Mysql关键字Explain 性能优化神器
Explain工具介绍
使用EXPLAIN关键字可以模拟优化器执行SQL语句,分析查询语句或是结构的性能瓶颈。在select语句之前增加explaion关键字,MySQL会在查询上设置一个标记,执行查询会返回执行计划的信息,而不是执行SQL。
Explaion分析示例
-- actor建表语句:
CREATE TABLE `actor` (
`id` int(11) NOT NULL,
`name` varchar(45) DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
-- film建表语句:
CREATE TABLE `film` (
`id` int(11) NOT NULL,
`name` varchar(10) NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
-- film_actor建表语句:
CREATE TABLE `film_actor` (
`id` int(11) NOT NULL,
`film_id` int(11) NOT NULL,
`actor_id` int(11) NOT NULL,
`remark` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_film_actor_id` (`film_id`,`actor_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
执行explain:
explain select * from actor;

如果是select语句返回的是执行结果,在select语句前面加上explain返回的是这条查询语句的执行SQL。
EXPLAIN两个变种
explain extended
会在explain的基础上额外提供一些查询优化的信息。紧随其后通过show warnings命令可以得到优化后的查询语句,从而看出优化器优化了什么。额外还有filtered列,是一个半分比的值,rows*filtered / 100可以估算出将要和explain中前一个表进行连接的行数(前一个表指explain中的id值比当前表id值小的表)。
explain EXTENDED select * from actor where id = 1;

explain partitions
相比explain多了个partitions字段,如果查询是基于分区表的话,会显示查询将访问的分区。
Explain中的列
id列
id列的编号是select的序列号,有几个select就有几个id,并且id的顺序是按select出现的顺序增长的。
id越大执行优先级越高,id相同则从上往下执行,id为NULL最后执行。
explain select (select 1 from actor where id = 1) from (select * from film
where id = 1) der;

select type列
select type表示对应行是简单还是复杂的查询。
simple:简单查询。查询不包含子查询和union。
explain select * from film where id=1

primary:复杂查询中最外层的select
subquery:包含在select中的子查询(不在from子句中)
derived:包含在from子句中的子查询。MySQL会将结果存放在一个临时表中,也称为派生表。
explain select (select 1 from actor where id = 1) from (select * from film
where id = 1) der;

union:在union关键字随后的selelct。
EXPLAIN select 1 union all select 1;

table列
这一列表示explain的一行正在访问哪个表。
当from子句中有子查询时,table列是格式,表示当前查询依赖id=N的查询,于是先执行id=N的查询。
当有union时,UNION RESULT的table列的值为<union 1,2>,1和2表示参与union的select行id。
type列
这一列表示关联类型或访问类型,即MySQL决定如何查找表中的行,查找数据行对应的大概范围。
依次从最优到最差的分别为:system>const>eq_ref>ref>range>index>All
一般来说,得保证查询达到range级别,最好达到ref。
NULL:MySQL能够在优化阶段分解查询语句,在执行阶段用不着在访问表或索引。例如:在索引列中选取最小值,可以单独查找索引来完成,不需在执行时访问表。
EXPLAIN select min(id) from film;

- const、system:mysql能对查询的某部分进行优化并将其转换成一个常量(可看成是show warnings的结果)。用于primay key或unique key的所有列与常数比较时,所以表最多有一个匹配行,读取1次,速读较快。system 是const的特例,表中只有一行元素匹配时为system。
EXPLAIN select * from (select * from film where id= 1) as tmp;

- eq_ref:primay key或 unique key索引的所有部分被连接使用,最多只会返回一条符合条件的记录。这可能是const之外最好的联接类型,简单的select查询不会出现这种type。
EXPLAIN select * from (select * from film where id= 1) as tmp;

- ref:相比eq_ref,不适用唯一索引,而是使用普通索引或者唯一索引的部分前缀,索引要和某个值相比较,可能会找到多个符合条件的行。
简单select查询,name是普通索引(非主键索引或唯一索引)
EXPLAIN select * from film where name='film1';

关联表查询,idx_film_actor_id是film_id和actor_id的联合索引,这里使用到了film_actor的左边前缀film_id部分。
EXPLAIN select film_id from film LEFT JOIN film_actor on film.id = film_actor.film_id;

- range:范围扫描通常出现在in(), between,>,<,>=等操作中。使用一个索引来检索给定范围的行。
EXPLAIN select * from actor WHERE id >1;

