Storm大数据实时计算
大数据也是构建各类系统的时候一种全新的思维,以及架构理念,比如Storm,Hive,Spark,ZooKeeper,HBase,Elasticsearch,等等
storm,在做热数据这块,如果要做复杂的热数据的统计和分析,亿流量,高并发的场景下,最合适的技术就是storm,没有其他
举例说明:
Storm:实时缓存热点数据统计->缓存预热->缓存热点数据自动降级
Hive:Hadoop生态栈里面,做数据仓库的一个系统,高并发访问下,海量请求日志的批量统计分析,日报周报月报,接口调用情况,业务使用情况,等等
我所知,在一些大公司里面,是有些人是将海量的请求日志打到hive里面,做离线的分析,然后反过来去优化自己的系统
Spark:离线批量数据处理,比如从DB中一次性批量处理几亿数据,清洗和处理后写入Redis中供后续的系统使用,大型互联网公司的用户相关数据
ZooKeeper:分布式系统的协调,分布式锁,分布式选举->高可用HA架构,轻量级元数据存储
HBase:海量数据的在线存储和简单查询,替代MySQL分库分表,提供更好的伸缩性
java底层,对应的是海量数据,然后要做一些简单的存储和查询,同时数据增多的时候要快速扩容
mysql分库分表就不太合适了,mysql分库分表扩容,还是比较麻烦的
Elasticsearch:海量数据的复杂检索以及搜索引擎的构建,支撑有大量数据的各种企业信息化系统的搜索引擎,电商/新闻等网站的搜索引擎,等等
mysql的like "%xxxx%",更加合适一些,性能更加好
hystrix,分布式系统的高可用性的限流,熔断,降级,等等,一些措施,缓存雪崩的方案,限流的技术
一、Storm到底是什么?
1、mysql,hadoop与storm
mysql:事务性系统,面临海量数据的尴尬
hadoop:离线批处理
storm:实时计算
3、storm的特点是什么?
(1)支撑各种实时类的项目场景:实时处理消息以及更新数据库,基于最基础的实时计算语义和API(实时数据处理领域);对实时的数据流持续的进行查询或计算,同时将最新的计算结果持续的推送给客户端展示,同样基于最基础的实时计算语义和API(实时数据分析领域);对耗时的查询进行并行化,基于DRPC,即分布式RPC调用,单表30天数据,并行化,每个进程查询一天数据,最后组装结果
storm做各种实时类的项目都ok
(2)高度的可伸缩性:如果要扩容,直接加机器,调整storm计算作业的并行度就可以了,storm会自动部署更多的进程和线程到其他的机器上去,无缝快速扩容
扩容起来,超方便
(3)数据不丢失的保证:storm的消息可靠机制开启后,可以保证一条数据都不丢
数据不丢失,也不重复计算
(4)超强的健壮性:从历史经验来看,storm比hadoop、spark等大数据类系统,健壮的多的多,因为元数据全部放zookeeper,不在内存中,随便挂都不要紧
特别的健壮,稳定性和可用性很高
(5)使用的便捷性:核心语义非常的简单,开发起来效率很高
用起来很简单,开发API还是很简单的
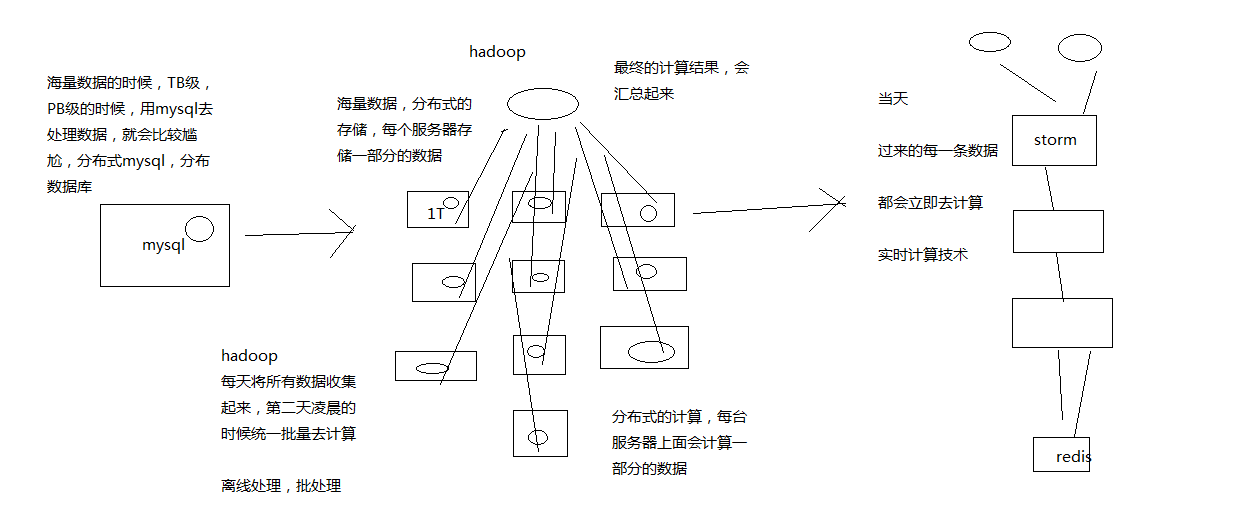
二、Storm的集群架构以及核心概念
1、Storm的集群架构
Nimbus,Supervisor,ZooKeeper,Worker,Executor,Task
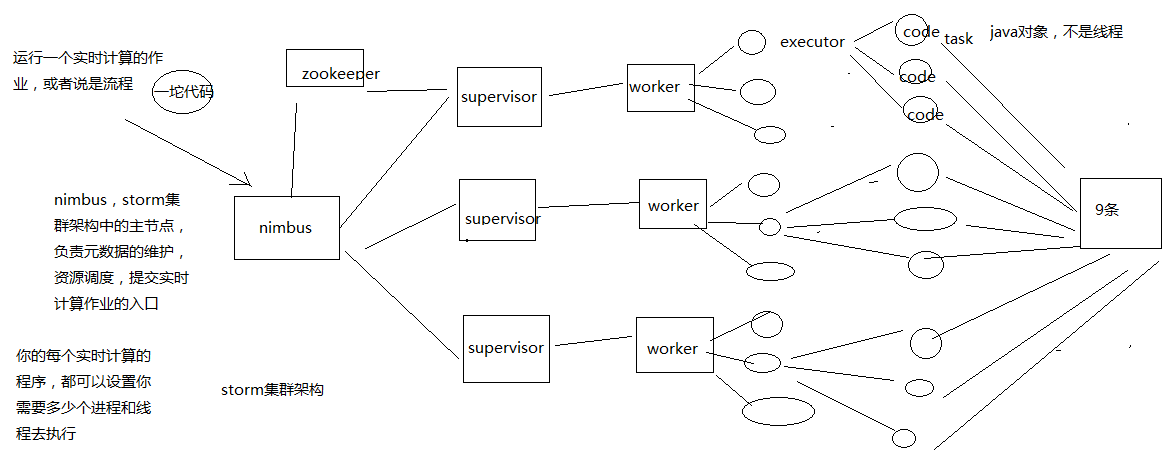
2、Storm的核心概念
Topology,Spout,Bolt,Tuple,Stream
拓扑:务虚的一个概念
Spout:数据源的一个代码组件,就是我们可以实现一个spout接口,写一个java类,在这个spout代码中,我们可以自己尝试去数据源获取数据,比如说从kafka中消费数据
bolt:一个业务处理的代码组件,spout会将数据传送给bolt,各种bolt还可以串联成一个计算链条,java类实现了一个bolt接口
一堆spout+bolt,就会组成一个topology,就是一个拓扑,实时计算作业,spout+bolt,一个拓扑涵盖数据源获取/生产+数据处理的所有的代码逻辑,topology
tuple:就是一条数据,每条数据都会被封装在tuple中,在多个spout和bolt之间传递
