HADOOP HDFS BALANCER介绍及经验总结(转)
1.集群执行balancer命令,依旧不平衡的原因是什么?该如何解决?
2.尽量不在NameNode上执行start-balancer.sh的原因是什么?
- sh $HADOOP_HOME/bin/start-balancer.sh –t 10%
复制代码
这个命令中-t参数后面跟的是HDFS达到平衡状态的磁盘使用率偏差值。如果机器与机器之间磁盘使用率偏差小于10%,那么我们就认为HDFS集群已经达到了平衡的状态。
HADOOP HDFS BALANCER介绍及经验总结(转)的更多相关文章
- 【转】HADOOP HDFS BALANCER介绍及经验总结
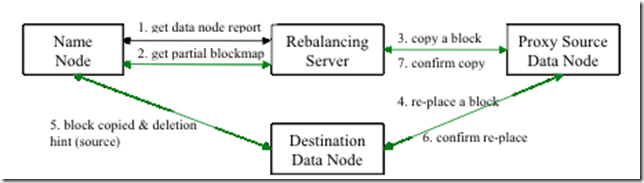
转自:http://www.aboutyun.com/thread-7354-1-1.html 集群平衡介绍 Hadoop的HDFS集群非常容易出现机器与机器之间磁盘利用率不平衡的情况,比如集群中添加 ...
- 【转载】漫谈HADOOP HDFS BALANCER
Hadoop的HDFS集群非常容易出现机器与机器之间磁盘利用率不平衡的情况,比如集群中添加新的数据节点.当HDFS出现不平衡状况的时候,将引发很多问题,比如MR程序无法很好地利用本地计算的优势,机器之 ...
- 【Hadoop离线基础总结】HDFS入门介绍
HDFS入门介绍 概述 HDFS全称为Hadoop Distribute File System,也就是Hadoop分布式文件系统,是Hadoop的核心组件之一. 分布式文件系统是横跨在多台计算机上的 ...
- Hadoop记录-HDFS balancer配置
HDFS balancer配置(可通过CM配置)dfs.datanode.balance.max.concurrent.moves 并行移动的block数量,默认5 dfs.datanode.bala ...
- 【Hadoop离线基础总结】HDFS详细介绍
HDFS详细介绍 分布式文件系统设计思路 概述 只有一台机器时的文件查找:hello.txt /export/servers/hello.txt 如果有多台机器时的文件查找:hello.txt nod ...
- Hadoop HDFS分布式文件系统 常用命令汇总
引言:我们维护hadoop系统的时候,必不可少需要对HDFS分布式文件系统做操作,例如拷贝一个文件/目录,查看HDFS文件系统目录下的内容,删除HDFS文件系统中的内容(文件/目录),还有HDFS管理 ...
- Hadoop HDFS 用户指南
This document is a starting point for users working with Hadoop Distributed File System (HDFS) eithe ...
- Hadoop HDFS负载均衡
Hadoop HDFS负载均衡 转载请注明出处:http://www.cnblogs.com/BYRans/ Hadoop HDFS Hadoop 分布式文件系统(Hadoop Distributed ...
- sudo -u hdfs hdfs balancer出现异常 No lease on /system/balancer.id
16/06/02 20:34:05 INFO balancer.Balancer: namenodes = [hdfs://dlhtHadoop101:8022, hdfs://dlhtHadoop1 ...
随机推荐
- Q&A:string、vector、iterator、bitset
细节要点 getline(cin,string)与cin>>string 在VS2013中通过输入换行符\n,对getline以及cin的用法进行测试,但是并没有像文中所述遇到换行符停止读 ...
- 为mac编写swift脚本
代码示例: #!/usr/bin/env xcrun swift print("Hello World") 可以用Sublime Text编写,安装Swift包后有语法着色功能.然 ...
- vue项目打包注意的地方
打包有两种方式: 第一种方式:1.更改config文件夹下prod.env.js下的地址: 2.将config文件夹下index.js中build下改为 assetsPublicPath: '', 第 ...
- 动态加载CSS,JS文件
var Head = document.getElementsByTagName('head')[0],style = document.createElement('style'); //文件全部加 ...
- 条款36:绝对不要重新定义,继承而来的non-virtual函数
重新定义一个继承而来的non-virtual函数可能会使得导致当函数被调用的时候,被调用的函数不是取决于调用的函数究竟属于的对象,而是取决于调用函数的指针或者引用的类型. 所以一般的说主要有两种观点在 ...
- uva11729 - Commando War(贪心)
贪心法,执行任务的时间J越长的应该越先交待.可以用相邻交换法证明正确性.其实对于两个人,要让总时间最短,就要让同一时间干两件事的时间最长. #include<iostream> #incl ...
- LeetCode Perfect Number
原题链接在这里:https://leetcode.com/problems/perfect-number/#/description 题目: We define the Perfect Number ...
- bzoj 1798 [Ahoi2009]Seq 维护序列seq ——线段树
题目:https://www.lydsy.com/JudgeOnline/problem.php?id=1798 先乘后加,就可给加法标记乘上乘法标记. 注意可能有 *0 的操作,所以 pshd 时不 ...
- 技术总监Sycx的故事
其实我在各种演讲里,线下吹牛里面无数次提及过他,讲过他的故事,但是总还是没有任何一次认认真真的详细讲过,所以,今天就讲讲他的故事吧. Sycx是福建漳州人,我经常开玩笑说,你生于一个著名的骗子之乡,为 ...
- live555源码分析----RSTPServer创建过程分析
最近五一回家,终于有机会能安静的看一下流媒体这方面相关的知识,准备分析live555的源码,接下来会把我读源码的过程记录成博客,以供其他的同路人参考. 因为再读源码的过程中,并不是一路顺着读下来,往往 ...