5,pandas高级数据处理
1、删除重复元素
使用duplicated()函数检测重复的行,返回元素为布尔类型的Series对象,每个元素对应一行,如果该行不是第一次出现,则元素为True
- keep参数:指定保留哪一重复的行数据 - 创建具有重复元素行的DataFrame
import numpy as np
import pandas as pd
from pandas import Series,DataFrame #创建一个df
np.random.seed(1)
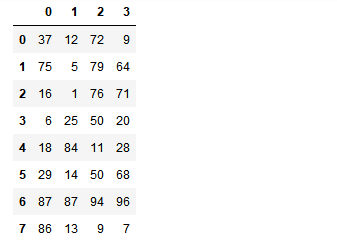
df = DataFrame(data=np.random.randint(0,100,size=(8,4)))
df
#手动将df的某几行设置成相同的内容
df.iloc[2] = [66,66,66,66]
df.iloc[4] = [66,66,66,66]
df.iloc[7] = [66,66,66,66]
df

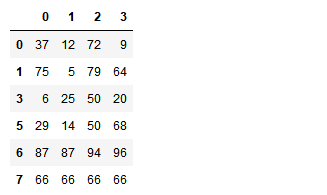
- 使用duplicated查看所有重复元素行
df.duplicated(keep='last')
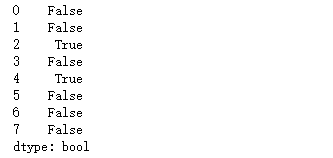
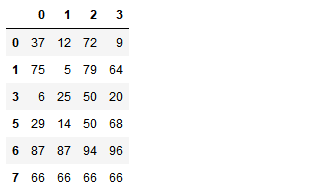
indexs = df.loc[df.duplicated(keep='last')].index
df.drop(labels=indexs,axis=0)
使用drop_duplicates()函数删除重复的行
- drop_duplicates(keep='first/last'/False)
df.drop_duplicates(keep='last')
2. 映射
1) replace()函数:替换元素
使用replace()函数,对values进行映射操作
Series替换操作
- 单值替换
- 普通替换
- 字典替换(推荐)
- 多值替换
- 列表替换
- 字典替换(推荐)
- 参数
- to_replace:被替换的元素
DataFrame替换操作
- 单值替换
- 普通替换: 替换所有符合要求的元素:to_replace=15,value='e'
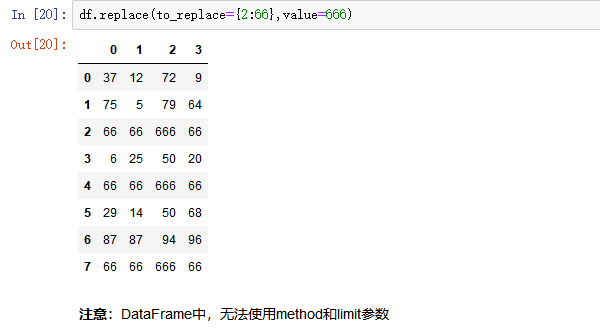
