重磅开源 KSQL:用于 Apache Kafka 的流数据 SQL 引擎 2017.8.29
Kafka 的作者 Neha Narkhede 在 Confluent 上发表了一篇博文,介绍了Kafka 新引入的KSQL 引擎——一个基于流的SQL。推出KSQL 是为了降低流式处理的门槛,为处理Kafka 数据提供简单而完整的可交互式SQL 接口。KSQL 目前可以支持多种流式操作,包括聚合(aggregate)、连接(join)、时间窗口(window)、会话(session),等等。
与传统 SQL 的主要区别
KSQL 与关系型数据库中的 SQL 还是有很大不同的。传统的 SQL 都是即时的一次性操作,不管是查询还是更新都是在当前的数据集上进行。而 KSQL 则不同,KSQL 的查询和更新是持续进行的,而且数据集可以源源不断地增加。KSQL 所做的其实是转换操作,也就是流式处理。
KSQL 的适用场景
1. 实时监控
一方面,可以通过 KSQL 自定义业务层面的度量指标,这些指标可以实时获得。底层的度量指标无法告诉我们应用程序的实际行为,所以基于应用程序生成的原始事件来自定义度量指标可以更好地了解应用程序的运行状况。另一方面,可以通过 KSQL 为应用程序定义某种标准,用于检查应用程序在生产环境中的行为是否达到预期。
2. 安全检测
KSQL 把事件流转换成包含数值的时间序列数据,然后通过可视化工具把这些数据展示在 UI 上,这样就可以检测到很多威胁安全的行为,比如欺诈、入侵,等等。KSQL 为此提供了一种实时、简单而完备的方案。
3. 在线数据集成
大部分的数据处理都会经历 ETL(Extract——Transform——Load)这样的过程,而这样的系统通常都是通过定时的批次作业来完成数据处理的,但批次作业所带来的延时在很多时候是无法被接受的。而通过使用 KSQL 和 Kafka 连接器,可以将批次数据集成转变成在线数据集成。比如,通过流与表的连接,可以用存储在数据表里的元数据来填充事件流里的数据,或者在将数据传输到其他系统之前过滤掉数据里的敏感信息。
4. 应用开发
对于复杂的应用来说,使用 Kafka 的原生 Streams API 或许会更合适。不过,对于简单的应用来说,或者对于不喜欢 Java 编程的人来说,KSQL 会是更好的选择。
KSQL 的核心抽象
KSQL 是基于 Kafka 的Streams API进行构建的,所以它的两个核心概念是流(Stream)和表(Table)。流是没有边界的结构化数据,数据可以被源源不断地添加到流当中,但流中已有的数据是不会发生变化的,即不会被修改也不会被删除。表就是流的视图,或者说它代表了可变数据的集合。它与传统的数据库表类似,只不过具备了一些流式语义,比如时间窗口,而且表中的数据是可变的。KSQL 将流和表集成在一起,允许将代表当前状态的表与代表当前发生事件的流连接在一起。
KSQL 架构
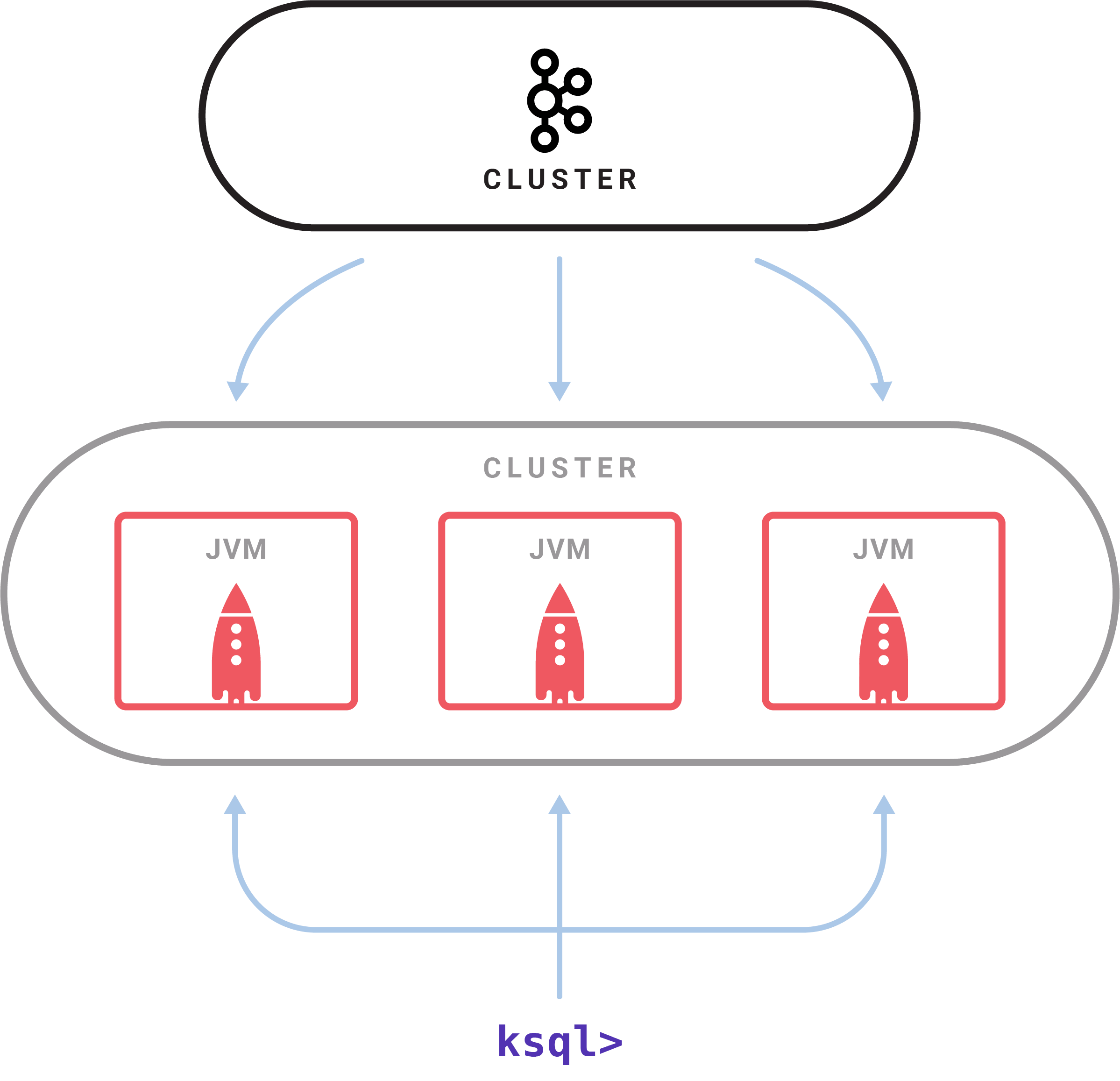
KSQL 是一个独立运行的服务器,多个 KSQL 服务器可以组成集群,可以动态地添加服务器实例。集群具有容错机制,如果一个服务器失效,其他服务器就会接管它的工作。KSQL 命令行客户端通过 REST API 向集群发起查询操作,可以查看流和表的信息、查询数据以及查看查询状态。因为是基于 Streams API 构建的,所以 KSQL 也沿袭了 Streams API 的弹性、状态管理和容错能力,同时也具备了仅一次(exactly once)语义。KSQL 服务器内嵌了这些特性,并增加了一个分布式SQL 引擎、用于提升查询性能的自动字节码生成机制,以及用于执行查询和管理的REST API。
Kafka+KSQL 要颠覆传统数据库
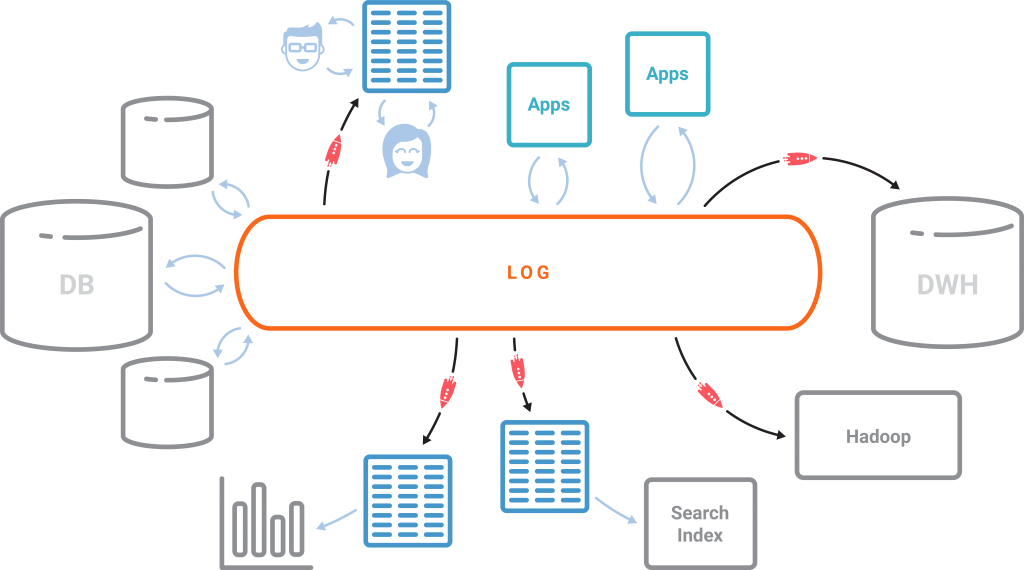
传统关系型数据库以表为核心,日志只不过是实现手段。而在以事件为中心的世界里,情况却恰好相反。日志成为了核心,而表几乎是以日志为基础,新的事件不断被添加到日志里,表的状态也因此发生变化。将 Kafka 作为中心日志,配置 KSQL 这个引擎,我们就可以创建出我们想要的物化视图,而且视图也会持续不断地得到更新。