stream:就是一个流,务虚的一个概念,抽象的概念,源源不断过来的tuple,就组成了一条数据流

并行度:Worker->Executor->Task
流分组:Task与Task之间的数据流向关系
Shuffle Grouping:随机发射,负载均衡
Fields Grouping:根据某一个,或者某些个,fields,进行分组,那一个或者多个fields如果值完全相同的话,
那么这些tuple,就会发送给下游bolt的其中固定的一个task
你发射的每条数据是一个tuple,每个tuple中有多个field作为字段
比如tuple,3个字段,name,age,salary

All Grouping
Global Grouping
None Grouping
Direct Grouping
Local or Shuffle Grouping
实现一个简单的列子:
import java.util.HashMap;
import java.util.Map;
import java.util.Random;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory; public class WordCountTopology { /**
* spout
*
* spout,继承一个基类,实现接口,这个里面主要是负责从数据源获取数据
*/
public static class RandomSentenceSpout extends BaseRichSpout { private static final long serialVersionUID = 3699352201538354417L; private static final Logger LOGGER = LoggerFactory.getLogger(RandomSentenceSpout.class); private SpoutOutputCollector collector;
private Random random; /**
* open方法
*
* open方法,是对spout进行初始化的
*
* 比如说,创建一个线程池,或者创建一个数据库连接池,或者构造一个httpclient
*
*/
@SuppressWarnings("rawtypes")
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
// 在open方法初始化的时候,会传入进来一个东西,叫做SpoutOutputCollector
// 这个SpoutOutputCollector就是用来发射数据出去的
this.collector = collector;
// 构造一个随机数生产对象
this.random = new Random();
} /**
* nextTuple方法
* 这个spout类,之前说过,最终会运行在task中,某个worker进程的某个executor线程内部的某个task中
* 那个task会负责去不断的无限循环调用nextTuple()方法
* 只要的话呢,无限循环调用,可以不断发射最新的数据出去,形成一个数据流
*/
public void nextTuple() {
Utils.sleep(100);
String[] sentences = new String[]{"the cow jumped over the moon", "an apple a day keeps the doctor away",
"four score and seven years ago", "snow white and the seven dwarfs", "i am at two with nature"};
String sentence = sentences[random.nextInt(sentences.length)];
LOGGER.info("【发射句子】sentence=" + sentence);
// 这个values,你可以认为就是构建一个tuple