- index:扫描全表索引,通常比All快一些
EXPLAIN select * from film;
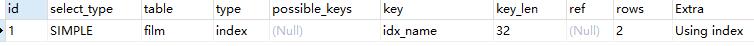
- all:即全表扫描,意味着MySQL需要从头到尾去查找所需要的行。这种情况下需要增加索引来进行优化。
EXPLAIN SELECT * from actor;

possible_keys列
这一列显示select可能会使用哪些查询来查找。
explain时可能会出现possible_keys有列,而key显示为NULL的情况,这种情况是因为表中的数据不多,MySQL认为索引对此查询帮助不大,选择了全表扫描。
如果该列为NULL,则没有相关的索引。这种情况下,可以通过检查where子句看是否可以创造一个适当的索引来提高查询性能,然后用explain查看效果。
EXPLAIN SELECT * from film_actor where film_id =1;

key列
这一列显示MySQL实际采用哪个索引对该表的访问。
如果没有使用索引,则改列为NULL。如果想强制MySQL使用或忽视possible_keys列中的索引,在查询中使用force index、 ignore index。
key_len列
这一列显示了mysql在索引里使用的字节数,通过这个值可以估算出具体使用了索引中的哪些列。
EXPLAIN SELECT * from film_actor where film_id =1;

film_actor的联合索引idx_film_actor_id由film_id和actor_id两个id列组成,并且每个int是4字节。通过结果中的key_len=4可推断出查询使用了第一个列:film_id列来执行索引查找。
ken_len计算规则如下:
字符串
char(n):n字节长度
varchar(n):n字节存储字符串长度,如果是utf-8, 则长度是3n+2数值类型
tinyint:1字节
smallint:2字节
int:4字节
bigint:8字节时间类型
date:3字节
timestamp:4字节
datetime:8字节
如果字段允许为NULL,需要1字节记录是否为NULL
索引最大长度是768字节,当字符串过长时,MySQL会做一个类似做前缀索引的处理,将前半部分的字符串提取出来做索引。
ref列
这一列显示了在key列记录的索引中,表查找值所用到的列或常量,常见的有: const(常量),字段名等。一般是查询条件或关联条件中等号右边的值,如果是常量那么ref列是const,非常量的话ref列就是字段名。
EXPLAIN SELECT * from film_actor where film_id =1;

row列
这一列是mysql估计要读取并检测的行数,注意这个不是结果集的行数。
Extra列
这一列是额外信息。
- Using index:使用覆盖索引(结果集的字段是索引,即select后的film_id)
explain select film_id from film_actor where film_id=1;
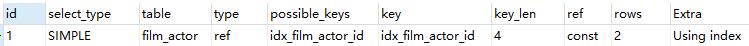
- Using index condition:查询的列不完全被索引覆盖,where条件中是一个前导的范围
explain select * from film_actor where film_id > 1;
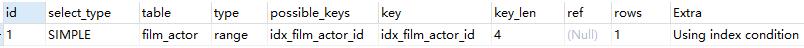
- Using where:使用where语句来处理结果,查询的列未被索引覆盖
explain select * from actor where name ='a'

- Using temporary:mysql需要创建一张临时表来处理查询。出现这种情况一般要进行优化,首先要想到是索引优化。
explain select DISTINCT name from actor;

actor.name没有索引,此时创建了临时表来处理distinct。
explain select DISTINCT name from film;
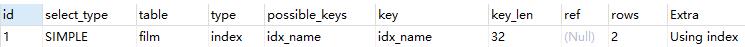
file.name建立了普通索引,此时查询时Extra是Using index,没有用到临时表。
- Using filesort:将用外部排序而不是索引排序,数据较小时从内存排序,否则需要在磁盘完成排序。这种情况下一般也是要考虑使用索引来优化的。
explain select * from actor order by name;

actor.name未创建索引,会浏览acotr整个表,保存排序关键字name和对应id,然后排序name并检索行记录。
explain select * from film order by name;
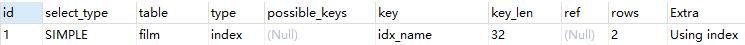
film.name建立了idx_name索引,此时查询时extra是Using index。
- select tables optimized away:使用某些聚合函数(比如:max、min)来访问存在索引的某个字段
explain select min(id) from film ;

还没关注我的公众号?
- 扫文末二维码关注公众号【小强的进阶之路】可领取如下:
- 学习资料: 1T视频教程:涵盖Javaweb前后端教学视频、机器学习/人工智能教学视频、Linux系统教程视频、雅思考试视频教程;
- 100多本书:包含C/C++、Java、Python三门编程语言的经典必看图书、LeetCode题解大全;
- 软件工具:几乎包括你在编程道路上的可能会用到的大部分软件;
- 项目源码:20个JavaWeb项目源码。

