Python之进程、线程、协程
进程和线程的目的
进程和线程目的是为了:提高执行效率
现代操作系统比如Mac OS X,UNIX,Linux,Windows等,都是支持“多任务”的操作系统。
什么叫“多任务“呢?简单地说,就是操作系统可以同时运行多个任务。打个比方,你一边在用浏览器上网,一边在听MP3,一边在用Word赶作业,这就是多任务,至少同时有3个任务正在运行。还有很多任务悄悄地在后台同时运行着,只是桌面上没有显示而已。
现在,多核CPU已经非常普及了,但是,即使过去的单核CPU,也可以执行多任务。由于CPU执行代码都是顺序执行的,那么,单核CPU是怎么执行多任务的呢?
答案就是操作系统轮流让各个任务交替执行,任务1执行0.01秒,切换到任务2,任务2执行0.01秒,再切换到任务3,执行0.01秒……这样反复执行下去。表面上看,每个任务都是交替执行的,但是,由于CPU的执行速度实在是太快了,我们感觉就像所有任务都在同时执行一样。
真正的并行执行多任务只能在多核CPU上实现,但是,由于任务数量远远多于CPU的核心数量,所以,操作系统也会自动把很多任务轮流调度到每个核心上执行。
对于操作系统来说,一个任务就是一个进程(Process),比如打开一个浏览器就是启动一个浏览器进程,打开一个记事本就启动了一个记事本进程,打开两个记事本就启动了两个记事本进程,打开一个Word就启动了一个Word进程。
有些进程还不止同时干一件事,比如Word,它可以同时进行打字、拼写检查、打印等事情。在一个进程内部,要同时干多件事,就需要同时运行多个“子任务”,我们把进程内的这些“子任务”称为线程(Thread)。
由于每个进程至少要干一件事,所以,一个进程至少有一个线程。当然,像Word这种复杂的进程可以有多个线程,多个线程可以同时执行,多线程的执行方式和多进程是一样的,也是由操作系统在多个线程之间快速切换,让每个线程都短暂地交替运行,看起来就像同时执行一样。当然,真正地同时执行多线程需要多核CPU才可能实现。
我们前面编写的所有的Python程序,都是执行单任务的进程,也就是只有一个线程。如果我们要同时执行多个任务怎么办?
有两种解决方案:
一种是启动多个进程,每个进程虽然只有一个线程,但多个进程可以一块执行多个任务。
还有一种方法是启动一个进程,在一个进程内启动多个线程,这样,多个线程也可以一块执行多个任务。
当然还有第三种方法,就是启动多个进程,每个进程再启动多个线程,这样同时执行的任务就更多了,当然这种模型更复杂,实际很少采用。
总结一下就是,多任务的实现有3种方式:
- 多进程模式;
- 多线程模式;
- 多进程+多线程模式。
同时执行多个任务通常各个任务之间并不是没有关联的,而是需要相互通信和协调,有时,任务1必须暂停等待任务2完成后才能继续执行,有时,任务3和任务4又不能同时执行,所以,多进程和多线程的程序的复杂度要远远高于我们前面写的单进程单线程的程序。
因为复杂度高,调试困难,所以,不是迫不得已,我们也不想编写多任务。但是,有很多时候,没有多任务还真不行。想想在电脑上看电影,就必须由一个线程播放视频,另一个线程播放音频,否则,单线程实现的话就只能先把视频播放完再播放音频,或者先把音频播放完再播放视频,这显然是不行的。
Python既支持多进程,又支持多线程,我们会讨论如何编写这两种多任务程序。
小结
线程是最小的执行单元,而进程由至少一个线程组成。如何调度进程和线程,完全由操作系统决定,程序自己不能决定什么时候执行,执行多长时间。
多进程和多线程的程序涉及到同步、数据共享的问题,编写起来更复杂。
总之一句话,具体案例具体分析。需要根据实际的情况,精准的定位问题的所在,而不会盲目去做方案
线程
概念:线程是应用程序中工作的最小单元,或者又称之为微进程。
组成:它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
阐释:线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。线程可以共享(调用)进程的数据资源
优点:共享内存,IO操作时候,创造并发操作
缺点:"......"(中国文化的博大精深的带引号)
关于多线程
多线程类似于同时执行多个不同程序,多线程运行有如下优点:
- 使用线程可以把占据长时间的程序中的任务放到后台去处理。