- 按列指定单值替换: to_replace={列标签:替换值} value='value'
- 多值替换
- 列表替换: to_replace=[] value=[]
- 字典替换(推荐) to_replace={to_replace:value,to_replace:value}
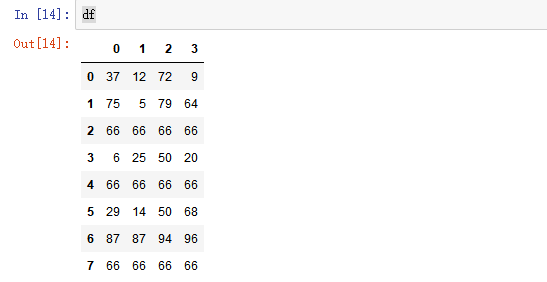
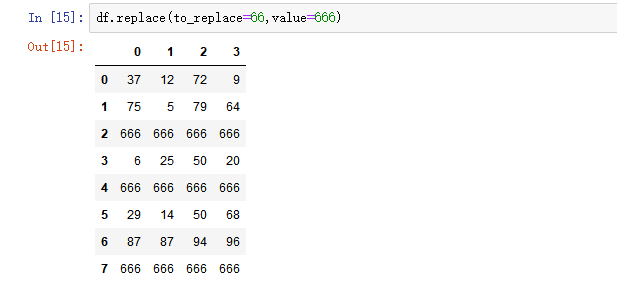
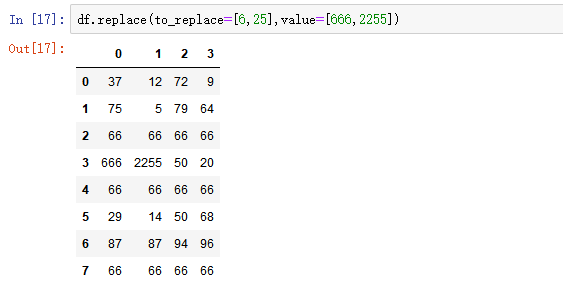
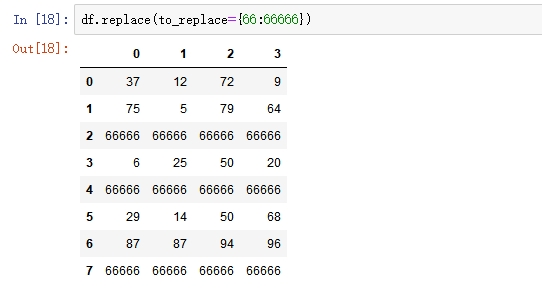
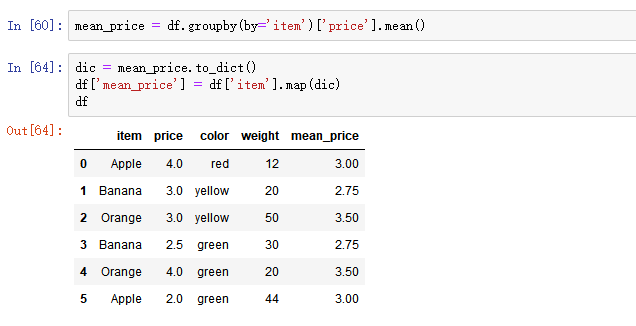
2) map()函数:新建一列 , map函数并不是df的方法,而是series的方法
- map()可以映射新一列数据
- map()中可以使用lambd表达式
map()中可以使用方法,可以是自定义的方法
eg:map({to_replace:value})
- 注意 map()中不能使用sum之类的函数,for循环
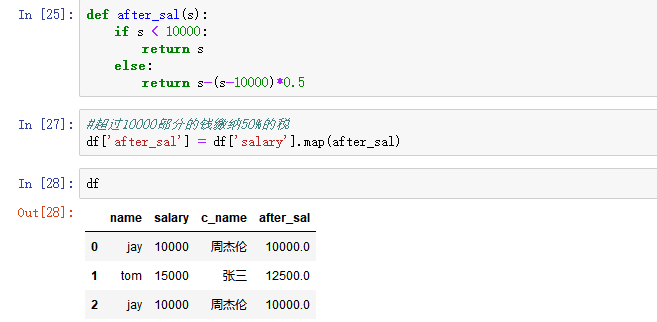
- 新增一列:给df中,添加一列,该列的值为英文名对应的中文名


map当做一种运算工具,至于执行何种运算,是由map函数的参数决定的(参数:lambda,函数)
- 使用自定义函数
注意:并不是任何形式的函数都可以作为map的参数。只有当一个函数具有一个参数且有返回值,那么该函数才可以作为map的参数。
3. 使用聚合操作对数据异常值检测和过滤
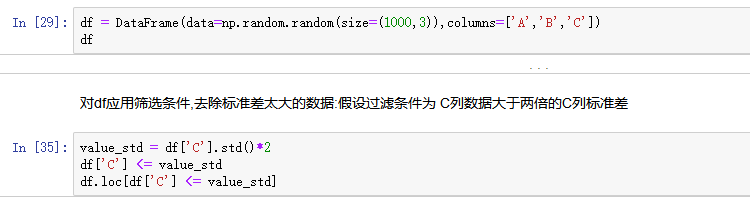
使用df.std()函数可以求得DataFrame对象每一列的标准差
- 创建一个1000行3列的df 范围(0-1),求其每一列的标准差
4. 排序
使用.take()函数排序
- take()函数接受一个索引列表,用数字表示,使得df根据列表中索引的顺序进行排序
- eg:df.take([1,3,4,2,5])可以借助np.random.permutation()函数随机排序
random_df = df.take(np.random.permutation(),axis=).take(np.random.permutation(),axis=)
random_df[:]
