3.Mysql集群------Mycat分库分表
前言:
分库分表,在本节里是水平切分,就是多个数据库里包含的表是一模一样的。
只是把字段散列的分到不同的库中。
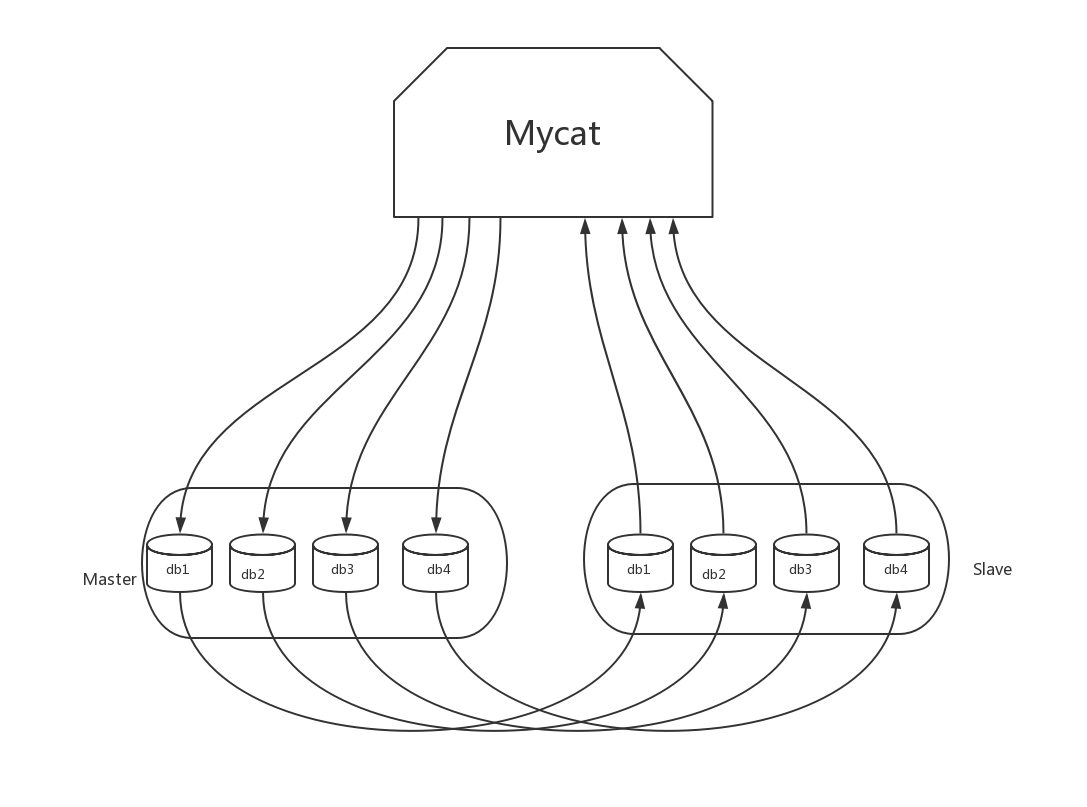
实践:
1.修改schema.xml
这里是在同一台服务器上建立了4个数据库db1,db2,db3,db4
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/"> <!-- 配置逻辑库XMDB -->
<schema name="XMDB" checkSQLschema="false" sqlMaxLimit="100">
<table name="user" dataNode="dn1,dn2,dn3,dn4" rule="crc32slot"/>
</schema>
<dataNode name="dn1" dataHost="node1" database="db1"/>
<dataNode name="dn2" dataHost="node1" database="db2"/>
<dataNode name="dn3" dataHost="node1" database="db3"/>
<dataNode name="dn4" dataHost="node1" database="db4"/>
<dataHost name="node1" maxCon="1000" minCon="10" balance="1" dbType="mysql" dbDriver="native">
<heartbeat>select user()</heartbeat>
<writeHost host="192.168.40.3" url="192.168.40.3:3306" user="root" password="123456">
<readHost host="192.168.40.3" url="192.168.40.3:3316" user="root" password="123456" />
</writeHost>
</dataHost> <!--
<dataHost name="sequoiadb1" maxCon="1000" minCon="1" balance="0" dbType="sequoiadb" dbDriver="jdbc">
<heartbeat> </heartbeat>
<writeHost host="hostM1" url="sequoiadb://1426587161.dbaas.sequoialab.net:11920/SAMPLE" user="jifeng" password="jifeng"></writeHost>
</dataHost> <dataHost name="oracle1" maxCon="1000" minCon="1" balance="0" writeType="0" dbType="oracle" dbDriver="jdbc"> <heartbeat>select 1 from dual</heartbeat>
<connectionInitSql>alter session set nls_date_format='yyyy-mm-dd hh24:mi:ss'</connectionInitSql>
<writeHost host="hostM1" url="jdbc:oracle:thin:@127.0.0.1:1521:nange" user="base" password="123456" > </writeHost> </dataHost> <dataHost name="jdbchost" maxCon="1000" minCon="1" balance="0" writeType="0" dbType="mongodb" dbDriver="jdbc">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM" url="mongodb://192.168.0.99/test" user="admin" password="123456" ></writeHost> </dataHost> <dataHost name="sparksql" maxCon="1000" minCon="1" balance="0" dbType="spark" dbDriver="jdbc">
<heartbeat> </heartbeat>
<writeHost host="hostM1" url="jdbc:hive2://feng01:10000" user="jifeng" password="jifeng"></writeHost> </dataHost> --> <!-- <dataHost name="jdbchost" maxCon="1000" minCon="10" balance="0" dbType="mysql"
dbDriver="jdbc"> <heartbeat>select user()</heartbeat> <writeHost host="hostM1"
url="jdbc:mysql://localhost:3306" user="root" password="123456"> </writeHost>
</dataHost> -->
</mycat:schema>
2.rule.xml
对应的rule
<property name="count">4</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
<?xml version="1.0" encoding="UTF-8"?>
<!-- - - Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License. - You
may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0
- - Unless required by applicable law or agreed to in writing, software -
distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the
License for the specific language governing permissions and - limitations
under the License. -->
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="rule1">
<rule>
<columns>id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule> <tableRule name="rule2">
<rule>
<columns>user_id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule> <tableRule name="sharding-by-intfile">
