]
Output: [2,3]
Explanation: The given directed graph will be like this:
1
/ \
v v
2-->3
Example 2:
Input: [[1,2], [2,3], [3,4], [4,1], [1,5]]
Output: [4,1]
Explanation: The given directed graph will be like this:
5 <- 1 -> 2
^ |
| v
4 <- 3
Note:
- The size of the input 2D-array will be between 3 and 1000.
- Every integer represented in the 2D-array will be between 1 and N, where N is the size of the input array.
解题思路:
1. 出现删除一条有向线段恢复有效的情况有两种:一种是一个结点有两个父结点存在,那么必须删除其中一个。另一种是有循环存在。因此可以采用两个步骤,第一步找出是否存在两个父结点,然后删除其中一条线段,判断剩下的图形是否有效,如果有效则为删除的那条线。否则为留下的线。
2. 第二种情况下,不存在两个父结点,那么造成循环的最后一条线段为解。
刷题记录:
1. 一刷,没有思路。
class Solution {
public:
vector<int> findRedundantDirectedConnection(vector<vector<int>>& edges) {
int N = edges.size();
vector<int> parent( + N, ), candA, candB;
for (int i = ; i < N; i++) {
int par = edges[i][], chi = edges[i][];
if (parent[chi] != ) {
candA = {parent[chi], chi};
candB.assign(edges[i].begin(), edges[i].end());
edges[i][] = ;
break;
}
parent[chi] = par;
}
for (int i = ; i <= N; i++) {
parent[i] = i;
}
for (int i = ; i < N; i++) {
int par = edges[i][], chi = edges[i][];
if (par == ) {
continue;
}
if (chi == find(parent, par)) {
return candA.empty() ? edges[i] : candA;
}
parent[chi] = par;
}
return candB;
}
int find(vector<int>& parent, int x) {
if (parent[x] != x) {
parent[x] = find(parent, parent[x]);
}
return parent[x];
}
};
686. Repeated String Match
Given two strings A and B, find the minimum number of times A has to be repeated such that B is a substring of it. If no such solution, return -1.
For example, with A = "abcd" and B = "cdabcdab".
Return 3, because by repeating A three times (“abcdabcdabcd”), B is a substring of it; and B is not a substring of A repeated two times ("abcdabcd").
Note:
The length of A and B will be between 1 and 10000.
解题思路:
1. 直接对字符串匹配从目标串的每个地方出发的情况进行比较即可。可以使用KMP方面提前对模式串的结构进行讨论和存储,能够加快查找的速度。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
int repeatedStringMatch(string A, string B) {
int lenA = A.size(), lenB = B.size();
for (int i = ; i < lenA; i++) {
int index = i, j = ;
int round = ;
while (j < lenB && A[index] == B[j]) {
index++;
if (index == lenA) {
round++;
index = ;
}
j++;
}
if (j == lenB) {
return index == ? round - : round;
}
}
return -;
}
};
687. Longest Univalue Path
Given a binary tree, find the length of the longest path where each node in the path has the same value. This path may or may not pass through the root.
Note: The length of path between two nodes is represented by the number of edges between them.
Example 1:
Input:
5
/ \
4 5
/ \ \
1 1 5
Output:
2
Example 2:
Input:
1
/ \
4 5
/ \ \
4 4 5
Output:
2
Note: The given binary tree has not more than 10000 nodes. The height of the tree is not more than 1000.
解题思路:
1 . 使用递归的方法,使递归函数返回与当前根结点相同的一边路径的最大值。然后上级结点根据与子结点的值比较情况判断最长路径。
刷题记录:
1. 一刷,BUG FREE
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
int longestUnivaluePath(TreeNode* root) {
int maxLen = ;
findHelper(root, NULL, maxLen);
return maxLen;
} int findHelper(TreeNode* root, TreeNode* parent, int& maxLen) {
if (!root) {
return ;
}
int left = findHelper(root->left, root, maxLen);
int right = findHelper(root->right, root, maxLen);
maxLen = max(maxLen, left + right);
return parent && root->val == parent->val ? max(left, right) + : ;
}
};
688. Knight Probability in Chessboard
On an NxN chessboard, a knight starts at the r-th row and c-th column and attempts to make exactly K moves. The rows and columns are 0 indexed, so the top-left square is (0, 0), and the bottom-right square is (N-1, N-1).
A chess knight has 8 possible moves it can make, as illustrated below. Each move is two squares in a cardinal direction, then one square in an orthogonal direction.

Each time the knight is to move, it chooses one of eight possible moves uniformly at random (even if the piece would go off the chessboard) and moves there.
The knight continues moving until it has made exactly K moves or has moved off the chessboard. Return the probability that the knight remains on the board after it has stopped moving.
Example:
Input: 3, 2, 0, 0
Output: 0.0625
Explanation: There are two moves (to (1,2), (2,1)) that will keep the knight on the board.
From each of those positions, there are also two moves that will keep the knight on the board.
The total probability the knight stays on the board is 0.0625.
Note:
Nwill be between 1 and 25.Kwill be between 0 and 100.- The knight always initially starts on the board.
解题思路:
1. 使用动态规划的办法,每一次求经过一次移动后达到下一次的位置存活的概率。然后对当前存活的棋子做归一化处理。
刷题记录:
1. 一刷,BUG FREE
689. Maximum Sum of 3 Non-Overlapping Subarrays
In a given array nums of positive integers, find three non-overlapping subarrays with maximum sum.
Each subarray will be of size k, and we want to maximize the sum of all 3*k entries.
Return the result as a list of indices representing the starting position of each interval (0-indexed). If there are multiple answers, return the lexicographically smallest one.
Example:
Input: [1,2,1,2,6,7,5,1], 2
Output: [0, 3, 5]
Explanation: Subarrays [1, 2], [2, 6], [7, 5] correspond to the starting indices [0, 3, 5].
We could have also taken [2, 1], but an answer of [1, 3, 5] would be lexicographically larger.
Note:
nums.lengthwill be between 1 and 20000.nums[i]will be between 1 and 65535.kwill be between 1 and floor(nums.length / 3).
解题思路:
1. 事先求出在每个下标以左作为开始下标和最大对应的下标。同理存储每个下标以右作为序列开始对应的最大下标。那么中间序列在数组中滑动时,其左边和右边序列开始的范围是确定的,根据前面动态规划求出的内容,可快速得到最大的结果。
刷题记录:
1. 一刷,没有思路
class Solution {
public:
vector<int> maxSumOfThreeSubarrays(vector<int>& nums, int k) {
if ( * k > nums.size()) {
return vector<int>();
}
int interval = ;
vector<int> sum;
for (int i = ; i < nums.size(); i++) {
interval += nums[i];
if (i >= k - ) {
sum.push_back(interval);
interval -= nums[i - k + ];
}
}
int len = sum.size();
vector<int> left, right(len, );
int index = ;
for (int i = ; i < len; i++) {
if (sum[i] > sum[index]) {
index = i;
}
left.push_back(index);
}
index = len - ;
for (int i = index; i >= ; i--) {
if (sum[i] >= sum[index]) {
index = i;
}
right[i] = index;
}
vector<int> res(, );
int maxSum = INT_MIN;
for (int j = k; j <= len - k - ; j++) {
if (sum[left[j - k]] + sum[j] + sum[right[j + k]] > maxSum) {
res[] = left[j - k];
res[] = j;
res[] = right[j + k];
maxSum = sum[left[j - k]] + sum[j] + sum[right[j + k]];
}
}
return res;
}
};
690. Employee Importance
You are given a data structure of employee information, which includes the employee's unique id, his importance value and his directsubordinates' id.
For example, employee 1 is the leader of employee 2, and employee 2 is the leader of employee 3. They have importance value 15, 10 and 5, respectively. Then employee 1 has a data structure like [1, 15, [2]], and employee 2 has [2, 10, [3]], and employee 3 has [3, 5, []]. Note that although employee 3 is also a subordinate of employee 1, the relationship is not direct.
Now given the employee information of a company, and an employee id, you need to return the total importance value of this employee and all his subordinates.
Example 1:
Input: [[1, 5, [2, 3]], [2, 3, []], [3, 3, []]], 1
Output: 11
Explanation:
Employee 1 has importance value 5, and he has two direct subordinates: employee 2 and employee 3. They both have importance value 3. So the total importance value of employee 1 is 5 + 3 + 3 = 11.
Note:
- One employee has at most one direct leader and may have several subordinates.
- The maximum number of employees won't exceed 2000.
解题思路:
1. DFS递归遍历每一个下属的重要性。
刷题记录:
1. 一刷,BUG FREE
/*
// Employee info
class Employee {
public:
// It's the unique ID of each node.
// unique id of this employee
int id;
// the importance value of this employee
int importance;
// the id of direct subordinates
vector<int> subordinates;
};
*/
class Solution {
public:
int getImportance(vector<Employee*> employees, int id) {
map<int, Employee*> employee;
set<int> visited;
for (auto p : employees) {
employee[p->id] = p;
}
int res = getHelper(employee, visited, id);
return res;
} int getHelper(map<int, Employee*>& employee, set<int>& visited, int id) {
if (visited.count(id)) {
return ;
}
int res = employee[id]->importance;
visited.insert(id);
for (auto subordinate : employee[id]->subordinates) {
res += getHelper(employee, visited, subordinate);
}
return res;
}
};
691. Stickers to Spell Word
We are given N different types of stickers. Each sticker has a lowercase English word on it.
You would like to spell out the given target string by cutting individual letters from your collection of stickers and rearranging them.
You can use each sticker more than once if you want, and you have infinite quantities of each sticker.
What is the minimum number of stickers that you need to spell out the target? If the task is impossible, return -1.
Example 1:
Input:
["with", "example", "science"], "thehat"
Output:
3
Explanation:
We can use 2 "with" stickers, and 1 "example" sticker.
After cutting and rearrange the letters of those stickers, we can form the target "thehat".
Also, this is the minimum number of stickers necessary to form the target string.
Example 2:
Input:
["notice", "possible"], "basicbasic"
Output:
-1
Explanation:
We can't form the target "basicbasic" from cutting letters from the given stickers.
Note:
stickershas length in the range[1, 50].stickersconsists of lowercase English words (without apostrophes).targethas length in the range[1, 15], and consists of lowercase English letters.- In all test cases, all words were chosen randomly from the 1000 most common US English words, and the target was chosen as a concatenation of two random words.
- The time limit may be more challenging than usual. It is expected that a 50 sticker test case can be solved within 35ms on average.
解题思路:
1. 用带记忆的递归,将剩下需要拼接的字符串作为target(状态)。在递归时每次只选择其中符合条件的一个进行递归。优先把当前第一个字母补充完整。
刷题记录:
1. 一刷,代码比较冗杂,写的过程有出错。思考:代码复杂不要害怕,只需要确保每一句代码都万无一失即可,有可能代码复杂换来的是执行效率高。
class Solution {
public:
int minStickers(vector<string>& stickers, string target) {
vector<int> need;
map<char, int> mapper;
for (auto letter : target) {
if (mapper.count(letter)) {
need[mapper[letter]]++;
} else {
mapper[letter] = (int)need.size();
need.push_back();
}
}
vector<vector<int>> sticker((int)stickers.size(), vector<int>((int)need.size(), ));
set<char> contain;
for (int i = ; i < stickers.size(); i++) {
for (auto letter : stickers[i]) {
if (mapper.count(letter)) {
sticker[i][mapper[letter]]++;
contain.insert(letter);
}
}
}
if ((int)contain.size() < (int)mapper.size()) {
return -;
}
sort(sticker.begin(), sticker.end(), greater<vector<int>>());
vector<bool> dominate((int)stickers.size(), false);
for (int i = ; i < stickers.size(); i++) {
if (dominate[i]) {
continue;
}
for (int j = i + ; j < stickers.size(); j++) {
if (dominate[j]) {
continue;
}
bool result = true;
for (int k = ; k < need.size(); k++) {
if (sticker[i][k] < sticker[j][k]) {
result = false;
break;
}
}
dominate[j] = result;
}
}
vector<vector<int>> newSticker;
for (int i = ; i < stickers.size(); i++) {
if (!dominate[i]) {
newSticker.push_back(vector<int>());
newSticker.back().assign(sticker[i].begin(), sticker[i].end());
}
}
int res = INT_MAX;
helper(newSticker, need, res, , );
return res;
}
void helper(vector<vector<int>>& sticker, vector<int>& need, int& res, int cur, int begin) {
if (isReady(need)) {
res = min(res, cur);
return;
}
if (begin >= sticker.size() || cur >= res) {
return;
}
int range = repeat(need, sticker[begin]);
for (int i = ; i <= range; i++) {
helper(sticker, need, res, cur + i, begin + );
change(need, sticker[begin], , -);
}
change(need, sticker[begin], range + , +);
return;
}
bool isReady(vector<int>& need) {
for (auto num : need) {
if (num > ) {
return false;
}
}
return true;
}
void change(vector<int>& need, vector<int>& sticker, int n, int sign) {
for (int i = ; i < need.size(); i++) {
need[i] += sticker[i] * n * sign;
}
return;
}
int repeat(vector<int>& need, vector<int>& sticker) {
int times = ;
for (int i = ; i < need.size(); i++) {
if (sticker[i] == || need[i] <= ) {
continue;
}
times = max(times, (int)ceil(need[i] / (float)sticker[i]));
}
return times;
}
};
692. Top K Frequent Words
Given a non-empty list of words, return the k most frequent elements.
Your answer should be sorted by frequency from highest to lowest. If two words have the same frequency, then the word with the lower alphabetical order comes first.
Example 1:
Input: ["i", "love", "leetcode", "i", "love", "coding"], k = 2
Output: ["i", "love"]
Explanation: "i" and "love" are the two most frequent words.
Note that "i" comes before "love" due to a lower alphabetical order.
Example 2:
Input: ["the", "day", "is", "sunny", "the", "the", "the", "sunny", "is", "is"], k = 4
Output: ["the", "is", "sunny", "day"]
Explanation: "the", "is", "sunny" and "day" are the four most frequent words,
with the number of occurrence being 4, 3, 2 and 1 respectively.
Note:
- You may assume k is always valid, 1 ≤ k ≤ number of unique elements.
- Input words contain only lowercase letters.
Follow up:
- Try to solve it in O(n log k) time and O(n) extra space.
解题思路:
1. 统计原向量中出现的单词以及对应的数量,然后将这些信息依次存入到优先级队列中。保持队列的大小为k,为出现频率最高且字典编纂顺序较小的词语。
刷题记录:
1. 一刷,BUG FREE
struct cmp {
bool operator() (pair<int, string>& p1, pair<int, string>& p2) {
return p1.first > p2.first || p1.first == p2.first && p1.second < p2.second;
}
};
class Solution {
public:
vector<string> topKFrequent(vector<string>& words, int k) {
map<string, int> wordsBag;
for (auto word : words) {
wordsBag[word]++;
}
priority_queue<pair<int, string>, vector<pair<int, string>>, cmp> pq;
for (map<string, int>::iterator it = wordsBag.begin(); it != wordsBag.end(); it++) {
pq.push(pair<int, string>(it->second, it->first));
if (pq.size() > k) {
pq.pop();
}
}
vector<string> res;
while (!pq.empty()) {
res.push_back(pq.top().second);
pq.pop();
}
return vector<string>(res.rbegin(), res.rend());
}
};
693. Binary Number with Alternating Bits
Given a positive integer, check whether it has alternating bits: namely, if two adjacent bits will always have different values.
Example 1:
Input: 5
Output: True
Explanation:
The binary representation of 5 is: 101
Example 2:
Input: 7
Output: False
Explanation:
The binary representation of 7 is: 111.
Example 3:
Input: 11
Output: False
Explanation:
The binary representation of 11 is: 1011.
Example 4:
Input: 10
Output: True
Explanation:
The binary representation of 10 is: 1010.
解题思路:
1. 对数中包含的bit位进行遍历,遇到最后两位相同的情况就返回false。注意&符号的优先级很低,比>还低。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
bool hasAlternatingBits(int n) {
while (n > ) {
if ((n & ) && (n & ) || !(n & ) && !(n & )) {
return false;
}
n >>= ;
}
return true;
}
};
695. Max Area of Island
Given a non-empty 2D array grid of 0's and 1's, an island is a group of 1's (representing land) connected 4-directionally (horizontal or vertical.) You may assume all four edges of the grid are surrounded by water.
Find the maximum area of an island in the given 2D array. (If there is no island, the maximum area is 0.)
Example 1:
[[0,0,1,0,0,0,0,1,0,0,0,0,0],
[0,0,0,0,0,0,0,1,1,1,0,0,0],
[0,1,1,0,1,0,0,0,0,0,0,0,0],
[0,1,0,0,1,1,0,0,1,0,1,0,0],
[0,1,0,0,1,1,0,0,1,1,1,0,0],
[0,0,0,0,0,0,0,0,0,0,1,0,0],
[0,0,0,0,0,0,0,1,1,1,0,0,0],
[0,0,0,0,0,0,0,1,1,0,0,0,0]]
Given the above grid, return 6. Note the answer is not11, because the island must be connected 4-directionally.
Example 2:
[[0,0,0,0,0,0,0,0]]
Given the above grid, return 0.
Note: The length of each dimension in the given grid does not exceed 50.
解题思路:
1. 定义递归函数返回从当前位置出发深度优先遍历得到的面积。改写位置上的数来标志其是否被访问过。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
int directions[][] = {{-, }, {, }, {, -}, {, }};
int maxAreaOfIsland(vector<vector<int>>& grid) {
int maxArea = ;
if (grid.empty() || grid[].empty()) {
return maxArea;
}
int m = grid.size(), n = grid[].size();
for (int i = ; i < m; i++) {
for (int j = ; j < n; j++) {
if (grid[i][j] == ) {
maxArea = max(maxArea, maxAreaHelper(grid, m, n, i, j));
}
}
}
return maxArea;
}
int maxAreaHelper(vector<vector<int>>& grid, int& m, int& n, int i, int j) {
int area = ;
grid[i][j] = -;
for (int k = ; k < ; k++) {
int next_i = i + directions[k][], next_j = j + directions[k][];
if (next_i < || next_j < || next_i >= m || next_j >= n || grid[next_i][next_j] != ) {
continue;
}
area += maxAreaHelper(grid, m, n, next_i, next_j);
}
return area;
}
};
696. Count Binary Substrings
Give a string s, count the number of non-empty (contiguous) substrings that have the same number of 0's and 1's, and all the 0's and all the 1's in these substrings are grouped consecutively.
Substrings that occur multiple times are counted the number of times they occur.
Example 1:
Input: "00110011"
Output: 6
Explanation: There are 6 substrings that have equal number of consecutive 1's and 0's: "0011", "01", "1100", "10", "0011", and "01".
Notice that some of these substrings repeat and are counted the number of times they occur.
Also, "00110011" is not a valid substring because all the 0's (and 1's) are not grouped together.
Example 2:
Input: "10101"
Output: 4
Explanation: There are 4 substrings: "10", "01", "10", "01" that have equal number of consecutive 1's and 0's.
Note:
s.lengthwill be between 1 and 50,000.swill only consist of "0" or "1" characters.