Mysql关键字Explain 性能优化神器的更多相关文章
- MySQL性能优化神器Explain
本文涉及:MySQL性能优化神器Explain的使用 简介 虽然使用Explain不能够马上调优我们的SQL,它也不能给予我们一些调整建议,但是它能够让我们了解MySQL 优化器是如何执行SQL 语句 ...
- MySql学习—— 查询性能优化 深入理解MySql如何执行查询
本篇深入了解查询优化和服务器的内部机制,了解MySql如何执行特定查询,从中也可以知道如何更改查询执行计划,当我们深入理解MySql如何真正地执行查询,明白高效和低效的真正含义,在实际应用中就能扬长避 ...
- MySQL之查询性能优化(二)
查询执行的基础 当希望MySQL能够以更高的性能运行查询时,最好的办法就是弄清楚MySQL是如何优化和执行查询的.MySQL执行一个查询的过程,根据图1-1,我们可以看到当向MySQL发送一个请求时, ...
- 2020重新出发,MySql基础,性能优化
@ 目录 MySQL性能优化 MySQL性能优化简述 使用 SHOW STATUS 命令 使用慢查询日志 MySQL 查询分析器 EXPLAIN DESCRIBE 索引对查询速度的影响 MySQL优化 ...
- MySQL 基础及性能优化工具
数据库,用户及权限 常用用户管理操作 # 创建本地用户 abc create user abc@localhost # 创建内网能够访问的用户 abc create user abc@'192.168 ...
- MySQL系列:性能优化
1. 优化简介 MySQL性能优化包括:查询优化.数据库结构优化.MySQL服务器优化等. 2. 查询优化 2.1 分析查询语句 MySQL提供EXPLAIN和DESCRIBE,用来分析查询语句. E ...
- MySQL设计规范与性能优化
引言 MySQL是目前使用最为广泛的关系型数据库之一,如果使用得当,可支撑企业级高并发.高可靠服务,使用不当甚至连并发量略高的个人网站都难以支撑: 就算使用了缓存,大量的数据库访问依旧在所难免,即使设 ...
- MySQL问题定位-性能优化之我见
前言 首先任何一个数据库不是独立存在的,也不是凭空想象决定出来的. 数据库的架构离不开应用的场景.所以,为了解决某些深入的问题,首先你得掌握数据库的原理与架构.原理掌握得越深入,越能帮助你定位复杂与隐 ...
- 【mysql】explain性能分析
1. explain的概念 使用EXPLAIN 关键字可以模拟优化器执行SQL 查询语句,从而知道MySQL 是如何处理你的SQL 语句的.分析你的查询语句或是表结构的性能瓶颈. 用法: Explai ...
随机推荐
- LocalDateTime的一些用法
包括获取当前时间,指定特定时间.进行时间的加减等 LocalDateTime localDateTime3 = LocalDateTime.now(); LocalDate.now(); LocalT ...
- selenium 中在 iframe 内的元素定位
有些时候 元素明明就在 但是通过什么方式定位都提示 定位不到元素 此时就要考虑元素是不是内嵌在iframe 中 对于内嵌在 ifra中的元素定位 首先定位到 iframe 元素 例如 iframe = ...
- sharding-jdbc 分布式数据库中间件
小编今天在做Sharding-jdbc时出现了一些问题,就上网百一百,发现网上的sharding-jdbc的参考是挺少的,唉还是要继续学习看文档. Sharding-jdbc介绍 Sharding-J ...
- webpack的一些坑
最近自己着手做一个小的Demo需要webpack,目前版本号是4.41.2,想使用的版本是3.6.0,因3x版本和4x版本很多地方不同,所以在安装过程中也是很多坎坷,下面是遇到的一些坑,和一些解决办法 ...
- linux常用命令-nginx常用命令
1.ctrl+alt+f2切换到命令界面 2.ifconfig查看IP 或者IP ADDR(en33 inter) 3.使用putty终端进行交互式操作 4.shell:提供用户输入的命令解释器 常用 ...
- React - 组件:函数组件
目录: . 组件名字首字母一定是大写的 . 返回一个jsx . jsx依赖React,所以组件内部需要引入React . 组件传参 a. 传递. <Component list={ arrDat ...
- HTML5 - websocket的应用 之 简易聊天室
需要知识点: 前端知识 jq操作dom nodejs socket.io 关于websocket api的知识点,见上篇章<HTML5-Websocket>. 聊天室思路/原理: A和B聊 ...
- IIS 安装 .net core 绑定为 https 使用SSL证书
前提条件: 自己服务器(Windows Server 2016)运行 dotnet .\Web****.dll 服务是可以使用http访问的 但由于实际情况必须使用https 思想历程,但未用: 1. ...
- Elasticsearch详解-续
Elasticsearch详解-续 Chandler_珏瑜 关注 7.6 2019.05.22 10:46* 字数 8366 阅读 675评论 4喜欢 25 5.3 性能调优 Elasticse ...
- Linux 就该这么学 CH09 使用ssh服务管理远程主机
1 .配置网络服务 1)配置网络参数 五种配置网络的方法:命令行,编译网络配置文件,nmtui(旧版ui界面),nm-connection-edit(新版ui),VM虚拟机右上角图标等. 这里配 ...