Dependency Parsing -13 chapter(Speech and Language Processing)
https://web.stanford.edu/~jurafsky/slp3/13.pdf
constituent-based 基于成分的
phrasal constituents and phrase-structure rules短语成分与短语结构规则
directed 有向的
morphologically 形态学
location adverbial 位置状语
predicates 谓语
coreference resolution 共指消解
Nominal subject名词性主语
Appositional modifier 同位修饰语
Determiner 限定符
Prepositions, postpositions 前置词,后置词
Coordinating conjunction 并列连词
taxonomies 分类学
13.1
dependency grammars
:
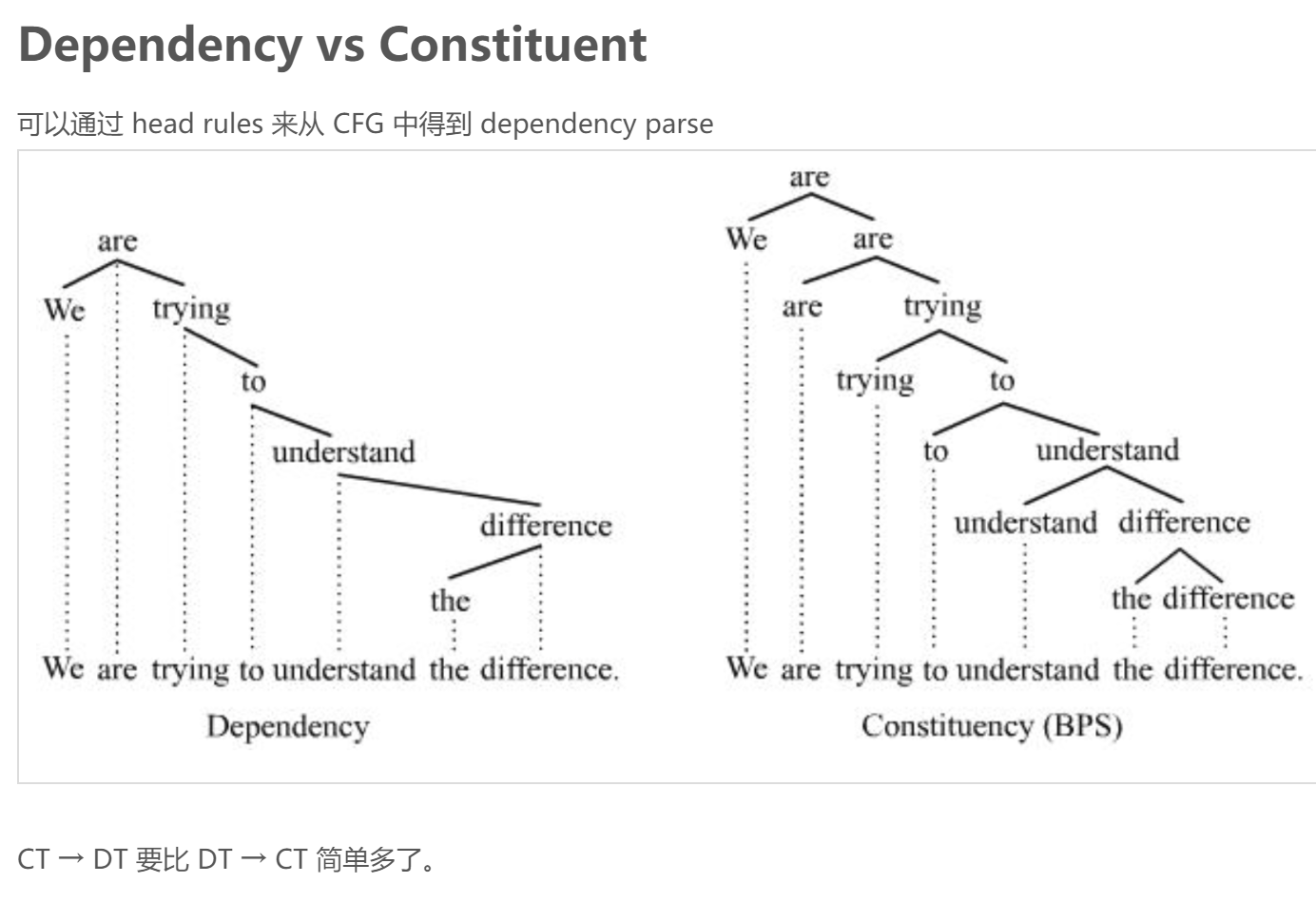
短语成分与短语结构规则不再直接起作用,相反,句子的句法结构只用词或词元以及单词之间的有向的二元语法关系来单独描述
