Flink FileSink 自定义输出路径——StreamingFileSink、BucketingSink 和 StreamingFileSink简单比较
接上篇:Flink FileSink 自定义输出路径——BucketingSink
上篇使用BucketingSink 实现了自定义输出路径,现在来看看 StreamingFileSink( 据说是StreamingFileSink 是社区优化后添加的connector,推荐使用)
StreamingFileSink 实现起来会稍微麻烦一点(也是灵活,功能更强大),因为可以自己实现序列化方法(源码里面有实例可以参考-复制)
StreamingFileSink 有两个方法可以输出到文件 forRowFormat 和 forBulkFormat,名字差不多代表的方法的含义:行编码格式和块编码格式
forRowFormat 比较简单,只提供了 SimpleStringEncoder 写文本文件,可以指定编码,如下:
import org.apache.flink.api.common.serialization.SimpleStringEncoder
import org.apache.flink.core.fs.Path
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink val input: DataStream[String] = ... val sink: StreamingFileSink[String] = StreamingFileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder[String]("UTF-8")) // 所有数据都写到同一个路径
.build() input.addSink(sink)
当然我们的主题还是根据输入数据自定义文件输出路径,就需要重写 DayBucketAssigner,如下:
import java.io.IOException
import java.nio.charset.StandardCharsets
import org.apache.flink.core.io.SimpleVersionedSerializer
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.node.ObjectNode
import org.apache.flink.streaming.api.functions.sink.filesystem.BucketAssigner class DayBucketAssigner extends BucketAssigner[ObjectNode, String] { /**
* bucketId is the output path
* @param element
* @param context
* @return
*/
override def getBucketId(element: ObjectNode, context: BucketAssigner.Context): String = {
//context.currentProcessingTime()
val day = element.get("date").asText("19790101000000").substring(0, 8)
// wrap can use day + "/" + xxx
day
} override def getSerializer: SimpleVersionedSerializer[String] = { StringSerializer
} /**
* 实现参考 : org.apache.flink.runtime.checkpoint.StringSerializer
*/
object StringSerializer extends SimpleVersionedSerializer[String] {
val VERSION = 77 override def getVersion = 77 @throws[IOException]
override def serialize(checkpointData: String): Array[Byte] = checkpointData.getBytes(StandardCharsets.UTF_8) @throws[IOException]
override def deserialize(version: Int, serialized: Array[Byte]): String = if (version != 77) throw new IOException("version mismatch")
else new String(serialized, StandardCharsets.UTF_8)
}
}
在初始化sink 的时候,指定 BucketAssigner 就可以了
val sinkRow = StreamingFileSink
.forRowFormat(new Path("D:\\idea_out\\rollfilesink"), new SimpleStringEncoder[ObjectNode]("UTF-8"))
.withBucketAssigner(new DayBucketAssigner)
// .withBucketCheckInterval(60 * 60 * 1000l) // 1 hour
.build()
执行结果如下:
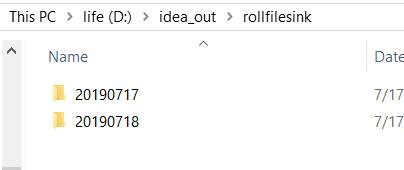
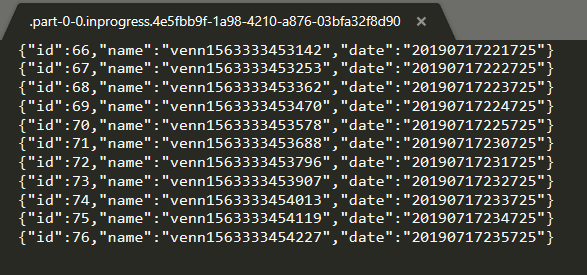
2、 forBulkFormat 和forRowFormat 不太一样,需要自己实现 BulkWriterFactory 和 DayBulkWriter,自定义程度高,可以实现自己的 FSDataOutputStream,写出各种格式的文件(forRowFormat 自定义Encoder 也可以,但是如 forBuckFormat 灵活)
// use define BulkWriterFactory and DayBucketAssinger
val sinkBuck = StreamingFileSink
.forBulkFormat(new Path("D:\\idea_out\\rollfilesink"), new DayBulkWriterFactory)
