Spark机器学习(11):协同过滤算法
协同过滤(Collaborative Filtering,CF)算法是一种常用的推荐算法,它的思想就是找出相似的用户或产品,向用户推荐相似的物品,或者把物品推荐给相似的用户。怎样评价用户对商品的偏好?可以有很多方法,如用户对商品的打分、购买、页面停留时间、保存、转发等等。得到了用户对商品的偏好,就可以给用户推荐商品。有两种方法:用户A喜欢物品1,商品2和物品1很相似,于是把物品2推荐给用户A;或者用户A和用户B很类似,B喜欢商品2,就将商品2推荐给用户A。所以协同过滤分为两类:基于用户的协同过滤和基于物品的协同过滤。
1. 相似度的计算
协同过滤算法一个重要的问题就是相似度的计算,相似度即衡量两个用户,或者两个物品之间相似的程度。计算相似度有几种方法:同现相似度(Cooccurrence Similarity)、欧氏距离(Euclidean Distance)、皮尔逊相关系数(Pearson Correlarion Coefficient)、Cosine相似度(Cosine Similarity)、Tanimoto系数(Tanimoto Coefficient)等。
1.1 同现相似度(Cooccurrence Similarity)
同现,即同时出现的意思,物品i和物品j的同现相似度的计算公式是:

N(i)是喜欢物品i的用户集合,N(j)是喜欢物品j的用户集合,可以理解为喜欢物品i的用户中有多少喜欢物品j。但是这样存在一个问题,如果物品j是热门物品,喜欢它的用户肯定很多,这样不论i是什么物品,wij的值就会很大。为了避免这个问题的出现,对公式进行了改进:
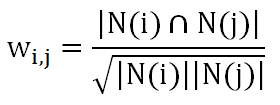
这样如果j是热门物品,分母会很大,从而惩罚了wij的值。
1.2 欧氏距离(Euclidean Distance)
n维空间中两个点x和y的距离:

当n=2时,是平面上两点之间的距离,当n=3时,是立体空间上两点之间的距离。相似度计算公式:
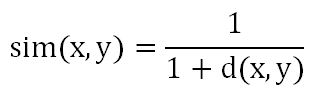
即距离越大,相似度越低;距离越小,相似度越高。当计算两个物品的相似度时,坐标轴是不同的用户,如果所有用户对这两个物品的偏好都差不多,那么这两个物品之间的距离就近,相似度就低,说明这两个物品很相似;反之,则说明这两个物品相似度低。
2. 推荐计算
推荐计算分为两类:基于用户的协同过滤和基于物品的协同过滤。
2.1 基于用户的协同过滤(User CF)
基于用户的协同过滤的基本思想是,对于每一个个用户,根据他对所有物品的偏好,计算他与所有其他用户的相似度(可以使用同现相似度或欧式距离),得到一个用户相似度矩阵Um×m。用户对物品的偏好评分矩阵Pm×n,U×P得到一个m×n矩阵,即对每个用户,每个物品的偏好,过滤掉已经存在的用户对商品的偏好,剩下的数据降序排序,即得到了一个推荐列表。
2.2 基于物品的协同过滤(Item CF)
基于物品的协同过滤的基本思想是,对于每一个个物品,根据所有用户对它的偏好,计算它与所有其他物品的相似度(可以使用同现相似度或欧式距离),得到一个物品相似度矩阵In×n。P×I得到一个m×n矩阵,即对每个用户,每个物品的偏好,过滤掉已经存在的用户对商品的偏好,剩下的数据降序排序,即得到了一个推荐列表。
3. 协同过滤算法的实现
MLlib并没有实现协同过滤算法,可以自己实现。
程序代码:
/**
* Created by Administrator on 2017/7/21.
