EM最大期望算法
【简介】
em算法,指的是最大期望算法(Expectation Maximization Algorithm,又译期望最大化算法),是一种迭代算法,在统计学中被用于寻找,依赖于不可观察的隐性变量的概率模型中,参数的最大似然估计。
EM 算法是 Dempster,Laind,Rubin 于 1977 年提出的求参数极大似然估计的一种方法,它可以从非完整数据集中对参数进行 MLE 估计,是一种非常简单实用的学习算法。这种方法可以广泛地应用于处理缺损数据,截尾数据,带有噪声等所谓的不完全数据。可以有一些比较形象的比喻说法把这个算法讲清楚。比如说食堂的大师傅炒了一份菜,要等分成两份给两个人吃,显然没有必要拿来天平一点的精确的去称分量,最简单的办法是先随意的把菜分到两个碗中,然后观察是否一样多,把比较多的那一份取出一点放到另一个碗中,这个过程一直迭代地执行下去,直到大家看不出两个碗所容纳的菜有什么分量上的不同为止。
EM算法就是这样,假设我们估计知道A和B两个参数,在开始状态下二者都是未知的,并且知道了A的信息就可以得到B的信息,反过来知道了B也就得到了A。可以考虑首先赋予A某种初值,以此得到B的估计值,然后从B的当前值出发,重新估计A的取值,这个过程一直持续到收敛为止(百度百科)。
【算法】
1、计算期望(E),利用概率模型参数的现有估计值,计算隐藏变量的期望;
2、最大化(M),利用E 步上求得的隐藏变量的期望,对参数模型进行最大似然估计;
3、M 步上找到的参数估计值被用于下一个 E 步计算中,这个过程不断交替进行。
【代码】
import math;
import copy;
import numpy as np;
import matplotlib.pyplot as plt; isdebug = True # 指定k个高斯分布參数。这里指定k=2。注意2个高斯分布具有同样均方差Sigma,分别为M1,M2。
def getdataSet(Sigma,M1,M2,k,N):
#创建长度为N的数据
dataSet = np.zeros((1,N))
for i in range(N):
#为数据赋值,并随机分开两组数据
if np.random.random(1) > 0.333:
dataSet[0,i] = np.random.normal()*Sigma + M1
else:
dataSet[0,i] = np.random.normal()*Sigma + M2
if isdebug:
print ("dataSet:",dataSet)
return dataSet # E算法:计算期望E[zij]
def E(Sigma,dataSet,Miu,k,N):
#创建概率数组
Exp = np.zeros((N,k))
Num = np.zeros(k)
for i in range(N):
Sum = 0
for j in range(k):
#求数据的高斯分布概率
Num[j] = math.exp((-1/(2*(float(Sigma**2))))*(float(dataSet[0,i]-Miu[j]))**2)
Sum += Num[j]
for j in range(k):
#求没类数据在各类中的占比,即隐藏变量Z
Exp[i,j] = Num[j] / Sum
if isdebug:
print ("Exp:",Exp) return Exp # M算法:最大化E[zij]的參数Miu
def M(Exp,dataSet,k,N):
Miu = np.random.random(k)
for j in range(k):
Num = 0
Sum = 0
for i in range(N):
Num += Exp[i,j]*dataSet[0,i]
Sum += Exp[i,j]
Miu[j] = Num / Sum
if isdebug:
print("Miu:",Miu)
return Miu #初始参数
Sigma = 6
M1 = -20
M2 = 20
k=2
N=0xffff #65535
Iter=0xff
EPS =1e-6 #随机初始数据
dataSet=getdataSet(Sigma,M1,M2,k,N) #初始先假设一个E[zij]
Miu = np.random.random(2)
# 算法迭代
for i in range(Iter):
oldMiu = copy.deepcopy(Miu)
#E
Exp = E(Sigma,dataSet,Miu,k,N)
#M
Miu = M(Exp,dataSet,k,N)
#如果达到精度Epsilon停止迭代
if sum(abs(Miu-oldMiu)) < EPS:
if isdebug:
print ("Iter:",i)
break plt.figure('emmmmm',figsize=(12, 6))
plt.hist(dataSet[0,:],100)
plt.xticks(fontsize=10, color="darkorange")
plt.yticks(fontsize=10, color="darkorange")
plt.show()
【结果】
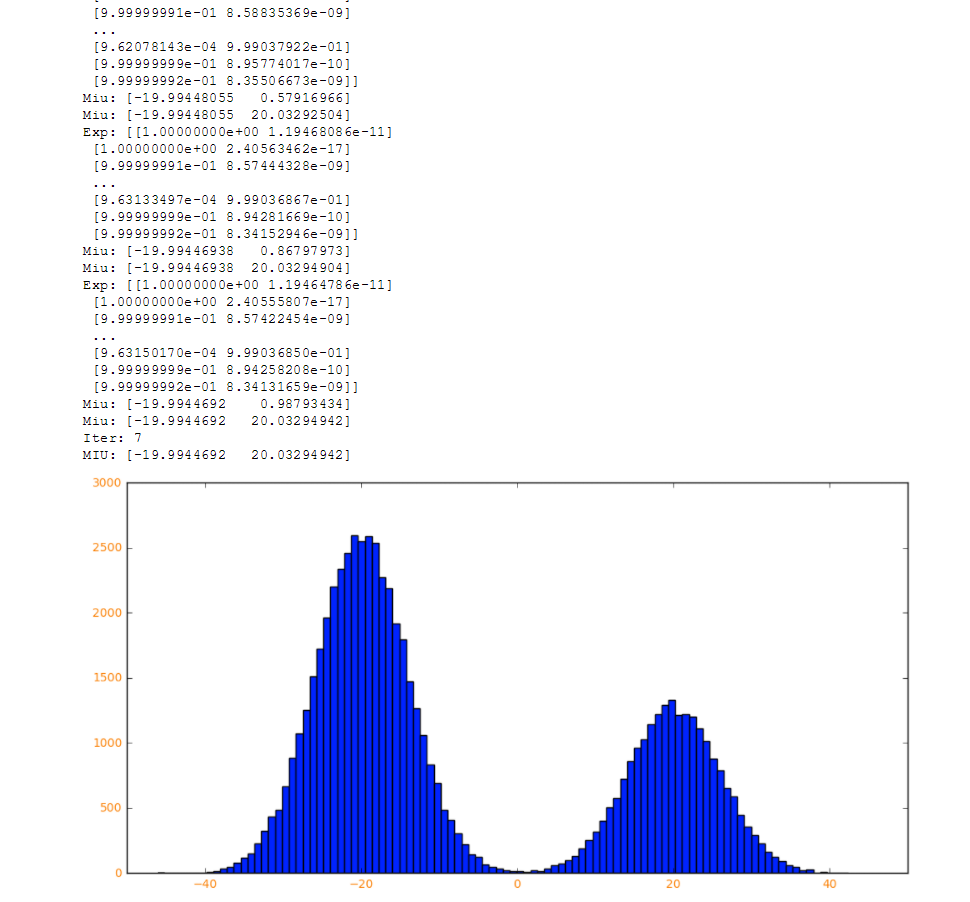
【参考文献】
https://blog.csdn.net/sm9sun/article/details/78745265
https://www.cnblogs.com/cxchanpin/p/6731780.html
------------------------------------------华丽的分割线------------------------------------------------------
有兴趣的同学可以关注公总号:RaoRao1994

EM最大期望算法的更多相关文章
- EM最大期望算法-走读
打算抽时间走读一些算法,尽量通俗的记录下面,希望帮助需要的同学. overview: 基本思想: 通过初始化参数P1,P2,推断出隐变量Z的概率分布(E步): 通过隐变量Z的概 ...
- 【机器学习】EM最大期望算法
EM, ExpectationMaximization Algorithm, 期望最大化算法.一种迭代算法,用于含有隐变量(hidden variable)的概率参数模型的最大似然估计或极大后验概率估 ...
- MLE极大似然估计和EM最大期望算法
机器学习十大算法之一:EM算法.能评得上十大之一,让人听起来觉得挺NB的.什么是NB啊,我们一般说某个人很NB,是因为他能解决一些别人解决不了的问题.神为什么是神,因为神能做很多人做不了的事.那么EM ...
