开源数据采集组件比较: scribe、chukwa、kafka、flume
针对每天TB级的数据采集,一般而言,这些系统需要具有以下特征:
- 构建应用系统和分析系统的桥梁,并将它们之间的关联解耦;
- 支持近实时的在线分析系统和类似于Hadoop之类的离线分析系统;
- 具有高可扩展性。即:当数据量增加时,可以通过增加节点进行水平扩展。
从设计架构,负载均衡,可扩展性和容错性等方面对开源的个关组件进行说明
FaceBook的Scribe
Scribe是facebook开源的日志收集系统,在facebook内部已经得到大量的应用。它能够从各种日志源上收集日志,存储到一个中央存储系统 (可以是NFS,分布式文件系统等)上,以便于进行集中统计分析处理。它为日志的“分布式收集,统一处理”提供了一个可扩展的,高容错的方案。
它最重要的特点是容错性好。当后端的存储系统crash时,scribe会将数据写到本地磁盘上,当存储系统恢复正常后,scribe将日志重新加载到存储系统中。
架构:scribe的架构比较简单,主要包括三部分,分别为scribe agent, scribe和存储系统。
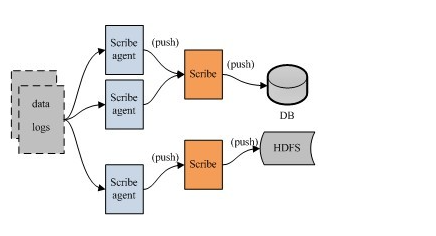
(1) scribe agent
scribe agent实际上是一个thrift client。 向scribe发送数据的唯一方法是使用thrift client, scribe内部定义了一个thrift接口,用户使用该接口将数据发送给server
(2) scribe
scribe接收到thrift client发送过来的数据,根据配置文件,将不同topic的数据发送给不同的对象。scribe提供了各种各样的store,如 file, HDFS等,scribe可将数据加载到这些store中。
(3) 存储系统
存储系统实际上就是scribe中的store,当前scribe支持非常多的store,包括:
- file(文件)
- buffer(双层存储,一个主储存,一个副存储)
- network(另一个scribe服务器)
- bucket(包含多个 store,通过hash的将数据存到不同store中)
- null(忽略数据)
- thriftfile(写到一个Thrift TFileTransport文件中)
- multi(把数据同时存放到不同store中)。
Apache的Chukwa
chukwa是一个属于hadoop系列产品,因而使用了很多hadoop的组件(用HDFS存储,用mapreduce处理数据),它提供了很多模块以支持hadoop集群日志分析。其架构示意图如下:
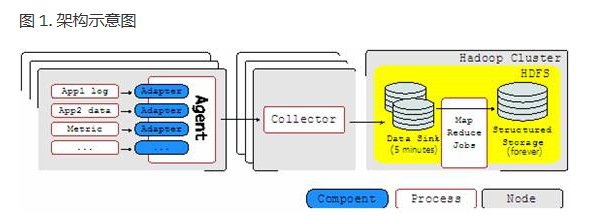
Chukwa中主要有3种角色,分别为:adaptor,agent,collector
Agent
- agent 是驻守在各个节点上的负责收集数据的程序。
- Agent 又由若干 adapter 组成。
- adapter 运行在 Agent 进程以内,执行实际收集数据的工作。
- 而 Agent 则负责 adapter 的管理(给adaptor提供各种服务,包括:启动和关闭adaptor,将数据通过HTTP传递给Collector;定期记录adaptor状态,以便crash后恢复)
Collector
- 对多个数据源发过来的数据进行合并,然后加载到HDFS中;隐藏HDFS实现的细节,如,HDFS版本更换后,只需修改collector即可
HDFS 存储系统
- Chukwa采用了HDFS作为存储系统。
- HDFS的设计初衷是支持大文件存储和小并发高速写的应用场景,而日志系统的特点恰好相反,它需支持高并发低速率的写和大量小文件的存储。
- 需要注意的是,直接写到HDFS上的小文件是不可见的,直到关闭文件,另外,HDFS不支持文件重新打开
Demux和achieving
- 直接支持利用MapReduce处理数据。
- 它内置了两个mapreduce作业,分别用于获取data和将data转化为结构化的log。存储到data store(可以是数据库或者HDFS等)中
LinkedIn的Kafka
Kafka是2010年12月份开源的项目,采用scala语言编写,使用了多种效率优化机制,整体架构比较新颖(push/pull),更适合异构集群。主要的设计元素如下:
