条件随机场之CRF++源码详解-训练
上篇的CRF++源码阅读中, 我们看到CRF++如何处理样本以及如何构造特征。本篇文章将继续探讨CRF++的源码,并且本篇文章将是整个系列的重点,会介绍条件随机场中如何构造无向图、前向后向算法、如何计算条件概率、如何计算特征函数的期望以及如何求似然函数的梯度。本篇将结合条件随机场公式推导和CRF++源码实现来讲解以上问题。
开启多线程
我们接着上一篇encoder.cpp文件中的learn函数继续看,该函数的下半部分将会调用具体的学习算法做训练。目前CRF++支持两种训练算法,一种是拟牛顿算法中的LBFGS算法,另一种是MIRA算法, 本篇文章主要探讨LBFGS算法的实现过程。在learn函数中,训练算法的入口代码如下:
switch (algorithm) {
case MIRA: //MIRA算法的入口
if (!runMIRA(x, &feature_index, &alpha[],
maxitr, C, eta, shrinking_size, thread_num)) {
WHAT_ERROR("MIRA execute error");
}
break;
case CRF_L2: //LBFGS-L2正则化的入口函数
if (!runCRF(x, &feature_index, &alpha[],
maxitr, C, eta, shrinking_size, thread_num, false)) {
WHAT_ERROR("CRF_L2 execute error");
}
break;
case CRF_L1: //LBFGS-L1正则化的入口函数
if (!runCRF(x, &feature_index, &alpha[],
maxitr, C, eta, shrinking_size, thread_num, true)) {
WHAT_ERROR("CRF_L1 execute error");
}
break;
}
runCRF函数中会初始化CRFEncoderThread数组,并启动每个线程,源码如下:
bool runCRF(const std::vector<TaggerImpl* > &x,
EncoderFeatureIndex *feature_index,
double *alpha,
size_t maxitr,
float C,
double eta,
unsigned short shrinking_size,
unsigned short thread_num,
bool orthant) {
... //省略代码
for (size_t itr = ; itr < maxitr; ++itr) { //开始迭代, 最大迭代次数为maxitr,即命令行参数-m
for (size_t i = ; i < thread_num; ++i) {
thread[i].start(); //启动每个线程,start函数中会调用CRFEncoderThread类中的run函数
} for (size_t i = ; i < thread_num; ++i) {
thread[i].join(); //等待所有线程结束
}
... //省略代码
CRFEncoderThread类中的run函数调用gradient函数,完成一系列的核心计算。源码如下:
void run() {
obj = 0.0;
err = zeroone = ;
std::fill(expected.begin(), expected.end(), 0.0); //excepted变量存放期望
for (size_t i = start_i; i < size; i += thread_num) {//每个线程并行处理多个句子, 并且每个线程处理的句子不相同, size是句子的个数
obj += x[i]->gradient(&expected[]); //x[i]是TaggerImpl对象,代表一个句子, gradient函数主要功能: 1. 构建无向图 2. 调用前向后向算法 3. 计算期望
int error_num = x[i]->eval();
err += error_num;
if (error_num) {
++zeroone;
}
}
}
构造无向图
我们知道条件随机场是概率图模型,几乎所有的概率计算都是在无向图上进行的。那么这个图是如果构造的呢?答案就在gradient函数第一个调用 —— buildLattice函数中。该函数完成2个核心功能,1. 构建无向图 2. 计算节点以及边上的代价,先看一下无向图的构造过程:
void TaggerImpl::buildLattice() {
if (x_.empty()) {
return;
}
feature_index_->rebuildFeatures(this); //调用该方法初始化节点(Node)和边(Path),并连接
... //省略代码
}
void FeatureIndex::rebuildFeatures(TaggerImpl *tagger) const {
size_t fid = tagger->feature_id(); //取出当前句子的feature_id,上篇介绍构造特征的时候,在buildFeatures函数中会set feature_id
const size_t thread_id = tagger->thread_id();
Allocator *allocator = tagger->allocator();
allocator->clear_freelist(thread_id);
FeatureCache *feature_cache = allocator->feature_cache();
//每个词以及对应的所有可能的label,构造节点
for (size_t cur = ; cur < tagger->size(); ++cur) { //遍历每个词,
const int *f = (*feature_cache)[fid++]; //取出每个词的特征列表,词的特征列表对应特征模板里的Unigram特征
for (size_t i = ; i < y_.size(); ++i) { //每个词都对应不同的label, 每个label用数组的下标表示,每个特征+当前的label就是特征函数