解题思路:
1. 统计连续出现的相同字符的次数,在间隔的数字之间较小的数字为其所能组成的子串对数。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
int countBinarySubstrings(string s) {
vector<int> nums;
int count = ;
for (int i = ; i < s.size(); i++) {
if (s[i] == s[i - ]) {
count++;
} else {
nums.push_back(count);
count = ;
}
}
nums.push_back(count);
int sum = ;
for (int i = ; i < nums.size(); i++) {
sum += min(nums[i - ], nums[i]);
}
return sum;
}
};
697. Degree of an Array
Given a non-empty array of non-negative integers nums, the degree of this array is defined as the maximum frequency of any one of its elements.
Your task is to find the smallest possible length of a (contiguous) subarray of nums, that has the same degree as nums.
Example 1:
Input: [1, 2, 2, 3, 1]
Output: 2
Explanation:
The input array has a degree of 2 because both elements 1 and 2 appear twice.
Of the subarrays that have the same degree:
[1, 2, 2, 3, 1], [1, 2, 2, 3], [2, 2, 3, 1], [1, 2, 2], [2, 2, 3], [2, 2]
The shortest length is 2. So return 2.
Example 2:
Input: [1,2,2,3,1,4,2]
Output: 6
Note:
nums.lengthwill be between 1 and 50,000.nums[i]will be an integer between 0 and 49,999.
解题思路:
1. 出现频率与整个数组的度相同,那么一定是出现在最高频率元素的两边。取这之间距离的最小值即可。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
int findShortestSubArray(vector<int>& nums) {
map<int, pair<int, int>> dict;
int maxFreq = , minLen = INT_MAX;
for (int i = ; i < nums.size(); i++) {
if (!dict.count(nums[i])) {
dict[nums[i]] = pair<int, int>(i, );
} else {
dict[nums[i]].second++;
}
if (dict[nums[i]].second > maxFreq) {
maxFreq = dict[nums[i]].second;
minLen = i - dict[nums[i]].first + ;
} else if (dict[nums[i]].second == maxFreq) {
minLen = min(minLen, i - dict[nums[i]].first + );
}
}
return minLen;
}
};
698. Partition to K Equal Sum Subsets
Given an array of integers nums and a positive integer k, find whether it's possible to divide this array into k non-empty subsets whose sums are all equal.
Example 1:
Input: nums = [4, 3, 2, 3, 5, 2, 1], k = 4
Output: True
Explanation: It's possible to divide it into 4 subsets (5), (1, 4), (2,3), (2,3) with equal sums.
Note:
1 <= k <= len(nums) <= 16.0 < nums[i] < 10000.
解题思路:
1. 使用递归的方式求每一组全部的可能性。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
bool canPartitionKSubsets(vector<int>& nums, int k) {
int sum = ;
for (auto num : nums) {
sum += num;
}
sort(nums.begin(), nums.end(), greater<int>());
if ((sum % k) || nums[] > (sum / k)) {
return false;
}
int average = sum / k;
vector<bool> canUse(nums.size(), true);
return partitionHelper(nums, canUse, average, average, , k);
}
bool partitionHelper(vector<int>& nums, vector<bool>& canUse, int& average, int target, int begin, int k) {
if (k == ) {
return true;
}
if (target == ) {
return partitionHelper(nums, canUse, average, average, , k - );
}
for (int i = begin; i < nums.size(); i++) {
if (!canUse[i] || nums[i] > target) {
continue;
}
canUse[i] = false;
if (partitionHelper(nums, canUse, average, target - nums[i], i + , k)) {
return true;
}
canUse[i] = true;
}
return false;
}
};
699. Falling Squares
On an infinite number line (x-axis), we drop given squares in the order they are given.
The i-th square dropped (positions[i] = (left, side_length)) is a square with the left-most point being positions[i][0]and sidelength positions[i][1].
The square is dropped with the bottom edge parallel to the number line, and from a higher height than all currently landed squares. We wait for each square to stick before dropping the next.
The squares are infinitely sticky on their bottom edge, and will remain fixed to any positive length surface they touch (either the number line or another square). Squares dropped adjacent to each other will not stick together prematurely.
Return a list ans of heights. Each height ans[i] represents the current highest height of any square we have dropped, after dropping squares represented by positions[0], positions[1], ..., positions[i].
Example 1:
Input: [[1, 2], [2, 3], [6, 1]]
Output: [2, 5, 5]
Explanation:
After the first drop of positions[0] = [1, 2]: _aa _aa ------- The maximum height of any square is 2.
After the second drop of positions[1] = [2, 3]: __aaa __aaa __aaa _aa__ _aa__ -------------- The maximum height of any square is 5. The larger square stays on top of the smaller square despite where its center of gravity is, because squares are infinitely sticky on their bottom edge.
After the third drop of positions[1] = [6, 1]: __aaa __aaa __aaa _aa _aa___a -------------- The maximum height of any square is still 5. Thus, we return an answer of [2, 5, 5].
Example 2:
Input: [[100, 100], [200, 100]]
Output: [100, 100]
Explanation: Adjacent squares don't get stuck prematurely - only their bottom edge can stick to surfaces.
Note:
1 <= positions.length <= 1000.1 <= positions[i][0] <= 10^8.1 <= positions[i][1] <= 10^6.
解题思路:
1. 这题采用比较简单的方式,就是双层遍历的方法去解决即可。每次加入一个正方形后,就讲其带来的影响改写到后面。
刷题记录:
1. 一刷,没有思路。
class Solution {
public:
vector<int> fallingSquares(vector<pair<int, int>>& positions) {
int maxHeight = ;
int len = positions.size();
vector<int> res;
vector<int> heights(len, );
for (int i = ; i < len; i++) {
heights[i] += positions[i].second;
maxHeight = max(maxHeight, heights[i]);
res.push_back(maxHeight);
int left = positions[i].first, right = positions[i].first + positions[i].second;
for (int j = i + ; j < len; j++) {
if (positions[j].first + positions[j].second <= left || positions[j].first >= right) {
continue;
}
heights[j] = max(heights[j], heights[i]);
}
}
return res;
}
};
712. Minimum ASCII Delete Sum for Two Strings
Given two strings s1, s2, find the lowest ASCII sum of deleted characters to make two strings equal.
Example 1:
Input: s1 = "sea", s2 = "eat"
Output: 231
Explanation: Deleting "s" from "sea" adds the ASCII value of "s" (115) to the sum.
Deleting "t" from "eat" adds 116 to the sum.
At the end, both strings are equal, and 115 + 116 = 231 is the minimum sum possible to achieve this.
Example 2:
Input: s1 = "delete", s2 = "leet"
Output: 403
Explanation: Deleting "dee" from "delete" to turn the string into "let",
adds 100[d]+101[e]+101[e] to the sum. Deleting "e" from "leet" adds 101[e] to the sum.
At the end, both strings are equal to "let", and the answer is 100+101+101+101 = 403.
If instead we turned both strings into "lee" or "eet", we would get answers of 433 or 417, which are higher.
Note:
0 < s1.length, s2.length <= 1000.- All elements of each string will have an ASCII value in
[97, 122].
解题思路:
1. 使用动态规划的方法,用下标表示字符串之间进行转换的范围。每次比较当前的字符是否相同来确定较小的变换方法。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
int minimumDeleteSum(string s1, string s2) {
int len1 = s1.size(), len2 = s2.size();
vector<vector<int>> dp(len1 + , vector<int>(len2 + , ));
for (int j = ; j <= len2; j++) {
dp[][j] += dp[][j - ] + s2[j - ];
}
for (int i = ; i <= len1; i++) {
dp[i][] = dp[i - ][] + s1[i - ];
}
for (int i = ; i <= len1; i++) {
for (int j = ; j <= len2; j++) {
if (s1[i - ] == s2[j - ]) {
dp[i][j] = dp[i - ][j - ];
} else {
dp[i][j] = min(dp[i - ][j] + s1[i - ], dp[i][j - ] + s2[j - ]);
}
}
}
return dp[len1][len2];
}
};
713. Subarray Product Less Than K
Your are given an array of positive integers nums.
Count and print the number of (contiguous) subarrays where the product of all the elements in the subarray is less than k.
Example 1:
Input: nums = [10, 5, 2, 6], k = 100
Output: 8
Explanation: The 8 subarrays that have product less than 100 are: [10], [5], [2], [6], [10, 5], [5, 2], [2, 6], [5, 2, 6].
Note that [10, 5, 2] is not included as the product of 100 is not strictly less than k.
Note:
0 < nums.length <= 50000.0 < nums[i] < 1000.0 <= k < 10^6.
解题思路:
1. 有两种方法可以解决这个问题,一种是用log将乘积转化为求和的形式,然后在以不同位置元素为左边界的情况下用二分查找寻找右边界并将范围加入到返回统计量中。另一种是采用滑动窗口,窗口每次往右滑动一位,根据当前乘积是否满足要求选择左边是否滑动。
刷题记录:
1. 一刷,没有注意到k<=1点corner case
class Solution {
public:
int numSubarrayProductLessThanK(vector<int>& nums, int k) {
if (k <= ) {
return ;
}
int count = , left = , right = -;
int len = nums.size();
int product = ;
while (right < len) {
while (right < len && product < k) {
count += right - left + ;
if (right + < len) {
product *= nums[right + ];
}
right++;
}
while (left <= right && product >= k) {
if (left < len) {
product /= nums[left];
}
left++;
}
}
return count;
}
};
714. Best Time to Buy and Sell Stock with Transaction Fee
Your are given an array of integers prices, for which the i-th element is the price of a given stock on day i; and a non-negative integer fee representing a transaction fee.
You may complete as many transactions as you like, but you need to pay the transaction fee for each transaction. You may not buy more than 1 share of a stock at a time (ie. you must sell the stock share before you buy again.)
Return the maximum profit you can make.
Example 1:
Input: prices = [1, 3, 2, 8, 4, 9], fee = 2
Output: 8
Explanation: The maximum profit can be achieved by:
- Buying at prices[0] = 1
- Selling at prices[3] = 8
- Buying at prices[4] = 4
- Selling at prices[5] = 9
The total profit is ((8 - 1) - 2) + ((9 - 4) - 2) = 8.
Note:
0 < prices.length <= 50000.0 < prices[i] < 50000.0 <= fee < 50000.
解题思路:
1. 自己采用的是逻辑的方法。这题用动态规划更好做,用两个变量存储当前天结束时,完整交易所能获得的最大利益和当前持有一个股票的最大利益。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
int maxProfit(vector<int>& prices, int fee) {
int low = prices[], high = -;
int profit = ;
for (int i = ; i < prices.size(); i++) {
if (prices[i] > prices[i - ]) {
high = max(high, prices[i]);
} else if (prices[i] < prices[i - ]){
if (high == -) {
low = min(low, prices[i]);
} else if (high - prices[i] > fee && high - low > fee) {
profit += high - low - fee;
low = prices[i];
high = -;
} else if (prices[i] < low) {
low = prices[i];
high = -;
}
}
}
if (high != - && high - low > fee) {
profit += high - low - fee;
}
return profit;
}
};
715. Range Module
A Range Module is a module that tracks ranges of numbers. Your task is to design and implement the following interfaces in an efficient manner.
addRange(int left, int right)Adds the half-open interval[left, right), tracking every real number in that interval. Adding an interval that partially overlaps with currently tracked numbers should add any numbers in the interval[left, right)that are not already tracked.
queryRange(int left, int right)Returns true if and only if every real number in the interval[left, right)is currently being tracked.
removeRange(int left, int right)Stops tracking every real number currently being tracked in the interval[left, right).
Example 1:
addRange(10, 20): null
removeRange(14, 16): null
queryRange(10, 14): true (Every number in [10, 14) is being tracked)
queryRange(13, 15): false (Numbers like 14, 14.03, 14.17 in [13, 15) are not being tracked)
queryRange(16, 17): true (The number 16 in [16, 17) is still being tracked, despite the remove operation)
Note:
- A half openinterval
[left, right)denotes all real numbersleft <= x < right. 0 < left < right < 10^9in all calls toaddRange, queryRange, removeRange.- The total number of calls to
addRangein a single test case is at most1000. - The total number of calls to
queryRangein a single test case is at most5000. - The total number of calls to
removeRangein a single test case is at most1000.
解题思路:
1. 使用线性遍历就可以完成对向量元素的插入和修改。因为插入的时间复杂度为O(N),所以没有必要用二分查找。
刷题记录:
1. 一刷,整体思路是对的,但是一个向量下标笔误。这种错误代价很大,一定要尽量避免。
struct interval {
int start;
int end;
interval(int a, int b){start = a; end = b;}
};
class RangeModule {
public:
vector<interval> intervals;
RangeModule() {
}
void addRange(int left, int right) {
if (intervals.empty()) {
intervals.push_back(interval(left, right));
}
int len = intervals.size();
int low = , high = len - ;
while (low < high) {
int mid = low + (high - low) / ;
if (left <= intervals[mid].end) {
high = mid;
} else {
low = mid + ;
}
}
int l = left <= intervals[low].end ? low : low + ;
low = ;
high = len - ;
while (low < high) {
int mid = low + ceil((high - low) / 2.0);
if (right >= intervals[mid].start) {
low = mid;
} else {
high = mid - ;
}
}
int r = right >= intervals[high].start ? high : high - ;
if (l > r) {
intervals.insert(intervals.begin() + r + , interval(left, right));
} else if (l == r) {
intervals[l].start = min(intervals[l].start, left);
intervals[l].end = max(intervals[l].end, right);
} else {
left = min(intervals[l].start, left);
right = max(intervals[r].end, right);
intervals.erase(intervals.begin() + l + , intervals.begin() + r + );
intervals[l].start = left;
intervals[l].end = right;
}
return;
}
bool queryRange(int left, int right) {
if (intervals.empty()) {
return false;
}
for (int i = ; i < intervals.size(); i++) {
if (left >= intervals[i].start && right <= intervals[i].end) {
return true;
}
}
return false;
}
void removeRange(int left, int right) {
if (intervals.empty()) {
intervals.push_back(interval(left, right));
}
int len = intervals.size();
int low = , high = len - ;
while (low < high) {
int mid = low + (high - low) / ;
if (left < intervals[mid].end) {
high = mid;
} else {
low = mid + ;
}
}
int l = left < intervals[low].end ? low : low + ;
low = ;
high = len - ;
while (low < high) {
int mid = low + ceil((high - low) / 2.0);
if (right > intervals[mid].start) {
low = mid;
} else {
high = mid - ;
}
}
int r = right > intervals[high].start ? high : high - ;
if (l == r) {
if (left > intervals[l].start && right < intervals[l].end) {
intervals.insert(intervals.begin() + l + , interval(right, intervals[l].end));
intervals[l].end = left;
} else if (left <= intervals[l].start && right >= intervals[l].end) {
intervals.erase(intervals.begin() + l);
} else if (right >= intervals[l].end) {
intervals[l].end = left;
} else {
intervals[l].start = right;
}
} else if (l < r) {
if (left <= intervals[l].start && right >= intervals[r].end) {
intervals.erase(intervals.begin() + l, intervals.begin() + r + );
} else if (left > intervals[l].start && right < intervals[r].end) {
intervals[l].end = left;
intervals[r].start = right;
intervals.erase(intervals.begin() + l + , intervals.begin() + r);
} else if (left <= intervals[l].start) {
intervals[r].start = right;
intervals.erase(intervals.begin() + l, intervals.begin() + r);
} else {
intervals[l].end = left;
intervals.erase(intervals.begin() + l + , intervals.begin() + r + );
}
}
return;
}
};
/**
* Your RangeModule object will be instantiated and called as such:
* RangeModule obj = new RangeModule();
* obj.addRange(left,right);
* bool param_2 = obj.queryRange(left,right);
* obj.removeRange(left,right);
*/
717. 1-bit and 2-bit Characters
We have two special characters. The first character can be represented by one bit 0. The second character can be represented by two bits (10 or 11).
Now given a string represented by several bits. Return whether the last character must be a one-bit character or not. The given string will always end with a zero.
Example 1:
Input:
bits = [1, 0, 0]
Output: True
Explanation:
The only way to decode it is two-bit character and one-bit character. So the last character is one-bit character.
Example 2:
Input:
bits = [1, 1, 1, 0]
Output: False
Explanation:
The only way to decode it is two-bit character and two-bit character. So the last character is NOT one-bit character.
Note:
1 <= len(bits) <= 1000.bits[i]is always0or1.
解题思路:
1. 顺序遍历判断
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
bool isOneBitCharacter(vector<int>& bits) {
int len = bits.size();
string bitsStr = "";
for (auto bit : bits) {
bitsStr.push_back('' + bit);
}
return !(len >= && bitsStr.substr(len - , )[] == '' && isValid(bitsStr.substr(, len - )));
}
bool isValid(string str) {
int i = , len = str.size();
while (i < len) {
if (str[i] == '') {
if (++i >= len) {
return false;
}
}
i++;
}
return true;
}
};
721. Accounts Merge
Given a list accounts, each element accounts[i] is a list of strings, where the first element accounts[i][0] is a name, and the rest of the elements are emails representing emails of the account.
Now, we would like to merge these accounts. Two accounts definitely belong to the same person if there is some email that is common to both accounts. Note that even if two accounts have the same name, they may belong to different people as people could have the same name. A person can have any number of accounts initially, but all of their accounts definitely have the same name.
After merging the accounts, return the accounts in the following format: the first element of each account is the name, and the rest of the elements are emails in sorted order. The accounts themselves can be returned in any order.
Example 1:
Input:
accounts = [["John", "johnsmith@mail.com", "john00@mail.com"], ["John", "johnnybravo@mail.com"], ["John", "johnsmith@mail.com", "john_newyork@mail.com"], ["Mary", "mary@mail.com"]]
Output: [["John", 'john00@mail.com', 'john_newyork@mail.com', 'johnsmith@mail.com'], ["John", "johnnybravo@mail.com"], ["Mary", "mary@mail.com"]]
Explanation:
The first and third John's are the same person as they have the common email "johnsmith@mail.com".
The second John and Mary are different people as none of their email addresses are used by other accounts.
We could return these lists in any order, for example the answer [['Mary', 'mary@mail.com'], ['John', 'johnnybravo@mail.com'],
['John', 'john00@mail.com', 'john_newyork@mail.com', 'johnsmith@mail.com']] would still be accepted.
Note:
- The length of
accountswill be in the range[1, 1000]. - The length of
accounts[i]will be in the range[1, 10]. - The length of
accounts[i][j]will be in the range[1, 30].
解题思路:
1. 使用Union Find和DFS搜索均可。
刷题记录:
1. 一刷,没有思路。
class Solution {
public:
vector<vector<string>> accountsMerge(vector<vector<string>>& acts) {
map<string, string> owner;
map<string, string> parents;
map<string, set<string>> unions;
for (int i = ; i < acts.size(); i++) {
for (int j = ; j < acts[i].size(); j++) {
parents[acts[i][j]] = acts[i][j];
owner[acts[i][j]] = acts[i][];
}
}
for (int i = ; i < acts.size(); i++) {
string p = find(acts[i][], parents);
for (int j = ; j < acts[i].size(); j++)
parents[find(acts[i][j], parents)] = p;
}
for (int i = ; i < acts.size(); i++)
for (int j = ; j < acts[i].size(); j++)
unions[find(acts[i][j], parents)].insert(acts[i][j]);
vector<vector<string>> res;
for (pair<string, set<string>> p : unions) {
vector<string> emails(p.second.begin(), p.second.end());
emails.insert(emails.begin(), owner[p.first]);
res.push_back(emails);
}
return res;
}
private:
string find(string s, map<string, string>& p) {
return p[s] == s ? s : find(p[s], p);
}
};
722. Remove Comments
Given a C++ program, remove comments from it. The program source is an array where source[i] is the i-th line of the source code. This represents the result of splitting the original source code string by the newline character \n.
