浅谈BloomFilter【上】基本概念和实现原理
在日常生活中。包括在设计计算机软件时,我们常常要推断一个元素是否在一个集合中。
比方在字处理软件中,须要检查一个英语单词是否拼写正确(也就是要推断 它是否在已知的字典中)。在 FBI。一个嫌疑人的名字是否已经在嫌疑名单上;在网络爬虫里。一个网址是否被訪问过等等。最直接的方法就是将集合中所有的元素存在计算机中,遇到一个新 元素时,将它和集合中的元素直接比較就可以。一般来讲。计算机中的集合是用哈希表(hash
table)来存储的。
它的长处是高速准确。缺点是费存储空间。当集合比較小时。这个问题不显著。可是当集合巨大时,哈希表存储效率低的问题就显现出来 了。比方说。一个象 Yahoo,Hotmail 和 Gmai 那样的公众电子邮件(email)提供商。总是须要过滤来自发送垃圾邮件的人(spamer)的垃圾邮件。一个办法就是记录下那些发垃圾邮件的 email 地址。
由于那些发送者不停地在注冊新的地址,全世界少说也有几十亿个发垃圾邮件的地址,将他们都存起来则须要大量的网络server。假设用哈希表,每存储一亿 个 email
地址, 就须要 1.6GB 的内存(用哈希表实现的详细办法是将每一个 email 地址相应成一个八字节的信息指纹(详见:googlechinablog.com/2006/08/blog-post.html)。 然后将这些信息指纹存入哈希表。由于哈希表的存储效率一般仅仅有 50%,因此一个 email 地址须要占用十六个字节。一亿个地址大约要 1.6GB。 即十六亿字节的内存)。
因此存贮几十亿个邮件地址可能须要上百 GB 的内存。除非是超级计算机。一般server是无法存储的。(该段引用谷歌数学之美:http://www.google.com.hk/ggblog/googlechinablog/2007/07/bloom-filter_7469.html)
一、基本概念
布隆过滤器(Bloom Filter)是由布隆(Burton Howard Bloom)在1970年提出的。它实际上是由一个非常长的二进制向量和一系列随机映射函数组成,布隆过滤器能够用于检索一个元素是否在一个集合中。它的长处是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率(假正例False
positives,即Bloom Filter报告某一元素存在于某集合中,可是实际上该元素并不在集合中)和删除困难,可是没有识别错误的情形(即假反例False negatives,假设某个元素确实没有在该集合中,那么Bloom Filter 是不会报告该元素存在于集合中的,所以不会漏报)。
假设想推断一个元素是不是在一个集合里。一般想到的是将所有元素保存起来。然后通过比較确定。
链表,树等等数据结构都是这样的思路. 可是随着集合中元素的添加,我们须要的存储空间越来越大,检索速度也越来越慢。只是世界上另一种叫作散列表(又叫哈希表,Hash table)的数据结构。它能够通过一个Hash函数将一个元素映射成一个位阵列(Bit
Array)中的一个点。
这样一来。我们仅仅要看看这个点是不是 1 就知道能够集合中有没有它了。这就是布隆过滤器的基本思想。
Hash面临的问题就是冲突。
假设 Hash 函数是良好的,假设我们的位阵列长度为 m 个点,那么假设我们想将冲突率减少到比如 1%, 这个散列表就仅仅能容纳 m/100 个元素。显然这就不叫空间有效了(Space-efficient)。
解决方法也简单,就是使用多个 Hash,假设它们有一个说元素不在集合中,那肯定就不在。假设它们都说在,尽管也有一定可能性它们在说谎。只是直觉上推断这样的事情的概率是比較低的。
长处
相比于其他的数据结构。布隆过滤器在空间和时间方面都有巨大的优势。布隆过滤器存储空间和插入/查询时间都是常数。另外, Hash 函数相互之间没有关系,方便由硬件并行实现。布隆过滤器不须要存储元素本身,在某些对保密要求非常严格的场合有优势。
布隆过滤器能够表示全集。其他不论什么数据结构都不能;
k 和 m 同样,使用同一组 Hash 函数的两个布隆过滤器的交并差运算能够使用位操作进行。
缺点
可是布隆过滤器的缺点和长处一样明显。误算率(False Positive)是当中之中的一个。随着存入的元素数量添加,误算率随之添加。
可是假设元素数量太少,则使用散列表足矣。
另外,普通情况下不能从布隆过滤器中删除元素. 我们非常easy想到把位列阵变成整数数组。每插入一个元素相应的计数器加1, 这样删除元素时将计数器减掉就能够了。
然而要保证安全的删除元素并非如此简单。首先我们必须保证删除的元素的确在布隆过滤器里面. 这一点单凭这个过滤器是无法保证的。另外计数器回绕也会造成问题。
二、算法描写叙述
一个empty bloom filter是一个有m bits的bit array。每一个bit位都初始化为0。
而且定义有k个不同的hash function,每一个都以uniform random distribution将元素hash到m个不同位置中的一个。
在以下的介绍中n为元素数,m为布隆过滤器或哈希表的slot数,k为布隆过滤器重hash
function数。