- 用户界面可以更加吸引人,这样比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进度条来显示处理的进度
- 程序的运行速度可能加快
- 在一些等待的任务实现上如用户输入、文件读写和网络收发数据等,线程就比较有用了。在这种情况下我们可以释放一些珍贵的资源如内存占用等等。
线程在执行过程中与进程还是有区别的。每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口。但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。
每个线程都有他自己的一组CPU寄存器,称为线程的上下文,该上下文反映了线程上次运行该线程的CPU寄存器的状态。
指令指针和堆栈指针寄存器是线程上下文中两个最重要的寄存器,线程总是在进程得到上下文中运行的,这些地址都用于标志拥有线程的进程地址空间中的内存。
- 线程可以被抢占(中断)。
- 在其他线程正在运行时,线程可以暂时搁置(也称为睡眠) -- 这就是线程的退让。
线程可以分为:
- 内核线程:由操作系统内核创建和撤销。
- 用户线程:不需要内核支持而在用户程序中实现的线程。
Python3 线程中常用的两个模块为:
- _thread
- threading(推荐使用)
thread 模块已被废弃。用户可以使用 threading 模块代替。所以,在 Python3 中不能再使用"thread" 模块。为了兼容性,Python3 将 thread 重命名为 "_thread"。
Python中使用线程有两种方式:函数或者用类来包装线程对象。
Python3 通过两个标准库 _thread 和 threading 提供对线程的支持。
_thread 提供了低级别的、原始的线程以及一个简单的锁,它相比于 threading 模块的功能还是比较有限的。
threading 模块除了包含 _thread 模块中的所有方法外,还提供的其他方法:
- threading.currentThread(): 返回当前的线程变量。
- threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
- threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
除了使用方法外,线程模块同样提供了Thread类来处理线程,Thread类提供了以下方法:
- run(): 用以表示线程活动的方法。
- start():启动线程活动。
- join([time]): 等待至线程中止。这阻塞调用线程直至线程的join() 方法被调用中止-正常退出或者抛出未处理的异常-或者是可选的超时发生。
- setDaemon(True):守护主线程,跟随主线程退(必须要放在start()上方)
- isAlive(): 返回线程是否活动的。
- getName(): 返回线程名。
- setName(): 设置线程名。
看了那么多废话,那么创建线程的方式有俩种,接下来看代码
一,通过调用模块的方式来创建线程(推荐使用)
调用模块创建线程
二,创建类通过继承的方式来创建线程
使用Threading模块创建线程,直接从threading.Thread继承,然后重写__init__方法和run方法:
使用继承创建线程
GIL(全局解释锁)
概念:在同一时刻多个线程中,只有一个线程只能被一个CPU调用
在知道线程的创建方式以及一些方法的使用后,引申一个cpython解释器的一个历史遗留问题,全局GIL锁
因为Python的线程虽然是真正的线程,但解释器执行代码时,有一个GIL锁:Global Interpreter Lock,任何Python线程执行前,必须先获得GIL锁,然后,每执行100条字节码,解释器就自动释放GIL锁,让别的线程有机会执行。这个GIL全局锁实际上把所有线程的执行代码都给上了锁,所以,多线程在Python中只能交替执行,即使100个线程跑在100核CPU上,也只能用到1个核。
当然了,也有通过别的途径提高执行效率,技术的道路上终无止境。
同步锁
多个线程共同对某个数据修改,则可能出现不可预料的结果,为了保证数据的正确性,需要对多个线程进行同步。
使用 Thread 对象的 Lock 和 Rlock 可以实现简单的线程同步。