- afka在设计之时为就将持久化消息作为通常的使用情况进行了考虑。
- 主要的设计约束是吞吐量而不是功能。
- 有关哪些数据已经被使用了的状态信息保存为数据使用者(consumer)的一部分,而不是保存在服务器之上。
- Kafka是一种显式的分布式系统。它假设,数据生产者(producer)、代理(brokers)和数据使用者(consumer)分散于多台机器之上。
架构:
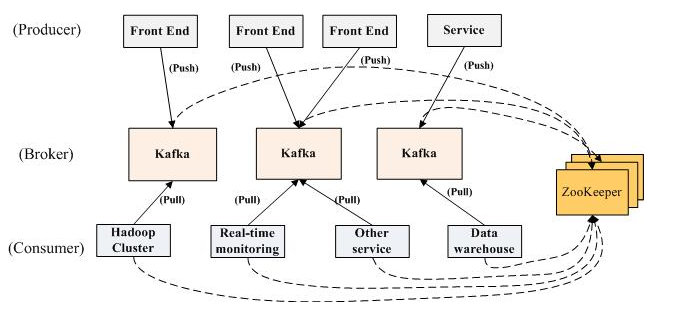
- Kafka实际上是一个消息发布订阅系统。
- producer向某个topic发布消息,而consumer订阅某个topic的消息,进而一旦有新的关于某个topic的消息,broker会传递给订阅它的所有consumer。
- 在kafka中,消息是按topic组织的,而每个topic又会分为多个partition,这样便于管理数据和进行负载均衡。
- 同时,它也使用了zookeeper进行负载均衡。
Kafka中主要有三种角色,分别为producer,broker和consumer
Producer
- Producer的任务是向broker发送数据。
- Kafka提供了两种producer接口,一种是low_level接口,使用该接口会向特定的broker的某个topic下的某个partition发送数据;另一种那个是high level接口,该接口支持同步/异步发送数据,基于zookeeper的broker自动识别和负载均衡(基于Partitioner)。
- 其中,基于zookeeper的broker自动识别值得一说。producer可以通过zookeeper获取可用的broker列表,也可以在zookeeper中注册listener,该listener在以下情况下会被唤醒:
- a.添加一个broker
- b.删除一个broker
- c.注册新的topic
- d.broker注册已存在的topic
Broker
Broker采取了多种策略提高数据处理效率,包括sendfile和zero copy等技术
Consumer
- consumer的作用是将日志信息加载到中央存储系统上。
- kafka提供了两种consumer接口,一种是low level的,它维护到某一个broker的连接,并且这个连接是无状态的,即,每次从broker上pull数据时,都要告诉broker数据的偏移量。另一种是high-level 接口,它隐藏了broker的细节,允许consumer从broker上push数据而不必关心网络拓扑结构。
- 更重要的是,对于大部分日志系统而言,consumer已经获取的数据信息都由broker保存,而在kafka中,由consumer自己维护所取数据信息。
Cloudera的Flume
Flume是cloudera于2009年7月开源的日志系统。它内置的各种组件非常齐全,用户几乎不必进行任何额外开发即可使用。设计目标如下:
- 可靠性: 当节点出现故障时,日志能够被传送到其他节点上而不会丢失。Flume提供了三种级别的可靠性保障,从强到弱依次分别为:可扩展性 : Flume采用了三层架构,分别问agent,collector和storage,每一层均可以水平扩展。其中,所有agent和collector由master统一管理,这使得系统容易监控和维护,且master允许有多个(使用ZooKeeper进行管理和负载均衡),这就避免了单点故障问题
- end-to-end(收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送。)
- Store on failure(这也是scribe采用的策略,当数据接收方crash时,将数据写到本地,待恢复后,继续发送)
- Best effort(数据发送到接收方后,不会进行确认)
- 可扩展性:Flume采用了三层架构,分别问agent,collector和storage,每一层均可以水平扩展。其中,所有agent和collector由master统一管理,这使得系统容易监控和维护,且master允许有多个(使用ZooKeeper进行管理和负载均衡),这就避免了单点故障问题
