[Python] 糗事百科文本数据的抓取
[Python] 糗事百科文本数据的抓取
源码
https://github.com/YouXianMing/QiuShiBaiKeText
- import sqlite3
- import time
- import requests
- from regexp_string import *
- class QiuShiBaiKeText35:
- db_name = 'qiu_shi_bai_ke_text35.db'
- conn = None
- def prepare(self):
- """
- 开始准备数据库相关准备工作
- :return: PiuShiBaiKeText35对象本身
- """
- # 连接数据库,不存在则创建
- self.conn = sqlite3.connect(self.db_name)
- # 不存在表则创建表
- sql_str = """CREATE TABLE IF NOT EXISTS qiu_shi_bai_ke_text (articleId INT8 PRIMARY KEY NOT NULL,
- content TEXT, date TIMESTAMP); """
- self.conn.execute(sql_str)
- # 关闭数据库
- self.conn.close()
- self.conn = None
- return self
- def start(self, max_page=99999):
- """
- 开始爬数据
- :param max_page: 最大页码,不设置则为99999
- :return: PiuShiBaiKeText35对象本身
- """
- self.conn = sqlite3.connect(self.db_name)
- self.__qiu_shi_text(max_page)
- self.conn.close()
- self.conn = None
- return self
- def __qiu_shi_text(self, max_page=99999):
- """
- 开始扫描
- :param max_page: 最大页码,不设置则为99999
- :return: None
- """
- for i in range(1, max_page):
- url = "http://www.qiushibaike.com/text/page/%s/" % i
- print(url)
- time.sleep(0.5)
- request = requests.get(url)
- if i != 1:
- request = requests.get(url)
- if request.url != url:
- break
- self.__convert_from_web_string(request.text)
- def __convert_from_web_string(self, web_string):
- """
- 获取网页字符串,并用正则表达式进行解析
- :param web_string: 网页字符串
- :return: None
- """
- # 获取列表
- pattern = r"""\d+" target="_blank" class='contentHerf' >.+?</span>"""
- item_list = RegExpString(web_string).get_item_list_with_pattern(pattern)
- # 如果存在列表,则遍历列表
- if item_list:
- for item in item_list:
- # 内容id
- article_id = RegExpString(item).search_with_pattern(r'^\d+').search_result
- # 内容
- article_content = RegExpString(item).search_with_pattern(
- r'(?<=<span>).+(?=</span>)').search_result
- article_content = RegExpString(article_content).replace_with_pattern(r'<br/>',
- "\n").replace_result
- # 打印内容
- print("http://www.qiushibaike.com/article/%s\n%s\n\n" % (article_id, article_content))
- # 先查找有没有这个id的数据
- cursor = self.conn.execute("""SELECT COUNT(*) FROM qiu_shi_bai_ke_text WHERE articleId = '%s';""" % article_id)
- for row in cursor:
- # 如果查不到数据,则插入数据
- if row[0] == 0:
- # 插入语句
- sql_str = """INSERT INTO qiu_shi_bai_ke_text (articleId, content, date) VALUES ('%s', '%s', '%s');""" % (
- article_id, article_content, time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()))
- self.conn.execute(sql_str)
- self.conn.commit()
细节
1. 抓取 http://www.qiushibaike.com/text/ 所有35个页面的文本数据
2. 抓取的数据写进数据库,数据库用的是sqlite3
3. 基于Python3.60版本,其他版本未测试
4. 网络库使用过的 requests (https://github.com/kennethreitz/requests) ,如果没有安装,请使用 pip install requests 安装
效果
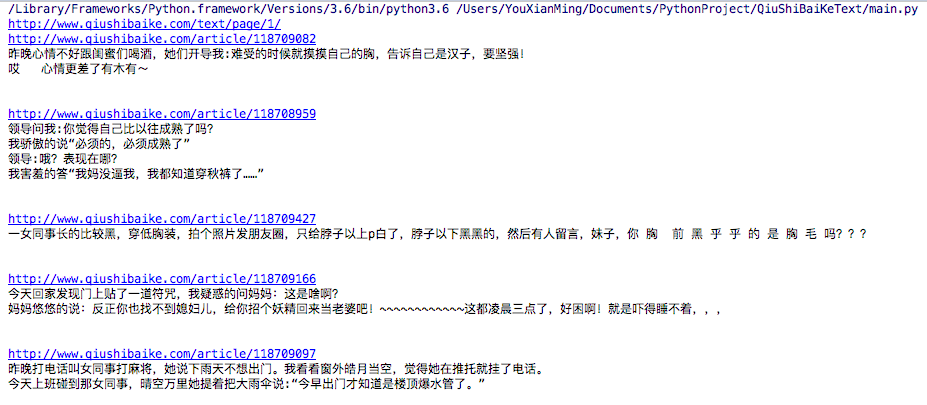
[Python] 糗事百科文本数据的抓取的更多相关文章
- python 糗事百科实例
爬取糗事百科段子,假设页面的URL是 http://www.qiushibaike.com/8hr/page/1 要求: 使用requests获取页面信息,用XPath / re 做数据提取 获取每个 ...