free word order:
依存句法的优点
1、可以处理形态学丰富和具有相对自由词语语序的语言
2、头依赖关系提供了对语义关系的近似,即两个谓词及其论元,这使得它们直接用于许多应用,如共指消解、问题回答。信息提取
the Universal Dependency:
用到的关系主要分两类:clausal relations(描述与谓语的语法角色)和modifier relations

13.2
dependency tree的有方向图的表示要满足以下限制:
a、只有一个指定的根节点,且没有弧指向它
b、除了根节点,每个顶点只有一个弧指向它
c、从根节点到V中的每个顶点,只有唯一的路径
projectivity:
一个词头指向依赖词的弧是投射性的定义为:如果对于在头词和依赖词之间的所有词,从头词到这些词的路径都存在,那么就说这条弧线是投射性的。
一棵依赖树是投射性的定义为:树所有的弧都是投射性的。
如果一棵依存树没有交叉边,那么就是投射性的。
需要注意的两个点:
a 使用最广的英语依存树库是通过head-finding规则自动由短语结构的树库得到的。用这种方式产生的树可以保证是投影性的,因为它们是由上下文无关文法得到的。
b 现在广泛使用的解析算法存在计算机计算限制。基于转换的方法只能产生投射性的树,因此任何有非投射性结构的句子用其计算时就会出错。这种限制促使了更灵活的基于图的解析方法。
13.3 Dependency Treebanks
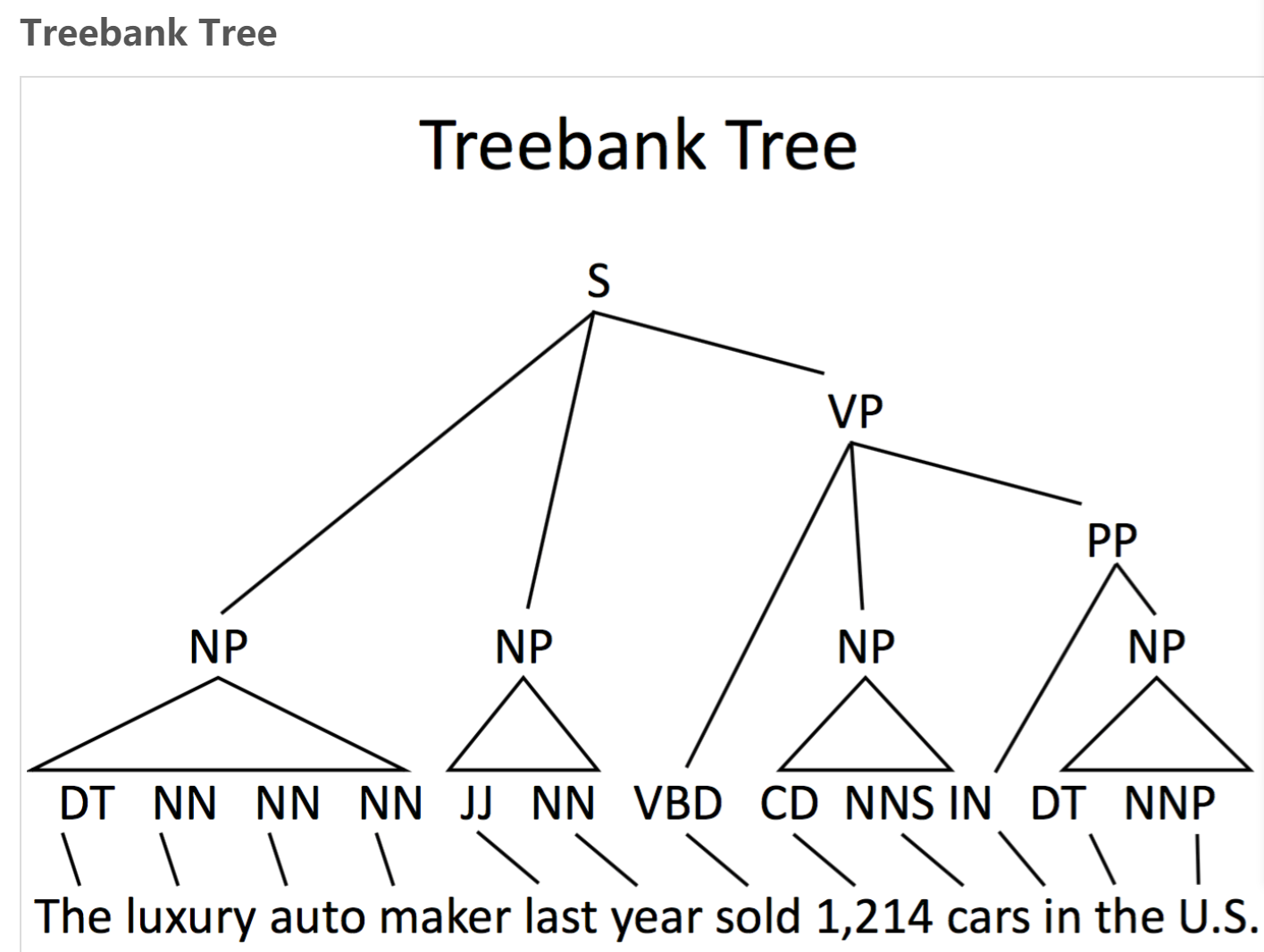
作为基于内容的方法,树库在依存器的发展和评估中起到了重要的作用。依存树库的创建使用了和第十章相似的方法,由人类标注者直接生成给定语料的依存结构,或者使用自动解析器给出最初的解析,然后让标注者手工修正。我们也使用了一个决定性的过程使用head rules来将已有的基于内容的树库翻译成依存库。
最有名的依存句法方法-Prague Dependency Treebank for Czech (PDT)
主要的英语依存树库是从Penn Treebank中的华尔街日报部分
从内容转换机构过程分为两子过程:
a、确认结构中所有头依赖的关系
b、确认所有这些关系的正确的依赖关系
a部分依赖于使用第十章中的head rules
转:
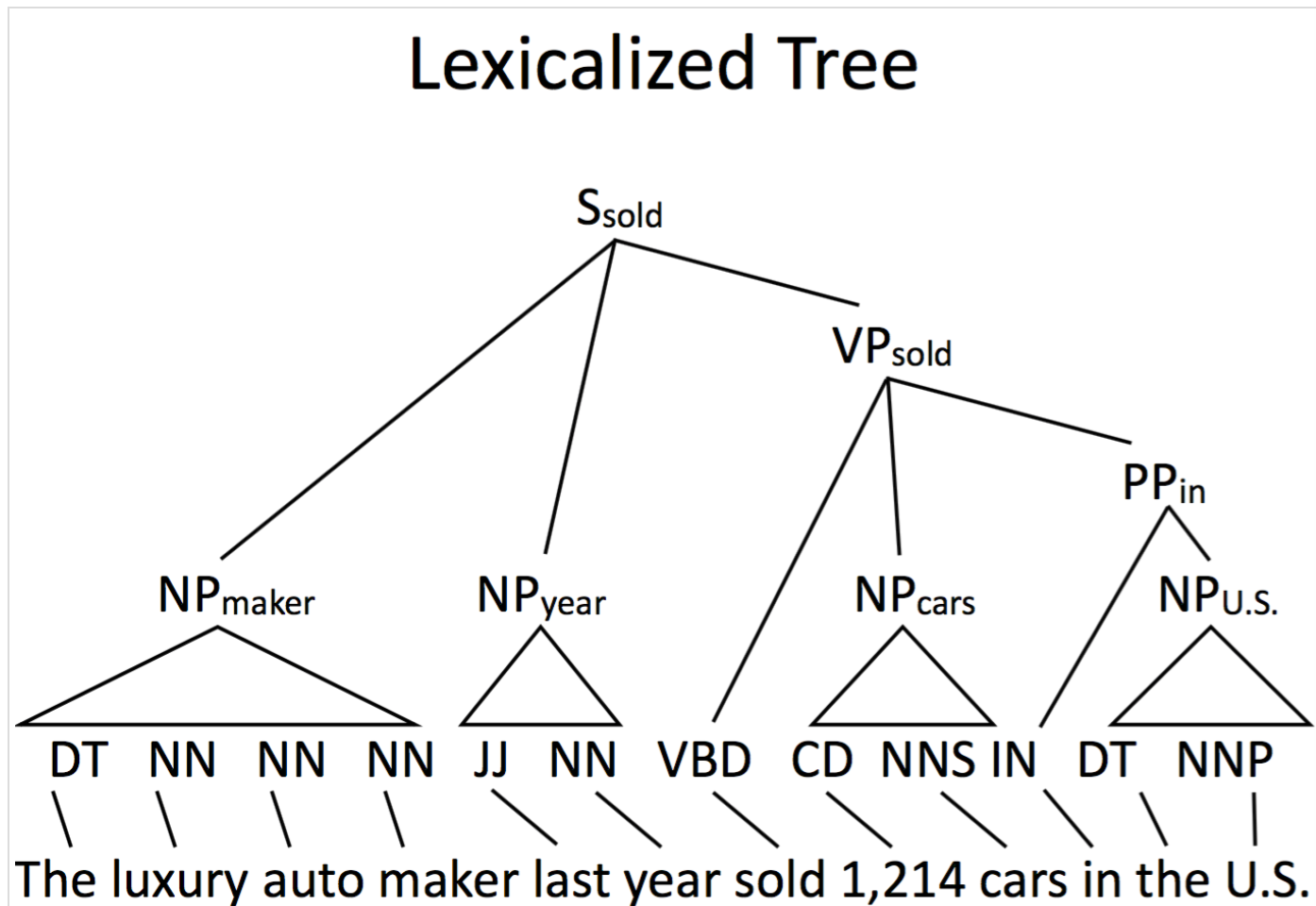
来考虑一下 production rules 是怎么产生的,过去很长一段时间用的都是 hand-written grammars,需要专家编写,很难 scale,覆盖率也非常有限,所以人们手工建立了 treebank,也就是对某些语料集做的标注(annotated data),之后 production rules 就可以通过算法直接从 treebank 抽取。
利用 Head rules,我们可以将 Penn Treebank tree 自动转化为一个 dependency tree,一些规则如下:
|
1
2
3
4
5
6
7
|
NP
If there is an NN daughter, the rightmost NN daughter is the head.
If there is an NP daughter, the leftmost NP daughter is the head.
If there is an NNP daughter , the rightmost NNP daughter is the head.
S
If there is a VP daughter, the leftmost VP daughter is the head.
ETC.
|
- Reusability of the labor
- Many parsers, POS taggers, etc.