.withBucketAssigner(new DayBucketAssigner())
.build()
实现如下:
import java.io.File
import java.nio.charset.StandardCharsets
import org.apache.flink.api.common.serialization.BulkWriter
import org.apache.flink.core.fs.FSDataOutputStream
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.node.ObjectNode
import org.apache.flink.util.Preconditions /**
* 实现参考 : org.apache.flink.streaming.api.functions.sink.filesystem.BulkWriterTest
*/
class DayBulkWriter extends BulkWriter[ObjectNode] { val charset = StandardCharsets.UTF_8
var stream: FSDataOutputStream = _ def DayBulkWriter(inputStream: FSDataOutputStream): DayBulkWriter = {
stream = Preconditions.checkNotNull(inputStream);
this
} /**
* write element
*
* @param element
*/
override def addElement(element: ObjectNode): Unit = {
this.stream.write(element.toString.getBytes(charset))
// wrapthis.stream.write('\n')
} override def flush(): Unit = {
this.stream.flush()
} /**
* output stream is input parameter, just flush, close is factory's job
*/
override def finish(): Unit = {
this.flush()
} } /**
* 实现参考 : org.apache.flink.streaming.api.functions.sink.filesystem.BulkWriterTest.TestBulkWriterFactory
*/
class DayBulkWriterFactory extends BulkWriter.Factory[ObjectNode] {
override def create(out: FSDataOutputStream): BulkWriter[ObjectNode] = {
val dayBulkWriter = new DayBulkWriter
dayBulkWriter.DayBulkWriter(out) }
}
执行的结果就不赘述了
又遇到个问题,StreamFileSink 没办法指定输出文件的名字。
BucketingSink 和 StreamingFileSink 的不同:
从源码位置来说:
BucketingSink 在 connector 下面,注重输出数据
StreamingFileSink 在api 下面,注重与三方交互
从版本来说:
BucketingSink 比较早就有了
StreamingFileSink 是1.6版本推出的功能(据说是优化后推出的)
从支持的文件系统来说:
BucketingSink 支持Hadoop 文件系统支持的所有文件系统(原文:This connector provides a Sink that writes partitioned files to any filesystem supported by Hadoop FileSystem)
StreamingFileSink 支持Flink FileSystem 抽象文件系统 (原文:This connector provides a Sink that writes partitioned files to filesystems supported by the Flink FileSystem abstraction)
从写数据的方式来说:
BucketingSink 默认的Writer是StringWriter,也提供SequenceFileWriter(字符)
StreamingFileSink 使用 OutputStream + Encoder 对外写数据 (字节)
从文件滚动策略来说:
BucketingSink 提供了时间、条数滚动
StreamingFileSink 默认提供时间(官网有说条数,没看到 This is also configurable but the default policy rolls files based on file size and a timeout,自己实现BulkWriter可以)
从目前(1.7.2)来说,BucketingSink 更开箱即用(功能相对简单),StreamingFileSink更麻烦(更灵活、强大)
只是个初学者,还不太能理解 BucketingSink 和 StreamingFileSink 的差异,等了解之后,再来完善
结论:比较推荐使用StreamingFileSink
理由:功能强大,数据刷新时间更快(没有,BucketingSink默认60S的问题,详情见上篇,最后一段)
Flink FileSink 自定义输出路径——StreamingFileSink、BucketingSink 和 StreamingFileSink简单比较的更多相关文章
- Flink FileSink 自定义输出路径——BucketingSink
今天看到有小伙伴在问,就想着自己实现一下. 问题: Flink FileSink根据输入数据指定输出位置,比如讲对应日期的数据输出到对应目录 输入数据: 20190716 输出到路径 20190716 ...
- Hadoop案例(五)过滤日志及自定义日志输出路径(自定义OutputFormat)
过滤日志及自定义日志输出路径(自定义OutputFormat) 1.需求分析 过滤输入的log日志中是否包含xyg (1)包含xyg的网站输出到e:/xyg.log (2)不包含xyg的网站输出到e: ...