In C++, there are two types of comments, line comments, and block comments.
The string // denotes a line comment, which represents that it and rest of the characters to the right of it in the same line should be ignored.
The string /* denotes a block comment, which represents that all characters until the next (non-overlapping) occurrence of */should be ignored. (Here, occurrences happen in reading order: line by line from left to right.) To be clear, the string /*/ does not yet end the block comment, as the ending would be overlapping the beginning.
The first effective comment takes precedence over others: if the string // occurs in a block comment, it is ignored. Similarly, if the string /* occurs in a line or block comment, it is also ignored.
If a certain line of code is empty after removing comments, you must not output that line: each string in the answer list will be non-empty.
There will be no control characters, single quote, or double quote characters. For example, source = "string s = "/* Not a comment. */";" will not be a test case. (Also, nothing else such as defines or macros will interfere with the comments.)
It is guaranteed that every open block comment will eventually be closed, so /* outside of a line or block comment always starts a new comment.
Finally, implicit newline characters can be deleted by block comments. Please see the examples below for details.
After removing the comments from the source code, return the source code in the same format.
Example 1:
Input:
source = ["/*Test program */", "int main()", "{ ", " // variable declaration ", "int a, b, c;", "/* This is a test", " multiline ", " comment for ", " testing */", "a = b + c;", "}"] The line by line code is visualized as below:
/*Test program */
int main()
{
// variable declaration
int a, b, c;
/* This is a test
multiline
comment for
testing */
a = b + c;
} Output: ["int main()","{ "," ","int a, b, c;","a = b + c;","}"] The line by line code is visualized as below:
int main()
{ int a, b, c;
a = b + c;
} Explanation:
The string/*denotes a block comment, including line 1 and lines 6-9. The string//denotes line 4 as comments.
Example 2:
Input:
source = ["a/*comment", "line", "more_comment*/b"]
Output: ["ab"]
Explanation: The original source string is "a/*comment\nline\nmore_comment*/b", where we have bolded the newline characters. After deletion, the implicit newline characters are deleted, leaving the string "ab", which when delimited by newline characters becomes ["ab"].
Note:
- The length of
sourceis in the range[1, 100]. - The length of
source[i]is in the range[0, 80]. - Every open block comment is eventually closed.
- There are no single-quote, double-quote, or control characters in the source code.
解题思路:
1. 顺序遍历每一行的字符串,对从当前位置开始的前两个字符组成的字符串已经当前是否处于block中进行判断。如果当前为"/*"且不处于block中,那么改写处于block中的状态;如果当前为"*/"且处于block中,那么改写为不处于block中的状态;注意只有当不处于block中时,"//"才可以生效。另外要处理一行结束时仍处于block中的情况,这样多行会汇聚成一行。
刷题记录:
1. 一刷,没有思路。
class Solution {
public:
vector<string> removeComments(vector<string>& source) {
vector<string> res;
bool inBlock = false;
string ans = "";
for (auto str : source) {
int i = , len = str.size();
while (i < len) {
string begin = str.substr(i, );
if (begin == "/*" && !inBlock) {
inBlock = true;
i++;
} else if (begin == "*/" && inBlock) {
inBlock = false;
i++;
} else if (begin == "//" && !inBlock) {
break;
} else if (!inBlock) {
ans.push_back(str[i]);
}
i++;
}
if (!ans.empty() && !inBlock) {
res.push_back(ans);
ans = "";
}
}
return res;
}
};
724. Find Pivot Index
Given an array of integers nums, write a method that returns the "pivot" index of this array.
We define the pivot index as the index where the sum of the numbers to the left of the index is equal to the sum of the numbers to the right of the index.
If no such index exists, we should return -1. If there are multiple pivot indexes, you should return the left-most pivot index.
Example 1:
Input:
nums = [1, 7, 3, 6, 5, 6]
Output: 3
Explanation:
The sum of the numbers to the left of index 3 (nums[3] = 6) is equal to the sum of numbers to the right of index 3.
Also, 3 is the first index where this occurs.
Example 2:
Input:
nums = [1, 2, 3]
Output: -1
Explanation:
There is no index that satisfies the conditions in the problem statement.
Note:
- The length of
numswill be in the range[0, 10000]. - Each element
nums[i]will be an integer in the range[-1000, 1000].
解题思路:
1. 使用前缀序列和数组来存储到每一个下标时前面元素的和,然后遍历元素下标,可以迅速计算出每个元素左边和右边元素和,并能判断是否相同。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
int pivotIndex(vector<int>& nums) {
int len = nums.size();
if (len == ) {
return -;
} else if (len == ) {
return ;
}
vector<int> sums(, );
int sum = ;
for (int i = ; i < len; i++) {
sum += nums[i];
sums.push_back(sum);
}
for (int i = ; i < len; i++) {
if (sums[i] == sum - sums[i + ]) {
return i;
}
}
return -;
}
};
725. Split Linked List in Parts
Given a (singly) linked list with head node root, write a function to split the linked list into k consecutive linked list "parts".
The length of each part should be as equal as possible: no two parts should have a size differing by more than 1. This may lead to some parts being null.
The parts should be in order of occurrence in the input list, and parts occurring earlier should always have a size greater than or equal parts occurring later.
Return a List of ListNode's representing the linked list parts that are formed.
Examples 1->2->3->4, k = 5 // 5 equal parts [ [1], [2], [3], [4], null ]
Example 1:
Input:
root = [1, 2, 3], k = 5
Output: [[1],[2],[3],[],[]]
Explanation:
The input and each element of the output are ListNodes, not arrays.
For example, the input root has root.val = 1, root.next.val = 2, \root.next.next.val = 3, and root.next.next.next = null.
The first element output[0] has output[0].val = 1, output[0].next = null.
The last element output[4] is null, but it's string representation as a ListNode is [].
Example 2:
Input:
root = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10], k = 3
Output: [[1, 2, 3, 4], [5, 6, 7], [8, 9, 10]]
Explanation:
The input has been split into consecutive parts with size difference at most 1, and earlier parts are a larger size than the later parts.
Note:
- The length of
rootwill be in the range[0, 1000]. - Each value of a node in the input will be an integer in the range
[0, 999]. kwill be an integer in the range[1, 50].
解题思路:
1. 首先求出整个链表的长度,然后根据要划分得到的组数求出每一节的平均长度和前面有多少节会包含多一个。然后依次添加入对应数量的链表。
刷题记录:
1. 一刷,BUG FREE
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
vector<ListNode*> splitListToParts(ListNode* root, int k) {
int num = ;
ListNode *p = root;
while (p != NULL) {
num++;
p = p->next;
}
int ave = num / k, remain = num % k;
vector<ListNode*> res;
if (ave == ) {
p = root;
while (p != NULL) {
ListNode *temp = p->next;
p->next = NULL;
res.push_back(p);
p = temp;
}
int remain = k - num;
for (int i = ; i < k - num; i++) {
res.push_back(NULL);
}
} else {
p = root;
for (int i = ; i < k; i++) {
int need = ave + (i < remain ? : );
for (int j = ; j < need - ; j++) {
p = p->next;
}
ListNode *temp = p->next;
p->next = NULL;
res.push_back(root);
root = p = temp;
}
}
return res;
}
};
729. My Calendar I
Implement a MyCalendar class to store your events. A new event can be added if adding the event will not cause a double booking.
Your class will have the method, book(int start, int end). Formally, this represents a booking on the half open interval [start, end), the range of real numbers x such that start <= x < end.
A double booking happens when two events have some non-empty intersection (ie., there is some time that is common to both events.)
For each call to the method MyCalendar.book, return true if the event can be added to the calendar successfully without causing a double booking. Otherwise, return false and do not add the event to the calendar.
Your class will be called like this: MyCalendar cal = new MyCalendar(); MyCalendar.book(start, end)
Example 1:
MyCalendar();
MyCalendar.book(10, 20); // returns true
MyCalendar.book(15, 25); // returns false
MyCalendar.book(20, 30); // returns true
Explanation:
The first event can be booked. The second can't because time 15 is already booked by another event.
The third event can be booked, as the first event takes every time less than 20, but not including 20.
Note:
- The number of calls to
MyCalendar.bookper test case will be at most1000. - In calls to
MyCalendar.book(start, end),startandendare integers in the range[0, 10^9].
解题思路:
1. 对interval的起始位置在排序序列中二分查找,找到其可能插入的位置,这个位置可能需要根据左右边界条件做些微调整。然后判断是否满足book的条件,如果满足则insert入。
刷题记录:
1. 一刷,BUG FREE
struct interval {
int s;
int e;
interval(int start, int end){s = start; e = end;}
};
class MyCalendar {
private:
vector<interval> intervals;
public:
MyCalendar() {
}
bool book(int start, int end) {
int len = (int)intervals.size();
int low = , high = len - ;
while (low < high) {
int mid = low + ceil((high - low) / 2.0);
if (start == intervals[mid].s) {
return false;
} else if (start > intervals[mid].s) {
low = mid;
} else {
high = mid - ;
}
}
if (low >= len || start < intervals[low].s) {
low--;
}
if (low >= && low < len && start < intervals[low].e || low + < len && intervals[low + ].s < end) {
return false;
}
intervals.insert(intervals.begin() + low + , interval(start, end));
return true;
}
};
/**
* Your MyCalendar object will be instantiated and called as such:
* MyCalendar obj = new MyCalendar();
* bool param_1 = obj.book(start,end);
*/
730. Count Different Palindromic Subsequences
Given a string S, find the number of different non-empty palindromic subsequences in S, and return that number modulo 10^9 + 7.
A subsequence of a string S is obtained by deleting 0 or more characters from S.
A sequence is palindromic if it is equal to the sequence reversed.
Two sequences A_1, A_2, ... and B_1, B_2, ... are different if there is some i for which A_i != B_i.
Example 1:
Input:
S = 'bccb'
Output: 6
Explanation:
The 6 different non-empty palindromic subsequences are 'b', 'c', 'bb', 'cc', 'bcb', 'bccb'.
Note that 'bcb' is counted only once, even though it occurs twice.
Example 2:
Input:
S = 'abcdabcdabcdabcdabcdabcdabcdabcddcbadcbadcbadcbadcbadcbadcbadcba'
Output: 104860361
Explanation:
There are 3104860382 different non-empty palindromic subsequences, which is 104860361 modulo 10^9 + 7.
Note:
- The length of
Swill be in the range[1, 1000]. - Each character
S[i]will be in the set{'a', 'b', 'c', 'd'}.
解题思路:
1. 使用带memory的递归函数去解决,对最外层以不同的字母包裹的不同方式进行递归,当找到最外层某种相同的字母时,递归调用原函数找其内部的回文子串。注意当出现一个新的字母时,考虑其单独出现的情况。
刷题记录:
1. 一刷,细节处理有问题。
class Solution {
private:
int base = 1e9 + ;
public:
int countPalindromicSubsequences(string S) {
int start = , end = (int)S.size() - ;
map<pair<int, int>, int> prev;
return countHelper(S, prev, start, end);
}
long long countHelper(string& S, map<pair<int, int>, int>& prev, int start, int end) {
pair<int, int> interval(start, end);
if (prev.count(interval)) {
return prev[interval];
}
long long count = ;
if (start > end) {
return count;
}
set<char> charSet;
while (start <= end) {
if (!charSet.count(S[start])) {
charSet.insert(S[start]);
count++;
} else {
start++;
continue;
}
int temp = end;
while (temp > start && S[temp] != S[start]) {
temp--;
}
if (temp > start) {
count = (count + countHelper(S, prev, start + , temp - ) + ) % base;
}
start++;
if (charSet.size() == ) {
break;
}
}
prev[interval] = count;
return count;
}
};
731. My Calendar II
Implement a MyCalendarTwo class to store your events. A new event can be added if adding the event will not cause a triple booking.
Your class will have one method, book(int start, int end). Formally, this represents a booking on the half open interval [start, end), the range of real numbers x such that start <= x < end.
A triple booking happens when three events have some non-empty intersection (ie., there is some time that is common to all 3 events.)
For each call to the method MyCalendar.book, return true if the event can be added to the calendar successfully without causing a triple booking. Otherwise, return false and do not add the event to the calendar.
Your class will be called like this: MyCalendar cal = new MyCalendar(); MyCalendar.book(start, end)
Example 1:
MyCalendar();
MyCalendar.book(10, 20); // returns true
MyCalendar.book(50, 60); // returns true
MyCalendar.book(10, 40); // returns true
MyCalendar.book(5, 15); // returns false
MyCalendar.book(5, 10); // returns true
MyCalendar.book(25, 55); // returns true
Explanation:
The first two events can be booked. The third event can be double booked.
The fourth event (5, 15) can't be booked, because it would result in a triple booking.
The fifth event (5, 10) can be booked, as it does not use time 10 which is already double booked.
The sixth event (25, 55) can be booked, as the time in [25, 40) will be double booked with the third event;
the time [40, 50) will be single booked, and the time [50, 55) will be double booked with the second event.
Note:
- The number of calls to
MyCalendar.bookper test case will be at most1000. - In calls to
MyCalendar.book(start, end),startandendare integers in the range[0, 10^9].
解题思路:
1. 可以直接用双层循环的方式,首先找到目标时间段与已遍历部分的重叠部分,然后判断该重叠部分与之后的时间是否有重合。如果有,则返回false;没有,则直接加入到向量中。
刷题记录:
1. 一刷,没有思路。
struct interval {
int start, end;
interval(int s, int e) {start = s; end = e;}
};
class MyCalendarTwo {
public:
vector<interval> intervals;
MyCalendarTwo() {
}
bool book(int start, int end) {
int len = (int)intervals.size();
for (int i = ; i < len; i++) {
int oStart = max(start, intervals[i].start), oEnd = min(end, intervals[i].end);
if (oStart < oEnd) {
for (int j = i + ; j < len; j++) {
if (max(oStart, intervals[j].start) < min(oEnd, intervals[j].end)) {
return false;
}
}
}
}
intervals.push_back(interval(start, end));
return true;
}
};
/**
* Your MyCalendarTwo object will be instantiated and called as such:
* MyCalendarTwo obj = new MyCalendarTwo();
* bool param_1 = obj.book(start,end);
*/
732. My Calendar III
Implement a MyCalendarThree class to store your events. A new event can always be added.
Your class will have one method, book(int start, int end). Formally, this represents a booking on the half open interval [start, end), the range of real numbers x such that start <= x < end.
A K-booking happens when K events have some non-empty intersection (ie., there is some time that is common to all K events.)
For each call to the method MyCalendar.book, return an integer K representing the largest integer such that there exists a K-booking in the calendar.
Your class will be called like this: MyCalendarThree cal = new MyCalendarThree(); MyCalendarThree.book(start, end)
Example 1:
MyCalendarThree();
MyCalendarThree.book(10, 20); // returns 1
MyCalendarThree.book(50, 60); // returns 1
MyCalendarThree.book(10, 40); // returns 2
MyCalendarThree.book(5, 15); // returns 3
MyCalendarThree.book(5, 10); // returns 3
MyCalendarThree.book(25, 55); // returns 3
Explanation:
The first two events can be booked and are disjoint, so the maximum K-booking is a 1-booking.
The third event [10, 40) intersects the first event, and the maximum K-booking is a 2-booking.
The remaining events cause the maximum K-booking to be only a 3-booking.
Note that the last event locally causes a 2-booking, but the answer is still 3 because
eg. [10, 20), [10, 40), and [5, 15) are still triple booked.
Note:
- The number of calls to
MyCalendarThree.bookper test case will be at most400. - In calls to
MyCalendarThree.book(start, end),startandendare integers in the range[0, 10^9].
解题思路:
1. 使用键值表来存储边界上的间隔个数,如果是start则++,如果是end则--。顺序遍历所有的边界值,即可找到最大的overlap数量。因为其一定出现在边界上。
刷题记录:
1. 一刷,没有思路。
class MyCalendarThree {
public:
map<int, int> boundry;
MyCalendarThree() {
}
int book(int start, int end) {
boundry[start]++;
boundry[end]--;
int maxOverlap = , cur = ;
for (map<int, int>::iterator it = boundry.begin(); it != boundry.end(); it++) {
cur += it->second;
if (cur > maxOverlap) {
maxOverlap = cur;
}
}
return maxOverlap;
}
};
/**
* Your MyCalendarThree object will be instantiated and called as such:
* MyCalendarThree obj = new MyCalendarThree();
* int param_1 = obj.book(start,end);
*/
733. Flood Fill
An image is represented by a 2-D array of integers, each integer representing the pixel value of the image (from 0 to 65535).
Given a coordinate (sr, sc) representing the starting pixel (row and column) of the flood fill, and a pixel value newColor, "flood fill" the image.
To perform a "flood fill", consider the starting pixel, plus any pixels connected 4-directionally to the starting pixel of the same color as the starting pixel, plus any pixels connected 4-directionally to those pixels (also with the same color as the starting pixel), and so on. Replace the color of all of the aforementioned pixels with the newColor.
At the end, return the modified image.
Example 1:
Input:
image = [[1,1,1],[1,1,0],[1,0,1]]
sr = 1, sc = 1, newColor = 2
Output: [[2,2,2],[2,2,0],[2,0,1]]
Explanation:
From the center of the image (with position (sr, sc) = (1, 1)), all pixels connected
by a path of the same color as the starting pixel are colored with the new color.
Note the bottom corner is not colored 2, because it is not 4-directionally connected
to the starting pixel.
Note:
- The length of
imageandimage[0]will be in the range[1, 50]. - The given starting pixel will satisfy
0 <= sr < image.lengthand0 <= sc < image[0].length. - The value of each color in
image[i][j]andnewColorwill be an integer in[0, 65535].
解题思路:
1. 递归向周围四个方向延伸即可。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
int dirs[][] = {{-, }, {, }, {, -}, {, }};
vector<vector<int>> floodFill(vector<vector<int>>& image, int sr, int sc, int newColor) {
if (image[sr][sc] == newColor) {
return image;
}
int target = image[sr][sc];
helper(image, sr, sc, target, newColor);
return image;
}
void helper(vector<vector<int>>& image, int i, int j, int& target, int& newColor) {
int row = image.size(), col = image[].size();
image[i][j] = newColor;
for (int k = ; k < ; k++) {
int next_i = i + dirs[k][], next_j = j + dirs[k][];
if (next_i < || next_i >= row || next_j < || next_j >= col || image[next_i][next_j] != target) {
continue;
}
helper(image, next_i, next_j, target, newColor);
}
return;
}
};
735. Asteroid Collision
We are given an array asteroids of integers representing asteroids in a row.
For each asteroid, the absolute value represents its size, and the sign represents its direction (positive meaning right, negative meaning left). Each asteroid moves at the same speed.
Find out the state of the asteroids after all collisions. If two asteroids meet, the smaller one will explode. If both are the same size, both will explode. Two asteroids moving in the same direction will never meet.