- 可管理性:所有agent和colletor由master统一管理,这使得系统便于维护。用户可以在master上查看各个数据源或者数据流执行情况,且可以对各个数据源配置和动态加载。Flume提供了web 和shell script command两种形式对数据流进行管理
- 功能可扩展性: 用户可以根据需要添加自己的agent,colletor或者storage。此外,Flume自带了很多组件,包括各种agent(file, syslog等),collector和storage(file,HDFS等)。
架构图:
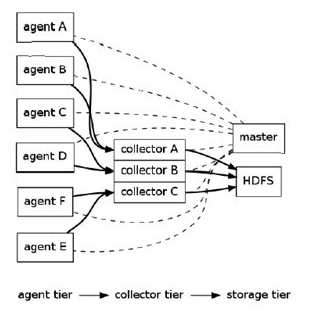
Flume采用了分层架构,由三层组成,分别为agent,collector和storage。其中,agent和collector均由两部分组成:source和sink,source是数据来源,sink是数据去向。
(1) agent :agent的作用是将数据源的数据发送给collector,Flume自带了很多直接可用的数据源(source),如:
- text(“filename”):将文件filename作为数据源,按行发送
- tail(“filename”):探测filename新产生的数据,按行发送出去
- fsyslogTcp(5140):监听TCP的5140端口,并且接收到的数据发送出去
- 同时提供了很多sink,如:
- console[("format")] :直接将将数据显示在桌面上
- text(“txtfile”):将数据写到文件txtfile中
- dfs(“dfsfile”):将数据写到HDFS上的dfsfile文件中
- syslogTcp(“host”,port):将数据通过TCP传递给host节点
(2) collector:collector的作用是将多个agent的数据汇总后,加载到storage中。它的source和sink与agent类似。
(3) storage : storage是存储系统,可以是一个普通file,也可以是HDFS,HIVE,HBase等。
event的相关概念:
flume的核心是把数据从数据源(source)收集过来,在将收集到的数据送到指定的目的地(sink)。为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,flume在删除自己缓存的数据。如下图:
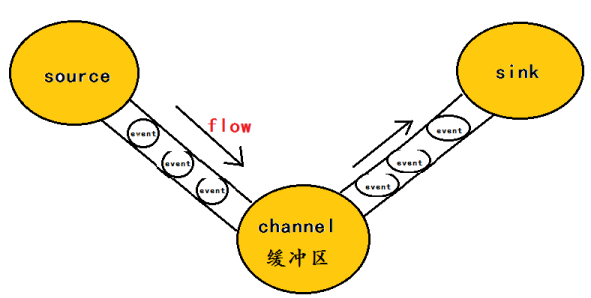
在整个数据的传输的过程中,流动的是event,即事务保证是在event级别进行的。那么什么是event呢?—–event将传输的数据进行封装,是flume传输数据的基本单位,如果是文本文件,通常是一行记录,event也是事务的基本单位。event从source,流向channel,再到sink,本身为一个字节数组,并可携带headers(头信息)信息。event代表着一个数据的最小完整单元,从外部数据源来,向外部的目的地去。
总结
根据这四个系统的架构设计,可以总结出系统需具备三个基本组件,分别为agent(封装数据源,将数据源中的数据发送给collector),collector(接收多个agent的数据,并进行汇总后导入后端的store中),store(中央存储系统,应该具有可扩展性和可靠性,应该支持当前非常流行的HDFS)。
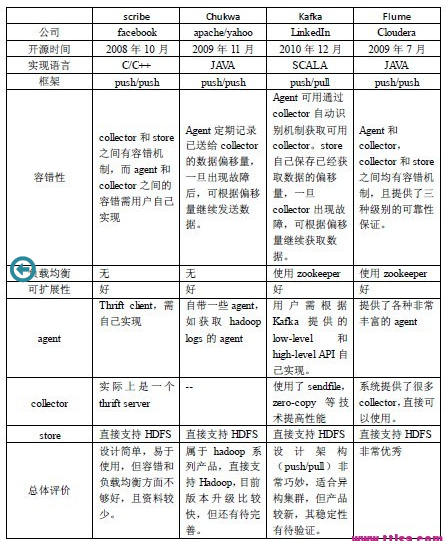
四个系统结果对比分析如下:
参考资料:
- https://www.ibm.com/developerworks/cn/opensource/os-cn-chukwa/
- http://www.open-open.com/lib/view/open1386814790486.html
开源数据采集组件比较: scribe、chukwa、kafka、flume的更多相关文章
- java企业架构 spring mvc +mybatis + KafKa+Flume+Zookeeper
声明:该框架面向企业,是大型互联网分布式企业架构,后期会介绍linux上部署高可用集群项目. 项目基础功能截图(自提供了最小部分) 平台简介 Jeesz是一个分布式的框架,提供 ...
