python网络爬虫(2)——scrapy框架的基础使用
这里写一下爬虫大概的步骤,主要是自己巩固一下知识,顺便复习一下。
一,网络爬虫的步骤
1,创建一个工程
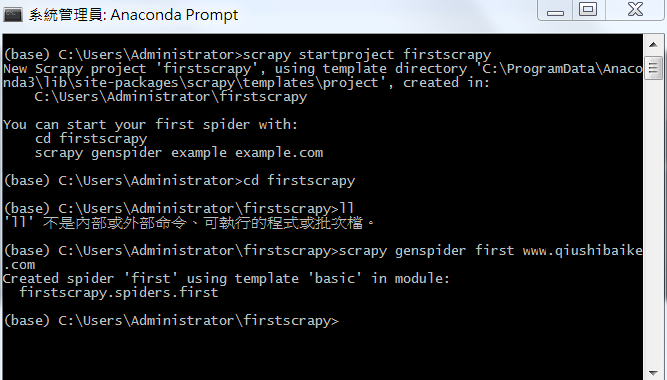
scrapy startproject 工程名称
创建好工程后,目录结构大概如下:

其中:
scrapy.cfg:项目的主配置信息(真正爬虫相关的配置信息在settings.py文件中)
items.py:设置数据存储模板,用于结构化数据,如:Django的Model
pipelines:数据持久化处理
settings.py:配置文件,如:递归的层数,并发数,延迟下载等
spiders:爬虫目录,如:创建文件,编写爬虫解析规则
2,在工程目录下创建一个爬虫文件
1, cd 工程
2,scrapy genspider example example.com
其中: example:表示爬虫文件的名称
example.com 表示起始的url(这个url可以随意写,最后在文件中修改即可)
3,对应的文件中编写爬虫程序来完成爬虫的相关操作
打开first.py,然后进入编写:

4,配置文件的编写
进入settings.py 中修改2个地方:
1,在大概19行中:对请求载体的身份进行伪装
我们可以去谷歌中找一个User-Agent的值 复制进去。效果如下: USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36' 2,在大概22行中,修改robots协议
robots协议是君子协议,大概爬虫的话,我们可以不遵照这个协议,哈哈哈哈 ROBOTSTXT_OBEY = False
5,执行
scrapy crwal 爬虫文件的名称 --nolog(组织日志信息的输出) # 输出打印信息
scrapy crawl first # 不输出打印信息
scrapy crawl first --nolog
效果如下:
【爬取的是杨子晚报,这里就以此为例,创建scrapy爬虫 网址:http://www.yangtse.com/】
第一步:安装scrapy框架
(这里不做详细介绍了,要是安装遇到问题的朋友们,可以参考下面链接
http://www.cnblogs.com/wj-1314/p/7856695.html)
第二步:创建scrapy爬虫文件
格式:scrapy startproject + 项目名称
scrapy startproject yangzi
第三步:进入爬虫文件
格式:cd 项目名称
cd yangzi
第四步:创建爬虫项目
格式:scrapy genspider -t basic 项目名称 网址
具体用法如下:

scrapy genspider -t basic yz http://www.yangtse.com/
创建好了,如下图:

解释一下文件:
- scrapy.cfg:项目的配置文件
- yangzi:该项目的python模块。之后您将在此加入代码。
- yangzi/items.py:项目中的item文件。
- yangzi/pipelines.py:项目中的pipelines文件。
- yangzi/yz/:放置spider代码的目录。
第五步:进入爬虫项目中,先写items
写这个的目的就是告诉项目,你要爬去什么东西,比如标题,链接,作者等.
Item是保存爬取到的数据的容器:其使用方法和python字典类似,并且提供了额外保护机制来避免拼写错误导致的未定义字段错误。
类似在ORM中做的一样,你可以通过创建一个scrapy.Item类,并且定义类型为scrapy.Field的类属性来定义一个Item。
首先根据需要从dmoz.org获取到的数据对item进行建模。我们需要从dmoz中获取名字,url,以及网站的描述。对此,在item中定义相应的字段。
以我写的为例,我想爬取标题,链接,内容,如下:
class YangziItem(scrapy.Item):
# define the fields for your item here like:
#标题
title = scrapy.Field()
#链接
link = scrapy.Field()
#内容
text = scrapy.Field()
第六步:进入pipelines,设置相应程序
分析爬去的网站,依次爬取的东西,因为pipelines是进行后续处理的,比如把数据写入MySQL,或者写入本地文档啊等等,就在pipelies里面写。这里直接输出,不做数据库的导入处理
class YangziPipeline(object):
def process_item(self, item, spider):
print(item["title"])
print(item["link"])
return item
第七步:再写自己创建的爬虫
(其实,爬虫和pipelines和settings前后顺序可以颠倒,这个不重要,但是一定要先写items)
Spider是用户编写用于从单个网站(或者一些网站)爬取数据的类。
其包含了一个用于下载的初始url,如何跟进网页中的链接以及如何分析页面中的内容,提取生成item的方法。
为了创建一个Spider,您必须继承scrapy.Spider类,且定义以下三个属性:
name:用于区别Spider。改名字必须是唯一的,您不可以为不同的Spider设定相同的名字。start_urls:包含了Spider在启动时进行爬取的url列表。因此,第一个被获取的页面给将是其中之一。后续的URL则从初始的URL获取到的数据中提取。parse():是spider的一个方法。被调用时,每个初始url完成下载后生成的Response对象将会作为唯一的参数传递给该函数。该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的Request对象。
进入爬虫后,先导入items,接下来需要创建一个ITEM容器,
it = YangziItem()
然后写自己的要爬去的内容,分析网页后,利用xpath写
def parse(self, response):
it = YangziItem()
it["title"] = response.xpath('//div[@class="box-text-title]/text()').extract()
it["link"] = response.xpath('//a[@target="_blank"]/@href').extract()
#it["text"] = response.xpath().extract()
yield it
第八步:设置settings
在settings中配置pipelines(ctrl+f 找到pipelines,然后解除那三行的注释,大约在64-68行之间),如下图

