Kudu的架构
不多说,直接上干货!
Kudu的架构
1、kudu的 基本框架
Kudu 是用于存储结构化( structured )的表( Table )。表有预定义的带类型的列( Columns ),每张表有一个主键( primary key )。主键带有唯一性( uniqueness )限制,可作为索引用来支持快速的 random access 。
类似于 BigTable , Kudu 的表是由很多数据子集构成的,表(Table)被水平拆分成多个 Tablets(片)。Kudu 用以每个 tablet 为一个单元来实现数据的 durability (持久化)。 Tablet(片) 有多个副本,同时在多个节点上进行持久化。
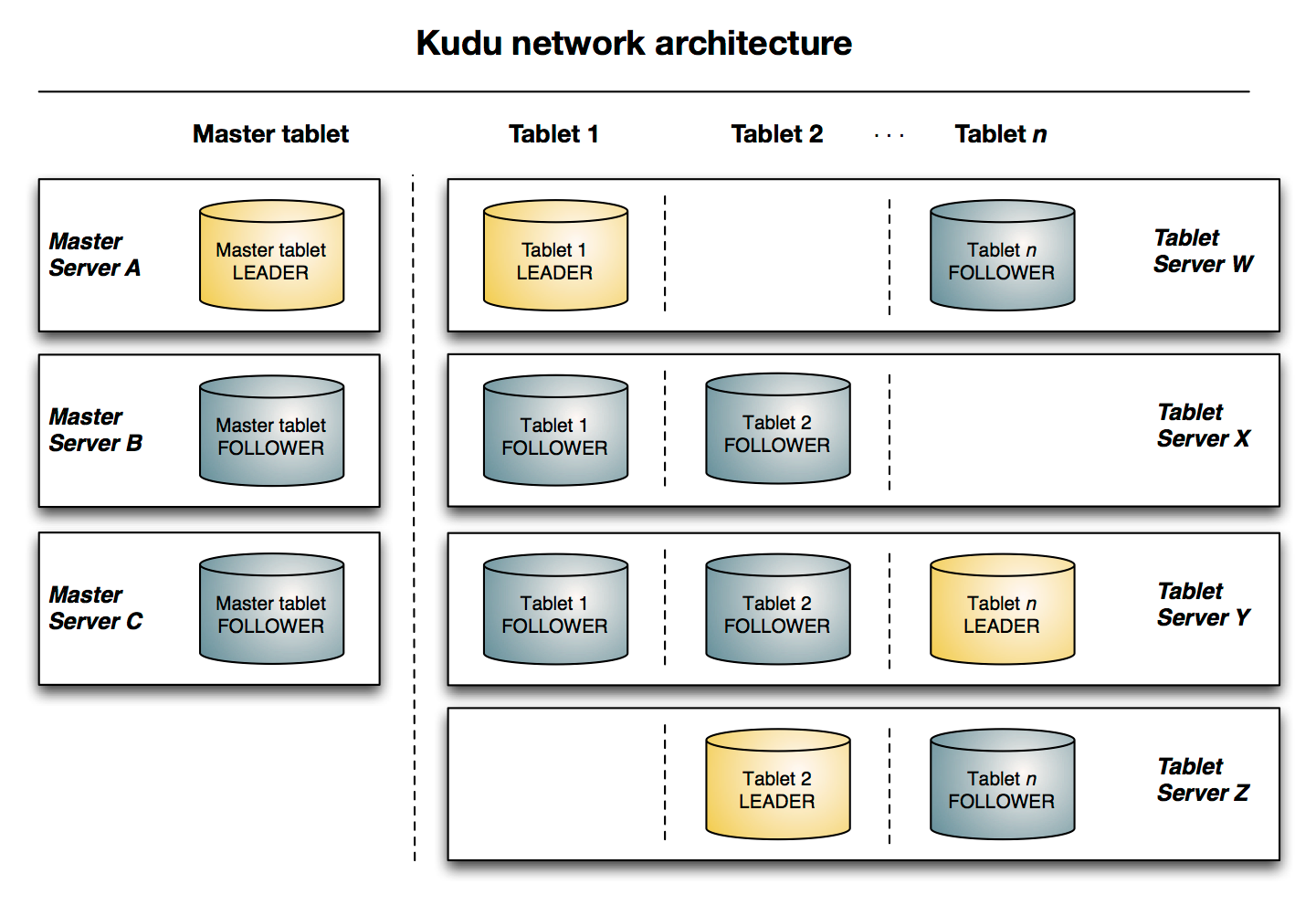
Kudu 有两种类型的组件, Master Server 和 Tablet Server 。
(1) Master Server 负责管理元数据。这些元数据包括 talbet 的基本信息,位置信息。 Master 还作为负载均衡服务器,监听 Tablet Server 的健康状态。对于副本数过低的 Tablet , Master 会在起 replication 任务来提高其副本数。 Master 的所有信息都在内存中 cache ,因此速度非常快。每次查询都在百毫秒级别。 Kudu 支持多个 Master ,不过只有一个 active Master ,其余只是作为灾备,不提供服务。
(2) Tablet Server 上存了 10~100 个 Tablets ,每个 Tablet 有 3 (或 5 )个副本存放在不同的 Tablet Server 上,每个 Tablet 同时只有一个 leader 副本,这个副本对用户提供修改操作,然后将修改结果同步给 follower 。 Follower 只提供读服务,不提供修改服务。副本之间使用 raft 协议来实现 High Availability ,当 leader 所在的节点发生故障时, followers 会重新选举 leader 。根据官方的数据,其 MTTR 约为 5 秒,对 client 端几乎没有影响。 Raft 协议的另一个作用是实现 Consistency 。 Client 对 leader 的修改操作,需要同步到 N/2+1 个节点上,该操作才算成功。
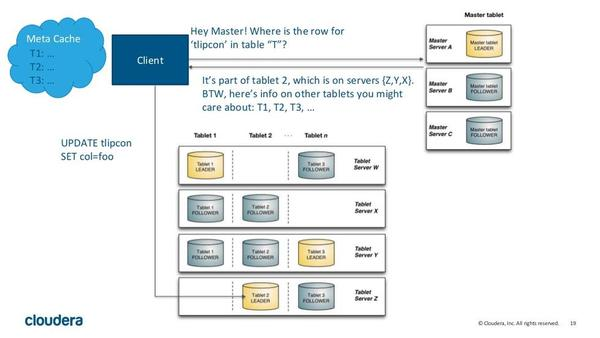
Kudu 采用了类似 log-structured 存储系统的方式,增删改操作都放在内存中的 buffer ,然后才 merge 到持久化的列式存储中。 Kudu 还是用了 WALs 来对内存中的 buffer 进行灾备。
2. 列式存储