Example 1:
Input:
asteroids = [5, 10, -5]
Output: [5, 10]
Explanation:
The 10 and -5 collide resulting in 10. The 5 and 10 never collide.
Example 2:
Input:
asteroids = [8, -8]
Output: []
Explanation:
The 8 and -8 collide exploding each other.
Example 3:
Input:
asteroids = [10, 2, -5]
Output: [10]
Explanation:
The 2 and -5 collide resulting in -5. The 10 and -5 collide resulting in 10.
Example 4:
Input:
asteroids = [-2, -1, 1, 2]
Output: [-2, -1, 1, 2]
Explanation:
The -2 and -1 are moving left, while the 1 and 2 are moving right.
Asteroids moving the same direction never meet, so no asteroids will meet each other.
Note:
- The length of
asteroidswill be at most10000. - Each asteroid will be a non-zero integer in the range
[-1000, 1000]..
解题思路:
1. 使用一个栈的方式用来存储之前的星球,当遍历原向量得到的星球为正数,直接入栈;当为负数,则可能与栈中的星球发生碰撞。因此对栈中的星球进行出栈碰撞处理。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
vector<int> asteroidCollision(vector<int>& asteroids) {
stack<int> planets;
for (auto asteroid : asteroids) {
if (asteroid > ) {
planets.push(asteroid);
continue;
}
while (!planets.empty() && planets.top() > ) {
if (planets.top() < -asteroid) {
planets.pop();
} else {
if (planets.top() == -asteroid) {
planets.pop();
}
asteroid = ;
break;
}
}
if (asteroid != ) {
planets.push(asteroid);
}
}
vector<int> res;
while (!planets.empty()) {
res.push_back(planets.top());
planets.pop();
}
reverse(res.begin(), res.end());
return res;
}
};
736. Parse Lisp Expression
You are given a string expression representing a Lisp-like expression to return the integer value of.
The syntax for these expressions is given as follows.
- An expression is either an integer, a let-expression, an add-expression, a mult-expression, or an assigned variable. Expressions always evaluate to a single integer.
- (An integer could be positive or negative.)
- A let-expression takes the form
(let v1 e1 v2 e2 ... vn en expr), whereletis always the string"let", then there are 1 or more pairs of alternating variables and expressions, meaning that the first variablev1is assigned the value of the expressione1, the second variablev2is assigned the value of the expressione2, and so on sequentially; and then the value of this let-expression is the value of the expressionexpr.
- An add-expression takes the form
(add e1 e2)whereaddis always the string"add", there are always two expressionse1, e2, and this expression evaluates to the addition of the evaluation ofe1and the evaluation ofe2.
- A mult-expression takes the form
(mult e1 e2)wheremultis always the string"mult", there are always two expressionse1, e2, and this expression evaluates to the multiplication of the evaluation ofe1and the evaluation ofe2.
- For the purposes of this question, we will use a smaller subset of variable names. A variable starts with a lowercase letter, then zero or more lowercase letters or digits. Additionally for your convenience, the names "add", "let", or "mult" are protected and will never be used as variable names.
- Finally, there is the concept of scope. When an expression of a variable name is evaluated, within the context of that evaluation, the innermost scope (in terms of parentheses) is checked first for the value of that variable, and then outer scopes are checked sequentially. It is guaranteed that every expression is legal. Please see the examples for more details on scope.
Evaluation Examples:
Input: (add 1 2)
Output: 3 Input: (mult 3 (add 2 3))
Output: 15 Input: (let x 2 (mult x 5))
Output: 10 Input: (let x 2 (mult x (let x 3 y 4 (add x y))))
Output: 14
Explanation: In the expression (add x y), when checking for the value of the variable x,
we check from the innermost scope to the outermost in the context of the variable we are trying to evaluate.
Since x = 3 is found first, the value of x is 3. Input: (let x 3 x 2 x)
Output: 2
Explanation: Assignment in let statements is processed sequentially. Input: (let x 1 y 2 x (add x y) (add x y))
Output: 5
Explanation: The first (add x y) evaluates as 3, and is assigned to x.
The second (add x y) evaluates as 3+2 = 5. Input: (let x 2 (add (let x 3 (let x 4 x)) x))
Output: 6
Explanation: Even though (let x 4 x) has a deeper scope, it is outside the context
of the final x in the add-expression. That final x will equal 2. Input: (let a1 3 b2 (add a1 1) b2)
Output 4
Explanation: Variable names can contain digits after the first character.
Note:
- The given string
expressionis well formatted: There are no leading or trailing spaces, there is only a single space separating different components of the string, and no space between adjacent parentheses. The expression is guaranteed to be legal and evaluate to an integer. - The length of
expressionis at most 2000. (It is also non-empty, as that would not be a legal expression.) - The answer and all intermediate calculations of that answer are guaranteed to fit in a 32-bit integer.
解题思路:
1. 要理清题目的思路和三种不同的操作符情况下如何操作。定义解析字符串的函数和计算值的函数帮助执行。采用递归的方式。顺序解析字符串时,可以将表示起始位置的参数作为引用传递,这样使得下一次的结果依赖于上一次的。
刷题记录:
1. 一刷,没有思路。
class Solution {
public:
int evaluate(string expression) {
map<string, int> vars;
return calculate(expression, vars);
}
int calculate(string exp, map<string, int> vars) {
if (exp[] != '(') {
if (exp[] >= 'a' && exp[] <= 'z') {
return vars[exp];
} else {
return stoi(exp);
}
}
exp = exp.substr(, (int)exp.size() - );
int start = ;
string operate = parse(exp, start);
if (operate == "let") {
while () {
string subExp = parse(exp, start);
if (start > exp.size()) {
return calculate(subExp, vars);
}
string value = parse(exp, start);
vars[subExp] = calculate(value, vars);
}
}
if (operate == "add") {
return calculate(parse(exp, start), vars) + calculate(parse(exp, start), vars);
}
if (operate == "mult") {
return calculate(parse(exp, start), vars) * calculate(parse(exp, start), vars);
}
}
string parse(string exp, int& start) {
int temp = start;
if (exp[start] == '(') {
int count = ;
do {
if (exp[temp] == '(') {
count++;
} else if (exp[temp] == ')') {
count--;
}
temp++;
} while (count != );
string ret = exp.substr(start, temp - start);
start = temp + ;
return ret;
}
while (temp < exp.size() && exp[temp] != ' ') {
temp++;
}
string ret = exp.substr(start, temp - start);
start = temp + ;
return ret;
}
};
738. Monotone Increasing Digits
Given a non-negative integer N, find the largest number that is less than or equal to N with monotone increasing digits.
(Recall that an integer has monotone increasing digits if and only if each pair of adjacent digits x and y satisfy x <= y.)
Example 1:
Input: N = 10
Output: 9
Example 2:
Input: N = 1234
Output: 1234
Example 3:
Input: N = 332
Output: 299
Note: N is an integer in the range [0, 10^9].
解题思路:
1. 从数字的尾部往前遍历,如果前面的数小于等于后面的数,那么可以保持原样。否则,当前位置的数减1,后面的数均变成9,用一个整形数标记这个位置。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
int monotoneIncreasingDigits(int N) {
vector<int> digits;
while (N > ) {
digits.push_back(N % );
N /= ;
}
int i = , index = ;
for (; i < digits.size(); i++) {
if (digits[i] > digits[i - ]) {
index = i;
digits[i]--;
}
}
int res = ;
for (int i = (int)digits.size() - ; i >= ; i--) {
res = * res + (i >= index ? digits[i] : );
}
return res;
}
};
739. Daily Temperatures
Given a list of daily temperatures, produce a list that, for each day in the input, tells you how many days you would have to wait until a warmer temperature. If there is no future day for which this is possible, put 0 instead.
For example, given the list temperatures = [73, 74, 75, 71, 69, 72, 76, 73], your output should be [1, 1, 4, 2, 1, 1, 0, 0].
Note: The length of temperatures will be in the range [1, 30000]. Each temperature will be an integer in the range [30, 100].
解题思路:
1. 用一个栈来存储后面的温度,使得在栈中的天数的温度呈现从高到低的排列。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
vector<int> dailyTemperatures(vector<int>& temperatures) {
int len = temperatures.size();
vector<int> res(len, );
stack<int> temper;
for (int i = len - ; i >= ; i--) {
while (!temper.empty() && temperatures[i] >= temperatures[temper.top()]) {
temper.pop();
}
if (!temper.empty()) {
res[i] = temper.top() - i;
}
temper.push(i);
}
return res;
}
};
740. Delete and Earn
Given an array nums of integers, you can perform operations on the array.
In each operation, you pick any nums[i] and delete it to earn nums[i] points. After, you must delete every element equal to nums[i] - 1 or nums[i] + 1.
You start with 0 points. Return the maximum number of points you can earn by applying such operations.
Example 1:
Input: nums = [3, 4, 2]
Output: 6
Explanation:
Delete 4 to earn 4 points, consequently 3 is also deleted.
Then, delete 2 to earn 2 points. 6 total points are earned.
Example 2:
Input: nums = [2, 2, 3, 3, 3, 4]
Output: 9
Explanation:
Delete 3 to earn 3 points, deleting both 2's and the 4.
Then, delete 3 again to earn 3 points, and 3 again to earn 3 points.
9 total points are earned.
Note:
- The length of
numsis at most20000. - Each element
nums[i]is an integer in the range[1, 10000].
解题思路:
1. 用动态规划的办法,用两个变量表示之前选择与不选择的最大收益。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
int deleteAndEarn(vector<int>& nums) {
map<int, int> scores;
for (auto num : nums) {
scores[num] += num;
}
int select = , notSelect = ;
for (map<int, int>::iterator it = scores.begin(); it != scores.end(); it++) {
int temp = notSelect;
notSelect = max(select, notSelect);
if (scores.count(it->first - )) {
select = temp + it->second;
} else {
select = notSelect + it->second;
}
}
return max(select, notSelect);
}
};
741. Cherry Pickup
In a N x N grid representing a field of cherries, each cell is one of three possible integers.
- 0 means the cell is empty, so you can pass through;
- 1 means the cell contains a cherry, that you can pick up and pass through;
- -1 means the cell contains a thorn that blocks your way.
Your task is to collect maximum number of cherries possible by following the rules below:
- Starting at the position (0, 0) and reaching (N-1, N-1) by moving right or down through valid path cells (cells with value 0 or 1);
- After reaching (N-1, N-1), returning to (0, 0) by moving left or up through valid path cells;
- When passing through a path cell containing a cherry, you pick it up and the cell becomes an empty cell (0);
- If there is no valid path between (0, 0) and (N-1, N-1), then no cherries can be collected.
Example 1:
Input: grid =
[[0, 1, -1],
[1, 0, -1],
[1, 1, 1]]
Output: 5
Explanation:
The player started at (0, 0) and went down, down, right right to reach (2, 2).
4 cherries were picked up during this single trip, and the matrix becomes [[0,1,-1],[0,0,-1],[0,0,0]].
Then, the player went left, up, up, left to return home, picking up one more cherry.
The total number of cherries picked up is 5, and this is the maximum possible.
Note:
gridis anNbyN2D array, with1 <= N <= 50.- Each
grid[i][j]is an integer in the set{-1, 0, 1}. - It is guaranteed that grid[0][0] and grid[N-1][N-1] are not -1.
解题思路:
1. 使用动态规划的方法,将原问题转化为两条从起点到终点的问题。如果经过重复的地方,不能采摘多次。用走的步伐数作为外层循环,内层循环为两条路径此时位于的横坐标。其纵坐标可以通过步伐数与横坐标计算出来。
2. 判断每种情况下,是否可能由前一种状态转换而成。当位置重合时,草莓数只能加一。
刷题记录:
1. 一刷,没有思路。
class Solution {
public:
int cherryPickup(vector<vector<int>>& grid) {
int N = grid.size();
vector<vector<int>> dp(N, vector<int>(N, -));
dp[][] = grid[][] == ? : ;
for (int k = ; k < * N - ; k++) {
vector<vector<int>> cur(N, vector<int>(N, -));
for (int i = ; i <= min(N - , k); i++) {
if (k - i > N - ) {
continue;
}
for (int j = ; j <= min(N - , k); j++) {
if (k - j > N - ) {
continue;
}
if (grid[i][k - i] == - || grid[j][k - j] == -) {
continue;
}
int cherries = dp[i][j];
if (i > ) {
cherries = max(cherries, dp[i - ][j]);
}
if (j > ) {
cherries = max(cherries, dp[i][j - ]);
}
if (i > && j > ) {
cherries = max(cherries, dp[i - ][j - ]);
}
if (cherries < ) {
continue;
}
cherries += grid[i][k - i] + (i == j ? : grid[j][k - j]);
cur[i][j] = cherries;
}
}
for (int i = ; i < N; i++) {
for (int j = ; j < N; j++) {
dp[i][j] = cur[i][j];
}
}
}
return max(dp[N - ][N - ], );
}
};
743. Network Delay Time
There are N network nodes, labelled 1 to N.
Given times, a list of travel times as directed edges times[i] = (u, v, w), where u is the source node, v is the target node, and w is the time it takes for a signal to travel from source to target.
Now, we send a signal from a certain node K. How long will it take for all nodes to receive the signal? If it is impossible, return -1.
Note:
Nwill be in the range[1, 100].Kwill be in the range[1, N].- The length of
timeswill be in the range[1, 6000]. - All edges
times[i] = (u, v, w)will have1 <= u, v <= Nand1 <= w <= 100.
解题思路:
1. Dijstra算法
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
int networkDelayTime(vector<vector<int>>& times, int N, int K) {
map<int, vector<pair<int, int>>> route;
for (int i = ; i < times.size(); i++) {
route[times[i][]].push_back(pair<int, int>(times[i][], times[i][]));
}
set<int> arrived;
map<int, int> delay;
delay[K] = ;
int maxDelay = ;
while (!delay.empty()) {
int index = -;
for (map<int, int>::iterator it = delay.begin(); it != delay.end(); it++) {
if (index == - || it->second < delay[index]) {
index = it->first;
}
}
arrived.insert(index);
maxDelay = delay[index];
for (auto r : route[index]) {
if (!arrived.count(r.first)) {
if (delay.count(r.first)) {
delay[r.first] = min(delay[r.first], delay[index] + r.second);
} else {
delay[r.first] = delay[index] + r.second;
}
}
}
delay.erase(index);
}
return arrived.size() == N ? maxDelay : -;
}
};
744. Find Smallest Letter Greater Than Target
Given a list of sorted characters letters containing only lowercase letters, and given a target letter target, find the smallest element in the list that is larger than the given target.
Letters also wrap around. For example, if the target is target = 'z' and letters = ['a', 'b'], the answer is 'a'.
Examples:
Input:
letters = ["c", "f", "j"]
target = "a"
Output: "c" Input:
letters = ["c", "f", "j"]
target = "c"
Output: "f" Input:
letters = ["c", "f", "j"]
target = "d"
Output: "f" Input:
letters = ["c", "f", "j"]
target = "g"
Output: "j" Input:
letters = ["c", "f", "j"]
target = "j"
Output: "c" Input:
letters = ["c", "f", "j"]
target = "k"
Output: "c"
Note:
lettershas a length in range[2, 10000].lettersconsists of lowercase letters, and contains at least 2 unique letters.targetis a lowercase letter.
解题思路:
1. 记录下比目标字符大的最小字符,和整个向量中的最小字符。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
char nextGreatestLetter(vector<char>& letters, char target) {
char res = 'z' + , minChar = 'z';
for (char letter : letters) {
if (letter > target) {
res = min(res, letter);
}
minChar = min(minChar, letter);
}
return res > 'z' ? minChar : res;
}
};
745. Prefix and Suffix Search
Given many words, words[i] has weight i.
Design a class WordFilter that supports one function, WordFilter.f(String prefix, String suffix). It will return the word with given prefix and suffix with maximum weight. If no word exists, return -1.
Examples:
Note:
wordshas length in range[1, 15000].- For each test case, up to
words.lengthqueriesWordFilter.fmay be made. words[i]has length in range[1, 10].prefix, suffixhave lengths in range[0, 10].words[i]andprefix, suffixqueries consist of lowercase letters only.
解题思路:
1. 将单词序列中可能出现的后缀与前缀组合找出来加入到TrieTree中,用'#'分割前后缀,将前缀放置在后面,可以避免对前缀的不同长度进行循环。只要在'#'之后的字符停下,都是符合条件的字符串。
刷题记录:
1. 一刷,超时,只要超时要想到用空间换时间。
class TrieTreeNode {
public:
TrieTreeNode* next[] = { NULL };
int weight;
TrieTreeNode(int weight) {
this->weight = weight;
}
};
class WordFilter {
public:
TrieTreeNode* root;
WordFilter(vector<string> words) {
root = new TrieTreeNode(-);
for (int index = ; index < words.size(); index++) {
string word = words[index];
int len = word.size();
int begin = max(, len - );
string prefix = word.substr(, min(len, ));
for (int i = begin; i <= len; i++) {
Add(word.substr(i) + "#" + prefix, index);
}
}
}
int f(string prefix, string suffix) {
return Search(suffix + "#" + prefix);
}
void Add(string word, int weight) {
TrieTreeNode* p = root;
bool flag = false;
for (auto letter : word) {
if (letter == '#') {
flag = true;
}
if (p->next[letter] == NULL) {
p->next[letter] = new TrieTreeNode(-);
}
p = p->next[letter];
if (flag) {
p->weight = weight;
}
}
}
int Search(string word) {
TrieTreeNode* p = root;
for (auto letter : word) {
if (p->next[letter] == NULL) {
return -;
}
p = p->next[letter];
}
return p->weight;
}
};
/**
* Your WordFilter object will be instantiated and called as such:
* WordFilter obj = new WordFilter(words);
* int param_1 = obj.f(prefix,suffix);
*/
746. Min Cost Climbing Stairs
On a staircase, the i-th step has some non-negative cost cost[i] assigned (0 indexed).
Once you pay the cost, you can either climb one or two steps. You need to find minimum cost to reach the top of the floor, and you can either start from the step with index 0, or the step with index 1.
Example 1:
Example 2:
Note:
costwill have a length in the range[2, 1000].- Every
cost[i]will be an integer in the range[0, 999].
解题思路:
1. 使用动态规划的方式,从后往前遍历。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
int minCostClimbingStairs(vector<int>& cost) {
int len = cost.size();
vector<int> dp(len + , );
for (int i = len - ; i >= ; i--) {
dp[i] = cost[i] + min(dp[i + ], dp[i + ]);
}
return min(dp[], dp[]);
}
};
747. Largest Number At Least Twice of Others
In a given integer array nums, there is always exactly one largest element.
Find whether the largest element in the array is at least twice as much as every other number in the array.
If it is, return the index of the largest element, otherwise return -1.
Example 1:
Example 2:
Note:
numswill have a length in the range[1, 50].- Every
nums[i]will be an integer in the range[0, 99].
