ruby2.2.2 源代码阅读笔记
这是win32下的结构
从ruby_setup开始阅读
Ruby对象内存结构
RVALUE是一个union,内含ruby所有结构体(RBasic RObject RClass RFloat RString RArray RRegexp RHash RData RTypedData RStruct RBignum RFile RNode RMatch RRational RComplex)以及用于gc的free结构。RVALUE是object space heap的最小单元。ruby及C扩展通常用VALUE引用RVALUE(或者具体的Rxxx结构),使用这些结构时,先对VALUE转型。
ruby _pioinfo()和msvc _pioinfo() __pioinfo[]关系
ruby使用自己实现的_pioinfo()函数去查全局变量__pioinfo[],这个函数与msvcrt的实现_pioinfo()有区别
由于ioinfo是msvcrt内部数据结构,没有公开到头文件也没有函数返回这个结构,但ruby要使用这些结构的头几个字段,所以ruby内定义了一个不完整的ioinfo结构,这个结构比msvcrt的ioinfo小。
为了保证偏移量,ruby使用自己的函数set_pioinfo_extra()计算ruby的ioinfo和msvcrt的ioinfo之间的大小差,保存在pioinfo_extra内,这个变量用于ruby的_pioinfo()函数;
就是说sizeof(ruby::ioinfo) + pioinfo_extra == sizeof(msvcrt::ioinfo)
配合msvcr100.dll,版本10.0.40219.1,从release下观察,sizeof(msvcrt_ioinfo)大小是64,pioinfo_extra是24
参考Microsoft Visual Studio 10.0\VC\crt\src\
ioinit.c line 49
internal.h line 120
以及ioinit.c内_alloc_osfhnd
msvcrt::__pioinfo[]是一个指针数组,有64个元素,每个元素是一个ioinfo数组首地址,每个ioinfo数组有32个ioinfo,即如下图
__pioinfo[0]->ioinfo[32]
__pioinfo[1]->ioinfo[32]
__pioinfo[2]->ioinfo[32]
__pioinfo[3]->ioinfo[32]
...
所以,从fd查到ioinfo的过程如下
index = fd >> 5;
ioinfo* p = __pioinfo[index];
所以,p[fd & 31]就是fd对应的ioinfo
ruby的_pioinfo()函数也是类似的流程,但有一个区别是,ioinfo的大小跟msvcrt内部的不一样,所以才会有pioinfo_extra这个变量出现。
set_pioinfo_extra()用于计算pioinfo_extra,但方法不严谨,可能会导致pioinfo_extra不准确,所以会导致ruby自己的_pioinfo()查出来的ioinfo不正确。
set_pioinfo_extra()计算所用的方法是
for (pioinfo_extra = 0; pioinfo_extra <= 64; pioinfo_extra += 4)
{
// 每次循环,ruby_ioinfo的大小在原有基础上加4字节
ruby_ioinfo.sizeof += pioinfo_extra;
index = fd >> 5;
msvcrt_ioinfo* p_m = __pioinfo[index];
ruby_ioinfo* p_r = __pioinfo[index];
if (p_m[fd & 31].osfhnd == p_r[fd & 31].osfhnd)
{
// 问题在这里
// 因为两个结构体大小不一样,所以osfhnd的偏移不一样,ruby认为每次按4字节增加ruby_ioinfo去比较,如果得到osfhnd一样,就得到pioinfo_extra
return pioinfo_extra;
}
}
ruby rb_thread_t结构
rb_thread_t结构很复杂,先解析目前已阅读的部分,之后慢慢补充
Init_BareVM用malloc分配主线程rb_thread_t结构。
GET_THREAD()永远返回当前线程。
每条系统线程都可以从tls index ruby_native_thread_key 获取自己的rb_thread_t结构,由Init_native_thread维护。
rb_thread_t是一个双向链表,由vmlt_node表明
rb_thread_t.rb_vm_t结构很复杂
rb_global_vm_lock_t