*/ import org.apache.log4j.{ Level, Logger }
import org.apache.spark.{ SparkConf, SparkContext } object ALSTest02 { def main(args:Array[String]) = { // 设置运行环境
val conf = new SparkConf().setAppName("Decision Tree")
.setMaster("spark://master:7077").setJars(Seq("E:\\Intellij\\Projects\\MachineLearning\\MachineLearning.jar"))
val sc = new SparkContext(conf)
Logger.getRootLogger.setLevel(Level.WARN) // 读取样本数据并解析
val dataRDD = sc.textFile("hdfs://master:9000/ml/data/sample_itemcf3.txt")
val userDataRDD = dataRDD.map(_.split(",")).map(f => (ItemPref(f(0), f(1), f(2).toDouble))).cache() // 建立模型
val simModel = new ItemSimilarity()
val itemRDD = simModel.Similarity(userDataRDD, "cooccurrence")
val recomm = new RecommendedItem
val recommRDD = recomm.Recommend(itemRDD, userDataRDD, 30) // 输出结果
println("物品相似度矩阵:")
itemRDD.sortBy(f => (f.itemid1, f.itemid2)).collect.foreach { simItem =>
println(simItem.itemid1 + ", " + simItem.itemid2 + ", " + simItem.similar)
}
println("用戶推荐列表:")
recommRDD.sortBy(f => (f.pref)).collect.foreach { UserRecomm =>
println(UserRecomm.userid + ", " + UserRecomm.itemid + ", " + UserRecomm.pref)
}
} }
运行结果:
物品相似度矩阵:
1, 2, 0.6666666666666666
1, 3, 0.6666666666666666
1, 5, 0.4082482904638631
1, 6, 0.3333333333333333
2, 1, 0.6666666666666666
2, 3, 0.3333333333333333
2, 4, 0.3333333333333333
2, 6, 0.6666666666666666
3, 1, 0.6666666666666666
3, 2, 0.3333333333333333
3, 4, 0.3333333333333333
3, 5, 0.4082482904638631
4, 2, 0.3333333333333333
4, 3, 0.3333333333333333
4, 5, 0.4082482904638631
4, 6, 0.6666666666666666
5, 1, 0.4082482904638631
5, 3, 0.4082482904638631
5, 4, 0.4082482904638631
5, 6, 0.4082482904638631
6, 1, 0.3333333333333333
6, 2, 0.6666666666666666
6, 4, 0.6666666666666666
6, 5, 0.4082482904638631
用戶推荐列表:
3, 1, 1.3333333333333333
6, 3, 1.8164965809277263
2, 4, 2.7079081189859817
1, 3, 3.0
5, 4, 3.666666666666666
3, 2, 3.6666666666666665
5, 5, 3.6742346141747673
6, 1, 3.8164965809277263
1, 5, 4.08248290463863
4, 5, 4.4907311951024935
3, 5, 4.4907311951024935
4, 3, 5.0
2, 6, 5.041241452319316
1, 4, 5.666666666666666
4, 1, 5.666666666666666
3, 6, 6.0
5, 6, 6.333333333333332
2, 2, 6.666666666666667
6, 2, 7.0
Spark机器学习(11):协同过滤算法的更多相关文章
- Spark机器学习之协同过滤算法
Spark机器学习之协同过滤算法 一).协同过滤 1.1 概念 协同过滤是一种借助"集体计算"的途径.它利用大量已有的用户偏好来估计用户对其未接触过的物品的喜好程度.其内在思想是相 ...
- 【机器学习笔记一】协同过滤算法 - ALS
参考资料 [1]<Spark MLlib 机器学习实践> [2]http://blog.csdn.net/u011239443/article/details/51752904 [3]线性 ...
- Spark 基于物品的协同过滤算法实现
J由于 Spark MLlib 中协同过滤算法只提供了基于模型的协同过滤算法,在网上也没有找到有很好的实现,所以尝试自己实现基于物品的协同过滤算法(使用余弦相似度距离) 算法介绍 基于物品的协同过滤算 ...
- spark机器学习从0到1协同过滤算法 (九)
一.概念 协同过滤算法主要分为基于用户的协同过滤算法和基于项目的协同过滤算法. 基于用户的协同过滤算法和基于项目的协同过滤算法 1.1.以用户为基础(User-based)的协同过滤 用相似统 ...