解题思路:
1. 找出最大元素对应的下标,然后判断是否符合题目条件。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
int dominantIndex(vector<int>& nums) {
int maxIndex = ;
for (int i = ; i < nums.size(); i++) {
if (nums[i] > nums[maxIndex]) {
maxIndex = i;
}
}
for (int i = ; i < nums.size(); i++) {
if (i != maxIndex && * nums[i] > nums[maxIndex]) {
return -;
}
}
return maxIndex;
}
};
748. Shortest Completing Word
Find the minimum length word from a given dictionary words, which has all the letters from the string licensePlate. Such a word is said to complete the given string licensePlate
Here, for letters we ignore case. For example, "P" on the licensePlate still matches "p" on the word.
It is guaranteed an answer exists. If there are multiple answers, return the one that occurs first in the array.
The license plate might have the same letter occurring multiple times. For example, given a licensePlate of "PP", the word "pair" does not complete the licensePlate, but the word "supper" does.
Example 1:
Example 2:
Note:
licensePlatewill be a string with length in range[1, 7].licensePlatewill contain digits, spaces, or letters (uppercase or lowercase).wordswill have a length in the range[10, 1000].- Every
words[i]will consist of lowercase letters, and have length in range[1, 15].
解题思路:
1. 依次将向量中的单词与目标词作比较,选择最短的。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
string shortestCompletingWord(string licensePlate, vector<string>& words) {
vector<int> letters(, );
int count = ;
for (auto letter : licensePlate) {
letter = tolower(letter);
if (letter >= 'a' && letter <= 'z') {
count++;
letters[letter - 'a']++;
}
}
int index = -;
for (int i = ; i < words.size(); i++) {
if (index != - && words[i].size() >= words[index].size()) {
continue;
}
vector<int> temp(letters);
int num = ;
for (auto letter : words[i]) {
if (--temp[letter - 'a'] >= ) {
num++;
}
}
if (num == count && (index == - || words[i].size() < words[index].size())) {
index = i;
}
}
return words[index];
}
};
749. Contain Virus
A virus is spreading rapidly, and your task is to quarantine the infected area by installing walls.
The world is modeled as a 2-D array of cells, where 0 represents uninfected cells, and 1 represents cells contaminated with the virus. A wall (and only one wall) can be installed between any two 4-directionally adjacent cells, on the shared boundary.
Every night, the virus spreads to all neighboring cells in all four directions unless blocked by a wall. Resources are limited. Each day, you can install walls around only one region -- the affected area (continuous block of infected cells) that threatens the most uninfected cells the following night. There will never be a tie.
Can you save the day? If so, what is the number of walls required? If not, and the world becomes fully infected, return the number of walls used.
Example 1:
Example 2:
Example 3:
Note:
- The number of rows and columns of
gridwill each be in the range[1, 50]. - Each
grid[i][j]will be either0or1. - Throughout the described process, there is always a contiguous viral region that will infect strictly more uncontaminated squares in the next round.
解题思路:
1. 模拟整个流程进行,判断每一块感染区域进行蔓延所能感染的区域数和需要建立的围墙数,选择将会感染最多的区域建立围墙。其他的区域修改被感染的地方。进行下一次循环,直到没有再会被感染的区域。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
int dirs[][] = {{-, }, {, }, {, -}, {, }};
int containVirus(vector<vector<int>>& grid) {
int count = , round = , m = grid.size(), n = grid[].size();
map<pair<int, int>, set<pair<int, int>>> infectedWalls;
while () {
infectedWalls.clear();
pair<int, int> start(-, -);
int walls = -;
for (int i = ; i < m; i++) {
for (int j = ; j < n; j++) {
if (grid[i][j] != round) {
continue;
}
int wallNum = ;
set<pair<int, int>> cells;
infect(grid, cells, wallNum, i, j, m, n, round);
pair<int, int> cur(i, j);
infectedWalls[cur] = cells;
if (!infectedWalls.count(start) || infectedWalls[cur].size() > infectedWalls[start].size()) {
start = cur;
walls = wallNum;
}
}
}
if (walls <= ) {
break;
}
count += walls;
round++;
buildWall(grid, start.first, start.second, m, n, round);
for (auto it : infectedWalls) {
if (it.first == start) {
continue;
}
for (auto _pair : it.second) {
grid[_pair.first][_pair.second] = round;
}
}
}
return count;
}
void infect(vector<vector<int>>& grid, set<pair<int, int>>& infecting, int& wallNum, int x, int y, int& m, int& n, int& round) {
grid[x][y]++;
for (int k = ; k < ; k++) {
int next_x = x + dirs[k][], next_y = y + dirs[k][];
if (next_x < || next_x >= m || next_y < || next_y >= n) {
continue;
}
if (grid[next_x][next_y] == ) {
infecting.insert(pair<int, int>(next_x, next_y));
wallNum++;
} else if(grid[next_x][next_y] == round) {
infect(grid, infecting, wallNum, next_x, next_y, m, n, round);
}
}
}
void buildWall(vector<vector<int>>& grid, int x, int y, int& m, int& n, int& round) {
grid[x][y] = -;
for (int k = ; k < ; k++) {
int next_x = x + dirs[k][], next_y = y + dirs[k][];
if (next_x < || next_x >= m || next_y < || next_y >= n) {
continue;
}
if (grid[next_x][next_y] == round) {
buildWall(grid, next_x, next_y, m, n, round);
}
}
}
};
752. Open the Lock
You have a lock in front of you with 4 circular wheels. Each wheel has 10 slots: '0', '1', '2', '3', '4', '5', '6', '7', '8', '9'. The wheels can rotate freely and wrap around: for example we can turn '9' to be '0', or '0' to be '9'. Each move consists of turning one wheel one slot.
The lock initially starts at '0000', a string representing the state of the 4 wheels.
You are given a list of deadends dead ends, meaning if the lock displays any of these codes, the wheels of the lock will stop turning and you will be unable to open it.
Given a target representing the value of the wheels that will unlock the lock, return the minimum total number of turns required to open the lock, or -1 if it is impossible.
Example 1:
Example 2:
Example 3:
Example 4:
Note:
- The length of
deadendswill be in the range[1, 500]. targetwill not be in the listdeadends.- Every string in
deadendsand the stringtargetwill be a string of 4 digits from the 10,000 possibilities'0000'to'9999'.
解题思路:
1. 使用BFS的方法对从"0000"开始变换,记录已经访问过的lock避免重复遍历。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
int openLock(vector<string>& deadends, string target) {
queue<string> locks;
locks.push("");
set<string> deadend(deadends.begin(), deadends.end());
if (target == "") {
return ;
}
if (deadend.count("")) {
return -;
}
set<string> visited;
visited.insert("");
int steps = ;
while (!locks.empty()) {
steps++;
int len = locks.size();
for (int i = ; i < len; i++) {
string temp = locks.front();
locks.pop();
for (int j = ; j < ; j++) {
for (int k = ; k < ; k++) {
string next = temp;
if (k == ) {
next[j] = next[j] == '' ? '' : next[j] + ;
} else {
next[j] = next[j] == '' ? '' : next[j] - ;
}
if (!visited.count(next) && !deadend.count(next)) {
if (next == target) {
return steps;
}
visited.insert(next);
locks.push(next);
}
}
}
}
}
return -;
}
};
753. Cracking the Safe
There is a box protected by a password. The password is n digits, where each letter can be one of the first k digits 0, 1, ..., k-1.
You can keep inputting the password, the password will automatically be matched against the last n digits entered.
For example, assuming the password is "345", I can open it when I type "012345", but I enter a total of 6 digits.
Please return any string of minimum length that is guaranteed to open the box after the entire string is inputted.
Example 1:
Example 2:
Note:
nwill be in the range[1, 4].kwill be in the range[1, 10].k^nwill be at most4096.
解题思路:
1. 这里假定一个设想成立,即每一次添加一个密码字符都能得到不同的密码串,这样不出现重复覆盖所有可能密码串的字符串存在。
2. 使用深度优先遍历,每次往字符串后添加一个字符保证末尾字符组成新的密码串,遍历覆盖所有的可能性,如果不存在,则返回继续查找。
刷题记录:
1. 一刷,没有思路。
class Solution {
public:
string crackSafe(int n, int k) {
unordered_set<string> strBag;
string str(n, '');
int maxNum = pow(k, n);
strBag.insert(str);
dfs(strBag, maxNum, str, n, k);
return str;
}
bool dfs(unordered_set<string>& strBag, int& maxNum, string& str, int& n, int& k)
{
if (strBag.size() == maxNum)
{
return true;
}
for (int i = ; i < k; ++i)
{
str.push_back('' + i);
string newPassword = str.substr(static_cast<int>(str.size()) - n);
if (strBag.find(newPassword) == strBag.end())
{
strBag.insert(newPassword);
if (dfs(strBag, maxNum, str, n, k))
{
return true;
}
else
{
strBag.erase(newPassword);
}
}
str.pop_back();
}
return false;
}
};
754. Reach a Number
You are standing at position 0 on an infinite number line. There is a goal at position target.
On each move, you can either go left or right. During the n-th move (starting from 1), you take n steps.
Return the minimum number of steps required to reach the destination.
Example 1:
Example 2:
Note:
targetwill be a non-zero integer in the range[-10^9, 10^9].
解题思路:
1. 先寻求最少步数能够达到目标或者超过目标的情况。然后根据超出的步数来判断需要更多几步来进行调整。第一种情况,如果多出步数为偶数,那么只需要将对应1/2步时反向即可。第二种情况多出步数为奇数,那么最多再需要两步进行+-1的调整。那么有没有可能再多一步结合前面的步就能补齐呢,进行计算判断即可。
刷题记录:
1. 一刷,没想到简单思路,采用广度优先遍历超时。
class Solution
{
public:
int reachNumber(int target)
{
target = abs(target);
int k = ceil((- + sqrt( * (double)target + )) / );
int steps = k * (k + ) / ;
if (steps - target != && (steps - target) % == )
{
return (k + - (steps - target)) % == ? k + : k + ;
}
else
{
return k;
}
}
};
756. Pyramid Transition Matrix
We are stacking blocks to form a pyramid. Each block has a color which is a one letter string, like `'Z'`.
For every block of color `C` we place not in the bottom row, we are placing it on top of a left block of color `A` and right block of color `B`. We are allowed to place the block there only if `(A, B, C)` is an allowed triple.
We start with a bottom row of bottom, represented as a single string. We also start with a list of allowed triples allowed. Each allowed triple is represented as a string of length 3.
Return true if we can build the pyramid all the way to the top, otherwise false.
Example 1:
Example 2:
Note:
bottomwill be a string with length in range[2, 8].allowedwill have length in range[0, 200].- Letters in all strings will be chosen from the set
{'A', 'B', 'C', 'D', 'E', 'F', 'G'}.
解题思路:
1. 使用深度优先遍历,依次查找每一种序列的可能性,由底到上,到最顶层。
解题思路:
1. 一刷,BUG FREE
class Solution
{
public:
bool pyramidTransition(string bottom, vector<string>& allowed)
{
unordered_map<char, unordered_map<char, vector<char>>> triples;
for (auto str : allowed)
{
triples[str[]][str[]].push_back(str[]);
} return dfs(triples, bottom);
} bool dfs(unordered_map<char, unordered_map<char, vector<char>>>& triples, string& bottom)
{
if (bottom.size() == )
{
return true;
} vector<string> upper;
string curStr = "";
buildHelper(triples, upper, bottom, , curStr);
for (auto str : upper)
{
if (dfs(triples, str))
{
return true;
}
} return false;
} void buildHelper(unordered_map<char, unordered_map<char, vector<char>>>& triples, vector<string>& strs, string& bottom, int i, string& curStr)
{
if (i == static_cast<int>(bottom.size()) - )
{
strs.push_back(curStr);
return;
} if (triples[bottom[i]].find(bottom[i + ]) != triples[bottom[i]].end())
{
for (auto letter : triples[bottom[i]][bottom[i + ]])
{
curStr.push_back(letter);
buildHelper(triples, strs, bottom, i + , curStr);
curStr.pop_back();
}
}
}
};
757. Set Intersection Size At Least Two
An integer interval [a, b] (for integers a < b) is a set of all consecutive integers from a to b, including a and b.
Find the minimum size of a set S such that for every integer interval A in intervals, the intersection of S with A has size at least 2.
Example 1:
Example 2:
Note:
intervalswill have length in range[1, 3000].intervals[i]will have length2, representing some integer interval.intervals[i][j]will be an integer in[0, 10^8].
解题思路:
1. 按照interval的左界递增排列,然后从尾端开始使用贪心算法,尽量选取最左的值,然后判断未考虑的interval是否有右界大于左值的,那么其所需的元素减一。注意在出现左值相同的情况下时,优先选择右值较小的,保证每次加入到set中的数都不同。
刷题记录:
1. 一刷,没有思路
class Solution {
public:
int intersectionSizeTwo(vector<vector<int>>& intervals) {
int res = ;
sort(intervals.begin(), intervals.end(), [] (const vector<int>& v1, const vector<int>& v2)
{ return v1[] < v2[] || v1[] == v2[] && v1[] > v2[]; });
int len = intervals.size();
vector<int> need(len, );
for (int i = len - ; i >= ; --i)
{
int target = ;
if (need[i] <= )
{
continue;
}
else if (need[i] == )
{
target = intervals[i][];
}
else if (need[i] == )
{
target = intervals[i][] + ;
}
res += need[i];
for (int j = i - ; j >= ; --j)
{
if (need[j] > && intervals[j][] >= intervals[i][])
{
need[j] -= (min(intervals[j][], target) - intervals[i][] + );
}
}
}
return res;
}
};
761. Special Binary String
Special binary strings are binary strings with the following two properties:
- The number of 0's is equal to the number of 1's.
- Every prefix of the binary string has at least as many 1's as 0's.
Given a special string S, a move consists of choosing two consecutive, non-empty, special substrings of S, and swapping them. (Two strings are consecutive if the last character of the first string is exactly one index before the first character of the second string.)
At the end of any number of moves, what is the lexicographically largest resulting string possible?
Example 1:
Note:
Shas length at most50.Sis guaranteed to be a special binary string as defined above.
解题思路:
1. 尽量多的递归调整原字符串。
刷题记录:
1. 一刷,没有思路
class Solution {
public:
string makeLargestSpecial(string S) {
vector<string> strs;
int i = , count = ;
for (int j = ; j < S.size(); ++j)
{
if (S[j] == '')
{
++count;
}
else
{
--count;
}
if (count == )
{
strs.push_back("" + makeLargestSpecial(S.substr(i + , j - i - )) + "");
i = j + ;
}
}
sort(strs.begin(), strs.end(), greater<string>());
string res = "";
for (auto str : strs)
{
res.append(str);
}
return res;
}
};
762. Prime Number of Set Bits in Binary Representation
Given two integers L and R, find the count of numbers in the range [L, R] (inclusive) having a prime number of set bits in their binary representation.
(Recall that the number of set bits an integer has is the number of 1s present when written in binary. For example, 21 written in binary is 10101 which has 3 set bits. Also, 1 is not a prime.)
Example 1:
Example 2:
Note:
L, Rwill be integersL <= Rin the range[1, 10^6].R - Lwill be at most 10000.
解题思路:
1. 直接对所有数遍历即可。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
int countPrimeSetBits(int L, int R) {
vector<bool> isPrime(, true);
isPrime[] = false;
isPrime[] = false;
isPrime[] = true;
int len = isPrime.size();
for (int i = ; i < len; ++i)
{
for (int j = ; j <= i; ++j)
{
if (i * j < len)
{
isPrime[i * j] = false;
}
else
{
break;
}
}
}
int res = ;
for (int num = L; num <= R; ++num)
{
if (isPrime[GetNumOfSetBits(num)])
{
++res;
}
}
return res;
}
int GetNumOfSetBits(int num)
{
int res = ;
while (num > )
{
num &= (num - );
++res;
}
return res;
}
};
@
780. Reaching Points
A move consists of taking a point (x, y) and transforming it to either (x, x+y) or (x+y, y).
Given a starting point (sx, sy) and a target point (tx, ty), return True if and only if a sequence of moves exists to transform the point (sx, sy) to (tx, ty). Otherwise, return False.
Examples:
Input: sx = 1, sy = 1, tx = 3, ty = 5
Output: True
Explanation:
One series of moves that transforms the starting point to the target is:
(1, 1) -> (1, 2)
(1, 2) -> (3, 2)
(3, 2) -> (3, 5) Input: sx = 1, sy = 1, tx = 2, ty = 2
Output: False Input: sx = 1, sy = 1, tx = 1, ty = 1
Output: True
Note:
sx, sy, tx, tywill all be integers in the range[1, 10^9].
解题思路:
1. 横纵坐标之间,较大的坐标最后一定是由较小的坐标相加得来的,因此可以循环用较大的坐标对较小坐标取余,直到目标坐标小于等于初始坐标。
刷题记录:
1. 一刷,没有思路
class Solution {
public:
bool reachingPoints(int sx, int sy, int tx, int ty) {
while (tx >= sx && ty >= sy) {
if (tx == sx) {
return ((ty - sy) % sx) == ;
}
if (ty == sy) {
return ((tx - sx) % sy) == ;
}
if (tx >= ty) {
tx = tx % ty;
} else {
ty = ty % tx;
}
}
return false;
}
};
781. Rabbits in Forest
In a forest, each rabbit has some color. Some subset of rabbits (possibly all of them) tell you how many other rabbits have the same color as them. Those answers are placed in an array.
Return the minimum number of rabbits that could be in the forest.
Examples:
Input: answers = [1, 1, 2]
Output: 5
Explanation:
The two rabbits that answered "1" could both be the same color, say red.
The rabbit than answered "2" can't be red or the answers would be inconsistent.
Say the rabbit that answered "2" was blue.
Then there should be 2 other blue rabbits in the forest that didn't answer into the array.
The smallest possible number of rabbits in the forest is therefore 5: 3 that answered plus 2 that didn't. Input: answers = [10, 10, 10]
Output: 11 Input: answers = []
Output: 0
Note:
answerswill have length at most1000.- Each
answers[i]will be an integer in the range[0, 999].
解题思路:
1. 相同颜色的兔子如果被访问到,其答案一定是相同的。相同颜色的兔子数等于其答案数加1,如果访问的兔子数大于其值,那么只能出现另一种颜色兔子数相同。
刷题记录:
1. 一刷,BUG FREE
782. Transform to Chessboard
An N x N board contains only 0s and 1s. In each move, you can swap any 2 rows with each other, or any 2 columns with each other.
What is the minimum number of moves to transform the board into a "chessboard" - a board where no 0s and no 1s are 4-directionally adjacent? If the task is impossible, return -1.
Examples:
Input: board = [[0,1,1,0],[0,1,1,0],[1,0,0,1],[1,0,0,1]]
Output: 2
Explanation:
One potential sequence of moves is shown below, from left to right: 0110 1010 1010
0110 --> 1010 --> 0101
1001 0101 1010
1001 0101 0101 The first move swaps the first and second column.
The second move swaps the second and third row. Input: board = [[0, 1], [1, 0]]
Output: 0
Explanation:
Also note that the board with 0 in the top left corner,
01
10 is also a valid chessboard. Input: board = [[1, 0], [1, 0]]
Output: -1
Explanation:
No matter what sequence of moves you make, you cannot end with a valid chessboard.
Note:
boardwill have the same number of rows and columns, a number in the range[2, 30].board[i][j]will be only0s or1s.
