【生活现场】从打牌到map-reduce工作原理解析(转)
原文:http://www.sohu.com/a/287135829_818692

小史是一个非科班的程序员,虽然学的是电子专业,但是通过自己的努力成功通过了面试,现在要开始迎接新生活了。
对小史面试情况感兴趣的同学可以观看面试现场系列。

找到工作后的一小段时间是清闲的,小史把新租房收拾利索后,就开始找同学小赵,小李和小王来聚会了。
吃过午饭后,下午没事,四个人一起商量来打升级。打升级要两副扑克牌,小史就去找吕老师借牌去了。

【多几张牌】

吕老师给小史拿出一把牌。




【map-reduce】



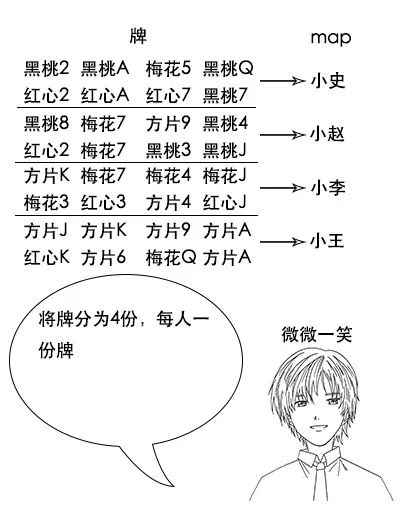













(注意,如果有两幅完整的牌,那么小赵手中的黑桃A一定不少于2张,因为其他人手中已经不可能有黑桃A了,图中的数据只是演示。)

【hadoop中的map-reduce】

吕老师:过程看上去很简单,但是要实现并不简单,要考虑很多异常情况,幸好开源项目hadoop已经帮我们实现了这个模型,我们用它很简单就能实现map-reduce。



吕老师:hadoop是一个分布式计算平台,我们只要开发map-reduce的作业(job),然后提交到hadoop平台,它就会帮我们跑这个map-reduce的作业啦。


map阶段:
publicstaticclassMyMapperextendsMapper<LongWritable, Text, Text, LongWritable> {
protectedvoidmap(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context)throwsjava.io.IOException, InterruptedException {
String card = value.toString();
context.write( newText(card), newLongWritable( 1L));
};
}
(友情提示:可左右滑动)

吕老师:申明不用看,主要看map方法,它有三个参数,key、value和context,逻辑也很简单,其实就是用context.write往下游写了一个(card,1)的映射关系。
reduce阶段:
publicstaticclassMyReducerextendsReducer<Text, LongWritable, Text, LongWritable> {
protectedvoidreduce(Text key, java.lang.Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context)throwsjava.io.IOException, InterruptedException {
longcount = 0L;
for(LongWritable value : values) {
count += value.get();
}
context.write(key, newLongWritable(count));
};
}
(友情提示:可左右滑动)

吕老师:reduce也很简单,方法中三个参数,key、values和context,因为到了reduce阶段,一个key可能有多个value,所以这里传进来的是values,函数逻辑其实就是简单地将values累加,然后通过context.write输出。

小史:我明白了,hadoop其实把map-reduce的流程已经固定下来并且实现了,只留给我们自定义map和自定义reduce的接口,而这两部分恰好是和业务强相关的。