持久化的列式存储存储,与 HBase 完全不同,而是使用了类似 Parquet 的方式,同一个列在磁盘上是作为一个连续的块进行存放的。例如,图中左边是 twitter 保存推文的一张表,而图中的右边表示了表在磁盘中的的存储方式,也就是将同一个列放在一起存放。这样做的第一个好处是,对于一些聚合和 join 语句,我们可以尽可能地减少磁盘的访问。
例如,我们要用户名为 newsycbot的推文数量,使用查询语句:
SELECT COUNT(*) FROM tweets WHERE user_name = ‘newsycbot’;
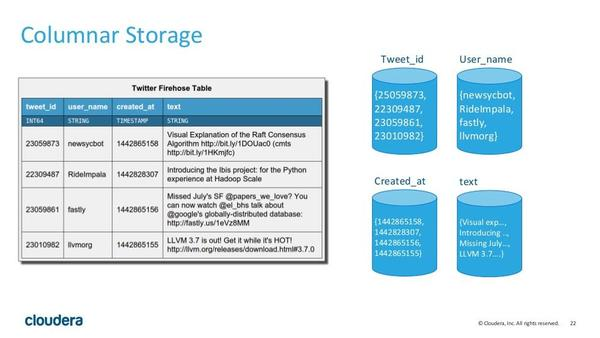
我们只需要查询 User_name 这个 block(块) 即可。同一个列的数据是集中的,而且是相同格式的, Kudu 可以对数据进行编码,例如字典编码,行长编码, bitshuffle 等。通过这种方式可以很大的减少数据在磁盘上的大小,提高吞吐率。除此之外,用户可以选择使用通用的压缩格式对数据进行压缩,如 LZ4, gzip, 或 bzip2 。这是可选的,用户可以根据业务场景,在数据大小和 CPU 效率上进行权衡。这一部分的实现上, Kudu 很大部分借鉴了 Parquet 的代码。
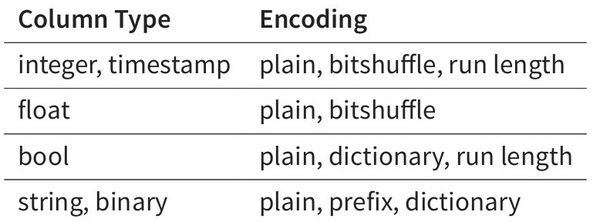
HBase 支持 snappy 存储,然而因为它的 LSM 的数据存储方式,使得它很难对数据进行特殊编码,这也是 Kudu 声称具有很快的 scan 速度的一个很重要的原因。不过,因为列式编码后的数据很难再进行修改,因此当这写数据写入磁盘后,是不可变的,这部分数据称之为 base 数据。 Kudu 用 MVCC (多版本并发控制)来实现数据的删改功能。更新、删除操作需要记录到特殊的数据结构里,保存在内存中的 DeltaMemStore 或磁盘上的 DeltaFIle 里面。 DeltaMemStore 是 B-Tree 实现的,因此速度快,而且可修改。磁盘上的 DeltaFIle 是二进制的列式的块,和 base 数据一样都是不可修改的。因此当数据频繁删改的时候,磁盘上会有大量的 DeltaFiles 文件, Kudu 借鉴了 Hbase 的方式,会定期对这些文件进行合并。
下图显示了一个具有三个 master 和多个 tablet server 的 Kudu 集群,每个服务器都支持多个 tablet。它说明了如何使用 Raft 共识来允许 master 和 tablet server 的 leader 和 follow。此外,tablet server 可以成为某些 tablet 的 leader,也可以是其他 tablet 的 follower。leader 以金色显示,而 follower 则显示为蓝色。
Kudu的架构的更多相关文章
- Kudu的集群安装(1.6.0-cdh5.14.0)
kudu的架构体系 下图显示了一个具有三个 master 和多个 tablet server 的 Kudu 集群,每个服务器都支持多个 tablet.它说明了如何使用 Raft 共识来允许 maste ...