<rule>
<columns>sharding_id</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-murmur">
<rule>
<columns>id</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
<tableRule name="crc32slot">
<rule>
<columns>id</columns>
<algorithm>crc32slot</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-month">
<rule>
<columns>create_time</columns>
<algorithm>partbymonth</algorithm>
</rule>
</tableRule>
<tableRule name="latest-month-calldate">
<rule>
<columns>calldate</columns>
<algorithm>latestMonth</algorithm>
</rule>
</tableRule> <tableRule name="auto-sharding-rang-mod">
<rule>
<columns>id</columns>
<algorithm>rang-mod</algorithm>
</rule>
</tableRule> <tableRule name="jch">
<rule>
<columns>id</columns>
<algorithm>jump-consistent-hash</algorithm>
</rule>
</tableRule> <function name="murmur"
class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property><!-- 默认是0 -->
<property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
<property name="virtualBucketTimes">160</property><!-- 一个实际的数据库节点被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍 -->
<!-- <property name="weightMapFile">weightMapFile</property> 节点的权重,没有指定权重的节点默认是1。以properties文件的格式填写,以从0开始到count-1的整数值也就是节点索引为key,以节点权重值为值。所有权重值必须是正整数,否则以1代替 -->
<!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property>
用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的murmur hash值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何东西 -->
</function> <function name="crc32slot"
class="io.mycat.route.function.PartitionByCRC32PreSlot">
<property name="count">4</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
</function>
<function name="hash-int"
class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
</function>
<function name="rang-long"
class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">3</property>
</function> <function name="func1" class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">8</property>
<property name="partitionLength">128</property>
</function>
<function name="latestMonth"
class="io.mycat.route.function.LatestMonthPartion">
<property name="splitOneDay">24</property>
</function>
<function name="partbymonth"
class="io.mycat.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2015-01-01</property>
</function> <function name="rang-mod" class="io.mycat.route.function.PartitionByRangeMod">
<property name="mapFile">partition-range-mod.txt</property>
</function> <function name="jump-consistent-hash" class="io.mycat.route.function.PartitionByJumpConsistentHash">
<property name="totalBuckets">3</property>
</function>
</mycat:rule>
3.检查mycat\conf\ruledata\crc32slot_USER.properties
#WARNING !!!Please do not modify or delete this file!!!
#Thu Sep 06 17:32:38 CST 2018
3=76800-102399
2=51200-76799
1=25600-51199
0=0-25599
如果对应的分出来了四个节点,直接启动,如果没有,删除这个文件,再启动。
3.Mysql集群------Mycat分库分表的更多相关文章
- MySQL+MyCat分库分表 读写分离配置
一. MySQL+MyCat分库分表 1 MyCat简介 java编写的数据库中间件 Mycat运行环境需要JDK. Mycat是中间件.运行在代码应用和MySQL数据库之间的应用. 前身 : cor ...
- 《MyCat分库分表策略详解》
在我们的项目发展到一定阶段之后,随着数据量的增大,分库分表就变成了一件非常自然的事情.常见的分库分表方式有两种:客户端模式和服务器模式,这两种的典型代表有sharding-jdbc和MyCat.所谓的 ...