这两个对象都有 acquire 方法和 release 方法。
对于那些需要每次只允许一个线程操作的数据,可以将其操作放到 acquire 和 release 方法之间。
加锁
线程的死锁和递归锁
在线程间共享多个资源的时候,如果两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁,因为系统判断这部分资源都正在使用,所有这两个线程在无外力作用下将一直等待下去。
解决死锁就可以用递归锁
递归锁
为了支持在同一线程中多次请求同一资源,python提供了“可重入锁”:threading.RLock。RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次acquire。直到一个线程所有的acquire都被release,其他的线程才能获得资源。
信号量(Semaphore):从意义上来讲,也可以称之为一种锁
信号量:指同时开几个线程并发
信号量用来控制线程并发数的,BoundedSemaphore或Semaphore管理一个内置的计数 器,每当调用acquire()时-1,调用release()时+1。
计数器不能小于0,当计数器为 0时,acquire()将阻塞线程至同步锁定状态,直到其他线程调用release()。(类似于停车位的概念)
BoundedSemaphore与Semaphore的唯一区别在于前者将在调用release()时检查计数 器的值是否超过了计数器的初始值,如果超过了将抛出一个异常。
信号量
同步条件(Event)
简单了解
Event对象实现了简单的线程通信机制,它提供了设置信号,清楚信号,等待等用于实现线程间的通信。
1 设置信号
使用Event的set()方法可以设置Event对象内部的信号标志为真。Event对象提供了isSet()方法来判断其内部信号标志的状态。当使用event对象的set()方法后,isSet()方法返回真
2 清除信号
使用Event对象的clear()方法可以清除Event对象内部的信号标志,即将其设为假,当使用Event的clear方法后,isSet()方法返回假
3 等待
Event对象wait的方法只有在内部信号为真的时候才会很快的执行并完成返回。当Event对象的内部信号标志位假时,则wait方法一直等待到其为真时才返回
同步条件
Event内部包含了一个标志位,初始的时候为false。
可以使用使用set()来将其设置为true;
或者使用clear()将其从新设置为false;
可以使用is_set()来检查标志位的状态;
另一个最重要的函数就是wait(timeout=None),用来阻塞当前线程,直到event的内部标志位被设置为true或者timeout超时。如果内部标志位为true则wait()函数理解返回。
多线程利器——队列(queue)
因为列表是不安全的数据结构,所以引申了新的模块——队列
Python 的 queue 模块中提供了同步的、线程安全的队列类,包括FIFO(先入先出)队列Queue,LIFO(后入先出)队列LifoQueue,和优先级队列 PriorityQueue。
这些队列都实现了锁原语,能够在多线程中直接使用,可以使用队列来实现线程间的同步。
queue 模块中的常用方法:
- queue.qsize() 返回队列的大小
- queue.empty() 如果队列为空,返回True,反之False
- queue.full() 如果队列满了,返回True,反之False
- queue.full 与 maxsize 大小对应
- queue.get([block[, timeout]])获取队列,timeout等待时间
- queue.get_nowait() 相当queue.get(False)
- queue.put(item) 写入队列,timeout等待时间
- queue.put_nowait(item) 相当Queue.put(item, False)
- queue.task_done() 在完成一项工作之后,queue.task_done()函数向任务已经完成的队列发送一个信号
- queue.join() 接收信号,继续执行queue.join()下面的代码
生产者与消费者模型
基于队列(queue)引出的一种思想
在这个现实社会中,生活中处处充满了生产和消费.