解题思路:
1. 分别判断行和列是否具备转换的条件。每行的二进制数值要么相同,要么对应位置取反。其为1的bit数应该为全部位数的一半,或者比0的bit数多一少一。
2. 由于先进行行交换和列交换的效果相同,所以可以看作先将全部的行变换再进行列变换。
3. 在计算交换的次数时只需要比较与目标数之间bit值不同的位置除以2,因为为0的bit数和为1的bit数是一样的,一个变换过去,必有变换回来的。
刷题记录:
1. 一刷,没有思路。
783. Minimum Distance Between BST Nodes
Given a Binary Search Tree (BST) with the root node root, return the minimum difference between the values of any two different nodes in the tree.
Example :
Input: root = [4,2,6,1,3,null,null]
Output: 1
Explanation:
Note that root is a TreeNode object, not an array. The given tree [4,2,6,1,3,null,null] is represented by the following diagram: 4
/ \
2 6
/ \
1 3 while the minimum difference in this tree is 1, it occurs between node 1 and node 2, also between node 3 and node 2.
Note:
- The size of the BST will be between 2 and
100. - The BST is always valid, each node's value is an integer, and each node's value is different.
解题思路:
1. 使用一个全局变量存储之前小于当前结点的值,然后用当前结点值减去这个变量来得到最小差距。并且更新变量值。
刷题记录:
1. 一刷,BUG FREE
784. Letter Case Permutation
Given a string S, we can transform every letter individually to be lowercase or uppercase to create another string. Return a list of all possible strings we could create.
Examples:
Input: S = "a1b2"
Output: ["a1b2", "a1B2", "A1b2", "A1B2"] Input: S = "3z4"
Output: ["3z4", "3Z4"] Input: S = "12345"
Output: ["12345"]
Note:
Swill be a string with length at most12.Swill consist only of letters or digits.
解题思路:
1. 可以维护一个字符串前缀的数组,在遍历的过程中如果出现了字母,那么就将前缀复制,一半加上小写,一半加上大写。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
vector<string> letterCasePermutation(string S) {
if (S.empty()) {
return vector<string>(, S);
}
vector<string> res;
permutateHelper(res, S, );
return res;
}
void permutateHelper(vector<string>& res, string& S, int begin) {
for (int i = begin; i < S.size(); i++) {
if (!islower(S[i]) && !isupper(S[i])) {
continue;
}
S[i] = tolower(S[i]);
permutateHelper(res, S, i + );
S[i] = toupper(S[i]);
permutateHelper(res, S, i + );
return;
}
res.push_back(S);
return;
}
};
785. Is Graph Bipartite?
Given a graph, return true if and only if it is bipartite.
Recall that a graph is bipartite if we can split it's set of nodes into two independent subsets A and B such that every edge in the graph has one node in A and another node in B.
The graph is given in the following form: graph[i] is a list of indexes j for which the edge between nodes i and j exists. Each node is an integer between 0 and graph.length - 1. There are no self edges or parallel edges: graph[i] does not contain i, and it doesn't contain any element twice.
Example 1:
Input: [[1,3], [0,2], [1,3], [0,2]]
Output: true
Explanation:
The graph looks like this:
0----1
| |
| |
3----2
We can divide the vertices into two groups: {0, 2} and {1, 3}.
Example 2:
Input: [[1,2,3], [0,2], [0,1,3], [0,2]]
Output: false
Explanation:
The graph looks like this:
0----1
| \ |
| \ |
3----2
We cannot find a way to divide the set of nodes into two independent ubsets.
Note:
graphwill have length in range[1, 100].graph[i]will contain integers in range[0, graph.length - 1].graph[i]will not containior duplicate values.
解题思路:
1. 使用宽度优先遍历或者深度优先遍历对节点标注颜色,如果出现冲突则返回。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
bool isBipartite(vector<vector<int>>& graph) {
int len = graph.size();
vector<int> mark(len, -);
for (int i = ; i < len; i++) {
if (mark[i] != -) {
continue;
}
mark[i] = ;
queue<int> nodes;
nodes.push(i);
while (!nodes.empty()) {
int index = nodes.front();
nodes.pop();
for (int j = ; j < graph[index].size(); j++) {
if (mark[graph[index][j]] != -) {
if (mark[graph[index][j]] == mark[index]) {
return false;
}
} else {
mark[graph[index][j]] = mark[index] == ? : ;
nodes.push(graph[index][j]);
}
}
}
}
return true;
}
};
786. K-th Smallest Prime Fraction
A sorted list A contains 1, plus some number of primes. Then, for every p < q in the list, we consider the fraction p/q.
What is the K-th smallest fraction considered? Return your answer as an array of ints, where answer[0] = p and answer[1] = q.
Examples:
Input: A = [1, 2, 3, 5], K = 3
Output: [2, 5]
Explanation:
The fractions to be considered in sorted order are:
1/5, 1/3, 2/5, 1/2, 3/5, 2/3.
The third fraction is 2/5. Input: A = [1, 7], K = 1
Output: [1, 7]
Note:
Awill have length between2and2000.- Each
A[i]will be between1and30000. Kwill be between1andA.length * (A.length + 1) / 2.
解题思路:
1. 使用优先级队列来存储组成较小分数的方式。
刷题记录:
1. 一刷,BUG FREE
struct cmp {
bool operator() (pair<int, pair<int, int>> a, pair<int, pair<int, int>> b) {
return a.second.first * b.second.second >= a.second.second * b.second.first;
}
};
class Solution {
public:
vector<int> kthSmallestPrimeFraction(vector<int>& A, int K) {
int len = A.size();
vector<int> index(len, len - );
priority_queue<pair<int, pair<int, int>>, vector<pair<int, pair<int, int>>>, cmp> fractions;
fractions.push(pair<int, pair<int, int>>(, pair<int, int>(A[], A[index[]])));
for (int i = ; i < K - && !fractions.empty(); i++) {
pair<int, pair<int, int>> frac(fractions.top());
fractions.pop();
if (index[frac.first] == len - && frac.first + < len && A[frac.first + ] < A[len - ]) {
fractions.push(pair<int, pair<int, int>>(frac.first + , pair<int, int>(A[frac.first + ], A[len - ])));
}
if (A[frac.first] < A[--index[frac.first]]) {
fractions.push(pair<int, pair<int, int>>(frac.first, pair<int, int>(A[frac.first], A[index[frac.first]])));
}
}
vector<int> ans;
ans.push_back(fractions.top().second.first);
ans.push_back(fractions.top().second.second);
return ans;
}
};
787. Cheapest Flights Within K Stops
There are n cities connected by m flights. Each fight starts from city u and arrives at v with a price w.
Now given all the cities and fights, together with starting city src and the destination dst, your task is to find the cheapest price from src to dst with up to k stops. If there is no such route, output -1.
Example 1:
Input:
n = 3, edges = [[0,1,100],[1,2,100],[0,2,500]]
src = 0, dst = 2, k = 1
Output: 200
Explanation:
The graph looks like this:
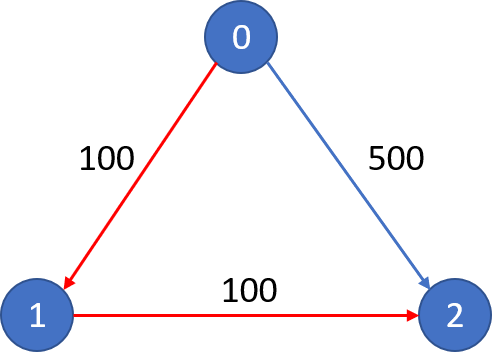
The cheapest price from city0to city2with at most 1 stop costs 200, as marked red in the picture.
Example 2:
Input:
n = 3, edges = [[0,1,100],[1,2,100],[0,2,500]]
src = 0, dst = 2, k = 0
Output: 500
Explanation:
The graph looks like this:
The cheapest price from city0to city2with at most 0 stop costs 500, as marked blue in the picture.
Note:
- The number of nodes
nwill be in range[1, 100], with nodes labeled from0ton- 1. - The size of
flightswill be in range[0, n * (n - 1) / 2]. - The format of each flight will be
(src,dst, price). - The price of each flight will be in the range
[1, 10000]. kis in the range of[0, n - 1].- There will not be any duplicated flights or self cycles.
解题思路:
1. 用宽度优先遍历来求解这个问题,最多经过k次循环。如果一个节点已经访问过且花费比当前花费要低,则直接跳过。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
int findCheapestPrice(int n, vector<vector<int>>& flights, int src, int dst, int K) {
vector<vector<pair<int, int>>> edges(n, vector<pair<int, int>>());
for (int i = ; i < flights.size(); i++) {
edges[flights[i][]].push_back(pair<int, int>(flights[i][], flights[i][]));
}
map<int, int> arrived;
int i = ;
queue<pair<int, int>> cities;
cities.push(pair<int, int>(src, ));
arrived[src] = ;
while (!cities.empty() && i <= K) {
int len = cities.size();
for (int i = ; i < len; i++) {
pair<int, int> city(cities.front());
cities.pop();
for (int j = ; j < edges[city.first].size(); j++) {
pair<int, int> next = edges[city.first][j];
if (arrived.count(next.first) && arrived[next.first] <= arrived[city.first] + next.second) {
continue;
}
int price = arrived[city.first] + next.second;
arrived[next.first] = price;
if (next.first != dst) {
cities.push(pair<int, int>(next.first, price));
}
}
}
i++;
}
return arrived.count(dst) ? arrived[dst] : -;
}
};
788. Rotated Digits
X is a good number if after rotating each digit individually by 180 degrees, we get a valid number that is different from X. A number is valid if each digit remains a digit after rotation. 0, 1, and 8 rotate to themselves; 2 and 5 rotate to each other; 6 and 9 rotate to each other, and the rest of the numbers do not rotate to any other number.
Now given a positive number N, how many numbers X from 1 to N are good?
Example:
Input: 10
Output: 4
Explanation:
There are four good numbers in the range [1, 10] : 2, 5, 6, 9.
Note that 1 and 10 are not good numbers, since they remain unchanged after rotating.
Note:
- N will be in range
[1, 10000].
解题思路:
1. 不要把问题想的很复杂,如果这个题要直接求统计数,那么需要根据最高位的数执行不同的递归函数。
2. 所以直接遍历范围内的每个数,判断其是否有效进行统计即可。
刷题记录:
1. 一刷,把问题复杂化,没做出来
class Solution {
public:
int rotatedDigits(int N) {
int count = ;
for (int num = ; num <= N; num++) {
if (isValid(num)) {
count++;
}
}
return count;
}
bool isValid(int num) {
bool valid = false;
while (num > ) {
int digit = num % ;
if (digit == || digit == || digit == ) {
return false;
}
if (digit == || digit == || digit == || digit == ) {
valid = true;
}
num /= ;
}
return valid;
}
};
789. Escape The Ghosts
You are playing a simplified Pacman game. You start at the point (0, 0), and your destination is (target[0], target[1]). There are several ghosts on the map, the i-th ghost starts at (ghosts[i][0], ghosts[i][1]).
Each turn, you and all ghosts simultaneously *may* move in one of 4 cardinal directions: north, east, west, or south, going from the previous point to a new point 1 unit of distance away.
You escape if and only if you can reach the target before any ghost reaches you (for any given moves the ghosts may take.) If you reach any square (including the target) at the same time as a ghost, it doesn't count as an escape.
Return True if and only if it is possible to escape.
Example 1:
Input:
ghosts = [[1, 0], [0, 3]]
target = [0, 1]
Output: true
Explanation:
You can directly reach the destination (0, 1) at time 1, while the ghosts located at (1, 0) or (0, 3) have no way to catch up with you.
Example 2:
Input:
ghosts = [[1, 0]]
target = [2, 0]
Output: false
Explanation:
You need to reach the destination (2, 0), but the ghost at (1, 0) lies between you and the destination.
Example 3:
Input:
ghosts = [[2, 0]]
target = [1, 0]
Output: false
Explanation:
The ghost can reach the target at the same time as you.
Note:
- All points have coordinates with absolute value <=
10000. - The number of ghosts will not exceed
100.
解题思路:
1. 比较与目标点的距离和离目标点最近的ghost的距离即可。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
bool escapeGhosts(vector<vector<int>>& ghosts, vector<int>& target) {
int minSteps = INT_MAX;
for (int i = ; i < ghosts.size(); i++) {
minSteps = min(minSteps, abs(ghosts[i][] - target[]) + abs(ghosts[i][] - target[]));
}
return abs(target[]) + abs(target[]) < minSteps;
}
};
790. Domino and Tromino Tiling
We have two types of tiles: a 2x1 domino shape, and an "L" tromino shape. These shapes may be rotated.
XX <- domino XX <- "L" tromino
X
Given N, how many ways are there to tile a 2 x N board? Return your answer modulo 10^9 + 7.
(In a tiling, every square must be covered by a tile. Two tilings are different if and only if there are two 4-directionally adjacent cells on the board such that exactly one of the tilings has both squares occupied by a tile.)
Example:
Input: 3
Output: 5
Explanation:
The five different ways are listed below, different letters indicates different tiles:
XYZ XXZ XYY XXY XYY
XYZ YYZ XZZ XYY XXY
Note:
- N will be in range
[1, 1000].
解题思路:
1. 使用动态规划,将较长长度瓷砖的拼接问题转化为已求得的较短瓷砖问题。研究如何构成一个方块的不同。可能为以下几种情况:
X XX XXY XXYY XXZZY
X YY XYY XZZY XZZYY
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
int numTilings(int N) {
int base = 1e9 + ;
long long count = ;
vector<int> dp( + N, );
dp[] = ;
for (int i = ; i <= N; i++) {
long long temp = dp[i - ];
if (i - >= ) {
temp += dp[i - ];
}
if (i - >= ) {
count = (count + dp[i - ]) % base;
}
dp[i] = (temp + * count) % base;
}
return dp[N];
}
};
791. Custom Sort String
S and T are strings composed of lowercase letters. In S, no letter occurs more than once.
S was sorted in some custom order previously. We want to permute the characters of T so that they match the order that S was sorted. More specifically, if x occurs before y in S, then x should occur before y in the returned string.
Return any permutation of T (as a string) that satisfies this property.
Example :
Input:
S = "cba"
T = "abcd"
Output: "cbad"
Explanation:
"a", "b", "c" appear in S, so the order of "a", "b", "c" should be "c", "b", and "a".
Since "d" does not appear in S, it can be at any position in T. "dcba", "cdba", "cbda" are also valid outputs.
Note:
Shas length at most26, and no character is repeated inS.Thas length at most200.SandTconsist of lowercase letters only.
解题思路:
1. 统计目标字符串中各字符的个数,然后依次进行排列。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
string customSortString(string S, string T) {
vector<int> letters(, );
for (auto letter : T) {
letters[letter - 'a']++;
}
string res;
for (auto letter : S) {
res.append(string(letters[letter - 'a'], letter));
letters[letter - 'a'] = -;
}
for (int i = ; i < ; i++) {
if (letters[i] != -) {
res.append(string(letters[i], 'a' + i));
}
}
return res;
}
};
792. Number of Matching Subsequences
Given string S and a dictionary of words words, find the number of words[i] that is a subsequence of S.
Example :
Input:
S = "abcde"
words = ["a", "bb", "acd", "ace"]
Output: 3
Explanation: There are three words inwordsthat are a subsequence ofS: "a", "acd", "ace".
Note:
- All words in
wordsandSwill only consists of lowercase letters. - The length of
Swill be in the range of[1, 50000]. - The length of
wordswill be in the range of[1, 5000]. - The length of
words[i]will be in the range of[1, 50].
解题思路:
1. 注意观察参数的规模和大小,这里明显S的长度偏大。所以需要存储S内部的信息来降低时间复杂度。我们想到用键值表存储S中每个字符出现的位置,并且这些下标自然由小到大排列,方便直接使用二分查找。
存储:O(length(S)) 时间:O(n*Length(word)*log(letter))
刷题记录:
1. 一刷,使用Trie Tree,仅能解决字典过大且出现重复前缀词的情况,不符合这题的需求。
class Solution {
public:
int numMatchingSubseq(string S, vector<string>& words) {
map<char, vector<int>> index;
for (int i = ; i < S.size(); i++) {
index[S[i]].push_back(i);
}
int count = ;
for (auto word : words) {
int i = , begin = ;
for (; i < word.size(); i++) {
int next = searchHelper(index, word[i], begin);
if (next == -) {
break;
}
begin = next + ;
}
if (i >= (int)word.size()) {
count++;
}
}
return count;
}
int searchHelper(map<char, vector<int>>& index, char letter, int begin) {
#define nums index[letter]
if (nums.empty()) {
return -;
}
int low = , high = (int)nums.size() - ;
while (low < high) {
int mid = low + (high - low) / ;
if (nums[mid] == begin) {
return begin;
} else if (nums[mid] < begin) {
low = mid + ;
} else {
high = mid;
}
}
return nums[high] >= begin ? nums[high] : -;
}
};
793. Preimage Size of Factorial Zeroes Function
Let f(x) be the number of zeroes at the end of x!. (Recall that x! = 1 * 2 * 3 * ... * x, and by convention, 0! = 1.)
For example, f(3) = 0 because 3! = 6 has no zeroes at the end, while f(11) = 2 because 11! = 39916800 has 2 zeroes at the end. Given K, find how many non-negative integers x have the property that f(x) = K.
Example 1:
Input: K = 0
Output: 5
Explanation: 0!, 1!, 2!, 3!, and 4! end with K = 0 zeroes. Example 2:
Input: K = 5
Output: 0
Explanation: There is no x such that x! ends in K = 5 zeroes.
Note:
Kwill be an integer in the range[0, 10^9].
解题思路:
1. 求以不同零结尾的阶乘个数,这题打了一个烟雾弹,因为以不同零结尾的数是不断变化的,每增加5就增加1。每增加25就再增加1,依次类推。由于这个增加导致部分数值会不出现,所以结果要么为0,要么为5.
空间:O(log5(K)) 时间:O(log5(K)).
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
int preimageSizeFZF(int K) {
K++;
int base = ;
vector<int> factors;
while (K >= base) {
factors.push_back(base);
base = * base + ;
}
int len = factors.size();
for (int i = len - ; i > ; i--) {
if ((K % factors[i]) == ) {
return ;
}
K %= factors[i];
}
return ;
}
};
794. Valid Tic-Tac-Toe State
A Tic-Tac-Toe board is given as a string array board. Return True if and only if it is possible to reach this board position during the course of a valid tic-tac-toe game.
The board is a 3 x 3 array, and consists of characters " ", "X", and "O". The " " character represents an empty square.
Here are the rules of Tic-Tac-Toe:
- Players take turns placing characters into empty squares (" ").
- The first player always places "X" characters, while the second player always places "O" characters.
- "X" and "O" characters are always placed into empty squares, never filled ones.
- The game ends when there are 3 of the same (non-empty) character filling any row, column, or diagonal.
- The game also ends if all squares are non-empty.
- No more moves can be played if the game is over.
Example 1:
Input: board = ["O ", " ", " "]
Output: false
Explanation: The first player always plays "X". Example 2:
Input: board = ["XOX", " X ", " "]
Output: false
Explanation: Players take turns making moves. Example 3:
Input: board = ["XXX", " ", "OOO"]
Output: false Example 4:
Input: board = ["XOX", "O O", "XOX"]
Output: true
Note:
boardis a length-3 array of strings, where each stringboard[i]has length 3.- Each
board[i][j]is a character in the set{" ", "X", "O"}.