为了add一个元素,用k个hash function将它hash得到bloom filter中k个bit位,将这k个bit位置1。
为了query一个元素。即推断它是否在集合中。用k个hash function将它hash得到k个bit位。若这k bits全为1,则此元素在集合中。若当中任一位不为1,则此元素比不在集合中(由于假设在,则在add时已经把相应的k个bits位置为1)。
不同意remove元素,由于那样的话会把相应的k个bits位置为0。而当中非常有可能有其他元素相应的位。因此remove会引入false negative,这是绝对不被同意的。
当k非常大时。设计k个独立的hash function是不现实而且困难的。对于一个输出范围非常大的hash function(比如MD5产生的128 bits数)。假设不同bit位的相关性非常小,则可把此输出切割为k份。
或者可将k个不同的初始值(比如0,1,2, … ,k-1)结合元素,feed给一个hash
function从而产生k个不同的数。
当add的元素过多时,即n/m过大时(n是元素数,m是bloom filter的bits数),会导致false positive过高,此时就须要又一次组建filter。但这样的情况相对少见。
三、 时间和空间上的优势
当能够承受一些误报时,布隆过滤器比其他表示集合的数据结构有着非常大的空间优势。比如self-balance BST, tries, hash table或者array, chain,它们中大多数至少都要存储元素本身。对于小整数须要少量的bits,对于字符串则须要随意多的bits(tries是个例外。由于对于有同样prefixes的元素能够共享存储空间);而chain结构还须要为存储指针付出额外的代价。对于一个有1%误报率和一个最优k值的布隆过滤器来说。不管元素的类型及大小,每一个元素仅仅须要9.6
bits来存储。这个长处一部分继承自array的紧凑性。一部分来源于它的概率性。
假设你觉得1%的误报率太高,那么对每一个元素每添加4.8 bits。我们就可将误报率减少为原来的1/10。
add和query的时间复杂度都为O(k)。与集合中元素的多少无关,这是其他数据结构都不能完毕的。
假设可能元素范围不是非常大,而且大多数都在集合中,则使用确定性的bit array远远胜过使用布隆过滤器。由于bit array对于每一个可能的元素空间上仅仅须要1 bit,add和query的时间复杂度仅仅有O(1)。注意到这样一个哈希表(bit array)仅仅有在忽略collision而且仅仅存储元素是否在当中的二进制信息时,才会获得空间和时间上的优势,而在此情况下。它就有效地称为了k=1的布隆过滤器。
而当考虑到collision时,对于有m个slot的bit array或者其他哈希表(即k=1的布隆过滤器)。假设想要保证1%的误判率,则这个bit array仅仅能存储m/100个元素。因而有大量的空间被浪费,同一时候也会使得空间复杂度急剧上升,这显然不是space
efficient的。
解决办法非常简单,使用k>1的布隆过滤器。即k个hash function将每一个元素改为相应于k个bits。由于误判度会减少非常多。而且假设參数k和m选取得好,一半的m可被置为为1,这充分说明了布隆过滤器的space efficient性。
四、 举例说明
以垃圾邮件过滤中黑白名单为例:现有1亿个email的黑名单,每一个都拥有8 bytes的指纹信息,则可能的元素范围为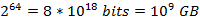
。对于bit array来说是根本不可能的范围,而且元素的数量(即email列表)为
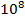 。相比于元素范围过于稀疏,而且还没有考虑到哈希表中的collision问题。
。相比于元素范围过于稀疏,而且还没有考虑到哈希表中的collision问题。
若採用哈希表,由于大多数採用open addressing来解决collision。而此时的search时间复杂度为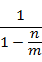 。
。
即若哈希表半满(n/m = 1/2)。则每次search须要probe 2次,因此在保证效率的情况下哈希表的存储效率最好不超过50%。此时每一个元素占8 bytes,总空间为: 。若採用Perfect
hashing(这里能够採用Perfect hashing是由于主要操作是search/query,而并非add和remove)。尽管保证worst-case也仅仅有一次probe,可是空间利用率更低,普通情况下为50%。worst-case时有不到一半的概率为25%。
若採用布隆过滤器,取k=8。
由于n为1亿,所以总共须要 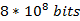 被置位为1。又由于在保证误判率低且k和m选取合适时,空间利用率为50%(后面会解释),所以总空间为:
被置位为1。又由于在保证误判率低且k和m选取合适时,空间利用率为50%(后面会解释),所以总空间为: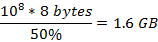 。