什么是生产者消费者模型
在 工作中,可能会碰到这样一种情况:某个模块负责产生数据,这些数据由另一个模块来负责处理(此处的模块是广义的,可以是类、函数、线程、进程等)。产生数据的模块,就形象地称为生产者;而处理数据的模块,就称为消费者。在生产者与消费者之间在加个缓冲区,形象的称之为仓库,生产者负责往仓库了进商 品,而消费者负责从仓库里拿商品,这就构成了生产者消费者模型。结构图如下
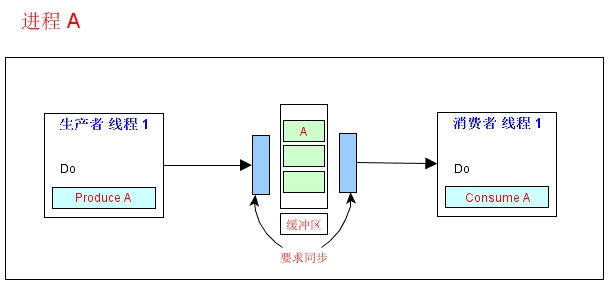
生产者消费者模型的优点
1、解耦
假设生产者和消费者分别是两个类。如果让生产者直接调用消费者的某个方法,那么生产者对于消费者就会产生依赖(也就是耦合)。将来如果消费者的代码发生变化, 可能会影响到生产者。而如果两者都依赖于某个缓冲区,两者之间不直接依赖,耦合也就相应降低了。
举个例子,我们去邮局投递信件,如果不使用邮筒(也就是缓冲区),你必须得把信直接交给邮递员。有同学会说,直接给邮递员不是挺简单的嘛?其实不简单,你必须 得认识谁是邮递员,才能把信给他(光凭身上穿的制服,万一有人假冒,就惨了)。这就产生和你和邮递员之间的依赖(相当于生产者和消费者的强耦合)。万一哪天邮递员换人了,你还要重新认识一下(相当于消费者变化导致修改生产者代码)。而邮筒相对来说比较固定,你依赖它的成本就比较低(相当于和缓冲区之间的弱耦合)。
2、支持并发
由于生产者与消费者是两个独立的并发体,他们之间是用缓冲区作为桥梁连接,生产者只需要往缓冲区里丢数据,就可以继续生产下一个数据,而消费者只需要从缓冲区了拿数据即可,这样就不会因为彼此的处理速度而发生阻塞。
接上面的例子,如果我们不使用邮筒,我们就得在邮局等邮递员,直到他回来,我们把信件交给他,这期间我们啥事儿都不能干(也就是生产者阻塞),或者邮递员得挨家挨户问,谁要寄信(相当于消费者轮询)。
3、支持忙闲不均
缓冲区还有另一个好处。如果制造数据的速度时快时慢,缓冲区的好处就体现出来了。当数据制造快的时候,消费者来不及处理,未处理的数据可以暂时存在缓冲区中。 等生产者的制造速度慢下来,消费者再慢慢处理掉。
为了充分复用,再拿寄信的例子来说事。假设邮递员一次只能带走1000封信。万一某次碰上情人节(也可能是圣诞节)送贺卡,需要寄出去的信超过1000封,这时 候邮筒这个缓冲区就派上用场了。邮递员把来不及带走的信暂存在邮筒中,等下次过来 时再拿走
对生产者与消费者模型的阐释就进行到这里,用代码实现生产者与消费者模型
包子工厂
进程
概念:就是一个程序在一个数据集上的一次动态执行过程(本质上来讲,就是运行中的程序(代指运行过程),程序不运行就不是进程) 抽象概念
组成:
1、程序:我们编写的程序用来描述进程要完成哪些功能以及如何完成
2、数据集:数据集则是程序在执行过程中所需要使用的资源
3、进程控制块:进程控制块用来记录进程的外部特征,描述进程的执行变化过程,系统可以利用它来控制和管理进程,它是系统感知进程存在的唯一标志。
阐释:进程与进程之间都占用的是独立的内存块,它们彼此之间的数据也是独立的
优点:同时利用多个CPU,能够同时进行多个操作
缺点:耗费资源(需要重新开辟内存空间)
构造方法:
Process([group [, target [, name [, args [, kwargs]]]]])
group: 线程组,目前还没有实现,库引用中提示必须是None;
target: 要执行的方法;
name: 进程名;
args/kwargs: 要传入方法的参数。
实例方法:
is_alive():返回进程是否在运行。
join([timeout]):阻塞当前上下文环境的进程程,直到调用此方法的进程终止或到达指定的timeout(可选参数)。
start():进程准备就绪,等待CPU调度
run():strat()调用run方法,如果实例进程时未制定传入target,这star执行t默认run()方法。
terminate():不管任务是否完成,立即停止工作进程
属性:
daemon:和线程的setDeamon功能一样
name:进程名字。
pid:进程号。
创建进程的方式有俩种
通过调用模块的方法创建进程
# 进程模块
import multiprocessing
import time
def f1():
start = time.time()
sum = 0
for n in range(100000000):
sum += n
print(sum)
print("data:{}".format(time.time() - start))
if __name__ == '__main__': # windows在调用进程的时候,必须加这句话,否则会报错
li = []
p1 = multiprocessing.Process(target=f1)
li.append(p1)
p2 = multiprocessing.Process(target=f1)
li.append(p2)
for p in li:
p.start()
for i in li:
i.join()
print("ending...")
