wordCount的执行流程
我们对于wordCount的这个流程,在清晰不过了,不过我们在使用spark以及hadoop本身的mapReduce的时候,我们是否理解其中的原理呢,今天我们就来介绍一下wordCount的执行原理,
1.首先我们都会这样子执行(wordCount执行在hadoop中)
val rdd = sc.textFile("hdfs://weekday01:9000/wc").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
rdd.saveAsTextFile("hdfs://weekday01:9000/out")
如果我们此时想看依赖的关系的话,我们可以这样操作
rdd.toDebugString(执行完这一步操作之后,你就可以看到你在hadoop中执行wordCount的这个过程,中间到底生成了
多少个rdd)
2.rdd与rdd的一些依赖关系
其实在我们每一次生成rdd的时候,都是由于后面的rdd要依赖前面的rdd
3.Lineage(血统)
RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage记录下来,以便恢复丢失
的分区,
此时rdd不会记录这个血统中的各个rdd的具体的值是多少。RDD的Lineage会记录RDD的元数据信息和转换行为,
当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区
4.内部实现细节
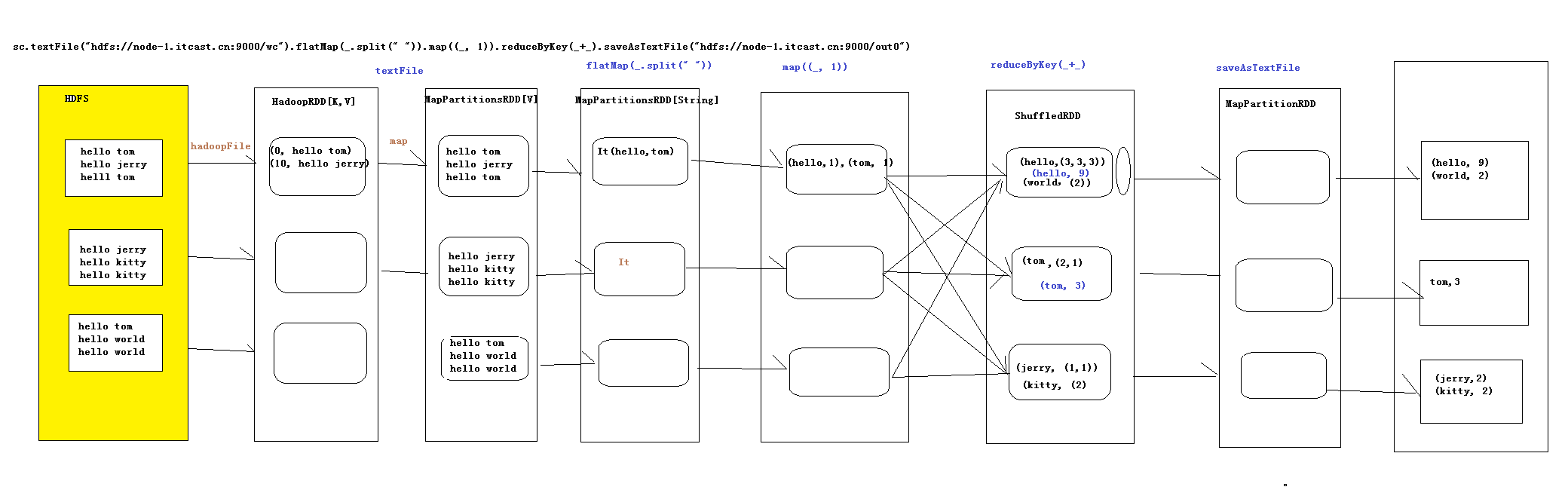
1.textFile会产生两个RDD,1.HadoopRDD,为什么第一个是HadoopRDD,因为我们需要在hadoop里面读取数据,
读取数据的时候是以(key,value)的形式读取数据,其中的可以是偏移量,而value是一行的数据,
2.MapPartitionsRDD,以为我们调用了map方法,而这其中的map的作用是把key取消掉了,从而我们把value取出来
2.xxx.flatMap,则这个产生一个RDD,即MapPartionsRDD,
3.map((_,1)),这个是读取每一行的数据,然后在对每一行进行操作,然后在生成一个MapPartitionsRDD,
经过这个RDD之后,这个里面装的都是(key,value)类型的数据
4.reduceByKey,这个里面new了一个ShuffleRDD,要进行聚合,这个会经历两次聚合,第一聚合是在这个分区里面,
当聚合完成之后,从上游拉下来,在进行总体的聚合,这就是所谓的先分区,在总体
5..saveAsTextFile(path:String),因为这个的操作是往hdfs写数据,所以我们需要拿到hdfs的流,不过如果我们用map的话,
就相当于我的每一条数据我都会拿一个流,这样浪费资源,所以此时的我,使用的是mapPartition(),则此时是拿取一个分区里
面的数据,我们拿一个流,把这一个分区的数据都写进去
综上所述,一共产生了6个RDD
/**
* Created by root on 2016/5/14.