- Mycat数据库中间件对Mysql读写分离和分库分表配置
Mycat是一个开源的分布式数据库系统,不同于oracle和mysql,Mycat并没有存储引擎,但是Mycat实现了mysql协议,前段用户可以把它当做一个Proxy.其核心功能是分表分库,即将一个 ...
- Mysql系列七:分库分表技术难题之分布式全局唯一id解决方案
一.前言 在前面的文章Mysql系列四:数据库分库分表基础理论中,已经说过分库分表需要应对的技术难题有如下几个: 1. 分布式全局唯一id 2. 分片规则和策略 3. 跨分片技术问题 4. 跨分片事物 ...
- 【MySQL】数据库(分库分表)中间件对比
分区:对业务透明,分区只不过把存放数据的文件分成了许多小块,例如mysql中的一张表对应三个文件.MYD,MYI,frm. 根据一定的规则把数据文件(MYD)和索引文件(MYI)进行了分割,分区后的表 ...
- Mycat分库分表(一)
随着业务变得越来越复杂,用户越来越多,集中式的架构性能会出现巨大的问题,比如系统会越来越慢,而且时不时会宕机,所以必须要解决高性能和可用性的问题.这个时候数据库的优化就显得尤为重要,在说优化方案前,先 ...
- MyCat分库分表入门
1.分区 对业务透明,分区只不过把存放数据的文件分成了许多小块,例如mysql中的一张表对应三个文件.MYD,MYI,frm. 根据一定的规则把数据文件(MYD)和索引文件(MYI)进行了分割,分区后 ...
- MyCat | 分库分表实践
引言 先给大家介绍2个概念:数据的切分(Sharding)根据其切分规则的类型,可以分为两种切分模式. 切分模式 一种是按照不同的表(或者Schema)来切分到不同的数据库(主机)之上,这种切可以称之 ...
- mycat 分库分表
单库分表已经在上篇写过了,这次写个分库分表,不同在于配置文件上的一点点不同 <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> &l ...
随机推荐
- 百度 CDN公共库
http://developer.baidu.com/wiki/index.php?title=docs/cplat/libs 简介 CDN公共库是指将常用的JS库存放在CDN节点,以方便广大开发者直 ...
- zepto.js常用操作
zepto.js是移动端的jquery,但是并没有提供所有与jquery类似的api.Zepto设计的目的是有一个5-10k的通用库.下载并快速执行.有一个熟悉通用的API,所以你能把你主要的精力放到 ...
- Fedora14 mount出现错误时解决办法【亲测有效】
挂载时出现了如上图所示问题,看第一条英语提示,我刚开始以为是文件权限不够,改了权限之后,依旧存在这样的问题, 于是,我上网查阅了一些资料: 在解决之前,先让我们一起来了解一下nfs: NFS最大功能就 ...
- 但是你没有【But you didn't.】【by Anonymous】
作者是一位普通的美国妇女,她的丈夫在女儿4岁时应征入伍去了越南战场,从此她便和女儿相依为命.后来,她的丈夫.孩子的爸爸不幸阵亡.她终身守寡,直至年老病逝.她女儿在整理遗物时发现了母亲当年写给父亲的这首 ...
- RadControl使用相同的Theme
我們僅須對兩個地方加一些程式碼,就可使所有的RadControl擁用相的Theme,如此一下不但可使Ap內布景主題一致,設計者亦不需要對每個控件做字型,顏色,大小等等瑣碎的設計. App.Xaml.c ...
- MyEclipse 比较常用的快捷键
Ctrl+D: 删除当前行 Alt+↓ 当前行和下面一行交互位置(特别实用,可以省去先剪切,再粘贴了) Alt+↑ 当前行和上面一行交互位置(同上) Alt+← 前一个编辑的页面 Alt+→ 下一个编 ...
- MacOS python自动补全设置
1. 新建python自动补全脚步 $ cd <workdir> $ touch tab.py $ vim tab.py,输入如下内容后保存 $ chmod +x tab.py #!/us ...
- Sass基础(二)
五.嵌套 在Sass中,嵌套有三种方式:选择器嵌套.属性嵌套.伪类嵌套 1.选择器嵌套 2.属性嵌套 3.伪类嵌套 六.混合宏 当样式变得越来越复杂,需要重复使用大段的样式时,使用变量就无法达到目的了 ...
- 深入理解mvc 一系列收藏
http://www.cnblogs.com/P_Chou/archive/2010/11/01/1866605.html
- 【转】【MATLAB】模拟和数字低通滤波器的MATLAB实现
原文地址:http://blog.sina.com.cn/s/blog_79ecf6980100vcrf.html 低通滤波器参数:Fs=8000,fp=2500,fs=3500,Rp=1dB,As= ...