rb_nativethread_lock_t
main_thread,主线程的rb_thread_t结构
running_thread,正在运行的rb_thread_t结构
living_threads,一些10年前的资料表明,ruby用双向循环链表记录解析器内所有线程rb_thread_t,多线程调度从这个链表内根据各种条件选择一条线程执行,具体细节需要继续阅读代码
default_params,分别设置脚本栈,机器栈,纤程栈的大小,粗略看来,机器栈相关的大小,在win32下然并卵。脚本栈将成为rb_thread_t stack_size的依据。注意,这堆数据ruby通过取环境变量得到,所以,可以通过环境变量来改变,RUBY_THREAD_VM_STACK_SIZE之类的。在vm.c vm_default_params_setup内设置。
rb_thread_t.machine结构
这个结构就记录的数据就是线程teb关于线程栈基址及长度的数据,ruby记录栈长度时做了些计算,暂时不清楚为什么要这样做(space = size / 5),具体源代码可参考thread_win32.c native_thread_init_stack。目前来看,stack_start的这貌似在某些xp机器上会算错,算小了,可以考虑直接取teb.StackBase。
之所以叫machine是因为这堆数据真是反映操作系统线程栈(机器栈,系统线程栈),ruby用这些数据检查ruby解析器函数调用时,是否存在栈溢出情况,源代码参考gc.c stack_check。machine stack为gc提供参考,在ruby发起gc mark时,会扫描machine stack上是否有引用object space内的对象(例如ruby自身和一些C扩展),如果有,就mark。
rb_thread_t stack stack_size cfp(rb_control_frame_t)字段
这些字段记录ruby解析器用于脚本解析的脚本栈,当脚本包含函数调用时,这些字段会发生变化。
在vm.c th_init()内初始化,观察得知,这个stack来自object space。
stack是栈顶,cfp是栈底。观察vm_push_frame(),cfp记录每一个frame的属性,cfp由栈底向上增长,而frame分配的储存空间,则由stack向下分配。如下图:
[...] <-stack
[...] -|
[...] |- frame 1 values
[...] <- cfp1.sp -|
[...]
...
[...] <-cfp1
[...] <-cfp0
所以,检查ruby脚本栈是否溢出就是检查cfp.sp + 分配空间 后是否大于cfp,这也是CHECK_VM_STACK_OVERFLOW0的逻辑。压栈由PUSH(x)宏实现,在vm_insnhelper.h内。
cfp内的iseq就是与这个脚本栈关联的虚拟机指令序列,cfg.pc就是虚拟机当前指令,虚拟机指令结构及定义,务必仔细阅读insns.def,insns.def会翻译成C函数,成为vm.inc文件。虚拟机指令主要由指令id标识,根据指令id选择对应的C函数执行,这个过程可在vm_exec_core()内
INSN_DISPATCH();
#include "vm.inc"
END_INSNS_DISPATCH();
虚拟机指令id在insns.inc内定义,接下来看一个具体的例子:
1.假设rb_thread_t.cfp.pc = 0x00d3c4f0
2.在windbg内执行 dd 0x00d3c4f0得到一下内容
00d3c4f0 00000028 00000001 00000010 00000003
00d3c500 0000000d 00000029 0000520b 0290aa40
00d3c510 00000000 0000002f 1bd351c3 80000000
00d3c520 00000098 00000001 00000000 00000000
00d3c530 00000000 00000000 00000000 00000000
00d3c540 00000000 00000000 1bd351c9 80000000
00d3c550 0000009e 00000000 00000000 00000000
00d3c560 00000000 00000000 00000000 00000000
观察第一个dword是0x28,在insns.inc内查找对应的指令,是trace,在vm.inc内INSN_ENTRY(trace)对应这条指令的逻辑。
rb_thread_t.native_thread_data
目前只有interrupt_event,由Init_native_thread创建事件
rb_thread_t.self
主线程是0,这个貌似是线程对应的ruby对象