- np.random.permutation(x)可以生成x个从0-(x-1)的随机数列
5. 数据分类处理【重点】
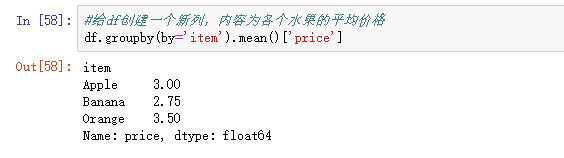
数据聚合是数据处理的最后一步,通常是要使每一个数组生成一个单一的数值。
数据分类处理:
- 分组:先把数据分为几组
- 用函数处理:为不同组的数据应用不同的函数以转换数据
- 合并:把不同组得到的结果合并起来
数据分类处理的核心:
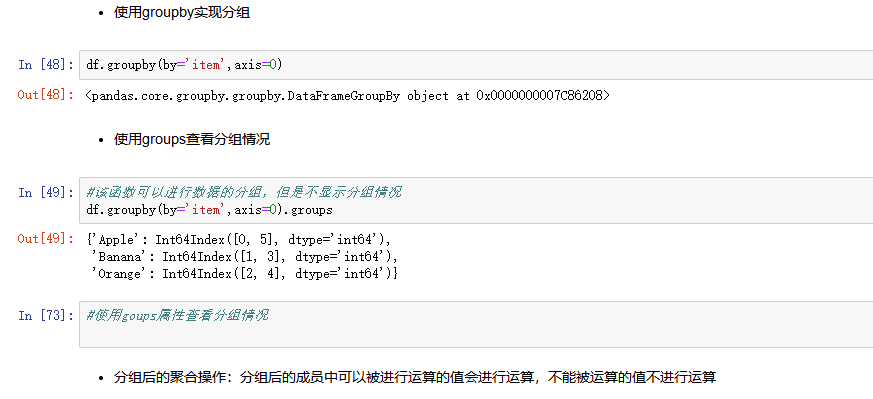
- groupby()函数
- groups属性查看分组情况
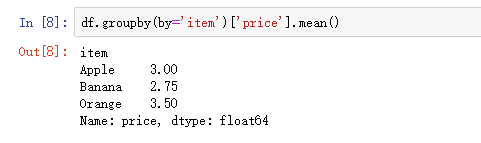
- eg: df.groupby(by='item').groups
分组
from pandas import DataFrame,Series
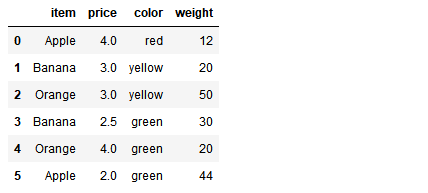
df = DataFrame({'item':['Apple','Banana','Orange','Banana','Orange','Apple'],
'price':[,,,2.5,,],
'color':['red','yellow','yellow','green','green','green'],
'weight':[,,,,,]})
df

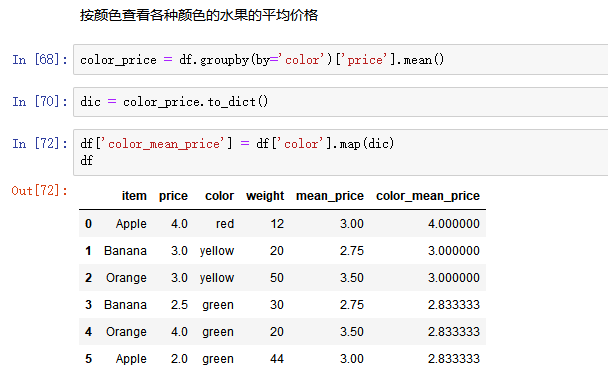
6. 高级数据聚合
使用groupby分组后,也可以使用transform和apply提供自定义函数实现更多的运算
- df.groupby('item')['price'].sum() <==> df.groupby('item')['price'].apply(sum)
- transform和apply都会进行运算,在transform或者apply中传入函数即可
- transform和apply也可以传入一个lambda表达式


5,pandas高级数据处理的更多相关文章
- Pandas之:Pandas高级教程以铁达尼号真实数据为例
Pandas之:Pandas高级教程以铁达尼号真实数据为例 目录 简介 读写文件 DF的选择 选择列数据 选择行数据 同时选择行和列 使用plots作图 使用现有的列创建新的列 进行统计 DF重组 简 ...