KSQL 的未来
KSQL 目前还处于开发者预览阶段,作者还在收集社区的反馈。未来计划增加更多的特性,包括支持更丰富的SQL 语法,让KSQL 成为生产就绪的系统。
这里有 KSQL 的快速入门指南和一个演示程序。可以在Slack 的#KSQL 频道上向作者提供反馈信息,或者如果发现Bug,可以在GitHub上提出来。
 KSQL - Streaming SQL for Apache Kafka
KSQL - Streaming SQL for Apache Kafka
KSQL is now GA and officially supported by Confluent Inc. Get started with KSQL today.
KSQL is the streaming SQL engine for Apache Kafka. It provides a simple and completely interactive SQL interface for stream processing on Kafka; no need to write code in a programming language such as Java or Python. KSQL is distributed, scalable, reliable, and real-time. It supports a wide range of powerful stream processing operations including aggregations, joins, windowing, sessionization, and much more. You can find more KSQL tutorials and resources here if you are interested.
Click here to watch a screencast of the KSQL demo on YouTube. 
Getting Started and Download
Stable Releases
Stable releases are published every four months and are officially supported by Confluent.
- Download latest stable KSQL, which is included in Confluent Platform.
- Follow the Quick Start.
- Read the KSQL Documentation, notably the KSQL Tutorials and Examples, which include Docker-based variants.
Preview Releases
In addition to supported stable KSQL releases, we also provide preview releases. We encourage you to try them in development and testing environments and to take advantage of Confluent Community resources to get help and share feedback.
Documentation
See KSQL documentation for the latest stable release.
Use Cases and Examples
Streaming ETL
Apache Kafka is a popular choice for powering data pipelines. KSQL makes it simple to transform data within the pipeline, readying messages to cleanly land in another system.
CREATE STREAM vip_actions AS