// tuple是最小的数据单位,无限个tuple组成的流就是一个stream
collector.emit(new Values(sentence));
} /**
* declareOutputFielfs这个方法
* 很重要,这个方法是定义一个你发射出去的每个tuple中的每个field的名称是什么
*/
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("sentence"));
} } /**
* 写一个bolt,直接继承一个BaseRichBolt基类
* 实现里面的所有的方法即可,每个bolt代码,同样是发送到worker某个executor的task里面去运行
*/
public static class SplitSentence extends BaseRichBolt { private static final long serialVersionUID = 6604009953652729483L; private OutputCollector collector; /**
* 对于bolt来说,第一个方法,就是prepare方法
*
* OutputCollector,这个也是Bolt的这个tuple的发射器
*
*/
@SuppressWarnings("rawtypes")
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
} /**
* execute方法
*
* 就是说,每次接收到一条数据后,就会交给这个executor方法来执行
*
*/
public void execute(Tuple tuple) {
String sentence = tuple.getStringByField("sentence");
String[] words = sentence.split(" ");
for(String word : words) {
collector.emit(new Values(word));
}
} /**
* 定义发射出去的tuple,每个field的名称
*/
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
} } public static class WordCount extends BaseRichBolt { private static final long serialVersionUID = 7208077706057284643L; private static final Logger LOGGER = LoggerFactory.getLogger(WordCount.class); private OutputCollector collector;
private Map<String, Long> wordCounts = new HashMap<String, Long>(); @SuppressWarnings("rawtypes")
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
} public void execute(Tuple tuple) {
String word = tuple.getStringByField("word"); Long count = wordCounts.get(word);
if(count == null) {
count = 0L;
}
count++; wordCounts.put(word, count); LOGGER.info("【单词计数】" + word + "出现的次数是" + count); collector.emit(new Values(word, count));
} public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
} } public static void main(String[] args) {
// 在main方法中,会去将spout和bolts组合起来,构建成一个拓扑