通过调用模块的方法
通过继承的方法创建进程
import multiprocessing
class Process(multiprocessing.Process):
def run(self):
sum = 0
for n in range(100000000):
sum += n
print(sum)
li = []
for i in range(2):
p = Process()
li.append(p)
if __name__ == '__main__':
for p in li:
p.start()
for i in li:
i.join()
print("ending")
通过继承的方法
进程之间的通信
1.使用队列(Queue)
import multiprocessing
import time
# 多进程队列通信
def func(q): # q并不是资源共享而得到的
time.sleep(1)
q.put(123)
q.put('oldwang')
print(id(q))
# time.sleep(1)
if __name__ == '__main__':
q = multiprocessing.Queue()
p_list = []
for p in range(2):
p = multiprocessing.Process(target=func, args=(q,))
p_list.append(p)
p.start()
while True:
print(q.get(),id(q))
[p.join() for p in p_list]
print('ending.....')
使用Queue进行通信
2.使用管道(Pipi)
import multiprocessing
import time
#进程间管道通信
def func(conn):
conn.send(123)
time.sleep(1)
data = conn.recv()
print(data)
if __name__ == '__main__':
p_list = []
parent_pipe, child_pipe = multiprocessing.Pipe()
p = multiprocessing.Process(target=func, args=(child_pipe,))
p_list.append(p)
p.start()
data = parent_pipe.recv()
print(data)
parent_pipe.send('hahaha')
使用管道(Pipe)
3.使用Manager
from multiprocessing import Process, Manager
def f(d,l,n):
d["name"] = "alex"
d[n] = "
l.append(n)
if __name__ == '__main__':
with Manager() as manager: # 类似于文件操作的with open(...)
d = manager.dict()
l = manager.list(range(5))
print(d,l)
p_list = []
for n in range(10):
p = Process(target=f,args=(d, l, n))
p.start()
p_list.append(p)
for p in p_list:
p.join() # 这儿的join必须加
print(d)
print(l)
# 关于数据共享的进程等待的问题,鄙人作出一些自己的理解
# 多核CPU的情况下,进程间是可以实现并行的,当然每个核处理的速度又有极其细微的差异性,速度处理稍慢些的进程在还在对数据进行处理的候,同时又想要得到数据了,自然会出现错误,所以要等待进程处理完这份数据的时候再进行操作
进程数据共享(Manager)
使用Manager
上述实现了进程间的数据通信,那么进程可以达到数据共享么?Sure。
Pipe、Queue 都有一定数据共享的功能,但是他们会堵塞进程, Manager不会堵塞进程, 而且都是多进程安全的。
A manager object returned by Manager() controls a server process which holds Python objects and allows other processes to manipulate them using proxies.
A manager returned by Manager() will support types list, dict, Namespace, Lock, RLock, Semaphore, BoundedSemaphore, Condition, Event, Barrier, Queue, Value and Array.