一个 treebank 包含了很多种信息,可以用于多种 parser - Valuable resource for linguistics
- Broad coverage
Penn Treebank 包含了多个语料库(Brown Corpus/Wall Street Journal/ATIS/Switchboard),每个语料库有大约一百万的单词,覆盖很广 - Frequencies and distributional information
包含了 frequency 信息 - Use Machine Learning algorithms to train parsers
把 treebank 数据分为 training set/dev set/test set,来训练 parser 吧~ - A way to evaluate systems
可以用来评估 parser 效果
最大的一个问题是 too big to fail。因为建立这些 treebank 很费时费力费钱,所以它们不能轻易的被替代;另外,尽管大多数的决定是由专家来做的,然而大多数的 coding 确是由非专家来完成的,而这些人也处于高压以及有限预算下,treebank 并不是尽善尽美的。
13.4 Transition-Based Dependency Parsing 基于转换的依存分析器
我们依存分析的第一种方式是收到称为shift-reduce parsing移位规约分析的基于栈的方法,最终是用来分析编程语言的。这种经典的方法简单精炼,应用CFG、栈和tokens列表就可以实现parsed。
configuration:包含栈、单词的输入buffer或者tokens、表示依存树的关系集合
对栈前面两个元素进行的操作:leftarc、rightarc、shift
arc standard:transition-based parsing的操作的集合~高效、简单
规定:
ROOT节点不能有箭头指向它,leftarc操作不能用在root是栈的第二个元素时
两种reduce规约操作都要求栈的两个元素用到了
transition-based依存分析器~dependency parse函数~返回句法树:
state←{[root], [words], [] } ; initial configuration
while state not final
t←ORACLE(state) ; choose a transition operator to apply
state←APPLY(t, state) ; apply it, creating a new state
return state
结束:句子的所有单词都已经被使用过,而且栈种只剩下唯一元素-root节点
优点:算法高效,复杂度和句子的长度成线性,属于贪婪算法
过程讲解:https://blog.csdn.net/u014422406/article/details/53954823
注意:
a、过程不止一种,都可以得到一样的合理的parse结果
b、这里假设了oracle总是会得出正确的操作,但这个假设在实际中是不成立的,因此,给定贪婪算法的方法,不正确的选择回到这不正确的parses因为parser没有机会回头来选择其他的方法。13.4.2部分会介绍别的方法,它们transition-based的方法来更充分的探索搜索空间。
c、这里介绍的这个例子是没有依存关系的标签的,为了产生带有标签的树,我们可以用依存标签来参数化leftarc和rightarc操作,例如LEFTARC(NSUBJ)或者RIGHTARC(DOBJ). 这就相当于把转换操作集合从之前的三种元素扩展为使用到的依存关系的集合再加上一个shift操作符。当然这也会使得oracle更加困难因为它有了更大的操作符集合去选择。
creating an oracle:
当下transition-based系统使用监督机器学习方法来训练分类器,这对oracle起到了作用。给定合适的训练数据,这些方法会学到一个函数,将configuration映射到transition操作上。再所有监督机器学习方法中,我们需要使用合适的训练数据,抽取对分类有效的特征。这种训练数据的来源需要是包含依存树的有代表性的treebanks。特征需要包含许多我们在第八章用于POS的特征,也有十二章中用于统计parsing模型的特征。
生成训练数据:
为了训练分类器,我们需要将configurations和transition操作(如leftarc、shift)配对。不幸的是,treebanks将整个句子和相应的树配对,因此它们并不能直接提供我们想要的。为了得到需要的训练数据,我们需要灵活应用oracle-based paring算法。我们用来自treebank的相应的作为参考的parses和训练句子一起,应用oracle来parse它们。为了产生训练句子,接着要通过运行算法并依赖一个新的training oracle来模仿parser的操作,这将会给每个连续的configuration提供正确的transition操作。
因为我们每个训练的句子都有一个gold-standard参考parse,所以我们就知道哪一个依存关系是对给定的句子有效的,因此我们在parser遍历configurations序列时,使用这个参考parse来引导operators的选择。更准确的说,给定一个参考parse和一个configuration,训练oracle的过程如下:
..........结合后面的例子,特别要注意的是:rightarc时,一定要栈内的所有单词都“被依赖”了
feature template 特征模板:自动从训练数据中生成特征
过程可以看下那个例子。。。。。。
learning:
过去几年,训练transition-based dependency parser的主流方法是多项逻辑回归和支持向量机,两个都是有效利用了sparse 特征。现在,神经网络、深度学习的方法也成功应用在transition-based parsing上。这些方法不再需要复杂的、手工的特征
Advanced Methods in Transition-Based Parsing:
arc eager transition system弧线跃迁:
名字来源:可以更快的插入rightward的关系
过程:增加了REDUCE操作,加速的原因可以使得词尽可能早的找到head
优点:新的transition系统中不需要改变潜在的parsing算法
看例子就懂啦。。。。
beam search:
上述讲的各种方法都是在每次做决定的时候都贪婪的做选择没有考虑其他方式
beam search:在系统内搜索决策系列,选择最好的,结合用heuristic filter启发式滤波器实现的breadth-first广度优先搜索策略,将搜索范围固定在beam width范围内。
代替在每次迭代中选择单个最佳transition操作,我们将把所有适用的运算符应用于agenda的每个状态,然后对得到的configuration进行评分。然后,我们将这些新configuration中的每一个添加到frontier边界,这会收到beam大小的约束。只要agenda的大小是在beam width范围内,我们就可以向agenda中加入新的configuration。一旦agenda达到限制,我们只能用比agenda里最差的configuration更好的新configuration替换它。最后,为了确保我们提取除了agenda中最好的可能的state,过程会一直循环下去知道agenda达到终止条件。
我们假设训练的分类器所使用的监督机器学习的作用是oracle,基于从现有的configuration中提取的特征来选择最好的transition操作。尽管learning方法是特定的,这个选择会被视为给所有可能的transition评分然后选择最好的。
gragh-based依存parsing:
在tree的空间中搜索最大化得分,search space编码为直接的graghs,利用图论的知识来搜索最优解决方案。更一般的形式是:给定一个句子s,我们搜索最佳的依存树。
edge-factored方法:树的得分是组成树的边的得分的和
使用gragh-based方法的原因:
a、不像transition-based方法,这些方法可以产生非投射性的树。即使投射性不是英语中的一个重要问题,但是它对于世界上很多语言来说是一个problem。
b、transition-based方法在短依赖关系上有更高的准确率,但是head和dependent之间的关系增加时准确率就会下降。gragh-based方法避免了给整个树评分的困难,而不是依赖于贪婪的local decisions。
parsing:
使用maximum spanning tree(MST)最大生成树算法解决带权重的有向图。
给定一个输入的句子,即一个全连接的、带权重的、有方向的gragh,顶点是输入的words,有向边代表所有可能的head-dependent关系。另外还有一个root节点以及root指向所有顶点的边。gragh上的权重反映了每个可能的head-dependent关系的得分,这个得分是由训练数据得到的模型产生的。给定这些权重,一个从root开始的这个graph对应的最大生成树就代表了这个句子的首选的dependency parse。
a、最大生成树中的每一个顶点都有一个incoming边(代表一个可能的head assignment)
b、每个边的绝对值对于最大生成树并不重要,重要的是enter每个顶点的权重。
缺点:当边集合中包含圈的时候就得不到树了
改进:cleanup phrase
还有使用rnn来进行multilingual parsing,这样只需要用到用word embedding表示的lexical信息,而不需要手工特征。
evaluate:
测试在测试集上dependency parser的效果
metric:
exact match即EM
labeled attachment score (LAS) and unlabeled attachment score (UAS). Finally, we can make use of a label accuracy score (LS), the percentage of tokens with correct labels, ignoring where the relations are coming from.其中Labeled attachment是word和它的head以及正确的依存关系,unlabeled attachment仅仅看词和head的正确率,不管依存关系。
这个看例子就懂了 。。。也就是说因为UAS中实不care依存关系到底是啥,也就是箭头上的label,所以USA的准确率就只需要看箭头标得起始终止位置是否正确就ok啦
precison和recall:一个系统在某种类型的依存类型例如NSUBJ上的性能,使用development
混淆矩阵:每个依存类型和别的混淆的频率
Dependency Parsing -13 chapter(Speech and Language Processing)的更多相关文章
- Formal Grammars of English -10 chapter(Speech and Language Processing)
determiner 限定词 DET propernoun 专有名词 NP (or noun phrase) mass noun 不可数名词 Det Nouns 限定词名词 relative pro ...
- Python第三方库SnowNLP(Simplified Chinese Text Processing)快速入门与进阶
简介 github地址:https://github.com/isnowfy/snownlp SnowNLP是一个python写的类库,可以方便的处理中文文本内容,是受到了TextBlob的启发而写的 ...
- NLP(Natural Language Processing)
https://github.com/kjw0612/awesome-rnn#natural-language-processing 通常有: (1)Object Recognition (2)Vis ...