- Lrc2srt精灵,增加自定义输出编码
2015.4.8 对中文支持有点问题,修改了一下,支持自定义输出编码! 修改了建议行末偏移,通常100到200最好了,人的反应时间! http://files.cnblogs.com/files/ro ...
- VS 工程的 输出路径和工作路径的区别
输出路径,是vs编译项目生成可执行文件的路径:工作路径是环境变量,比如我们在程序中写相对路径,就是以这个路径为基础的.在默认情况下,输出路径和工作路径都不写的话,默认是程序的bin下面的debug或者 ...
- HD1385Minimum Transport Cost(Floyd + 输出路径)
Minimum Transport Cost Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/O ...
- EDIUS设置自定义输出的方法
在做后期视频剪辑时,往往根据需求,需要输出不同分辨率格式的视频文件,那在EDIUS中,如何自定义输出设置,使之符合自己的需要呢?下面小编就来详细讲讲EDIUS自定义输出的一二事吧. 当剪辑完影片,设置 ...
- C++builder XE 安装控件 及输出路径
C++builder XE 安装控件 与cb6不一样了,和delphi可以共用一个包. 启动RAD Studio.打开包文件. Project>Options>Delphi Compile ...
- HDU 1385 Minimum Transport Cost (最短路,并输出路径)
题意:给你n个城市,一些城市之间会有一些道路,有边权.并且每个城市都会有一些费用. 然后你一些起点和终点,问你从起点到终点最少需要多少路途. 除了起点和终点,最短路的图中的每个城市的费用都要加上. 思 ...
- web项目Log4j日志输出路径配置问题
问题描述:一个web项目想在一个tomcat下运行多个实例(通过修改war包名称的实现),然后每个实例都将日志输出到tomcat的logs目录下实例名命名的文件夹下进行区分查看每个实例日志,要求通过尽 ...
随机推荐
- Calling Extraterrestrial Intelligence Again POJ 1411
题目链接:http://poj.org/problem?id=1411 题目大意:找两个素数p,q满足a/b<=p/q<=1 且p*q<=m,求p*q最大的一组素数对. 第一次想的是 ...
- SSM整合Dubbo登陆案例
登陆案例 一.创建Service项目存放共同数据 1.1 创建实体类 private long id; private String loginName; private String userNa ...
- docker 挂载实现容器配置更改为外部文件
docker安装镜像后,每个服务都是独立的容器,容器与容器之间可以说是没关系,隔离独立的. 而且虚拟出来的这些容器里面的基本安装工具都是没有的,比如vi,vim等等.需要使用,还得安装处理. 那么我们 ...
- Tensorflow细节-P194-组合训练数据
import tensorflow as tf files = tf.train.match_filenames_once("data.tfrecords-*") filename ...
- Mysql 基础 1
MySQL基础 1.概念 数据库,为我们提供高效.便捷的方式对数据进行增删改查的工具 优势 程序稳定.数据一致性.并发.效率 2.数据库管理系统 (DataBase Management System ...
- C语言定义结构体指针数组并初始化;里面全是结构体的地址
#include <stdio.h> #include <string.h> struct tells;//声明结构体 struct info { char *infos; } ...
- P4568 飞行路线 分层图最短路
P4568 飞行路线 分层图最短路 分层图最短路 问题模型 求最短路时,可有\(k\)次更改边权(减为0) 思路 在普通求\(Dijkstra\)基础上,\(dis[x][j]\)多开一维\(j\)以 ...
- copy()函数技术推演
/*** str_copy.c ***/ #include<stdio.h> void copy_str21(char *from, char *to) { for(; *from != ...
- 部署Django到云服务器(centos+nginx+mysql+uwsgi+python3)【操作篇(1)】
开篇 笛卡尔说:"你不能教会一个人任何东西,你只能帮助他发现他自己内心本来就有的东西!" jacky能教你的,只能是经验和建议,要逆袭还得通过自己对数据的不断领悟,数据领域的技能都 ...
- Bootstrap selectpicker 下拉框多选获取选中value和多选获取文本值
1.页面代码: 页面引入: bootstrap-select.min.css和 bootstrap-select.min.js. defaults-zh_CN.min.js文件,并初始化下拉选项框. ...