rb_objspace_t
目前来说,只能呵呵,下图是10年前的资料,仅供参考
https://ruby-hacking-guide.github.io/gc.html
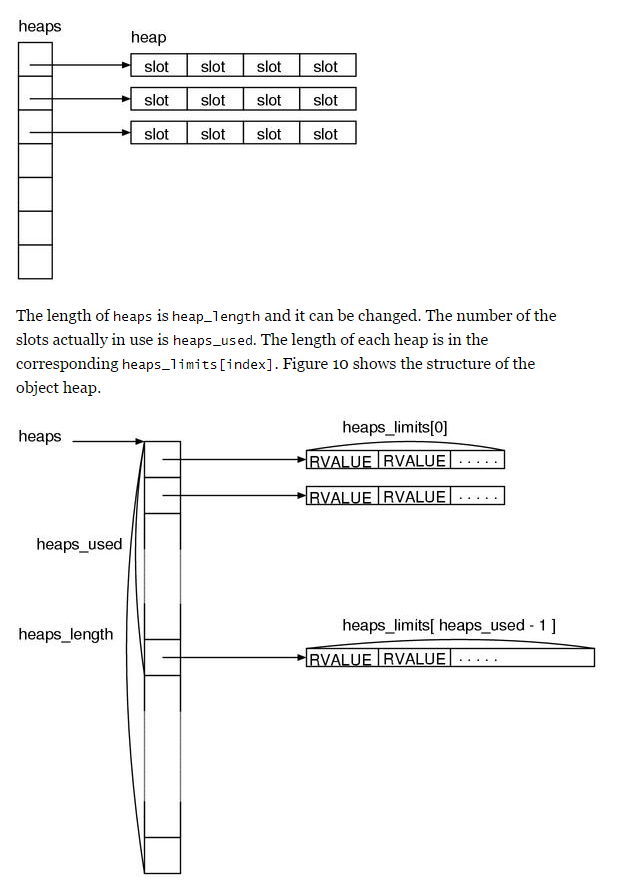
由函数Init_heap初始化。
唯一一个rb_objspace实例,用于管理对象gc,内存分配,大小限制有宏GC_MALLOC_LIMIT_MIN以及GC_MALLOC_LIMIT_MAX控制,体现在rb_objspace_t.malloc_params.limit。
以下只是猜测,观察代码,rb_objspace_t.heap_pages就是对应上图结构。sorted是heaps表,sorted_length是heaps_length,page就是上图的heap了。观察heap_pages_expand_sorted(),是增加sorted表,用于增加page。当expand完成后,使用heap_assign_page()增加page。
heap_assign_page()先从tomb_heap内取page,如果没有tomb,就新建page(包括page head和page body),按body地址排序,插入sorted表,标记为free page,这个时候貌似会触发gc,释放page上引用到的ruby对象(例如这个page是从tomb来的)。
上述过程在heap_add_pages()内触发,Init_heap会把pages都添加到eden_heap内。
init_mark_stack()初始化了4块stack_chunk_t,mark_stack,跟gc mark有关。
objspace->finalizer_table,不清楚用途。
objspace->flags.gc_stressful,用于控制gc的频繁度,如果大于0,在newobj的时候,也会触发gc,参考gc.c newobj_of()。
garbage_collect(),先使用ready_to_gc()执行heap_assign_page(),然后执行gc_marks(),分为mark_start和mark_rest两个步骤:1)vm,finalizer_table,线程的rb_thread_t ,encoding等等,计算对象代龄,收集到mark_stack内,其中rb_thread_t是mark机器栈上由局部变量引用的ruby对象,特别需要注意,局部变量有可能被优化到寄存器,所以,写ruby c扩展时,局部变量需要用volatile保护;另外,ruby源码到处可见RB_GC_GUARD,它的作用也类似,避免调用栈末端函数折叠优化,从而避免栈变量优化(末端函数被折叠,栈就消失了,gc mark机器栈时就会误判对象生命周期);2)遍历mark_stack,marking,把eden heap内所有sweep page都移动到tomb heap内。
所以,ruby内所有对象都有rvalue引用,gc就是针对object space内的rvalue进行。
rb_iseq_t rb_iseq_struct
虚拟机指令序列对象。
type序列类型
location应该是序列对应的ruby模块吧,path是个RString,强转之后能看到具体名字。
PUSH_TAG POP_TAG EXEC_TAG JUMP_TAG
ruby使用c setjmp longjmp实现各种跳转,例如异常跳转,解析器循环求值跳出等等。
tag结构体,tag结构体是rb_thread_t的成员,用链表纪录的栈结构tag。ruby在机器栈上构造tag,放到rb_thread_t tag栈顶部,用这个tag执行setjmp。当setjmp返回,从rb_thread_t.tag弹出。jump_tag就是用rb_thread_t.tag作为longjmp参数,longjmp目的由rb_thread_t.state表明,在eval_intern.h内RUBY_TAG_xxx定义。
下面是整个过程:
PUSH_TAG ---- 构造tag实例,压rb_thread_t.tag
EXEC_TAG ---- setjmp
POP_TAG ---- 从rb_thread_t.tag弹出
下面是循环跳出过程:
rb_eval(break) >----
rb_eval(if) | longjmp state=RUBY_TAG_BREAK
rb_eval(block) |
rb_eval(while) <----
ruby2.2.2 源代码阅读笔记的更多相关文章
- Mongodb源代码阅读笔记:Journal机制
Mongodb源代码阅读笔记:Journal机制 Mongodb源代码阅读笔记:Journal机制 涉及的文件 一些说明 PREPLOGBUFFER WRITETOJOURNAL WRITETODAT ...