。
所需空间比上述哈希结构小得多,而且误判率在万分之中的一个以下。
五、误判概率的证明和计算
假设布隆过滤器中的hash function满足simple uniform hashing假设:每一个元素都等概率地hash到m个slot中的不论什么一个。与其他元素被hash到哪个slot无关。
若m为bit数,则对某一特定bit位在一个元素由某特定hash function插入时没有被置位为1的概率为:
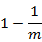
则k个hash function中没有一个对其置位的概率为:
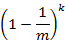
假设插入了n个元素,但都未将其置位的概率为:
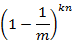
则此位被置位的概率为:
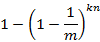
如今考虑query阶段,若相应某个待query元素的k bits所有置位为1。则可判定其在集合中。因此将某元素误判的概率为:
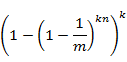
由于 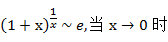 ,而且
,而且 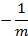
当m非常大时趋近于0,所以
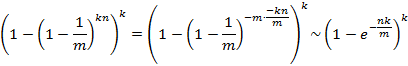
从上式中能够看出,当m增大或n减小时。都会使得误判率减小,这也符合直觉。
如今计算对于给定的m和n。k为何值时能够使得误判率最低。
设误判率为k的函数为:
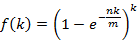
设 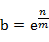 ,
,
则简化为
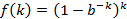 ,两边取对数
,两边取对数
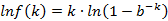
, 两边对k求导
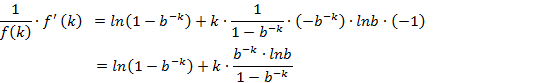
以下求最值
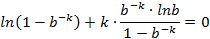
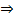
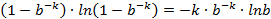

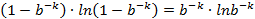
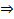
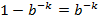
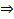
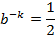
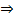
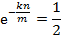
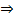
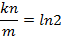
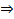
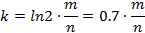
因此,即当 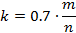
时误判率最低,此时误判率为:
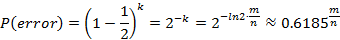
能够看出若要使得误判率≤1/2。则:
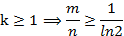
这说明了若想保持某固定误判率不变。布隆过滤器的bit数m与被add的元素数n应该是线性同步添加的。
六、设计和应用布隆过滤器的方法
应用时首先要先由用户决定要add的元素数n和希望的误差率P。这也是一个设计完整的布隆过滤器须要用户输入的仅有的两个參数,之后的所有參数将由系统计算。并由此建立布隆过滤器。
系统首先要计算须要的内存大小m bits:
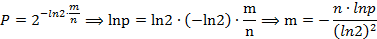
再由m。n得到hash function的个数:
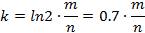
至此系统所需的參数已经备齐,接下来add n个元素至布隆过滤器中。再进行query。
依据公式。当k最优时:
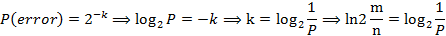
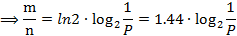
因此可验证当P=1%时,存储每一个元素须要9.6 bits:
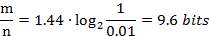