- EM最大期望化算法
最大期望算法(Expectation-maximization algorithm,又译期望最大化算法)在统计中被用于寻找,依赖于不可观察的隐性变量的概率模型中,参数的最大似然估计. 在统计计算中,最 ...
- EM(期望最大化)算法初步认识
不多说,直接上干货! 机器学习十大算法之一:EM算法(即期望最大化算法).能评得上十大之一,让人听起来觉得挺NB的.什么是NB啊,我们一般说某个人很NB,是因为他能解决一些别人解决不了的问题.神为什么 ...
- 最大期望算法 Expectation Maximization概念
在统计计算中,最大期望(EM,Expectation–Maximization)算法是在概率(probabilistic)模型中寻找参数最大似然估计的算法,其中概率模型依赖于无法观测的隐藏变量(Lat ...
- EM 算法
这个暂时还不太明白,先写一点明白的. EM:最大期望算法,属于基于模型的聚类算法.是对似然函数的进一步应用. 我们知道,当我们想要估计某个分布的未知值,可以使用样本结果来进行似然估计,进而求最大似然估 ...
- 顶尖数据挖掘辅助教学套件(TipDM-T6)产品白皮书
顶尖数据挖掘辅助教学套件 (TipDM-T6) 产 品 说 明 书 广州泰迪智能科技有限公司 版权所有 地址: 广州市经济技术开发区科学城232号 网址: ht ...
- 顶尖大数据挖掘实战平台(TipDM-H8)产品白皮书
顶尖大数据挖掘实战平台 (TipDM-H8) 产 品 说 明 书 广州泰迪智能科技有限公司 版权所有 地址: 广州市经济技术开发区科学城232号 网址: http: ...
随机推荐
- 2015.9.28 不能将多个项传入“Microsoft.Build.Framework.ITaskItem”类型的参数 问题解决
方法是:项目->属性->安全性->启用ClickOnce安全设置, 把这个复选框前面的勾去掉就可以了.
- windows异常演示,指定异常类型,然后生成异常
#include "stdafx.h"#include <Windows.h>#include <float.h> DWORD Filter (LPEXCE ...
- javascript——正则表达式(RegExp、String)(未完工)
在 javascript 中,正则表达式由两部分组成:正则表达式的匹配模式文本:匹配模式文本的修饰符: 修饰符: 修饰符 说明 i 忽略大小写 g 执行全局匹配 m 执行多行匹配 匹配模式文本包括以下 ...
- Python 标准库 -> Pprint 模块 -> 用于打印 Python 数据结构
使用 pprint 模块 pprint 模块( pretty printer ) 用于打印 Python 数据结构. 当你在命令行下打印特定数据结构时你会发现它很有用(输出格式比较整齐, 便于阅读). ...
- hadoop 更改 tmp目录
配置hadoop临时目录--------------------- 1.配置[core-site.xml]文件 <configuration> <property> <n ...
- 基于cookie实现用户验证
#!/usr/bin/env python import tornado.ioloop import tornado.web class IndexHander(tornado.web.Request ...
- Ajax笔记(一)
Ajax三步骤: Asynchronous Javascript And XML 1.运用HTML和CSS实现页面,表达信息: 2.运用XMLHttpRequest和web服务器进行数据的异步交换: ...
- [poj3348]Cows
题目大意:求凸包面积. 解题关键:模板题,叉积求面积. 这里的cmp函数需要调试一下,虽然也对,与普通的思考方式不同. #include<cstdio> #include<cstri ...
- CentOS7下安装pip和pip3
1.首先检查linux有没有安装python-pip包,直接执行 yum install python-pip 2.没有python-pip包就执行命令 yum -y install epel-rel ...
- vue 之 介绍及简单使用
浏览目录 vue的介绍 vue的使用 vue的介绍 简介 vue官网说:Vue.js(读音 /vjuː/,类似于 view) 是一套构建用户界面的渐进式框架.与其他重量级框架不同的是,Vue 采用自底 ...