解题思路:
1. 一定要注意审题,这个题目的意思是说有没有可能达到题中给定的状态。是一个判断棋局有效性的问题,不是让你去下。
2. X的数量一定要么和O相同,要么大1。然后统计X连线和O连线的次数。连线次数和一定小于1,因为一旦有人连线就结束。然后分别结合落子数判断。
空间:O(1) 时间:O(1)
刷题记录:
1. 一刷,没读懂题意。
class Solution {
public:
bool validTicTacToe(vector<string>& board) {
int X = , O = ;
for (int i = ; i < ; i++) {
for (int j = ; j < ; j++) {
if (board[i][j] == 'X') {
X++;
} else if (board[i][j] == 'O') {
O++;
}
}
}
if (X < O || X > O + ) {
return false;
}
int winX = countWin(board, 'X'), winO = countWin(board, 'O');
if (winX + winO > ) {
return false;
}
if (winX == ) {
return X == O + ;
} else if (winO == ) {
return X == O;
} else {
return true;
}
}
int countWin(vector<string>& board, char type) {
int count = ;
for (int i = ; i < ; i++) {
if (board[i][] == type && board[i][] == type && board[i][] == type) {
count++;
}
}
for (int j = ; j < ; j++) {
if (board[][j] == type && board[][j] == type && board[][j] == type) {
count++;
}
}
if (board[][] == type && board[][] == type && board[][] == type) {
count++;
}
if (board[][] == type && board[][] == type && board[][] == type) {
count++;
}
return count;
}
};
795. Number of Subarrays with Bounded Maximum
We are given an array A of positive integers, and two positive integers L and R (L <= R).
Return the number of (contiguous, non-empty) subarrays such that the value of the maximum array element in that subarray is at least Land at most R.
Example :
Input:
A = [2, 1, 4, 3]
L = 2
R = 3
Output: 3
Explanation: There are three subarrays that meet the requirements: [2], [2, 1], [3].
Note:
- L, R and
A[i]will be an integer in the range[0, 10^9]. - The length of
Awill be in the range of[1, 50000].
解题思路:
1. 根据数组中出现满足范围的数的最后的下标,和前一个不满足条件的隔断元素的下标。统计不同的元素作为范围的右边时的可能情况。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
int numSubarrayBoundedMax(vector<int>& A, int L, int R) {
int begin = , last = -;
int count = ;
for (int i = ; i < A.size(); i++) {
if (A[i] <= R) {
if (A[i] >= L) {
last = i;
}
if (last != -) {
count += last - begin + ;
}
} else {
begin = i + ;
last = -;
}
}
return count;
}
};
796. Rotate String
We are given two strings, A and B.
A shift on A consists of taking string A and moving the leftmost character to the rightmost position. For example, if A = 'abcde', then it will be 'bcdea' after one shift on A. Return True if and only if A can become B after some number of shifts on A.
Example 1:
Input: A = 'abcde', B = 'cdeab'
Output: true Example 2:
Input: A = 'abcde', B = 'abced'
Output: false
Note:
AandBwill have length at most100.
解题思路:
1. 依次判断移动不同的位数时,拼接起来的字符串是否完全相同。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
bool rotateString(string A, string B) {
if (A.size() != B.size()) {
return false;
}
if (A.empty() && B.empty()) {
return true;
}
int len = A.size();
for (int i = ; i < len; i++) {
if (A.substr(, i) == B.substr(len - i) && A.substr(i) == B.substr(, len - i)) {
return true;
}
}
return false;
}
};
797. All Paths From Source to Target
Given a directed, acyclic graph of N nodes. Find all possible paths from node 0 to node N-1, and return them in any order.
The graph is given as follows: the nodes are 0, 1, ..., graph.length - 1. graph[i] is a list of all nodes j for which the edge (i, j) exists.
Example:
Input: [[1,2], [3], [3], []]
Output: [[0,1,3],[0,2,3]]
Explanation: The graph looks like this:
0--->1
| |
v v
2--->3
There are two paths: 0 -> 1 -> 3 and 0 -> 2 -> 3.
Note:
- The number of nodes in the graph will be in the range
[2, 15]. - You can print different paths in any order, but you should keep the order of nodes inside one path.
解题思路:
1. 此题不需要做太多存储上的优化以及记录已经得到的递归后的结果。
2. 需要根据实际情况,灵活判断优化程度。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
vector<vector<int>> allPathsSourceTarget(vector<vector<int>>& graph) {
map<int, vector<int>> paths;
findHelper(graph, paths, );
vector<vector<int>> res;
vector<int> ans(, (int)graph.size() - );
resolver(res, ans, paths, (int)graph.size() - );
for (int i = ; i < res.size(); i++) {
reverse(res[i].begin(), res[i].end());
}
return res;
}
void findHelper(vector<vector<int>>& graph, map<int, vector<int>>& paths, int start) {
if (start == (int)graph.size() - ) {
return;
}
for (int i = ; i < graph[start].size(); i++) {
if (paths.count(graph[start][i])) {
paths[graph[start][i]].push_back(start);
} else {
paths[graph[start][i]].push_back(start);
findHelper(graph, paths, graph[start][i]);
}
}
return;
}
void resolver(vector<vector<int>>& res, vector<int>& ans, map<int, vector<int>>& paths, int start) {
if (start == ) {
res.push_back(ans);
return;
}
if (!paths.count(start)) {
return;
}
for (int i = ; i < paths[start].size(); i++) {
ans.push_back(paths[start][i]);
resolver(res, ans, paths, paths[start][i]);
ans.pop_back();
}
return;
}
};
798. Smallest Rotation with Highest Score
Given an array A, we may rotate it by a non-negative integer K so that the array becomes A[K], A[K+1], A{K+2], ... A[A.length - 1], A[0], A[1], ..., A[K-1]. Afterward, any entries that are less than or equal to their index are worth 1 point.
For example, if we have [2, 4, 1, 3, 0], and we rotate by K = 2, it becomes [1, 3, 0, 2, 4]. This is worth 3 points because 1 > 0 [no points], 3 > 1 [no points], 0 <= 2 [one point], 2 <= 3 [one point], 4 <= 4 [one point].
Over all possible rotations, return the rotation index K that corresponds to the highest score we could receive. If there are multiple answers, return the smallest such index K.
Example 1:
Input: [2, 3, 1, 4, 0]
Output: 3
Explanation:
Scores for each K are listed below:
K = 0, A = [2,3,1,4,0], score 2
K = 1, A = [3,1,4,0,2], score 3
K = 2, A = [1,4,0,2,3], score 3
K = 3, A = [4,0,2,3,1], score 4
K = 4, A = [0,2,3,1,4], score 3
So we should choose K = 3, which has the highest score.
Example 2:
Input: [1, 3, 0, 2, 4]
Output: 0
Explanation: A will always have 3 points no matter how it shifts.
So we will choose the smallest K, which is 0.
Note:
Awill have length at most20000.A[i]will be in the range[0, A.length].
解题思路:
1. 此题需要细致的去思考,在每一次移动一位的过程中发生了什么。当移动发生时,第一位的数移到最后一定会导致得分+1,然后需要提取统计在移动特定位数时,失去的分值。
解题思路:
1. 一刷,没有思路。
class Solution {
public:
int bestRotation(vector<int>& A) {
if (A.empty()) {
return ;
}
int len = A.size();
vector<int> lossPoints(len, );
for (int i = ; i < len; i++) {
lossPoints[(i - A[i] + + len) % len]++;
}
int maxPoints = , K = ;
int points = ;
for (int i = ; i < len; i++) {
points += - lossPoints[i];
if (points > maxPoints) {
maxPoints = points;
K = i;
}
}
return K;
}
};
799. Champagne Tower
We stack glasses in a pyramid, where the first row has 1 glass, the second row has 2 glasses, and so on until the 100th row. Each glass holds one cup (250ml) of champagne.
Then, some champagne is poured in the first glass at the top. When the top most glass is full, any excess liquid poured will fall equally to the glass immediately to the left and right of it. When those glasses become full, any excess champagne will fall equally to the left and right of those glasses, and so on. (A glass at the bottom row has it's excess champagne fall on the floor.)
For example, after one cup of champagne is poured, the top most glass is full. After two cups of champagne are poured, the two glasses on the second row are half full. After three cups of champagne are poured, those two cups become full - there are 3 full glasses total now. After four cups of champagne are poured, the third row has the middle glass half full, and the two outside glasses are a quarter full, as pictured below.
Now after pouring some non-negative integer cups of champagne, return how full the j-th glass in the i-th row is (both i and j are 0 indexed.)
Example 1:
Input: poured = 1, query_glass = 1, query_row = 1
Output: 0.0
Explanation: We poured 1 cup of champange to the top glass of the tower (which is indexed as (0, 0)). There will be no excess liquid so all the glasses under the top glass will remain empty. Example 2:
Input: poured = 2, query_glass = 1, query_row = 1
Output: 0.5
Explanation: We poured 2 cups of champange to the top glass of the tower (which is indexed as (0, 0)). There is one cup of excess liquid. The glass indexed as (1, 0) and the glass indexed as (1, 1) will share the excess liquid equally, and each will get half cup of champange.
Note:
pouredwill be in the range of[0, 10 ^ 9].query_glassandquery_rowwill be in the range of[0, 99].
解题思路:
1. 此题使用动态规划的方法,用液体的体积去计量,不要用流速!!
刷题记录:
1. 一刷,思路错误。
class Solution {
public:
double champagneTower(int poured, int query_row, int query_glass) {
vector<vector<double>> dp(query_row + , vector<double>(query_glass + , ));
dp[][] = poured;
for (int i = ; i <= query_row; i++) {
for (int j = ; j <= min(query_glass, i); j++) {
if (j == ) {
dp[i][j] = dp[i - ][j] > ? (dp[i - ][j] - ) / : ;
} else if (j == i) {
dp[i][j] = dp[i - ][j - ] > ? (dp[i - ][j - ] - ) / : ;
} else {
dp[i][j] = dp[i - ][j] > ? (dp[i - ][j] - ) / : ;
dp[i][j] += dp[i - ][j - ] > ? (dp[i - ][j - ] - ) / : ;
}
}
}
return min(dp[query_row][query_glass], 1.0d);
}
};
801. Minimum Swaps To Make Sequences Increasing
We have two integer sequences A and B of the same non-zero length.
We are allowed to swap elements A[i] and B[i]. Note that both elements are in the same index position in their respective sequences.
At the end of some number of swaps, A and B are both strictly increasing. (A sequence is strictly increasing if and only if A[0] < A[1] < A[2] < ... < A[A.length - 1].)
Given A and B, return the minimum number of swaps to make both sequences strictly increasing. It is guaranteed that the given input always makes it possible.
Example:
Input: A = [1,3,5,4], B = [1,2,3,7]
Output: 1
Explanation:
Swap A[3] and B[3]. Then the sequences are:
A = [1, 3, 5, 7] and B = [1, 2, 3, 4]
which are both strictly increasing.
Note:
A, Bare arrays with the same length, and that length will be in the range[1, 1000].A[i], B[i]are integer values in the range[0, 2000].
解题思路:
1. 顺序遍历数组,根据A、B向量当前位置与前一位置上的数的大小关系来决定可能的组合关系,一种是与自身前一元素组合,一种是对方前一元素交叉组合。然后结合前一个位置上的数是否交换组合成四种情况。动态规划计算出当前位置上的数是否交换得到的最小交换次数。
刷题记录:
1. 一刷,没有思路。
class Solution {
public:
int minSwap(vector<int>& A, vector<int>& B) {
int len = (int)A.size();
int n1 = , s1 = ;
for (int i = ; i < len; i++) {
int n2 = INT_MAX, s2 = INT_MAX;
if (A[i] > A[i - ] && B[i] > B[i - ]) {
n2 = min(n2, n1);
s2 = min(s2, s1 + );
}
if (A[i] > B[i - ] && B[i] > A[i - ]) {
n2 = min(n2, s1);
s2 = min(s2, n1 + );
}
n1 = n2;
s1 = s2;
}
return min(n1, s1);
}
};
802. Find Eventual Safe States
In a directed graph, we start at some node and every turn, walk along a directed edge of the graph. If we reach a node that is terminal (that is, it has no outgoing directed edges), we stop.
Now, say our starting node is eventually safe if and only if we must eventually walk to a terminal node. More specifically, there exists a natural number K so that for any choice of where to walk, we must have stopped at a terminal node in less than K steps.
Which nodes are eventually safe? Return them as an array in sorted order.
The directed graph has N nodes with labels 0, 1, ..., N-1, where N is the length of graph. The graph is given in the following form: graph[i] is a list of labels j such that (i, j) is a directed edge of the graph.
Example:
Input: graph = [[1,2],[2,3],[5],[0],[5],[],[]]
Output: [2,4,5,6]
Here is a diagram of the above graph.
Note:
graphwill have length at most10000.- The number of edges in the graph will not exceed
32000. - Each
graph[i]will be a sorted list of different integers, chosen within the range[0, graph.length - 1].
解题思路:
1. 使用深度优先遍历,对每一个结点判断其是否位安全结点,同时在递归判断它的所有下游结点时,使用字典存储得到的结论,避免重复递归。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
vector<int> eventualSafeNodes(vector<vector<int>>& graph) {
int len = (int)graph.size();
map<int, bool> safeNodes;
vector<int> res;
for (int i = ; i < len; i++) {
set<int> visited;
if (isSafeNode(graph, safeNodes, visited, i)) {
res.push_back(i);
}
}
return res;
}
bool isSafeNode(vector<vector<int>>& graph, map<int, bool>& safeNodes, set<int>& hasVisited, int start) {
if (safeNodes.count(start)) {
return safeNodes[start];
}
if (hasVisited.count(start)) {
safeNodes[start] = false;
return safeNodes[start];
}
hasVisited.insert(start);
for (int i = ; i < graph[start].size(); i++) {
if (!isSafeNode(graph, safeNodes, hasVisited, graph[start][i])) {
safeNodes[start] = false;
hasVisited.erase(start);
return safeNodes[start];
}
}
safeNodes[start] = true;
hasVisited.erase(start);
return safeNodes[start];
}
};
803. Bricks Falling When Hit
We have a grid of 1s and 0s; the 1s in a cell represent bricks. A brick will not drop if and only if it is directly connected to the top of the grid, or at least one of its (4-way) adjacent bricks will not drop.
We will do some erasures sequentially. Each time we want to do the erasure at the location (i, j), the brick (if it exists) on that location will disappear, and then some other bricks may drop because of that erasure.
Return an array representing the number of bricks that will drop after each erasure in sequence.
Example 1:
Input:
grid = [[1,0,0,0],[1,1,1,0]]
hits = [[1,0]]
Output: [2]
Explanation:
If we erase the brick at (1, 0), the brick at (1, 1) and (1, 2) will drop. So we should return 2.
Example 2:
Input:
grid = [[1,0,0,0],[1,1,0,0]]
hits = [[1,1],[1,0]]
Output: [0,0]
Explanation:
When we erase the brick at (1, 0), the brick at (1, 1) has already disappeared due to the last move. So each erasure will cause no bricks dropping. Note that the erased brick (1, 0) will not be counted as a dropped brick.
Note:
- The number of rows and columns in the grid will be in the range [1, 200].
- The number of erasures will not exceed the area of the grid.
- It is guaranteed that each erasure will be different from any other erasure, and located inside the grid.
- An erasure may refer to a location with no brick - if it does, no bricks drop.
解题思路:
1. 不要一开始就尝试考虑很复杂的方法,就用简单的递归判断周围的每个砖块是否会脱落,然后决定是否进行递归考虑。一定要注意在进行递归的时候,将已经遍历过的砖块的数值暂时改写为一个其他的数值,以避免反复递归。
刷题记录:
1. 一刷,使用的方法过于复杂。
class Solution {
public:
int dirs[][] = {{-, }, {, }, {, }, {, -}};
vector<int> hitBricks(vector<vector<int>>& grid, vector<vector<int>>& hits) {
vector<int> res;
for (int i = ; i < hits.size(); i++) {
int r = hits[i][], c = hits[i][];
int count = ;
if (grid[r][c] == ) {
count = solver(grid, r, c);
}
res.push_back(count);
}
return res;
}
int solver(vector<vector<int>>& grid, int r, int c) {
int m = (int)grid.size(), n = (int)grid[].size();
int count = ;
grid[r][c] = ;
for (int k = ; k < ; k++) {
int next_r = r + dirs[k][], next_c = c + dirs[k][];
if (next_r < || next_r >= m || next_c < || next_c >= n || grid[next_r][next_c] == ) {
continue;
}
if (isFall(grid, next_r, next_c)) {
count += + solver(grid, next_r, next_c);
}
}
return count;
}
bool isFall(vector<vector<int>>& grid, int r, int c) {
if (r == ) {
return false;
}
int m = (int)grid.size(), n = (int)grid[].size();
grid[r][c] = ;
for (int k = ; k < ; k++) {
int next_r = r + dirs[k][], next_c = c + dirs[k][];
if (next_r < || next_r >= m || next_c < || next_c >= n || grid[next_r][next_c] != ) {
continue;
}
if (!isFall(grid, next_r, next_c)) {
grid[r][c] = ;
return false;
}
}
grid[r][c] = ;
return true;
}
};
804. Unique Morse Code Words
International Morse Code defines a standard encoding where each letter is mapped to a series of dots and dashes, as follows: "a" maps to ".-", "b" maps to "-...", "c" maps to "-.-.", and so on.
For convenience, the full table for the 26 letters of the English alphabet is given below:
[".-","-...","-.-.","-..",".","..-.","--.","....","..",".---","-.-",".-..","--","-.","---",".--.","--.-",".-.","...","-","..-","...-",".--","-..-","-.--","--.."]
Now, given a list of words, each word can be written as a concatenation of the Morse code of each letter. For example, "cab" can be written as "-.-.-....-", (which is the concatenation "-.-." + "-..." + ".-"). We'll call such a concatenation, the transformation of a word.
Return the number of different transformations among all words we have.
Example:
Input: words = ["gin", "zen", "gig", "msg"]
Output: 2
Explanation:
The transformation of each word is:
"gin" -> "--...-."
"zen" -> "--...-."
"gig" -> "--...--."
"msg" -> "--...--." There are 2 different transformations, "--...-." and "--...--.".
Note:
- The length of
wordswill be at most100. - Each
words[i]will have length in range[1, 12]. words[i]will only consist of lowercase letters.
解题思路:
1. 按照题目指定的规则将所有的单词转化为Morse Code,插入到字符串的集合中,最后统计有多少个不同的字符串。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
int uniqueMorseRepresentations(vector<string>& words) {
string morseCodes[] = {".-","-...","-.-.","-..",".","..-.","--.","....","..",".---","-.-",".-..","--","-.","---",".--.","--.-",".-.","...","-","..-","...-",".--","-..-","-.--","--.."};
set<string> unique;
for (auto word : words) {
string repre = "";
for (auto letter : word) {
repre.append(morseCodes[letter - 'a']);
}
unique.insert(repre);
}
return (int)unique.size();
}
};
805. Split Array With Same Average
In a given integer array A, we must move every element of A to either list B or list C. (B and C initially start empty.)