小史:也就是说业务方只需要告诉hadoop怎么进行map和怎么进行reduce,hadoop就能帮我们跑map-reduce的计算任务啦。
【分区函数】


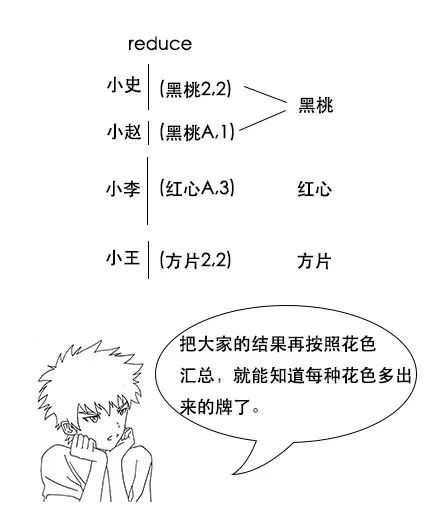



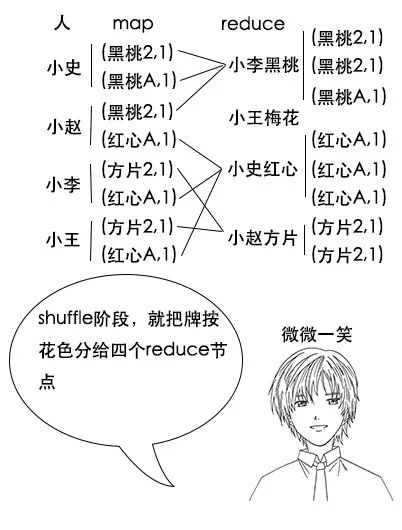

小史:我明白了,这样一来,最后reduce完成之后,我这边多出来的牌全是红心的,其他人多出来的牌也算是同一花色,就不用进行二次统计了,这真是个好办法。

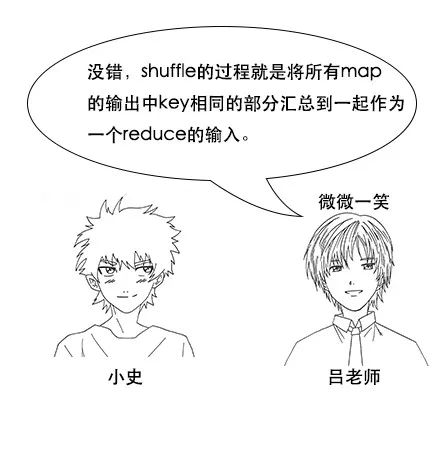
吕老师:没错,这就是分区函数的作用,在hadoop中,虽然shuffle阶段有默认规则,但是我们可以自定义分区函数来改变这个规则,让它更加适合我们的业务。
【合并函数】





吕老师:如果你不合并,那么传给shuffle阶段的就有两个数据,如果你预合并了,那么传给shuffle阶段的就只有一个数据,这样数据量减少了一半。





吕老师:hadoop当然考虑到了这个点,你可以自定义一个合并函数,hadoop在map阶段会调用它对本地数据进行预合并。

【hadoop帮我们做的事情】







吕老师:还有呀,刚才说的分布式系统中网络传输是有成本的,hadoop会帮我们把数据送到最近的节点,尽量减少网络传输。




吕老师:hadoop有两大重大贡献,一个是刚刚讲的map-reduce,另一个是分布式文件系统hdfs,hdfs可以说是分布式存储系统的基石。其实一般来说,map-reduce任务的输入,也就是那个很大的数据文件,一般都是存在hdfs上的。