TopologyBuilder builder = new TopologyBuilder(); // 这里的第一个参数的意思,就是给这个spout设置一个名字
// 第二个参数的意思,就是创建一个spout的对象
// 第三个参数的意思,就是设置spout的executor有几个
builder.setSpout("RandomSentence", new RandomSentenceSpout(), 2);
builder.setBolt("SplitSentence", new SplitSentence(), 5)
.setNumTasks(10)
.shuffleGrouping("RandomSentence");
// 这个很重要,就是说,相同的单词,从SplitSentence发射出来时,一定会进入到下游的指定的同一个task中
// 只有这样子,才能准确的统计出每个单词的数量
// 比如你有个单词,hello,下游task1接收到3个hello,task2接收到2个hello
// 5个hello,全都进入一个task
builder.setBolt("WordCount", new WordCount(), 10)
.setNumTasks(20)
.fieldsGrouping("SplitSentence", new Fields("word")); Config config = new Config(); // 说明是在命令行执行,打算提交到storm集群上去
if(args != null && args.length > 0) {
config.setNumWorkers(3);
try {
StormSubmitter.submitTopology(args[0], config, builder.createTopology());
} catch (Exception e) {
e.printStackTrace();
}
} else {
// 说明是在eclipse里面本地运行
config.setMaxTaskParallelism(20); LocalCluster cluster = new LocalCluster();
cluster.submitTopology("WordCountTopology", config, builder.createTopology()); Utils.sleep(60000); cluster.shutdown();
}
}
}
部署一个storm集群
(1)安装Java 7和Pythong 2.6.6
(2)下载storm安装包,解压缩,重命名,配置环境变量
(3)修改storm配置文件
mkdir /var/storm
conf/storm.yaml
storm.zookeeper.servers:
- "111.222.333.444"
- "555.666.777.888" storm.local.dir: "/mnt/storm" nimbus.seeds: ["111.222.333.44"]
slots.ports,指定每个机器上可以启动多少个worker,一个端口号代表一个worker
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
(4)启动storm集群和ui界面
一个节点,storm nimbus >/dev/null 2>&1 &
三个节点,storm supervisor >/dev/null 2>&1 &
一个节点,storm ui >/dev/null 2>&1 &
(5)访问一下ui界面,8080端口
提交程序到storm集群来运行
将eclipse中的工程,进行打包
storm jar path/to/allmycode.jar org.me.MyTopology arg1 arg2 arg3
(2)在storm ui上观察storm作业的运行
(3)kill掉某个storm作业
storm kill topology-name
冷启动的问题:
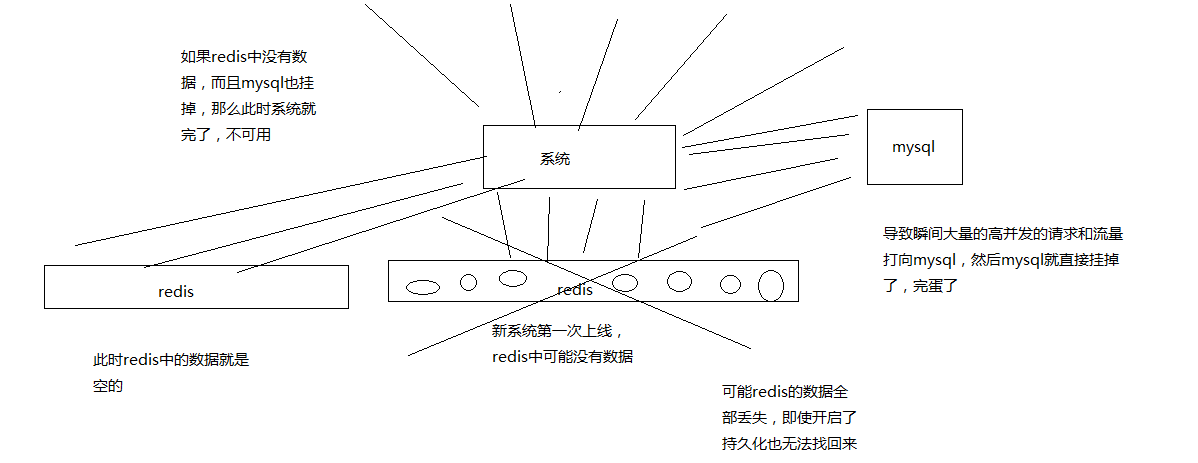
缓存冷启动,redis启动后,一点数据都没有,直接就对外提供服务了,mysql就裸奔