由上述英文我们了解到,通过Manager()可以实现进程上的数据共享,并且支持的类型也由很多
进程同步(同步锁)
# 为什么引申进程同步
# 数据的一致性
import time
from multiprocessing import Lock, Process
def run(i, lock):
with lock: # 自动获得锁和释放锁
time.sleep(1)
print(i)
if __name__ == '__main__':
lock = Lock()
for i in range(10):
p = Process(target=run,args=(i,lock,))
p.start()
进程同步
进程同步(Lock)
Semaphore
Semaphore 和 Lock 稍有不同,Semaphore 相当于 N 把锁,获取其中一把就可以执行了。 信号量的总数 N 在构造时传入,s = Semaphore(N)。 和 Lock 一样,如果信号量为0,则进程堵塞,直到信号大于0
进程池
如果有50个任务要去执行,CPU只有4核,那创建50个进程完成,其实大可不必,徒增管理开销。如果只想创建4个进程,让它们轮流替完成任务,不用自己去管理具体的进程的创建销毁,那 Pool 是非常有用的。
Pool 是进程池,进程池能够管理一定的进程,当有空闲进程时,则利用空闲进程完成任务,直到所有任务完成为止
关于进程池的API用法(并不是只有俩个哦)
apply (每个任务是排队进行,类似于串行失去意义)
apply_async (任务都是并发进行,并且可以设置回调函数) 进程的并发其实可以称之为并行了,可以利用到多核CPU
import multiprocessing
import time
def func(i):
time.sleep(1)
print('hello %s',i)
#回调函数Bar()在主进程中执行
def Bar(args):
print('我是回调函数Bar')
if __name__ == '__main__':
pool = multiprocessing.Pool(5) # 创建进程池,限定进程最大量为5
for i in range(100):
pool.apply_async(func=func, args=(i,), callback=Bar) # 创建进程
pool.close() #先关闭进程池
pool.join() #在进行join()操作
print('ending...')
# 看看 Pool 的执行流程,有三个阶段。第一、一个进程池接收很多任务,然后分开执行任务;第二、不再接收任务了;第三、等所有任务完成了,回家,不干了。
# 这就是上面的方法,close 停止接收新的任务,如果还有任务来,就会抛出异常。 join 是等待所有任务完成。 join 必须要在 close 之后调用,否则会抛出异常。terminate 非正常终止,内存不够用时,垃圾回收器调用的就是这个方法
进程池
协程
概念:协程,又称微线程,纤程。英文名Coroutine。 是非抢占式的程序 主要也是解决I/O操作的
协程的概念很早就提出来了,但直到最近几年才在某些语言(如Lua)中得到广泛应用。
子程序,或者称为函数,在所有语言中都是层级调用,比如A调用B,B在执行过程中又调用了C,C执行完毕返回,B执行完毕返回,最后是A执行完毕。
所以子程序调用是通过栈实现的,一个线程就是执行一个子程序。
子程序调用总是一个入口,一次返回,调用顺序是明确的。而协程的调用和子程序不同。
协程看上去也是子程序,但执行过程中,在子程序内部可中断,然后转而执行别的子程序,在适当的时候再返回来接着执行。
优点:
优点1: 协程极高的执行效率。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。
优点2: 不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
因为协程是一个线程执行,那怎么利用多核CPU呢?最简单的方法是多进程+协程,既充分利用多核,又充分发挥协程的高效率,可获得极高的性能。
import time
import queue
def consumer(name):
print("--->ready to eat baozi........")
while True:
new_baozi = yield # yield实现上下文切换,传包子进来
print("[%s] is eating baozi %s" % (name,new_baozi))
#time.sleep(1)
def producer():
r = con.__next__()
r = con2.__next__()
n = 0
while 1:
time.sleep(1)
print("\033[32;1m[producer]\033[0m is making baozi %s and %s" %(n,n+1) )
con.send(n) # 发送告诉他有包子了
con2.send(n+1)
n +=2
if __name__ == '__main__':
con = consumer("c1")
con2 = consumer("c2")
producer(
使用yield简单实现协程
greenlet是一个用C实现的协程模块,相比与python自带的yield,它可以使你在任意函数之间随意切换,而不需把这个函数先声明为generator
from greenlet import greenlet
def test1():
print(12)
gr2.switch()
print(34)
gr2.switch()
def test2():
print(56)
gr1.switch()
print(78)
gr1 = greenlet(test1)
gr2 = greenlet(test2)
gr1.switch()
gr2.switch()
greenlet
Gevent
import gevent
import requests,time
start_time = time.time()
def get_url(url):
print("get: {}".format(url))
resp = requests.get(url)
data = resp.text
print(len(data),url)
# get_url('https://www.python.org/')
# get_url('https://www.yahoo.com/')
# get_url('https://www.baidu.com/')
# get_url('https://www.sina.com.cn/')
# get_url('http://www.xiaohuar.com/')
gevent.joinall(
[
gevent.spawn(get_url, 'https://www.python.org/'),
gevent.spawn(get_url, 'https://www.yahoo.com/'),
gevent.spawn(get_url, 'https://www.baidu.com/'),
gevent.spawn(get_url, 'https://www.sina.com.cn/'),
gevent.spawn(get_url,'http://www.xiaohuar.com/')
]
)
print(time.time()-start_time)
Gevent
协程的优势:
1、没有切换的消耗
2、没有锁的概念
有一个问题:能用多核吗?