第九步:运行爬虫文件
scrapy crawl yz
scrapy crawl yz --nolog #不想显示日志文件
python网络爬虫(2)——scrapy框架的基础使用的更多相关文章
- Python网络爬虫之Scrapy框架(CrawlSpider)
目录 Python网络爬虫之Scrapy框架(CrawlSpider) CrawlSpider使用 爬取糗事百科糗图板块的所有页码数据 Python网络爬虫之Scrapy框架(CrawlSpider) ...
- 16.Python网络爬虫之Scrapy框架(CrawlSpider)
引入 提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调parse方法). 方法 ...
- 16,Python网络爬虫之Scrapy框架(CrawlSpider)
今日概要 CrawlSpider简介 CrawlSpider使用 基于CrawlSpider爬虫文件的创建 链接提取器 规则解析器 引入 提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话, ...
- Python逆向爬虫之scrapy框架,非常详细
爬虫系列目录 目录 Python逆向爬虫之scrapy框架,非常详细 一.爬虫入门 1.1 定义需求 1.2 需求分析 1.2.1 下载某个页面上所有的图片 1.2.2 分页 1.2.3 进行下载图片 ...
- 网络爬虫值scrapy框架基础
简介 Scrapy是一个高级的Python爬虫框架,它不仅包含了爬虫的特性,还可以方便的将爬虫数据保存到csv.json等文件中. 首先我们安装Scrapy. 其可以应用在数据挖掘,信息处理或存储历史 ...
- Python学习---爬虫学习[scrapy框架初识]
Scrapy Scrapy是一个框架,可以帮助我们进行创建项目,运行项目,可以帮我们下载,解析网页,同时支持cookies和自定义其他功能. Scrapy是一个为了爬取网站数据,提取结构性数据而编写的 ...
- python网络爬虫之scrapy 工程创建以及原理介绍
执行scrapy startproject XXXX的命令,就会在对应的目录下生成工程 在pycharm中打开此工程目录:并在Run中选择Edit Configuration 点击+创建一个Pytho ...
- 网络爬虫之scrapy框架设置代理
前戏 os.environ()简介 os.environ()可以获取到当前进程的环境变量,注意,是当前进程. 如果我们在一个程序中设置了环境变量,另一个程序是无法获取设置的那个变量的. 环境变量是以一 ...
- 网络爬虫之scrapy框架(CrawlSpider)
一.简介 CrawlSpider其实是Spider的一个子类,除了继承到Spider的特性和功能之外,还派生了其自己独有的更强大的特性和功能.其中最显著的功能就是"LinkExtractor ...
- 网络爬虫之scrapy框架详解
twisted介绍 Twisted是用Python实现的基于事件驱动的网络引擎框架,scrapy正是依赖于twisted, 它是基于事件循环的异步非阻塞网络框架,可以实现爬虫的并发. twisted是 ...
随机推荐
- .NET Core 收徒,有缘者,可破瓶颈
最近感悟天命,偶有所得,故而打算收徒若干,以继吾之传承. 有缘者,可破瓶颈,职场巅峰指日可待. 入门基本要求: 1.工作经验:1年或以上. 2.拜师费用:3999元(RMB). 传承说明: 1.收徒人 ...
- echarts折线图上下颜色渐变样式
// 折线图let lineChart = echarts.init(document.getElementById('lineChart'));let lineOption = { title: { ...
- vue cli 3.0快速创建项目
本地安装vue-cli 前置条件 更新npm到最新版本 命令行运行: npm install -g npmnpm就自动为我们更新到最新版本 淘宝npm镜像使用方法 npm config set reg ...
- warning: Unexpected unnamed function (func-names)
warning: Unexpected unnamed function (func-names) 看到这个提示基本是就是说你的函数不能是匿名函数,最好可以起一个名字,然后你增加一个函数名称就好了 R ...
- unlink remove
int unlink(const char *pathname); 删除一个文件的目录项并减少它的链接数 unlink()会删除参数pathname指定的文件.如果该文件名为最后连接点,但有其他进程打 ...
- 如何在一个ubuntu系统上搭建SVN版本控制工具
有话说,由于公司项目部署需要,将Windows工程迁移到Linux,通过调查确定使用Ubuntu的Linux操作系统.那么如何快速搭建和Windows一样快捷方便的开发环境就很重要了.本文讲述如何在一 ...
- MarkdownPad 2破解
MarkdownPad 2 是一款较不错的Markdown编辑器,可快速将文本转换为美观的HTML/XHTML的网页格式代码,且操作方便,用户可以通过键盘快捷键和工具栏按钮来使用或者移除Markdow ...
- <人人都懂设计模式>-单例模式
这个模式,我还是了解的. 书上用了三种不同的方法. class Singleton1: # 单例实现方式1 __instance = None __is_first_init = False def ...
- WordPress自定义查询WP_Query使用方法大全
自定义调用文章在网站建设中很常用,wordpress也很人性化,用新建查询new WP_Query就能实现相关功能.WP_Query怎么用呢?随ytkah一起来看看吧 我们知道wordpress的主循 ...
- zz2017-2018年AI技术前沿进展与趋势
2017年AI技术前沿进展与趋势 人工智能最近三年发展得如火如荼,学术界.工业界.投资界各方一起发力,硬件.算法与数据共同发展,不仅仅是大型互联网公司,包括大量创业公司以及传统行业的公司都开始涉足人工 ...