(1)提前给redis中灌入部分数据,再提供服务
(2)肯定不可能将所有数据都写入redis,因为数据量太大了,第一耗费的时间太长了,第二根本redis容纳不下所有的数据
(3)需要根据当天的具体访问情况,实时统计出访问频率较高的热数据
(4)然后将访问频率较高的热数据写入redis中,肯定是热数据也比较多,我们也得多个服务并行读取数据去写,并行的分布式的缓存预热
(5)然后将灌入了热数据的redis对外提供服务,这样就不至于冷启动,直接让数据库裸奔了
1、nginx+lua将访问流量上报到kafka中
要统计出来当前最新的实时的热数据是哪些,我们就得将商品详情页访问的请求对应的流量,日志,实时上报到kafka中
2、storm从kafka中消费数据,实时统计出每个商品的访问次数,访问次数基于LRU内存数据结构的存储方案
优先用内存中的一个LRUMap去存放,性能高,而且没有外部依赖
否则的话,依赖redis,我们就是要防止redis挂掉数据丢失的情况,就不合适了; 用mysql,扛不住高并发读写; 用hbase,hadoop生态系统,维护麻烦,太重了
只要统计出最近一段时间访问最频繁的商品,然后对它们进行访问计数,同时维护出一个前N个访问最多的商品list即可
热数据,可以拿到最近一段,比如最近1个小时,最近5分钟,1万个商品请求,统计出最近这段时间内每个商品的访问次数,排序,做出一个排名前N的list
计算好每个task大致要存放的商品访问次数的数量,计算出大小
然后构建一个LRUMap,apache commons collections有开源的实现,设定好map的最大大小,就会自动根据LRU算法去剔除多余的数据,保证内存使用限制
即使有部分数据被干掉了,然后下次来重新开始计数,也没关系,因为如果它被LRU算法干掉,那么它就不是热数据,说明最近一段时间都很少访问了
3、每个storm task启动的时候,基于zk分布式锁,将自己的id写入zk同一个节点中
4、每个storm task负责完成自己这里的热数据的统计,每隔一段时间,就遍历一下这个map,然后维护一个前3个商品的list,更新这个list
5、写一个后台线程,每隔一段时间,比如1分钟,都将排名前3的热数据list,同步到zk中去,存储到这个storm task对应的一个zn的ode中去
6、需要一个服务,比如说,代码可以跟缓存数据生产服务放一起,但是也可以放单独的服务
每次服务启动的时候,就会去拿到一个storm task的列表,然后根据taskid,一个一个的去尝试获取taskid对应的znode的zk分布式锁
如果能获取到分布式锁的话,那么就将那个storm task对应的热数据的list取出来
然后将数据从mysql中查询出来,写入缓存中,进行缓存的预热,多个服务实例,分布式的并行的去做,基于zk分布式锁做了协调了,分布式并行缓存的预热
Storm大数据实时计算的更多相关文章
- Storm 实战:构建大数据实时计算
Storm 实战:构建大数据实时计算(阿里巴巴集团技术丛书,大数据丛书.大型互联网公司大数据实时处理干货分享!来自淘宝一线技术团队的丰富实践,快速掌握Storm技术精髓!) 阿里巴巴集团数据平台事业部 ...
- 大数据实时计算工程师/Hadoop工程师/数据分析师职业路线图
http://edu.51cto.com/roadmap/view/id-29.html http://my.oschina.net/infiniteSpace/blog/308401 大数据实时计算 ...
- 一文让你彻底了解大数据实时计算引擎 Flink
前言 在上一篇文章 你公司到底需不需要引入实时计算引擎? 中我讲解了日常中常见的实时需求,然后分析了这些需求的实现方式,接着对比了实时计算和离线计算.随着这些年大数据的飞速发展,也出现了不少计算的框架 ...
- 阿里云DataWorks正式推出Stream Studio:为用户提供大数据实时计算的数据中台
5月15日 阿里云DataWorks正式推出Stream Studio,正式为用户提供大数据的实时计算能力,同时标志着DataWorks成为离线.实时双计算领域的数据中台. 据介绍,Stream St ...