而每当想将误判率减少为原来的1/10。则存储每一个元素须要添加4.8 bits:
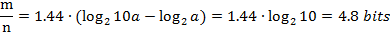
这里须要特别注意的是。9.6 bits/element不仅包括了被置为1的k位,还把包括了没有被置为1的一些位数。此时的
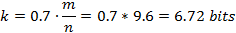
才是每一个元素相应的为1的bit位数。
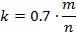
从而使得P(error)最小时。我们注意到:
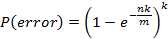 中的
中的 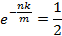
,即

此概率为某bit位在插入n个元素后未被置位的概率。因此,想保持错误率低。布隆过滤器的空间使用率需为50%。
七、Bloom Filter 用例
Google 著名的分布式数据库 Bigtable 使用了布隆过滤器来查找不存在的行或列,以减少磁盘查找的IO次数[3]。
Squid 网页代理缓存server在 cache
digests 中使用了也布隆过滤器[4]。
Venti 文档存储系统也採用布隆过滤器来检測先前存储的数据[5]。
SPIN 模型检測器也使用布隆过滤器在大规模验证问题时跟踪可达状态空间[6]。
Google Chrome浏览器使用了布隆过滤器加速安全浏览服务[7]。
在非常多Key-Value系统中也使用了布隆过滤器来加快查询过程,如 Hbase。Accumulo,Leveldb,一般而言,Value 保存在磁盘中。訪问磁盘须要花费大量时间。然而使用布隆过滤器能够高速推断某个Key相应的Value是否存在,因此能够避免非常多不必要的磁盘IO操作。仅仅是引入布隆过滤器会带来一定的内存消耗,下图是在Key-Value系统中布隆过滤器的典型使用:

八、布隆过滤器相关扩展
Counting filters
主要的布隆过滤器不支持删除(Deletion)操作,可是 Counting filters 提供了一种能够不用又一次构建布隆过滤器但却支持元素删除操作的方法。在Counting filters中原来的位数组中的每一位由
bit 扩展为 n-bit 计数器。实际上,主要的布隆过滤器能够看作是仅仅有一位的计数器的Counting filters。原来的插入操作也被扩展为把 n-bit 的位计数器加1,查找操作即检查位数组非零就可以。而删除操作定义为把位数组的相应位减1。可是该方法也有位的算术溢出问题,即某一位在多次删除操作后可能变成负值,所以位数组大小 m 须要充分大。另外一个问题是Counting filters不具备伸缩性,由于Counting
filters不能扩展,所以须要保存的最大的元素个数须要提前知道。
否则一旦插入的元素个数超过了位数组的容量。false positive的发生概率将会急剧添加。当然也有人提出了一种基于 D-left Hash 方法实现支持删除操作的布隆过滤器。同一时候空间效率也比Counting filters高。
Data synchronization
Byers等人提出了使用布隆过滤器近似数据同步[9]。
Bloomier filters
Chazelle 等人提出了一个通用的布隆过滤器,该布隆过滤器能够将某一值与每一个已经插入的元素关联起来。并实现了一个关联数组Map[10]。
与普通的布隆过滤器一样。Chazelle实现的布隆过滤器也能够达到较低的空间消耗,但同一时候也会产生false
positive。只是,在Bloomier filter中。某 key 假设不在 map 中,false positive在会返回时会被定义出的。
该Map 结构不会返回与 key 相关的在 map 中的错误的值。
在下一节。我们将会用Java 实现一个简单的 BloomFilter.
用Java实现 BloomFilter:http://blog.csdn.net/zq602316498/article/details/40660695
本文图片和内容文字来源与两篇文章,原文地址:
http://www.cnblogs.com/allensun/archive/2011/02/16/1956532.html
http://www.cnblogs.com/haippy/archive/2012/07/13/2590351.html
浅谈BloomFilter【上】基本概念和实现原理的更多相关文章
- Java网络编程和NIO详解7:浅谈 Linux 中NIO Selector 的实现原理
Java网络编程和NIO详解7:浅谈 Linux 中NIO Selector 的实现原理 转自:https://www.jianshu.com/p/2b71ea919d49 本系列文章首发于我的个人博 ...
- 浅谈异步上传插件 jquery-file-upload插件
当我们需要异步上传文件的时候,我们倾向于在网上查找相关的JQuery插件,jquery-file-upload就是我们经常看到的,但是他的主页是英文的,对于我们这些英语比较差的同学来说,简直就是... ...
