Hadoop版Helloworld之wordcount运行示例
1.编写一个统计单词数量的java程序,并命名为wordcount.java,代码如下:
import java.io.IOException;
import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount { public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1);
private Text word = new Text(); public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
} public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
2.声明java环境变量:
export JAVA_HOME=/usr/java/default
export PATH=${JAVA_HOME}/bin:${PATH}
export HADOOP_CLASSPATH=${JAVA_HOME}/lib/tools.jar
其中JAVA_HOME根据自己安装java的实际路径进行配置。
注意:如果不声明以上环境变量,那么在以后运行时,将会收到错误提示:
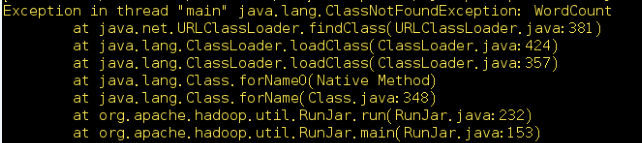
3.编译并创建jar包。
bin/hadoop com.sun.tools.javac.Main WordCount.java
jar cf wc.jar WordCount*.class
4.运行第三步骤生成的wc.jar包。此时要注意,output文件夹不要手工创建,系统运行后会自动创建。
bin/hadoop jar wc.jar WordCount /user/root/wordcount/input /user/root/wordcount/output
正常运行结束后,会在outPut文件夹下生成part-r-00000及__SUCCESS两个文件,其中part-r-00000存储分析结果。运行命令:
bin/hadoop fs -cat /user/root/wordcount/output/part-r-00000
即可查看分析结果,如下图所示: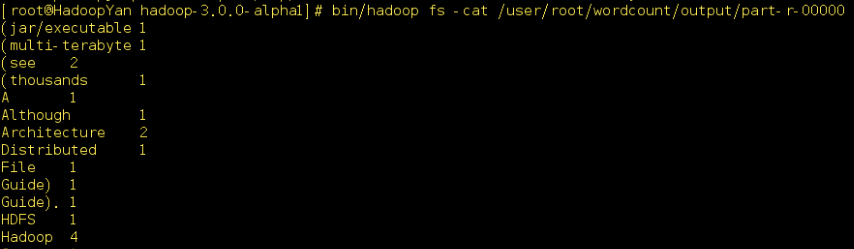
至此,本示例完成。
Hadoop版Helloworld之wordcount运行示例的更多相关文章
- [b0013] Hadoop 版hello word mapreduce wordcount 运行(三)
目的: 不用任何IDE,直接在linux 下输入代码.调试执行 环境: Linux Ubuntu Hadoop 2.6.4 相关: [b0012] Hadoop 版hello word mapred ...
- [b0012] Hadoop 版hello word mapreduce wordcount 运行(二)
目的: 学习Hadoop mapreduce 开发环境eclipse windows下的搭建 环境: Winows 7 64 eclipse 直接连接hadoop运行的环境已经搭建好,结果输出到ecl ...
- hadoop自带例子wordcount的具体运行步骤
1.在hadoop所在目录“usr/local”下创建一个文件夹input root@ubuntu:/usr/local# mkdir input 2.在文件夹input中创建两个文本文件file1. ...
- 在eclipse上跑hadoop的helloworld
关于hadoop的用处什么我就不说了,在这里记录下在eclipse上第一次跑hadoop遇到的问题吧~ hadoop的安装我就不说啦,网上教程一大堆~我直接用的公司的Linux上的hadoop. ec ...
- eclipse hadoop1.2.0配置及wordcount运行
"error: failure to login"问题 http://www.cnblogs.com/xia520pi/archive/2012/05/20/2510723.htm ...
- hadoop第一个例子WordCount
hadoop查看自己空间 http://127.0.0.1:50070/dfshealth.jsp import java.io.IOException; import java.util.Strin ...
- 执行hadoop自带的WordCount实例
hadoop 自带的WordCount实例可以统计一批文本文件中各单词出现的次数.下面介绍如何执行WordCount实例. 1.启动hadoop [root@hadoop ~]# start-all. ...
- Hadoop环境搭建及wordcount程序
目的: 前期学习了一些机器学习基本算法,实际企业应用中算法是核心,运行的环境和数据处理的平台是基础. 手段: 搭建简易hadoop集群(由于机器限制在自己的笔记本上通过虚拟机搭建) 一.基础环境介绍 ...
- Windows上配置Mask R-CNN及运行示例demo.ipynb
最近做项目需要用到Mask R-CNN,于是花了几天时间配置.简单跑通代码,踩了很多坑,写下来分享给大家. 首先贴上官方Mask R-CNN的Github地址:https://github.com/m ...
随机推荐
- Spring Cloud Eureka Server例子程序
Spring-Cloud-Eureka-Server 及Client 例子程序 参考源代码:https://github.com/spring-cloud-samples/eureka 可以启动成功, ...
- 使用Fiddler提高前端工作效率 (实例篇)
上篇中,我们对Fiddler Web Debugger有了简单的接触,也许你已经开始在用Fiddler进行HTTP相关的调试,在这一篇,我们将通过一个实例了解Fiddler的神奇魔法. 在我们前端开发 ...
- SQLite批量插入,修改数据库 zt
SQLiteConnection sqConnection = dataProvider.GetDbConnection(); sqConnection.Open(); SQLiteCommand s ...
- LED汽车前大灯
一.LED汽车前大灯遇到问题.分析和解决 问题1: 当电源电压增大时,LED等闪烁,而且电源电压增大的越多闪烁的频率越低. 原因分析: 电源电压从12V升高到24V过程中,开关MOS管的Vds增大,Q ...
- OC修饰词 - 内存管理
<招聘一个靠谱的 iOS>—参考答案(上) 说明:面试题来源是微博@我就叫Sunny怎么了的这篇博文:<招聘一个靠谱的 iOS>,其中共55题,除第一题为纠错题外,其他54道均 ...
- Latex 常用知识点存档
前言: 本篇仅作为自己的知识存档. $Latex$是什么,就不用介绍了,网上好多教程和知识点,当忘记的时候搜一下就可以了. 本科做美赛和毕设的时候用的$Latex$排版,最近开始在博客园写点东东,发现 ...
- capitalize()在Python中含义
Python为string对象提供了转换大小写的方法:upper() 和 lower(). 还不止这些,Python还为我们提供了首字母大写,其余小写的capitalize()方法, 以及所有单词首字 ...
- Python+django部署(一)
之所以 写这篇文章的原因在于django环境的确轻松搭建,之前Ubuntu上安装了,的确很轻松,但是后期我才知道随便做个环境出来很容易到了后面很麻烦,污 染了系统里的python版本,导致系统pyth ...
- [python]用profile协助程序性能优化
转自:http://blog.csdn.net/gzlaiyonghao/article/details/1483728 本文最初发表于恋花蝶的博客http://blog.csdn.net/lanph ...
- 【BZOJ 1319】 Sgu261Discrete Rootsv (原根+BSGS+EXGCD)
1319: Sgu261Discrete Roots Time Limit: 1 Sec Memory Limit: 64 MBSubmit: 389 Solved: 172 Descriptio ...