- 水晶报表13.x(Crystal Reports for VS2010)的安装部署经验
这两天搞安装包真心坎坷,一个问题接一个问题,先是为了实现自定义动作现啃vbs,后面又是安装过程老是报错: 各种搜索.各种尝试,总算搞掂,积累了些经验,分享一下. 首先CR for VS2010的所有东 ...
- SDN 编程语言 p4(SDN programming language P4)
行业趋势,SND是未来. P4 是未来. SDN is inevitably, and P4 is inevitably. P4 = Programming Protocol-Independent ...
- Intellij Idea 13 快捷键(与Eclipse比对)以及基本的设置
详见:http://blog.yemou.net/article/query/info/tytfjhfascvhzxcyt404 刚到新公司,用的台式机配置不给力,Eclipse很不给力,几个项目一起 ...
- Kubespray部署Kubernetes 1.13.0(使用本地镜像仓库)
1. 下载kubespray # git clone https://github.com/kubernetes-sigs/kubespray.git # cd kubespray # pip ins ...
- 学习笔记之自然语言处理(Natural Language Processing)
自然语言处理 - 维基百科,自由的百科全书 https://zh.wikipedia.org/wiki/%E8%87%AA%E7%84%B6%E8%AF%AD%E8%A8%80%E5%A4%84%E7 ...
- 2015年第13本(英文第9本):Murder on the Orient Express 东方快车谋杀案
书名:Murder on the Orient Express 东方快车谋杀案 作者:Agatha Christie 单词数:6.1万 不重复单词数:不详 首万词不重复单词数:不详 蓝思值:640 阅 ...
随机推荐
- 使用Spring-data-jpa(1)(三十)
在实际开发过程中,对数据库的操作无非就“增删改查”.就最为普遍的单表操作而言,除了表和字段不同外,语句都是类似的,开发人员需要写大量类似而枯燥的语句来完成业务逻辑. 为了解决这些大量枯燥的数据操作语句 ...
- 【Jmeter基础知识】Jmeter响应断言和断言结果
一.Jmeter创建一个响应断言 1.步骤:添加--断言--响应断,进入响应断言页面 2.断言内容:可以采用直接去搜索某些文本信息,或者可以去断言某个变量,如图 二.Jmeter创建一个断言结果 1. ...
- Win10系列:VC++绘制位图图片
在使用Direct2D绘制图片的过程中,通过IWICImagingFactory工厂接口来得到绘制图片所需要的资源.本小节将介绍如何通过IWICImagingFactory工厂接口得到这些资源,并使用 ...
- Python Django 之 Template 模板的使用
一.模板样式 注意: 1.url urlpatterns = { path('admin/', admin.site.urls), path('order/', views.order), path( ...
- vue-14-过滤
过滤器可以用在两个地方:mustache 插值和 v-bind 表达式 <!-- in mustaches --> {{ message | capitalize }} <!-- i ...
- 深入理解java虚拟机---虚拟机工具jstat(十七)
jstack---没什么用 jstack用于生成java虚拟机当前时刻的线程快照.线程快照是当前java虚拟机内每一条线程正在执行的方法堆栈的集合,生成线程快照的主要目的是定位线程出现长时间停顿的原因 ...
- windows文件映射
0x01 使用文件映射实现共享内存. 用内存映射文件实现进程间的通讯:Windows中的内存映射文件的机制为我们高效地操作文件提供了一种途径,它允许我们在进程中保留一段内存区域,把硬盘或页文件上的目标 ...
- android 广播 接收短信
; i < messages.length; i++) { SmsMessage ms = SmsMessage.createFromPdu((byte[])pdus[i]); String f ...
- Final阶段第1周/共1周 Scrum立会报告+燃尽图 06
作业要求[https://edu.cnblogs.com/campus/nenu/2018fall/homework/2485] 版本控制:https://git.coding.net/liuyy08 ...
- oracle 12c中种子数据库的隐藏与保护
Oracle 12c种子数据库(pdbseed)的状态是read only,这是因为Oracle对种子数据库进行了保护,避免遭到破坏.保护好种子数据库的目的,是为了以此为模板,新建pdb数据库. 新的 ...