- MySQL数据实时增量同步到Kafka - Flume
转载自:https://www.cnblogs.com/yucy/p/7845105.html MySQL数据实时增量同步到Kafka - Flume 写在前面的话 需求,将MySQL里的数据实时 ...
- Net Core开源通讯组件 SmartRoute
Net Core开源通讯组件 SmartRoute(服务即集群) SmartRoute是基于Dotnet Core设计的可运行在linux和windows下的服务通讯组件,其设计理念是去中心化和零配置 ...
- 【干货】.NET开发通用组件发布(三) 简易数据采集组件
组件介绍和合作开发 http://www.cnblogs.com/MrHuo/p/MrHuoControls.html 简易数据采集组件 怎么说他是一个简易的数据采集组件呢?因为由于时间仓促,缺少从某 ...
- 开源通讯组件ec
跨平台开源通讯组件elastic communication elastic communication是基于c#开发支持.net和mono的通讯组件(简称EC),EC的主要目的简化mono和.net ...
- .NET开源Protobuf-net组件修炼手册
一.前言 Protocol Buffer(简称Protobuf或PB) 是一个跨平台的消息交互协议,类似xml.json等 :别只会用Json和XML了,快来看看Google出品的Protocol B ...
- .NET开源Protobuf-net组件葵花手册
一.前言 我们都知道 protobuf是由Google开发的一款与平台无关,语言无关,可扩展的序列化结构数据格式,可用做数据存储格式, 通信协议 ! 在前面<.NET开源Protobuf-net ...
- 鸿蒙开源第三方组件——SlidingMenu_ohos侧滑菜单组件
目录: 1.前言 2.背景 3.效果展示 4.Sample解析 5.Library解析 6.<鸿蒙开源第三方组件>文章合集 前言 基于安卓平台的SlidingMenu侧滑菜单组件(http ...
- 【全网首发】鸿蒙开源三方组件--强大的弹窗库XPopup组件
目录: 1.介绍 2.效果一览 3.依赖 4.如何使用 5.下载链接 6.<鸿蒙开源三方组件>文章合集 1. 介绍 XPopup是一个弹窗库,可能是Harmony平台最好的弹窗库.它从 ...
随机推荐
- Js代码一些要素
---恢复内容开始--- 条件语句 is(条件){ 语句 }else { 语句 } {}在js中我们把他叫代码块.如果代码块里内容没有执行完,语句就不会向下执行. 代码块是一个独立的整体.如果js中莫 ...
- Spring的PropertyPlaceholderConfigurer
在项目中我们一般将配置信息(如数据库的配置信息)配置在一个properties文件中,如下: jdbcUrl=jdbc:mysql://localhost:3306/flowable?useUnico ...
- 自动化测试-22.RobotFrameWork鼠标和键盘的操作针对出现window界面的处理
键盘和鼠标的操作:使用AutoItLibrary模块 1.安装pywin32 http://sourceforge.net/projects/pywin32/files/pywin32/Build%2 ...
- canvas默认是黑色全透明,不是白色全透明。
- 【linux基础】如何查看Linux系统是64位还是32位
如何查看Linux系统是64位还是32位 $getconf LONG_BIT or $file /bin/ls or #查看linux版本 $lsb_release -a or $uname -a 参 ...
- Java中的数组初探
1.数组的类型? Java中的数组为引用类型. 2.数组的三种初始化方式 1. int[] arr1=new int[] {1,2,3,4,}; 2. int[] arr2= {1,2,3,4,}; ...
- 使用Python中的log模块将loss输出到终端与保存到文件
记得之前对深度学习中得loss输出,经常自己会将输出流重新定向到一个文件中, 比如 python main.py > & | tee log.txt 对于caffe这种c++框架而言,用 ...
- maven 构建 war文件&&Glassfish运行+部署war文件+访问(命令行模式)
Glassfish常用命令 asadmin start-domain --verbose #启动Glassfish服务器(默认domain1) ,并在终端显示相关信 ...
- next_permutation(start,end)
一道水题,简单的next_permutation用法,相同的还有prev_permutation 包含在头文件<algorithm>中 字符串 acab 含有两个a ,一个b ,一个c , ...
- Mysql的两种引擎
Innodb引擎: 1.Innodb引擎提供了对数据库ACID事务的支持,并且实现了SQL标准的四种隔离级别 2.该引擎还提供了行级锁和外键约束,它的设计目标是处理大容量数据库系统,它本身其实就是基于 ...