- Spark MLlib协同过滤算法
算法说明 协同过滤(Collaborative Filtering,简称CF,WIKI上的定义是:简单来说是利用某个兴趣相投.拥有共同经验之群体的喜好来推荐感兴趣的资讯给使用者,个人透过合作的机制给予 ...
- 机器学习 | 简介推荐场景中的协同过滤算法,以及SVD的使用
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是机器学习专题的第29篇文章,我们来聊聊SVD在上古时期的推荐场景当中的应用. 推荐的背后逻辑 有没有思考过一个问题,当我们在淘宝或者是 ...
- Collaborative Filtering(协同过滤)算法详解
基本思想 基于用户的协同过滤算法是通过用户的历史行为数据发现用户对商品或内容的喜欢(如商品购买,收藏,内容评论或分享),并对这些喜好进行度量和打分.根据不同用户对相同商品或内容的态度和偏好程度计算用户 ...
- win7下使用Taste实现协同过滤算法
如果要实现Taste算法,必备的条件是: 1) JDK,使用1.6版本.需要说明一下,因为要基于Eclipse构建,所以在设置path的值之前要先定义JAVA_HOME变量. 2) Maven,使用2 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:协同过滤算法
实验目的 初步认识推荐系统 学会用mapreduce实现复杂的算法 学会系统过滤算法的基本步骤 实验原理 前面我们说过了qq的好友推荐,其实推荐算法是所有机器学习算法中最重要.最基础.最复杂的算法,一 ...
随机推荐
- linux上apache并发数与服务器内存关系计算!
Linunx(本次为ubuntu) apache! 连接数理论上当然是支持越大越好,但要在服务器的能力范围内,这跟服务器的CPU.内存.带宽等都有关系. 查看当前的连接数可以用: ps aux | g ...
- NodeJS学习:搭建私有NPM
工具 verdaccio nrm pm2 特点 verdaccio 的特点: 不同步拉取npm库,占据大量硬盘,没有硬盘被撑爆的问题: 安装配置极其简单,不需要数据库: 支持配置上游registry配 ...
- HTML5游戏 看你有多“色” 开发
所有文章搬运自我的个人主页:sheilasun.me 在极客学院看到了这个游戏,在网上找到这个游戏玩了好久真的比较上瘾,于是自己也试着做了一下,可以戳这里试玩→看你有多色 游戏规则: 找出颜色不同的方 ...
- POJ1417 True Liars 并查集 动态规划 (种类并查集)
欢迎访问~原文出处——博客园-zhouzhendong 去博客园看该题解 题目传送门 - POJ1417 题意概括 有一群人,p1个好人,p2个坏人. 他们说了n句话.(p1+p2<=600,n ...
- JsDOM操作
DOM(文档对象模型) 在JS中,所有的事物都是节点,元素.文本等都是节点.把浏览器中的标签看成树状结构,每个标签看成一个节点(dom元素). 应用场景:可以通过节点进行DOM对象的增删改查 获取DO ...
- Windows10下安装Maven以及Eclipse安装Maven插件 + 创建Maven项目
在官网下载Maven http://maven.apache.org/download.cgi 下载下来后加压缩,将apache-maven-3.5.4文件夹复制到想要存放它的位置,我放在了 ...
- Shell学习之Shell特性(一)
Shell学习之Shell特性 目录 命令和文件自动补齐功能 命令历史记忆功能 history.上下键.!number.!string.!$.!! 别名功能 alias.unalias cp.~use ...
- 如何使用 Git LFS 提交大文件?
参考资料: An open source Git extension for versioning large files Git LFS的使用 如何使用 Git LFS 提交大文件? Git LFS ...
- chrome浏览器调试工具你会使用吗?
浏览器调试工具使用总结 一. console使用 console.table(),可以把对象输出成表格的形式,直观的观察数据. console.dir(),可以直观观察dom元素的对象形式 二. $的 ...
- PHP给图片加水印
<?php /** *图片加水印 *@param $srcImg 原图 *@param $waterImg 水印图片 *@param $savepath 保存路径 *@param $savena ...