答:可以采用多进程+协程,是一个很好的解决并发的方案
并行 & 并发 同步 & 异步
并发 : 是指系统具有处理多个任务(动作)的能力
并行 : 是指系统具有 同时 处理多个任务(动作)的能力
并行是并发的一个子集
同步 与 异步
同步: 当进程执行到一个IO(等待外部数据)的时候,------等:同步
异步: ------不等:一直等到数据接收成功,再回来处理
任务: IO密集型
计算密集型
对于IO密集型的任务 : python的多线程的是有意义的
可以采用多进程+协程
对于计算密集型的任务: python的多线程就不推荐,python就不适用了。当然了可以用进程,也可以改C
用户态 & 内核态
内核态与用户态指的是计算机的两种工作状态
即cpu的两种工作状态
(现在的操作系统都是分时操作系统,分时的根源来自于硬件层面操作系统内核占用的内存与应用程序占用的内存彼此之间隔离)
cpu通过psw(程序状态寄存器)中的一个2进制位来控制cpu本身的工作状态,即内核态与用户态。
内核态:操作系统内核只能运作于cpu的内核态,这种状态意味着可以执行cpu所有的指令,可以执行cpu所有的指令,这也意味着对计算机硬件资源有着完全的控制权限,并且可以控制cpu工作状态由内核态转成用户态。
用户态:应用程序只能运作于cpu的用户态,这种状态意味着只能执行cpu所有的指令的一小部分(或者称为所有指令的一个子集),这一小部分指令对计算机的硬件资源没有访问权限(比如I/O),并且不能控制由用户态转成内核态
用户空间和内核空间
现在操作系统都是采用虚拟存储器,那么对32位操作系统而言,它的寻址空间(虚拟存储空间)为4G(2的32次方)。
操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的所有权限。
为了保证用户进程不能直接操作内核(kernel),保证内核的安全,操心系统将虚拟空间划分为两部分,一部分为内核空间,一部分为用户空间。
针对linux操作系统而言,将最高的1G字节(从虚拟地址0xC0000000到0xFFFFFFFF),供内核使用,称为内核空间,而将较低的3G字节(从虚拟地址0x00000000到0xBFFFFFFF),供各个进程使用,称为用户空间
Python之进程、线程、协程的更多相关文章
- python的进程/线程/协程
1.python的多线程 多线程就是在同一时刻执行多个不同的程序,然而python中的多线程并不能真正的实现并行,这是由于cpython解释器中的GIL(全局解释器锁)捣的鬼,这把锁保证了同一时刻只有 ...
- python进阶——进程/线程/协程
1 python线程 python中Threading模块用于提供线程相关的操作,线程是应用程序中执行的最小单元. #!/usr/bin/env python # -*- coding:utf-8 - ...
- Python中进程线程协程小结
进程与线程的概念 进程 程序仅仅只是一堆代码而已,而进程指的是程序的运行过程.需要强调的是:同一个程序执行两次,那也是两个进程. 进程:资源管理单位(容器). 线程:最小执行单位,管理线程的是进程. ...
- Python并发编程系列之常用概念剖析:并行 串行 并发 同步 异步 阻塞 非阻塞 进程 线程 协程
1 引言 并发.并行.串行.同步.异步.阻塞.非阻塞.进程.线程.协程是并发编程中的常见概念,相似却也有却不尽相同,令人头痛,这一篇博文中我们来区分一下这些概念. 2 并发与并行 在解释并发与并行之前 ...