SELECT userid, page, action
FROM clickstream c
LEFT JOIN users u ON c.userid = u.user_id
WHERE u.level = 'Platinum';
Anomaly Detection
KSQL is a good fit for identifying patterns or anomalies on real-time data. By processing the stream as data arrives you can identify and properly surface out of the ordinary events with millisecond latency.
CREATE TABLE possible_fraud AS
SELECT card_number, count(*)
FROM authorization_attempts
WINDOW TUMBLING (SIZE 5 SECONDS)
GROUP BY card_number
HAVING count(*) > 3;
Monitoring
Kafka's ability to provide scalable ordered messages with stream processing make it a common solution for log data monitoring and alerting. KSQL lends a familiar syntax for tracking, understanding, and managing alerts.
CREATE TABLE error_counts AS
SELECT error_code, count(*)
FROM monitoring_stream
WINDOW TUMBLING (SIZE 1 MINUTE)
WHERE type = 'ERROR'
GROUP BY error_code;
Join the Community
You can get help, learn how to contribute to KSQL, and find the latest news by connecting with the Confluent community.
- Ask a question in the #ksql channel in our public Confluent Community Slack. Account registration is free and self-service.
- Join the Confluent Google group.
Contributing
Contributions to the code, examples, documentation, etc. are very much appreciated.
- Report issues and bugs directly in this GitHub project.
- Learn how to work with the KSQL source code, including building and testing KSQL as well as contributing code changes to KSQL by reading our Development and Contribution guidelines.
- One good way to get started is by tackling a newbie issue.
License
The project is licensed under the Confluent Community License.
Apache, Apache Kafka, Kafka, and associated open source project names are trademarks of the Apache Software Foundation.