- kudu基础入门
1.kudu介绍 1.1 背景介绍 在KUDU之前,大数据主要以两种方式存储: (1)静态数据: 以 HDFS 引擎作为存储引擎,适用于高吞吐量的离线大数据分析场景.这类存储的局限性是数据无法进行随机 ...
- KuDu论文解读
kudu是cloudera在2012开始秘密研发的一款介于hdfs和hbase之间的高速分布式存储数据库.兼具了hbase的实时性.hdfs的高吞吐,以及传统数据库的sql支持.作为一款实时.离线之间 ...
- Kudu – 在快数据上的进行快分析的存储
转自: http://www.tuicool.com/articles/nmYf2uf Cloudera Impala Kudu – 在快数据上的进行快分析的存储 Kudu,对应中文的含义应该 ...
- Apache Kudu
Apache Kudu是由Cloudera开源的存储引擎,可以同时提供低延迟的随机读写和高效的数据分析能力.Kudu支持水平扩展,使用Raft协议进行一致性保证,并且与Cloudera Impala和 ...
- Cloudera Kudu是什么?
不多说,直接上干货! Cloudera Kudu是什么? kudu是cloudera在2012开始秘密研发的一款介于hdfs和hbase之间的高速分布式列式存储数据库.兼具了hbase的实时性.hdf ...
- kuda 了解片
本来上个月想去了解一下kuda的,结果一直没有抽出时间去搞,现在大致先开个头,方便后面深入! Apache Kudu是开源Apache Hadoop生态系统的新成员,它完善了Hadoop的存储层,可以 ...
- kudu架构(转)
特点: High availability(高可用性).Tablet server 和 Master 使用 Raft Consensus Algorithm 来保证节点的高可用,确保只要有一半以上 ...
- hadoop生态圈列式存储系统--kudu
介绍 Kudu 是一个针对 Apache Hadoop 平台而开发的列式存储管理器.Kudu 共享 Hadoop 生态系统应用的常见技术特性: 它在 commodity hardware(商品硬件)上 ...
随机推荐
- maven tomcat:run指定tomcat7:
配置好下面的内容后,执行 run as -> tomcat7:run 或者tomcat6:run可以将maven的web应用在tomcat6/7里面运行 ,eclipse Indigo 版本默认 ...
- SpringMVC执行流程(四)
DispatcherServlet 组建的默认配置 HandlerMapping有这两种:BeanNameUrlHandlerMapping,SimpleUrlHandlerMapping Handl ...
- Xcode编译报错信息总结
1.dyld: Library not loaded: @rpath/.../xxx.framework 一般与这个库的加载路径有关,先看看是否将静态库设置成了动态库(库的Mach-o Type选项) ...
- iTween插件使用
itween插件 itween是一个动画库,作者创建它的目的就是最小的投入实现最大的产出.用它可以轻松实现各种动画,晃动,旋转,移动.褪色.上色.控制音频等. iTween原理: itween的核心是 ...
- [MOOC程序设计与算法二] 递归二
1.表达式计算 输入为四则运算表达式,仅由整数.+.-.* ./ .(.) 组成,没有空格,要求求其值.假设运算符结果都是整数 ."/"结果也是整数 表达式也是递归的定义: 表达式 ...
- 学习高性能mysql
Mysql 的InnoDB存储引擎实现的不是简单的行级锁,实现的是MVCC,多版本并发控制,可以理解成行级锁的一个变种. InnoDB的MVCC是通过在每行纪录后面保存两个隐藏的列来实现的.这两个列, ...
- Bit(位) and Byte(字节) ASCll 编码【基础】
Bit(位) 与Byte(字节)的区别bit意为“位”,是计算机运算的基础,与数据处理速度和传输速度有关.比如:USB2.0标准接口传输速率为480Mbps,其中bps=bits per second ...
- C语言数据结构-单链表的实现-初始化、销毁、长度、查找、前驱、后继、插入、删除、显示操作
1.数据结构-单链表的实现-C语言 typedef struct LNode { int data; struct LNode* next; } LNode,*LinkList; //这两者等价.Li ...
- atcoder 2643 切比雪夫最小生成树
There are N towns on a plane. The i-th town is located at the coordinates (xi,yi). There may be more ...
- 树莓派使用 HLS 实现视频流直播
说明 这次介绍一下基于上一篇文章"树莓派编译安装 FFmpeg "的应用,即 HLS 视频流直播.原理是 FFmpeg 将 USB 摄像头的原始视频流压缩为 H.264 视频流,然 ...