- CI框架源代码阅读笔记5 基准測试 BenchMark.php
上一篇博客(CI框架源代码阅读笔记4 引导文件CodeIgniter.php)中.我们已经看到:CI中核心流程的核心功能都是由不同的组件来完毕的.这些组件类似于一个一个单独的模块,不同的模块完毕不同的 ...
- CI框架源代码阅读笔记3 全局函数Common.php
从本篇開始.将深入CI框架的内部.一步步去探索这个框架的实现.结构和设计. Common.php文件定义了一系列的全局函数(一般来说.全局函数具有最高的载入优先权.因此大多数的框架中BootStrap ...
- CI框架源代码阅读笔记2 一切的入口 index.php
上一节(CI框架源代码阅读笔记1 - 环境准备.基本术语和框架流程)中,我们提到了CI框架的基本流程.这里再次贴出流程图.以备參考: 作为CI框架的入口文件.源代码阅读,自然由此開始. 在源代码阅读的 ...
- Spark源代码阅读笔记之DiskStore
Spark源代码阅读笔记之DiskStore BlockManager底层通过BlockStore来对数据进行实际的存储.BlockStore是一个抽象类,有三种实现:DiskStore(磁盘级别的持 ...
- Java Jdk1.8 HashMap源代码阅读笔记二
三.源代码阅读 3.元素包括containsKey(Object key) /** * Returns <tt>true</tt> if this map contains a ...
- Discuz!源代码阅读笔记之common.inc.php文件【1】
<?php /* [Discuz!] (C)2001-2007 Comsenz Inc. This is NOT a freeware, use is subject to license te ...
- 【MySQL】filesort.cc 源代码阅读笔记
最近阅读了部分MySQL排序的代码,把心得记录一下. 参考代码 MySQL: 文件: filesort.cc 函数: filesort() 排序过程伪代码 function filesort(tabl ...
- Flask 源代码阅读笔记
我认为我已经养成了一个坏习惯.在使用一个框架过程中对它的内部原理非常感兴趣,有时候须要花不少精力才 明确,这也导致了学习的缓慢,但换来的是对框架的内部机理的熟悉,正如侯捷所说,源代码面前,了无秘密.这 ...
随机推荐
- 高能物理/HyperPhysics的网站/Website
参考: 基础物理-高能物理[Hyperphysics]
- 376. Wiggle Subsequence
A sequence of numbers is called a wiggle sequence if the differences between successive numbers stri ...
- hybird app
Hybrid App 是混合模式应用的简称,兼具 Native App 和 Web App 两种模式应用的优势,开发成本低,拥有 Web 技术跨平台特性.目前大家所知道的基于中间件的移动开发框架都是采 ...
- LAMP虚拟主机配置以及控制目录访问
3.基于域名的虚拟主机配置 NameVirtualHost192.168.3.32:80#apache2.2.xx版本需要开启此选项,而且要和下面的保持一致:2.4.x版本就不需要此项设置了 < ...
- js:合同-已知起始日期、年限,自动计算截止日期
dateAddYear('2016-01-01', '3') ;//返回:2018-12-31 浏览器:ie11,ff 46.0.1(成功)360v8.1(急速模式,成功) 浏览器:360v8.1(兼 ...
- Binding的源和路径
书上写着:Binding的源也就是数据的源头.Binding对于源的要求很简单-只要他是一个对象!并且通过属性(Property)公开自己的数据,它就可以作为Binding的源了.就像上一篇我写的那个 ...
- C# 正则获取html内容
1.获取div内容 string str = "tt<u>ss</u><div id=\"test\"><div>< ...
- POJ 3254 压缩状态DP
题意:一个矩形网格,可以填0或1, 但有些位置什么数都不能填,要求相邻两个不同时为1,有多少种填法.矩形大小最大 12*12. 压缩状态DP大多有一个可行的state的范围,先求出这个state范围, ...
- javascript高级编程笔记03(正则表达式)
引用类型 检测数组 注:我们实际开发中经常遇到要把数组转化成以逗号隔开,我以前都是join来实现,其实又更简单的方法可以用toString方法,它会自动用逗号隔开转换成字符串,其实toString内部 ...
- ExtJS4中initComponent和constructor的区别
Ext的define方法参数类型define( String className, Object data, Function createdFn ) 创建自定义类时,先构造(constructor) ...