- Python爬虫--抓取糗事百科段子
今天使用python爬虫实现了自动抓取糗事百科的段子,因为糗事百科不需要登录,抓取比较简单.程序每按一次回车输出一条段子,代码参考了 http://cuiqingcai.com/990.html 但该 ...
- python爬虫之爬取糗事百科并将爬取内容保存至Excel中
本篇博文为使用python爬虫爬取糗事百科content并将爬取内容存入excel中保存·. 实验环境:Windows10 代码编辑工具:pycharm 使用selenium(自动化测试工具)+p ...
- 糗事百科python爬虫
# -*- coding: utf-8 -*- #coding=utf-8 import urllib import urllib2 import re import thread import ti ...
- 5 使用ip代理池爬取糗事百科
从09年读本科开始学计算机以来,一直在迷茫中度过,很想学些东西,做些事情,却往往陷进一些技术细节而蹉跎时光.直到最近几个月,才明白程序员的意义并不是要搞清楚所有代码细节,而是要有更宏高的方向,要有更专 ...
- 初识python 之 爬虫:使用正则表达式爬取“糗事百科 - 文字版”网页数据
初识python 之 爬虫:使用正则表达式爬取"古诗文"网页数据 的兄弟篇. 详细代码如下: #!/user/bin env python # author:Simple-Sir ...
- python 抓取糗事百科糗图
1 首先看下要抓取的页面 这是糗事百科里面的糗图页面,每一页里面有很多的图片,我们要做的就是把这些图片抓取下来. 2 分析网页源代码 发现源代码里面的每张图是这样储存的,所以决定使用正则匹配出图片的u ...
- Python抓取糗事百科成人版图片
最近开始学习爬虫,一开始看的是静觅的爬虫系列文章,今天看到糗事百科成人版,心里就邪恶了一下,把图片都爬下来吧,哈哈~ 虽然后来实现了,但还是存在一些问题,暂且不提,先切入正题吧,没什么好说的,直接上代 ...
- Python爬虫(十八)_多线程糗事百科案例
多线程糗事百科案例 案例要求参考上一个糗事百科单进程案例:http://www.cnblogs.com/miqi1992/p/8081929.html Queue(队列对象) Queue是python ...
随机推荐
- 恋爱Linux(Fedora20)2——安装Java运行环境(JDK)
因为Fedora20自带OpenJDK,所以我们先删除掉自带的: 1)查看当前的jdk情况 # rpm -qa|grep jdk 2)卸载openjdk # yum -y remove java ja ...
- PHP 抽象类
* 抽象类 * 1.使用关键字: abstract * 2.类中只要有一个方法声明为abstract抽象方法,那么这个类就必须声明为抽象类 * 3.抽象方法只允许有方法声明与参数列表,不允许有方法体; ...
- springMVC源码分析--FlashMap和FlashMapManager重定向数据保存
在上一篇博客springMVC源码分析--页面跳转RedirectView(三)中我们看到了在RedirectView跳转时会将跳转之前的请求中的参数保存到fFlashMap中,然后通过FlashMa ...
- thinkphp错误提示:系统发生错误
下载最新版本3.1.3,定义了一个应用,进入应用的config.php,在里面添加数据库类链接信息,在控制器里面M()一个表,访问控制器方法提示:系统发生错误.如果使用连接字符串DSN方式,调用M() ...
- Java 和 C++ 的部分区别
1. Java是解释型语言,所谓的解释型语言,就是源码会先经过一次编译,成为中间码,中间码再被解释器解释成机器码.对于Java而言,中间码就是字节码(.class),而解释器在JVM中内置了. 2. ...
- Hibernate之关联关系映射(一对一主键映射和一对一外键映射)
1:Hibernate的关联关系映射的一对一外键映射: 1.1:第一首先引包,省略 1.2:第二创建实体类: 这里使用用户信息和身份证信息的关系,用户的主键编号既可以做身份证信息的主键又可以做身份证信 ...
- 《Java程序性能优化》之设计优化
豆瓣读书:http://book.douban.com/subject/19969386/ 第一章 Java性能调优概述 1.性能的参考指标 执行时间: CPU时间: 内存分配: 磁盘吞吐量: 网络吞 ...
- mysql undo 和redo 被误删除的恢复操作(一致性)
今天在群里看到有人说不熟悉innodb把ibdata(数据文件)和ib_logfile(事务日志)文件误删除了.不知道怎么解决.当时我也不知道怎么办.后来查阅相关资料.终找到解决方法.其实恢复也挺简单 ...
- Codeforces 585D Lizard Era: Beginning
Lizard Era: Beginning 折半之后搜就完事了, 直接存string字符串卡空间, 随便卡卡空间吧. #include<bits/stdc++.h> #define LL ...
- Flutter常用组件(Widget)解析-ListView
一个可滚动的列表组件 不管在哪,列表组件都尤为重要和常用. 首先来看个例子: import 'package:flutter/material.dart'; void main () => ru ...