*/
object WordCount {
def main(args: Array[String]) {
//非常重要,是通向Spark集群的入口
val conf = new SparkConf().setAppName("WC")
.setJars(Array("C:\\HelloSpark\\target\\hello-spark-1.0.jar"))
.setMaster("spark://node-1.itcast.cn:7077")
val sc = new SparkContext(conf) //textFile会产生两个RDD:HadoopRDD -> MapPartitinsRDD
sc.textFile(args()).cache()
// 产生一个RDD :MapPartitinsRDD
.flatMap(_.split(" "))
//产生一个RDD MapPartitionsRDD
.map((_, ))
//产生一个RDD ShuffledRDD
.reduceByKey(_+_)
//产生一个RDD: mapPartitions
.saveAsTextFile(args())
sc.stop()
}
}
流程图
wordCount的执行流程的更多相关文章
- MapReduce执行流程及程序编写
MapReduce 一种分布式计算模型,解决海量数据的计算问题,MapReduce将计算过程抽象成两个函数 Map(映射):对一些独立元素(拆分后的小块)组成的列表的每一个元素进行指定的操作,可以高度 ...
- 追源索骥:透过源码看懂Flink核心框架的执行流程
li,ol.inline>li{display:inline-block;padding-right:5px;padding-left:5px}dl{margin-bottom:20px}dt, ...
- 透过源码看懂Flink核心框架的执行流程
前言 Flink是大数据处理领域最近很火的一个开源的分布式.高性能的流式处理框架,其对数据的处理可以达到毫秒级别.本文以一个来自官网的WordCount例子为引,全面阐述flink的核心架构及执行流程 ...
- 大数据学习day23-----spark06--------1. Spark执行流程(知识补充:RDD的依赖关系)2. Repartition和coalesce算子的区别 3.触发多次actions时,速度不一样 4. RDD的深入理解(错误例子,RDD数据是如何获取的)5 购物的相关计算
1. Spark执行流程 知识补充:RDD的依赖关系 RDD的依赖关系分为两类:窄依赖(Narrow Dependency)和宽依赖(Shuffle Dependency) (1)窄依赖 窄依赖指的是 ...
- 步步深入:MySQL架构总览->查询执行流程->SQL解析顺序
前言: 一直是想知道一条SQL语句是怎么被执行的,它执行的顺序是怎样的,然后查看总结各方资料,就有了下面这一篇博文了. 本文将从MySQL总体架构--->查询执行流程--->语句执行顺序来 ...
- 第二天 ci执行流程
第二天 ci执行流程 welcome 页面 this this->load 单入口框架index.php 两个文件夹 system application定义 定义常亮路径 载入 codeign ...
- 轻量级前端MVVM框架avalon - 执行流程2
接上一章 执行流程1 在这一大堆扫描绑定方法中应该会哪些实现? 首先我们看avalon能帮你做什么? 数据填充,比如表单的一些初始值,切换卡的各个面板的内容({{xxx}},{{xxx|html}}, ...
- [Java编程思想-学习笔记]第4章 控制执行流程
4.1 return 关键字return有两方面的用途:一方面指定一个方法结束时返回一个值:一方面强行在return位置结束整个方法,如下所示: char test(int score) { if ...
- ThinkPHP2.2框架执行流程图,ThinkPHP控制器的执行流程
ThinkPHP2.2框架执行原理.流程图在线手册 ThinkPHP控制器的执行流程 对用户的第一次URL访问 http://<serverIp>/My/index.php/Index/s ...
随机推荐
- php的yii框架开发总结4
用户验证的实现:/protected/components/UserIdentity.php 修改:function authenticate()函数中的语句 public function auth ...
- 笨办法学Python(五)
习题 5: 更多的变量和打印 我们现在要键入更多的变量并且把它们打印出来.这次我们将使用一个叫“格式化字符串(format string)”的东西. 每一次你使用 " 把一些文本引用起来,你 ...
- simotion读写CF卡,保存/读取变量
simotion读写CF卡功能 1 使用西门子的Simotion运动控制器时,有时需要用到 读/写 CF卡的功能.主要来自以下几个方面的需求. 1)用户数据量较大,可保持(retain)存储区的容量不 ...
- [转载]互联网 免费的WebService接口
股票行情数据 WEB 服务(支持香港.深圳.上海基金.债券和股票:支持多股票同时查询) Endpoint: http://webservice.webxml.com.cn/WebServices/St ...
- Linux MySQL单实例源码编译安装5.6
cmake软件 tar -zxvf cmake-2.8.11.2.tar.gz cd cmake-2.8.11.2 ./bootstrap make make install cd ../ 依赖包 ...
- ABI and ISA
ABI定义了如何使用ISA. ISA定义了机器码的使用规则. http://www.delorie.com/gnu/docs/gmp/gmp_6.html ABI and ISA ABI (Appli ...
- 【洛谷4815】[CCO2014] 狼人游戏(树形DP)
点此看题面 大致题意: 已知有平民和狼人共\(n\)个,每个平民会指控和保护任何人,每个狼人只会指控平民.保护狼人.告诉你\(m\)对指控与保护的关系,求有\(k\)个狼人的方案总数. 树形\(DP\ ...
- CUDA线性内存分配
原文链接 概述:线性存储器可以通过cudaMalloc().cudaMallocPitch()和cudaMalloc3D()分配 1.1D线性内存分配 1 cudaMalloc(void**,int) ...
- LeetCode706. Design HashMap
题目 不使用任何内建的哈希表库设计一个哈希映射 具体地说,你的设计应该包含以下的功能 put(key, value):向哈希映射中插入(键,值)的数值对.如果键对应的值已经存在,更新这个值. get ...
- java通过FreeMarker模板生成Excel文件之.ftl模板制作
关于怎么通过freemarker模板生成excel的文章很多,关键点在于怎么制作模板文件.ftl 网上的办法是: (1)把Excel模板的格式调好,另存为xml文件 (2)新建一个.ftl文件,把xm ...