【笔记】
小史在往回走的路上,在手机里记录下了这次的笔记。
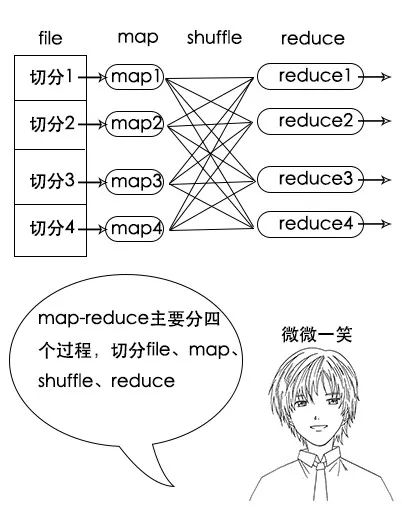
一、map-reduce的四个关键阶段:file切分、map阶段、shuffle阶段、reduce阶段。
二、hadoop帮我们做了大部分工作,我们只需自定义map和reduce阶段。
三、可以通过自定义分区函数和合并函数控制map-reduce过程的细节。
四、hadoop还有一个叫hdfs的牛逼东西,下次问问吕老师。
【回到房间】
生活现场是互联网侦察推出的现场系列中的另一个板块,旨在通过生活中的场景,来解释大数据微服务技术中的基本原理,希望对大家学习技术原理有所帮助。
【生活现场】从打牌到map-reduce工作原理解析(转)的更多相关文章
- jdk线程池ThreadPoolExecutor工作原理解析(自己动手实现线程池)(一)
jdk线程池ThreadPoolExecutor工作原理解析(自己动手实现线程池)(一) 线程池介绍 在日常开发中经常会遇到需要使用其它线程将大量任务异步处理的场景(异步化以及提升系统的吞吐量),而在 ...
- Map/Reduce 工作机制分析 --- 数据的流向分析
前言 在MapReduce程序中,待处理的数据最开始是放在HDFS上的,这点无异议. 接下来,数据被会被送往一个个Map节点中去,这也无异议. 下面问题来了:数据在被Map节点处理完后,再何去何从呢? ...
- 第十篇:Map/Reduce 工作机制分析 - 数据的流向分析
前言 在MapReduce程序中,待处理的数据最开始是放在HDFS上的,这点无异议. 接下来,数据被会被送往一个个Map节点中去,这也无异议. 下面问题来了:数据在被Map节点处理完后,再何去何从呢? ...
- Map/Reduce 工作机制分析 --- 作业的执行流程
前言 从运行我们的 Map/Reduce 程序,到结果的提交,Hadoop 平台其实做了很多事情. 那么 Hadoop 平台到底做了什么事情,让 Map/Reduce 程序可以如此 "轻易& ...
- 第九篇:Map/Reduce 工作机制分析 - 作业的执行流程
前言 从运行我们的 Map/Reduce 程序,到结果的提交,Hadoop 平台其实做了很多事情. 那么 Hadoop 平台到底做了什么事情,让 Map/Reduce 程序可以如此 "轻易& ...
- Servlet 工作原理解析
转自:http://www.ibm.com/developerworks/cn/java/j-lo-servlet/ Web 技术成为当今主流的互联网 Web 应用技术之一,而 Servlet 是 J ...
- [转]Servlet 工作原理解析
Web 技术成为当今主流的互联网 Web 应用技术之一,而 Servlet 是 Java Web 技术的核心基础.因而掌握 Servlet 的工作原理是成为一名合格的 Java Web 技术开发人员的 ...
- Servlet 工作原理解析--转载
原文:http://www.ibm.com/developerworks/cn/java/j-lo-servlet/index.html?ca=drs- Web 技术成为当今主流的互联网 Web 应用 ...
- 【Java】Servlet 工作原理解析
Web 技术成为当今主流的互联网 Web 应用技术之一,而 Servlet 是 Java Web 技术的核心基础.因而掌握 Servlet 的工作原理是成为一名合格的 Java Web 技术开发人员的 ...
随机推荐
- php取整的几种方式,四舍五入,舍去法取整,进一法取整
php取整的几种方式,四舍五入,舍去法取整,进一法取整方式一:round 对浮点数进行四舍五入语法:float round ( float val [, int precision] ) echo r ...
- 使用 docker-compose 运行 MySQL
使用 docker-compose 运行 MySQL 目录结构 . │ .env │ docker-compose.yml │ └─mysql ├─config │ my.cnf │ └─data m ...
- 深度学习中目标检测Object Detection的基础概念及常用方法
目录 关键术语 方法 two stage one stage 共同存在问题 多尺度 平移不变性 样本不均衡 各个步骤可能出现的问题 输入: 网络: 输出: 参考资料 What is detection ...
- JS高阶---定时器相关
首先看几个问题: [主体] (1)定时器真的时定时执行的吗? 顺序验证: 测试结果: 接下来对上述代码做下修改,增加一个长时间工作的消耗,此时再来验证下定时器运行的精准度 结果如下: (2)定时器回调 ...
- JS高阶---作用域面试
面试题1: ,答案为10 有一点需要明确:作用域是在定义编写代码时已经决定好的 面试题2: 结果1: 结果2: 首先在内部作用域找,没有 然后在全局作用域找,window没有,所以会报错 如果想找对象 ...
- pdfium:创建CreateNewDoc
CreateNewDoc //创建文档 https://github.com/PureFusionOS/android_external_pdfium/blob/040b899a933cdb37 ...
- mysql5.6运行一段时间之后网站页面出现乱码解决办法
mysql5.6运行一段时间之后网站页面出现乱码,怎么都打不开,经过排查之后,知道是数据库默认字符集出问题了,在此分享给大家经验. 在mysql5.6配置文件:my.ini 找到: 添加如下内容: [ ...
- mac pro下安装安装 SymPy 和 matplotlib报错解决方案
因为自己写python分析时候要用到这两个库,但是mac 上安装不成功.原来是要安装原来装 matplotlib 之前先要安装 freetyp 和 libpng. brew install freet ...
- VC 静态库与动态库(四)动态库创建与使用_显示调用
在第三章的基础上,接着添加一个显示调用项目 显示调用项目创建: 1.给解决方案添加一个新的控制台项目DisplayCall用于测试动态库,创建完成后设置为启动项目 2.DisplayCall.cpp添 ...
- HDU1213:How Many Tables(并查集入门)
-----------刷点水题练习java------------- 题意:给定N点,M边的无向图,问有多少个连通块. 思路:可以搜索; 可以并查集.这里用并查集练习java的数组使用,ans=N, ...