- Python 进程线程协程 GIL 闭包 与高阶函数(五)
Python 进程线程协程 GIL 闭包 与高阶函数(五) 1 GIL线程全局锁 线程全局锁(Global Interpreter Lock),即Python为了保证线程安全而采取的独立线程运行的 ...
- python自动化开发学习 进程, 线程, 协程
python自动化开发学习 进程, 线程, 协程 前言 在过去单核CPU也可以执行多任务,操作系统轮流让各个任务交替执行,任务1执行0.01秒,切换任务2,任务2执行0.01秒,在切换到任务3,这 ...
- 进程&线程&协程
进程 一.基本概念 进程是系统资源分配的最小单位, 程序隔离的边界系统由一个个进程(程序)组成.一般情况下,包括文本区域(text region).数据区域(data region)和堆栈(stac ...
- 多道技术 进程 线程 协程 GIL锁 同步异步 高并发的解决方案 生产者消费者模型
本文基本内容 多道技术 进程 线程 协程 并发 多线程 多进程 线程池 进程池 GIL锁 互斥锁 网络IO 同步 异步等 实现高并发的几种方式 协程:单线程实现并发 一 多道技术 产生背景 所有程序串 ...
- python进程/线程/协程
一 背景知识 顾名思义,进程即正在执行的一个过程.进程是对正在运行程序的一个抽象. 进程的概念起源于操作系统,是操作系统最核心的概念,也是操作系统提供的最古老也是最重要的抽象概念之一.操作系统的其他所 ...
- python-socket和进程线程协程(代码展示)
socket # 一.socket # TCP服务端 import socket # 导入socket tcp_sk = socket.socket() # 实例化一个服务器对象 tcp_sk.bin ...
随机推荐
- CRUD全栈式编程架构之MVC的扩展设计
MVC执行流程 路由的扩展 我理解的路由作用有以下几个 Seo优化,用“/”分开的url爬虫更爱吃 物理和逻辑文件分离,url不再按照文件路径映射 Controller,Action的选择 MVC路由 ...
- Can Microsoft’s exFAT file system bridge the gap between OSes?
转自:http://arstechnica.com/information-technology/2013/06/review-is-microsofts-new-data-sharing-syste ...
- mysql常用命令添加外键主键约束存储过程索引
数据库连接 mysql -u root -p123456 查看表 show databases 创建数据库设置编码 create table books character set utf8; 创建用 ...
- CSS font-size字体大小样式属性
设置字体大小CSS单词与语法 基本语法结构: .divcss5{font-size:12px;}设置了文字大小为12px像素Font-size+字体大小数值+单位 单词:font-size语法:fon ...
- 前端HTML基础
1.0开发工具介绍 sublime的使用技巧链接 HTML特殊符号表 1.1 html概念 超文本标记语言(Hypertext Markup Language),属于一种描述性的标记语言(markup ...
- javascript入门笔记9-认识DOM
认识DOM 文档对象模型DOM(Document Object Model)定义访问和处理HTML文档的标准方法.DOM 将HTML文档呈现为带有元素.属性和文本的树结构(节点树). 将HTML代码分 ...
- 【例题收藏】◇例题·II◇ Berland and the Shortest Paths
◇例题·II◇ Berland and the Shortest Paths 题目来源:Codeforce 1005F +传送门+ ◆ 简单题意 给定一个n个点.m条边的无向图.保证图是连通的,且m≥ ...
- 解决php文字及图片显示乱码的问题
我们在学习PHP的过程中,想必有不少新手朋友们都遇到过乱码的问题,解决乱码问题不仅是小白们必须掌握的基础知识点,也是最为常见的PHP面试题之一.下面就结合简单代码示例给大家总结介绍下,PHP遇到乱码时 ...
- 用ajax获取淘宝关键字接口
可定需要查看淘宝界面的结构,按F12查看网页,此时先清除一下网页中的数据,让Network制空,随后在输入框中输入新的内容,比如钱包,数据中会出现新的数据.点击及查看蓝色方框中的内容 点击之后,你可以 ...
- js获取url参数方法
function GetQueryString(name) { var reg = new RegExp("(^|&)" + name + "=([^&] ...