- 《storm实战-构建大数据实时计算读书笔记》
自己的思考: 1.接收任务到任务的分发和协调 nimbus.supervisor.zookeeper 2.高容错性 各个组件都是无状态的,状态 ...
- 大数据笔记(二十二)——大数据实时计算框架Storm
一. 1.对比:离线计算和实时计算 离线计算:MapReduce,批量处理(Sqoop-->HDFS--> MR ---> HDFS) 实时计算:Storm和Spark Sparki ...
- 《大数据实时计算引擎 Flink 实战与性能优化》新专栏
基于 Flink 1.9 讲解的专栏,涉及入门.概念.原理.实战.性能调优.系统案例的讲解. 专栏介绍 扫码下面专栏二维码可以订阅该专栏 首发地址:http://www.54tianzhisheng. ...
- Impala简介PB级大数据实时查询分析引擎
1.Impala简介 • Cloudera公司推出,提供对HDFS.Hbase数据的高性能.低延迟的交互式SQL查询功能. • 基于Hive使用内存计算,兼顾数据仓库.具有实时.批处理.多并发等优点 ...
- 基于TI 多核DSP 的大数据智能计算处理解决方案
北京太速科技有限公司 大数据智能计算,是未来的一个发展趋势,大数据计算系统主要完成数据的存储和管理:数据的检索与智能计算. 特别是在智能城市领域,由于人口聚集给城市带来了交通.医疗.建筑等各方面的压力 ...
随机推荐
- 第09组 Alpha冲刺(6/6)
队名:观光队 组长博客 作业博客 组员实践情况 王耀鑫 过去两天完成了哪些任务 文字/口头描述 博客撰写,文档,答辩材料整理. 展示GitHub当日代码/文档签入记录 接下来的计划 QA. 还剩下哪些 ...
- 聊聊Mysql索引和redis跳表 ---redis的有序集合zset数据结构底层采用了跳表原理 时间复杂度O(logn)(阿里)
redis使用跳表不用B+数的原因是:redis是内存数据库,而B+树纯粹是为了mysql这种IO数据库准备的.B+树的每个节点的数量都是一个mysql分区页的大小(阿里面试) 还有个几个姊妹篇:介绍 ...
- 2018-2019-2 20175217 实验四《Android开发基础》实验报告
一.实验报告封面 课程:Java程序设计 班级:1752班 姓名:吴一凡 学号:20175217 指导教师:娄嘉鹏 实验日期:2019年5月16日 实验时间:--- 实验序号:实验四 实验名称:And ...
- 【Gamma】Scrum Meeting 3
目录 写在前面 进度情况 任务进度表 Gamma阶段燃尽图 照片 写在前面 例会时间:5.27 22:30-23:30 例会地点:微信群语音通话 代码进度记录github在这里 临近期末,团队成员课程 ...
- yum 安装指定版本Docker
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/weixin_39553910/artic ...
- Kibana启动后外网访问不了
问题 Kibana启动后,使用外网访问 http://ip地址:5601 访问不了日志中最后显示 "statusCode":302 ,在控制台 curl http://localh ...
- 浅析String.intern()方法
1.String类型“==”比较样例代码如下:package com.luna.test;public class StringTest { public static void main(Strin ...
- CatBoost使用GPU实现决策树的快速梯度提升CatBoost Enables Fast Gradient Boosting on Decision Trees Using GPUs
python机器学习-乳腺癌细胞挖掘(博主亲自录制视频)https://study.163.com/course/introduction.htm?courseId=1005269003&ut ...
- Xamarin.Forms Shell基础教程(1)
Xamarin.Forms Shell基础教程(1) 什么是Xamarin.Forms Shell Shell是Visual Studio为Xamarin Forms提供的解决方案模版.本质上,She ...
- Error-ASP.NET:无效的 JSON 基元: object。
ylbtech-Error-ASP.NET:无效的 JSON 基元: object. 1.返回顶部 1. “/”应用程序中的服务器错误. 无效的 JSON 基元: object. 说明: 执行当前 ...