- pandas小记:pandas高级功能
http://blog.csdn.net/pipisorry/article/details/53486777 pandas高级功能:面板数据.字符串方法.分类.可视化. 面板数据 {pandas数据 ...
- Pandas缺失数据处理
Pandas缺失数据处理 Pandas用np.nan代表缺失数据 reindex() 可以修改 索引,会返回一个数据的副本: df1 = df.reindex(index=dates[0:4], co ...
- pandas | 使用pandas进行数据处理——DataFrame篇
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是pandas数据处理专题的第二篇文章,我们一起来聊聊pandas当中最重要的数据结构--DataFrame. 上一篇文章当中我们介绍了 ...
- 数据分析06 /pandas高级操作相关案例:人口案例分析、2012美国大选献金项目数据分析
数据分析06 /pandas高级操作相关案例:人口案例分析.2012美国大选献金项目数据分析 目录 数据分析06 /pandas高级操作相关案例:人口案例分析.2012美国大选献金项目数据分析 1. ...
- pandas高级操作
pandas高级操作 import numpy as np import pandas as pd from pandas import DataFrame,Series 替换操作 替换操作可以同步作 ...
- Pandas高级教程之:GroupBy用法
Pandas高级教程之:GroupBy用法 目录 简介 分割数据 多index get_group dropna groups属性 index的层级 group的遍历 聚合操作 通用聚合方法 同时使用 ...
- Python——Pandas 时间序列数据处理
介绍 Pandas 是非常著名的开源数据处理库,我们可以通过它完成对数据集进行快速读取.转换.过滤.分析等一系列操作.同样,Pandas 已经被证明为是非常强大的用于处理时间序列数据的工具.本节将介绍 ...
- pandas | 使用pandas进行数据处理——Series篇
本文始发于个人公众号:TechFlow,原创不易,求个关注 上周我们关于Python中科学计算库Numpy的介绍就结束了,今天我们开始介绍一个新的常用的计算工具库,它就是大名鼎鼎的Pandas. Pa ...
随机推荐
- maven struts2工程StrutsPrepareAndExecuteFilter cannot be cast to javax.servlet.Filter
maven搭建struts2工程时报错 严重: Exception starting filter struts2java.lang.ClassCastException: org.apache.st ...
- 算法练习-Palindrome Number
判断回文整数 来源 https://leetcode.com/problems/palindrome-number/ 要求 判断一个整数是不是回文数,尽量减少内存暂用. 思路 可能的情况: 负数的应当 ...
- MVC框架的实现
现在web开发基本都是MVC的架构了,struts.springMvc 等等.其中一个重要的功能就是将客户发起的请求,分发至我们定义的Action里面的方法之中. 闲暇之余,我也做了一个类似于spri ...
- 笨办法学Python(二十三)
习题 23: 读代码 上一周你应该已经牢记了你的符号列表.现在你需要将这些运用起来,再花一周的时间,在网上阅读代码.这个任务初看会觉得很艰巨.我将直接把你丢到深水区呆几天,让你竭尽全力去读懂实实在在的 ...
- ubuntu linux查看cpu信息
$ cat /proc/cpuinfo CPU核心数量 $ grep -c processor /proc/cpuinfo
- 如何用代码填充S/4HANA销售订单行项目的数量字段
我的任务是用代码生成S/4HANA销售订单(Sales Order)的行项目,并且填充对应的quantity(数量)值. 最开始我用了下面的代码,把quantity的值写入item字段target_q ...
- ssh key一键自动化生成公钥私钥,并自动分发上百服务器免密码交互
题记:由于工作需要管理大量服务器,所以需要配公钥实现免密登录. ssh批量分发可以一键执行这个操作,但是使用ssh分发服务还需要对各个服务器进行.ssh/id_dsa.pub公钥上传,密码验证.所以需 ...
- service 入门
https://www.cnblogs.com/keguangqiang/p/3663086.html#undefined
- android ndk中使用gprof
1.下载gprof支持库 下载地址: http://code.google.com/p/android-ndk-profiler/ 2.代码上的修改添加 在初始化时: monstartup(" ...
- 【洛谷P1063】NOIP2006能量项链
能量项链 https://www.luogu.org/problemnew/show/P1063 好像比合并石子更水.. 区间动规,f[l][r]表示合并区间l~r的最大能量 按区间长度dp 枚举中间 ...