Return true if and only if after such a move, it is possible that the average value of B is equal to the average value of C, and B and C are both non-empty.
Example :
Input:
[1,2,3,4,5,6,7,8]
Output: true
Explanation: We can split the array into [1,4,5,8] and [2,3,6,7], and both of them have the average of 4.5.
Note:
- The length of
Awill be in the range [1, 30]. A[i]will be in the range of[0, 10000].
解题思路:
1. 递归寻找不同长度情况下的组合,能否有可能实现其平均数等于全局的平均数。在对不同长度进行递归前可以采用优化策略判断当前长度的整数是否有可能形成指定的平均值。
2. 其实也就是对不同长度的递归问题,不要看Accepted的人数少就害怕时间复杂度过高而不敢尝试了。
刷题记录:
1. 一刷,思路不正确。
class Solution {
public:
bool splitArraySameAverage(vector<int>& A) {
int len = (int)A.size();
int sum = ;
for (auto num : A) {
sum += num;
}
sort(A.begin(), A.end());
for (int i = ; i <= len / ; i++) {
if (sum * i % len != ) {
continue;
}
if (helper(A, sum * i / len, i, , , )) {
return true;
}
}
return false;
}
bool helper(vector<int>& A, int target, int num, int sum, int start, int curNum) {
if (sum == target && curNum == num) {
return true;
}
if (curNum >= num) {
return false;
}
for (int i = start; i < A.size(); i++) {
if (i != start && A[i] == A[i - ]) {
continue;
}
if (sum + A[i] > target) {
break;
}
if (helper(A, target, num, sum + A[i], i + , curNum + )) {
return true;
}
}
return false;
}
};
806. Number of Lines To Write String
We are to write the letters of a given string S, from left to right into lines. Each line has maximum width 100 units, and if writing a letter would cause the width of the line to exceed 100 units, it is written on the next line. We are given an array widths, an array where widths[0] is the width of 'a', widths[1] is the width of 'b', ..., and widths[25] is the width of 'z'.
Now answer two questions: how many lines have at least one character from S, and what is the width used by the last such line? Return your answer as an integer list of length 2.
Example :
Input:
widths = [10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10]
S = "abcdefghijklmnopqrstuvwxyz"
Output: [3, 60]
Explanation:
All letters have the same length of 10. To write all 26 letters,
we need two full lines and one line with 60 units.
Example :
Input:
widths = [4,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10]
S = "bbbcccdddaaa"
Output: [2, 4]
Explanation:
All letters except 'a' have the same length of 10, and
"bbbcccdddaa" will cover 9 * 10 + 2 * 4 = 98 units.
For the last 'a', it is written on the second line because
there is only 2 units left in the first line.
So the answer is 2 lines, plus 4 units in the second line.
Note:
- The length of
Swill be in the range [1, 1000]. Swill only contain lowercase letters.widthsis an array of length26.widths[i]will be in the range of[2, 10].
解题思路:
1. 遍历字符串,根据其占位数量进行递增。如果超过每行的限制就从新的一行开始。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
vector<int> numberOfLines(vector<int>& widths, string S) {
vector<int> res(, );
int width = ;
for (int i = ; i < S.size(); i++) {
if (width + widths[S[i] - 'a'] > ) {
res[]++;
width = widths[S[i] - 'a'];
} else {
width += widths[S[i] - 'a'];
}
}
res[] = width;
return res;
}
};
807. Max Increase to Keep City Skyline
In a 2 dimensional array grid, each value grid[i][j] represents the height of a building located there. We are allowed to increase the height of any number of buildings, by any amount (the amounts can be different for different buildings). Height 0 is considered to be a building as well.
At the end, the "skyline" when viewed from all four directions of the grid, i.e. top, bottom, left, and right, must be the same as the skyline of the original grid. A city's skyline is the outer contour of the rectangles formed by all the buildings when viewed from a distance. See the following example.
What is the maximum total sum that the height of the buildings can be increased?
Example:
Input: grid = [[3,0,8,4],[2,4,5,7],[9,2,6,3],[0,3,1,0]]
Output: 35
Explanation:
The grid is:
[ [3, 0, 8, 4],
[2, 4, 5, 7],
[9, 2, 6, 3],
[0, 3, 1, 0] ] The skyline viewed from top or bottom is: [9, 4, 8, 7]
The skyline viewed from left or right is: [8, 7, 9, 3] The grid after increasing the height of buildings without affecting skylines is: gridNew = [ [8, 4, 8, 7],
[7, 4, 7, 7],
[9, 4, 8, 7],
[3, 3, 3, 3] ]
Notes:
1 < grid.length = grid[0].length <= 50.- All heights
grid[i][j]are in the range[0, 100]. - All buildings in
grid[i][j]occupy the entire grid cell: that is, they are a1 x 1 x grid[i][j]rectangular prism.
解题思路:
1. 每个位置所能增长的最大高度由其top/down视图和left/right视图共同决定。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
int maxIncreaseKeepingSkyline(vector<vector<int>>& grid) {
int N = (int)grid.size();
vector<int> vertical(N, ), horizontal(N, );
for (int i = ; i < N; i++) {
for (int j = ; j < N; j++) {
horizontal[i] = max(horizontal[i], grid[i][j]);
vertical[j] = max(vertical[j], grid[i][j]);
}
}
int sum = ;
for (int i = ; i < N; i++) {
for (int j = ; j < N; j++) {
sum += min(horizontal[i], vertical[j]) - grid[i][j];
}
}
return sum;
}
};
808. Soup Servings
There are two types of soup: type A and type B. Initially we have N ml of each type of soup. There are four kinds of operations:
- Serve 100 ml of soup A and 0 ml of soup B
- Serve 75 ml of soup A and 25 ml of soup B
- Serve 50 ml of soup A and 50 ml of soup B
- Serve 25 ml of soup A and 75 ml of soup B
When we serve some soup, we give it to someone and we no longer have it. Each turn, we will choose from the four operations with equal probability 0.25. If the remaining volume of soup is not enough to complete the operation, we will serve as much as we can. We stop once we no longer have some quantity of both types of soup.
Note that we do not have the operation where all 100 ml's of soup B are used first.
Return the probability that soup A will be empty first, plus half the probability that A and B become empty at the same time.
Notes:
0 <= N <= 10^9.- Answers within
10^-6of the true value will be accepted as correct.
解题思路:
1. 使用带记忆的递归函数去计算在每种情况下最后符合题目条件的概率值,并且存储下来避免后面重复递归。另外,当初始值N比较大时,会导致B比A流的慢的概率极低,在这种情况下需要直接返回1。
刷题记录:
1. 一刷,没有思路
class Solution {
public:
double soupServings(int N) {
if (N > ) {
return 1.0;
}
map<pair<int, int>, double> remain;
return helper(N, N, remain);
}
double helper(int A, int B, map<pair<int, int>, double>& remain) {
pair<int, int> cur(A, B);
if (remain.count(cur)) {
return remain[cur];
}
if (A <= && B <= ) {
return 0.5;
}
if (A <= && B > ) {
return ;
}
if (A > && B <= ) {
return ;
}
double p = 0.25 * helper(A - , B, remain) + 0.25 * helper(A - , B - , remain) + 0.25 * helper(A - , B - , remain) + 0.25 * helper(A - , B - , remain);
remain[cur] = p;
return p;
}
};
809. Expressive Words
Sometimes people repeat letters to represent extra feeling, such as "hello" -> "heeellooo", "hi" -> "hiiii". Here, we have groups, of adjacent letters that are all the same character, and adjacent characters to the group are different. A group is extended if that group is length 3 or more, so "e" and "o" would be extended in the first example, and "i" would be extended in the second example. As another example, the groups of "abbcccaaaa" would be "a", "bb", "ccc", and "aaaa"; and "ccc" and "aaaa" are the extended groups of that string.
For some given string S, a query word is stretchy if it can be made to be equal to S by extending some groups. Formally, we are allowed to repeatedly choose a group (as defined above) of characters c, and add some number of the same character c to it so that the length of the group is 3 or more. Note that we cannot extend a group of size one like "h" to a group of size two like "hh" - all extensions must leave the group extended - ie., at least 3 characters long.
Given a list of query words, return the number of words that are stretchy.
Notes:
0 <= len(S) <= 100.0 <= len(words) <= 100.0 <= len(words[i]) <= 100.Sand all words inwordsconsist only of lowercase letters
解题思路:
1. 依次将字符串与目标字符串进行比较,看看相同字符出现的顺序是否一致,如果需要扩展的情况,扩展后的字符数是否大于等于3.
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
int expressiveWords(string S, vector<string>& words) {
int count = ;
for (auto word : words) {
if (judge(S, word)) {
count++;
}
}
return count;
}
bool judge(string& S, string& word) {
int len_S = S.size(), len_word = word.size();
int i = , j = ;
while (i < len_S && j < len_word) {
int pre_i = i, pre_j = j;
while (i + < len_S && S[i] == S[i + ]) {
i++;
}
while (j + < len_word && word[j] == word[j + ]) {
j++;
}
if (S[i] != word[j] || (i - pre_i + ) < (j - pre_j + ) || (i - pre_i + ) > (j - pre_j + ) && (i - pre_i + ) < ) {
return false;
}
i++;
j++;
}
return i >= len_S && j >= len_word;
}
};
810. Chalkboard XOR Game
We are given non-negative integers nums[i] which are written on a chalkboard. Alice and Bob take turns erasing exactly one number from the chalkboard, with Alice starting first. If erasing a number causes the bitwise XOR of all the elements of the chalkboard to become 0, then that player loses. (Also, we'll say the bitwise XOR of one element is that element itself, and the bitwise XOR of no elements is 0.)
Also, if any player starts their turn with the bitwise XOR of all the elements of the chalkboard equal to 0, then that player wins.
Return True if and only if Alice wins the game, assuming both players play optimally.
Notes:
1 <= N <= 1000.0 <= nums[i] <= 2^16.
解题思路:
1. 这个题有一点trick在里面,当原向量所有数的异或为0,初始玩家直接获胜。当不为0,且向量长度为偶数时,由于为偶数,那么一定存在与异或值至少两个不同的数,选择一个数拿掉即可。剩下的当为奇数时,可能所有数相同,此时抽掉任何数均输;可能存在不同的数,抽掉后异或不为0,但是对方又变成了之前偶数的情形。
刷题记录:
1. 一刷,想不到trick的思路。
class Solution {
public:
bool xorGame(vector<int>& nums) {
int xorRes = ;
for (auto num : nums) {
xorRes ^= num;
}
return xorRes == || (int)nums.size() % == ;
}
};
811. Subdomain Visit Count
A website domain like "discuss.leetcode.com" consists of various subdomains. At the top level, we have "com", at the next level, we have "leetcode.com", and at the lowest level, "discuss.leetcode.com". When we visit a domain like "discuss.leetcode.com", we will also visit the parent domains "leetcode.com" and "com" implicitly.
Now, call a "count-paired domain" to be a count (representing the number of visits this domain received), followed by a space, followed by the address. An example of a count-paired domain might be "9001 discuss.leetcode.com".
We are given a list cpdomains of count-paired domains. We would like a list of count-paired domains, (in the same format as the input, and in any order), that explicitly counts the number of visits to each subdomain.
Notes:
- The length of
cpdomainswill not exceed100. - The length of each domain name will not exceed
100. - Each address will have either 1 or 2 "." characters.
- The input count in any count-paired domain will not exceed
10000.
解题思路:
1. 对字符串进行解析,不同层次的字符串进行统计。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
vector<string> subdomainVisits(vector<string>& cpdomains) {
map<string, int> counts;
for (auto str : cpdomains) {
int pos = str.find_first_of(' ');
int count = stoi(str.substr(, pos));
do {
pos++;
string ip = str.substr(pos);
counts[ip] += count;
pos = str.find_first_of('.', pos);
} while (pos != string::npos);
}
vector<string> res;
for (auto it : counts) {
string ans = to_string(it.second) + " " + it.first;
res.push_back(ans);
}
return res;
}
};
812. Largest Triangle Area
You have a list of points in the plane. Return the area of the largest triangle that can be formed by any 3 of the points.
Notes:
3 <= points.length <= 50.- No points will be duplicated.
-50 <= points[i][j] <= 50.- Answers within
10^-6of the true value will be accepted as correct.
解题思路:
1. 计算所有可能的情况,求的最大值。
刷题记录:
1. 一刷,BUG FREE
class Solution {
public:
double largestTriangleArea(vector<vector<int>>& points) {
double maxArea = ;
int len = points.size();
for (int i = ; i < len; i++) {
for (int j = i + ; j < len; j++) {
for (int k = j + ; k < len; k++) {
double a = length(points[i], points[j]);
double b = length(points[i], points[k]);
double c = length(points[j], points[k]);
double p = (a + b + c) / ;
double area = sqrt(p * (p - a) * (p - b) * (p - c));
if (area > maxArea) {
maxArea = area;
}
}
}
}
return maxArea;
}
double length(vector<int>& x, vector<int>& y) {
return sqrt((x[] - y[]) * (x[] - y[]) + (x[] - y[]) * (x[] - y[]));
}
};
814. Binary Tree Pruning
We are given the head node root of a binary tree, where additionally every node's value is either a 0 or a 1.
Return the same tree where every subtree (of the given tree) not containing a 1 has been removed.
(Recall that the subtree of a node X is X, plus every node that is a descendant of X.)

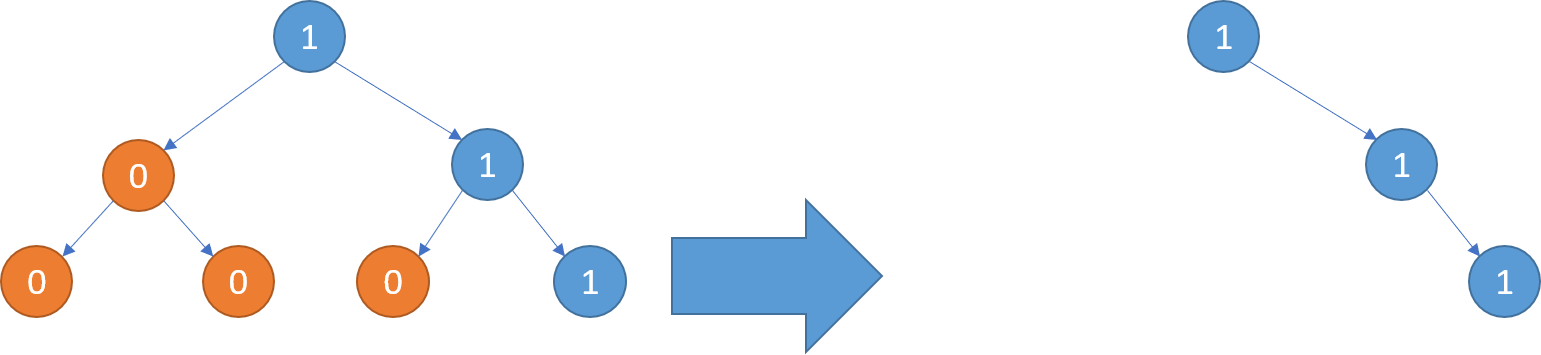
Note:
- The binary tree will have at most
100 nodes. - The value of each node will only be
0or1.
解题思路:
1. 对根结点的左右子树递归调用原函数,记得如果根结点不被擦除的话,需要根据左右递归函数的返回值改写其左右指针。
刷题记录:
1. 一刷,BUG FREE
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
TreeNode* pruneTree(TreeNode* root) {
if (root == NULL) {
return NULL;
}
TreeNode* left = pruneTree(root->left), *right = pruneTree(root->right);
if (left == NULL && right == NULL && root->val == ) {
return NULL;
}
root->left = left;
root->right = right;
return root;
}
};
leetcode 学习心得 (4)的更多相关文章
- leetcode 学习心得 (3)
源代码地址:https://github.com/hopebo/hopelee 语言:C++ 517. Super Washing Machines You have n super washing ...
- leetcode 学习心得 (1) (24~300)
源代码地址:https://github.com/hopebo/hopelee 语言:C++ 24.Swap Nodes in Pairs Given a linked list, swap ever ...
- leetcode 学习心得 (2) (301~516)
源代码地址:https://github.com/hopebo/hopelee 语言:C++ 301. Remove Invalid Parentheses Remove the minimum nu ...
- 我的MYSQL学习心得(一) 简单语法
我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(四) 数据类型 我的MYSQL学习心得(五) 运 ...
- 我的MYSQL学习心得(二) 数据类型宽度
我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(四) 数据类型 我的MYSQL学习心得(五) 运 ...
- 我的MYSQL学习心得(三) 查看字段长度
我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(四) 数据类型 我的MYSQL学习心得(五) 运 ...
- 我的MYSQL学习心得(四) 数据类型
我的MYSQL学习心得(四) 数据类型 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(五) 运 ...
- 我的MYSQL学习心得(五) 运算符
我的MYSQL学习心得(五) 运算符 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(四) 数据 ...
- 我的MYSQL学习心得(六) 函数
我的MYSQL学习心得(六) 函数 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(四) 数据类 ...
随机推荐
- Sring StringBuffer StringBuilder封装类
Sring StringBuffer StringBuilder封装类 一.String类常见方法的使用 字符串数据都是一个对象 字符串数据一旦初始化就不可以被改变 字符串对象都存储于常量池中,字符串 ...
- cookie 用户认证
客户端浏览器上的一个文件 可认为是键值对集合 基于浏览器的功能 可以实现一个用户验证的功能 因为要在页面上显示当前用户的信息 修改 写index urls 运行直接输入index时 会自动进入lo ...
- xgboost:
https://www.zybuluo.com/Dounm/note/1031900 GBDT算法详解 http://mlnote.com/2016/10/05/a-guide-to-xgboost- ...
- python 面试真题
0.Python是什么? Python是一种解释型语言.但是跟C和C的衍生语言不同,Python代码在运行之前不需要编译.其他解释型语言还包括PHP和Ruby. Python是动态类型语言,指的是在声 ...
- 手机爬虫--appium
adb 安装:下载android-sdk压缩包,解压后其中有adb.exe,配置环境变量后即可 cmd下'adb'即可启动adb客户端 adb devices –l 查看已连接的模拟器 adb co ...
- python中使用rsa加密
前提不多说, 为什么使用RSA加密请自行搜索,直接正为: 一. 生成公钥及私钥, 并保存 二. 使用公钥加密, 私钥解密 后记: 通常使用中, 会先对数据进行bas64加密, 再对加密后的内容使用rs ...
- [LeetCode] 854. K-Similar Strings 相似度为K的字符串
Strings A and B are K-similar (for some non-negative integer K) if we can swap the positions of two ...
- shell之startup
#!/bin/sh # # # # PROJECT=$ APPWORK_DIR=~/apps/$PROJECT LOGPATH=~/logs/$ LOGFILE=~/logs/$PROJECT/${P ...
- 使用 Java 执行 groovy 脚本或方法
1. 引入依赖 <dependency> <groupId>org.codehaus.groovy</groupId> <artifactId>groo ...
- oracle--介质恢复和实例恢复的基本概念
1.概念 REDO LOG是Oracle为确保已经提交的事务不会丢失而建立的一个机制.实际上REDO LOG的存在是为两种场景准备的,一种我们称之为实例恢复(INSTANCE RECOVERY),一种 ...