重磅开源 KSQL:用于 Apache Kafka 的流数据 SQL 引擎 2017.8.29的更多相关文章
- 用Apache Kafka构建流数据平台的建议
在<流数据平台构建实战指南>第一部分中,Confluent联合创始人Jay Kreps介绍了如何构建一个公司范围的实时流数据中心.InfoQ前期对此进行过报道.本文是根据第二部分整理而成. ...
- 用Apache Kafka构建流数据平台
近来,有许多关于“流处理”和“事件数据”的讨论,它们往往都与像Kafka.Storm或Samza这样的技术相关.但并不是每个人都知道如何将这种技术引入他们自己的技术栈.于是,Confluent联合创始 ...
- Apache Kafka分布式流处理平台及大厂面试宝典v3.0.0
概述 **本人博客网站 **IT小神 www.itxiaoshen.com 定义 Apache Kafka官网地址 http://kafka.apache.org/ 最新版本为 3.0.0 Apach ...
- kafka实时流数据架构
初识kafka https://www.cnblogs.com/wenBlog/p/9550039.html 简介 Kafka经常用于实时流数据架构,用于提供实时分析.本篇将会简单介绍kafka以及它 ...
- Flink+Kafka 接收流数据并打印到控制台
试验环境 Windows:IDEA Linux:Kafka,Zookeeper POM和Demo <?xml version="1.0" encoding="UTF ...
- Streaming SQL for Apache Kafka
KSQL是基于Kafka的Streams API进行构建的流式SQL引擎,KSQL降低了进入流处理的门槛,提供了一个简单的.完全交互式的SQL接口,用于处理Kafka的数据. KSQL是一套基于Apa ...
- Apache Kafka开发入门指南(2)
Apache Kafka目标是统一离线和在线处理,与Flume和Scribe相比较,Kafka在处理活动流数据方面更具优势.但是从架构的视野来看,Kafka与传统的消息系统(例如ActiveMQ或Ra ...
- 使用命令进行Apache Kafka操作
1.目标 我们可以在Kafka集群上执行几个Apache Kafka Operations .因此,在本文中,我们将详细讨论所有Apache Kafka操作.它还包括有助于实现这些Kafka操作的命令 ...
- Apache Kafka Consumer 消费者集
1.目标 在我们的上一篇文章中,我们讨论了Kafka Producer.今天,我们将讨论Kafka Consumer.首先,我们将看到什么是Kafka Consumer和Kafka Consumer的 ...
随机推荐
- Angular----样式
本篇根据Angular官网提供的例子,对Angular涉及到的样式绑定进行说明. 一.提供的CSS样式 .red{ color:red; } .green{ color: green; } .yell ...
- rsync免密码远程复制文件
目标: 从云服务器(112.77.69.212)把mongodb中的文件同步到本地. 步骤一:在云服务器上创建用户 $ adduser monbak $ passwd monbak 步骤二:设置免密登 ...
- java 使用网建SMS发送短信验证码
首先, 注册并登录网建用户, 新注册用户将获得5条的测试短信 网建短信通地址: http://sms.webchinese.cn/default.shtml 注册账号在此就不多做赘述了, 直接上代码 ...
- Livy 安装教程
Livy 安装教程 本文原始地址:https://sitoi.cn/posts/16143.html 安装环境 Fedora 29 Spark PySpark 安装步骤 下载 Livy 安装包 解压 ...
- 等了半年的AMD锐龙3000系列台式机处理器今天终于上市开卖了!
第三代AMD锐龙台式机处理器参数:
- java String、String.concat和StringBuilder性能对比
看到网上有人已经做过对比,并且贴出了代码,然后我运行了之后发现跟我分析的结论差距很大.发现他的代码有个问题,UUID.randomUUID() 首次调用耗时会很高,这个耗时被计算给了String,这对 ...
- 201871010132——张潇潇《面向对象程序设计JAVA》第二周学习总结
项目 内容 这个作业属于哪个课程 https://www.cnblogs.com/nwnu-daizh/ 这个作业的要求在哪里 https://www.cnblogs.com/nwnu-daizh/p ...
- JDK1.8 LocalDate 使用方式;LocalDate 封装Util,LocalDate工具类(四)
未完待续 ........ 前言: 加班了好几天,终于结束上一个坑的项目了,项目交接人员全部离职,代码一行注释没有,无人问津的情况下,完成了项目,所以好的规范真的很重要. 继续日期改写 一 ...
- 浏览器bug html 底部
- 使用log4Net输出调试信息
在上一篇搭建服务器端的项目基础上,使用log4Net进行调试信息输出 http://www.cnblogs.com/fzxiaoyi/p/8439769.html 1.先分析下Photo 自带的服务器 ...