- 浅谈数学上的矩阵——矩阵的乘法运算的概念及C++上的实现模板
首先让我们来谈一谈数学意义上的矩阵(在座各位也可以简单地将它理解为一个二维数组) 这样可以帮助我们理解矩阵加速及其运用的原理(矩阵加速是一个及其玄学的东西,所以请重点理解矩阵乘法) 这里给出一段严格 ...
- 浅谈Js对象的概念、创建、调用、删除、修改!
一.我们经常困惑,对象究竟是什么,其实这是一种思维,一种意识上的东西,就像我们都说 世界是有物质组成的道理一样,理解了下面的几句话!对象也不是那么抽象! 1.javascript中的所有事 ...
- 浅谈BloomFilter【下】用Java实现BloomFilter
通过前一篇文章的学习,对于 BloomFilter 的概念和原理.以及误报率等计算方法都一个理性的认识了. 在这里,我们将用 Java'实现一个简单的 BloomFilter . package pr ...
- 浅谈webuploader上传文件
官网:http://c7.gg/fw4sn 案例: 文件上传进度 // 文件上传过程中创建进度条实时显示. uploader.on( 'uploadProgress', function( file, ...
- SpringBoot: 浅谈文件上传和访问的坑 (MultiPartFile)
本次的项目环境为 SpringBoot 2.0.4, JDK8.0. 服务器环境为CentOS7.0, Nginx的忘了版本. 前言 SpringBoot使用MultiPartFile接收来自表单的f ...
- 浅谈--ETCD的基本概念及用法
1. 简介 ETCD 是一个高可用的分布式键值数据库,可用于服务发现.ETCD 采用 raft 一致性算法,基于 Go 语言实现. raft是一个强一致的集群日志同步算法. ETCD使用gRPC,网络 ...
- 浅谈 underscore 内部方法 group 的设计原理
前言 真是天一热什么事都不想干,这个月只产出了一篇文章,赶紧写一篇压压惊! 前文(https://github.com/hanzichi/underscore-analysis/issues/15)说 ...
随机推荐
- 计蒜客 28206.Runway Planning (BAPC 2014 Preliminary ACM-ICPC Asia Training League 暑假第一阶段第一场 F)
F. Runway Planning 传送门 题意简直就是有毒,中间bb一堆都是没用的,主要的意思就是度数大于180度的就先减去180度,然后除以10,四舍五入的值就是答案.如果最后结果是0就输出18 ...
- Codeforces 897 A.Scarborough Fair-字符替换
A. Scarborough Fair time limit per test 2 seconds memory limit per test 256 megabytes input stan ...
- Codeforces 208E - Blood Cousins(树上启发式合并)
208E - Blood Cousins 题意 给出一棵家谱树,定义从 u 点向上走 k 步到达的节点为 u 的 k-ancestor.多次查询,给出 u k,问有多少个与 u 具有相同 k-ance ...
- poj2774(最长公共子串)
poj2774 题意 求两个字符串的最长公共子串 分析 论文 将两个字符串合并,中间插入分隔符,在找最大的 height 值的时候保证,两个字符串后缀的起始点分别来自原来的两个字符串. code #i ...
- [POJ 3378] Crazy Thairs
Link: POJ 3378 传送门 Solution: 按序列长度$dp$, 设$dp[i][j]$为到第$i$个数,符合要求的序列长度为$j$时的序列个数, 易得转移方程:$dp[i][j]=\s ...
- [CF623E]Transforming Sequence
$\newcommand{\align}[1]{\begin{align*}#1\end{align*}}$题意:对于一个序列$a_{1\cdots n}(a_i\in[1,2^k-1])$,定义序列 ...
- cannot be cast to javassist.util.proxy.Proxy
工程lib冲突 javassist-3.18.1-GA.jar javassist-3.11.0.GA.jar 删除一个
- linux命令行翻页
在linux上面执行命令,若命令太多屏幕显示不完,通过Shift+pageup/pageDown来查看. putty连接linux后执行就不存在这个问题.
- sourceinsight----tabsiplus颜色配置文件
参考: http://blog.csdn.net/orbit/article/details/7585607 下面是我的颜色配置 http://files.cnblogs.com/pengdongli ...
- JAVA实现通用日志记录
原文:http://blog.csdn.net/jinzhencs/article/details/51882751 前言: 之前想在filter层直接过滤httpServerletRequest请求 ...