Node *n = allocator->newNode(thread_id); //初始化新的节点,即Node对象
n->clear();
n->x = cur; //当前词
n->y = i; //当前词的label
n->fvector = f; //特征列表
tagger->set_node(n, cur, i); //有一个二维数组node_存放每个节点
}
}
//从第二个词开始构造节点之间的边,两个词之间有y_.size()*y_.size()条边
for (size_t cur = ; cur < tagger->size(); ++cur) {
const int *f = (*feature_cache)[fid++]; //取出每个边的特征列表,边的特征列表对应特征模板里的Bigram特征
for (size_t j = ; j < y_.size(); ++j) {//前一个词的label有y_.size()种情况,即y_.size()个节点
for (size_t i = ; i < y_.size(); ++i) {//当前词label也有y_.size()种情况,即y_.size()个节点
Path *p = allocator->newPath(thread_id);//初始化新的节点,即Path对象
p->clear();
//add函数会设置当前边的左右节点,同时会把当前边加入到左右节点的边集合中
p->add(tagger->node(cur - , j), //前一个节点
tagger->node(cur, i)); //当前节点
p->fvector = f;
}
}
}
}
图构造完成后, 接下来看看节点和边上的代价是如何计算的。那么代价是什么?我的理解就是特征函数值乘以特征的权重。这部分源码在buildLattice函数中,具体如下:
for (size_t i = ; i < x_.size(); ++i) {
for (size_t j = ; j < ysize_; ++j) {
feature_index_->calcCost(node_[i][j]); //计算节点的代价
const std::vector<Path *> &lpath = node_[i][j]->lpath;
for (const_Path_iterator it = lpath.begin(); it != lpath.end(); ++it) {
feature_index_->calcCost(*it); //计算边的代价
}
}
}
//节点的代价计算函数
void FeatureIndex::calcCost(Node *n) const {
n->cost = 0.0;
#define ADD_COST(T, A) \
do { T c = ; \
for (const int *f = n->fvector; *f != -; ++f) { c += (A)[*f + n->y]; } \ //取每个特征以及当前节点的label,即为特征函数,且值为1,特征函数乘以权重(alpha_[*f + n->y])是代价,特征函数为1所以代价=alpha_[*f + n->y]*1,对所有代价求和
n->cost =cost_factor_ *(T)c; } while () //cost_factor_是代价因子
if (alpha_float_) {
ADD_COST(float, alpha_float_);
} else {
ADD_COST(double, alpha_); //将会在这里调用, 上一篇内容可以看到,CRF++初始化的是alpha_变量
}
#undef ADD_COST
}
//边的代价计算函数与节点类似,不再赘述
看完源码,我们举个例子来可视化一下无向图,仍然用上一篇中构造特征的那个例子。如果忘记了,出门左转回顾一下。上一个例子中有三个词,假设这三个词分别是“我”、“爱”、“你”。构建的无向图如图一所示。
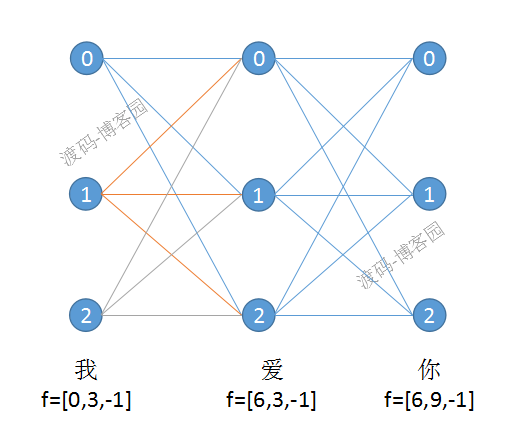
图一
这个例子中,有三个词和三个label,每个label用0,1,2表示,之前我们说过用数组下标代替label。每个词有3个节点,且这三个节点的特征列表f是一样的,由于label不一样,所以他们的特征函数值不一样。由于没有bigram特征,所有边上的特征列表都是f=[-1]。大部分资料的无向图前后会加一个start节点和stop节点,加上后可以便于理解和公式推导。CRF++源码中没加,所以我们这里就没有表示。在这里node_[0][0]对应就是最左上角的节点,代表“我”这个词label为0的节点。我们再看一下node_[0][0]这个节点的代价如何计算的,node_[0][0]的cost = alpha_[0 + 0] + alpha_[3 + 0] = alpha_[0] + alpha_[3],由于alpha_第一次节点初始化为0,所以cost=0。其余节点和边计算方法类似。
前向-后向算法
有了无向图,我们就可以在图上进行前向-后向算法。利用前向-后向算法,很容易计算标记序列在位置i(词)的label是yi的条件概率,以及在位置i-1(前一个词)与位置i(当前词)的label是yi-1与yi的条件概率。进行CRF++源码阅读之前先看一下条件随机场矩阵的表示形式。对一个句子的每一个位置(单词) i=1,2,…,n+1,定义一个 m 阶矩阵(m 是标记 yi 取值的个数),i=0代表start节点, i=n+1代表stop节点。
\begin{aligned} M_i(x) &= \left \{ M_i(y_{i-1},y_i|x)\right \} \\ M_i(y_{i-1},y_i|x)&= \exp \left \{ W_i(y_{i-1} ,y_i|x)\right \}\\ W_i(y_{i-1},y_i|x)&= \sum_{k=1}^Kw_k \cdot f_k(y_{i-1},y_i,x,i) \end{aligned}
\begin{align} f_k(y_{i-1},y_i,x,i) = \left \{ \begin{aligned} &t_k(y_{i-1},y_i,x,i), \ \ k = 1,2,...,K_1 \\ &s_t(y_i,x,i), \ \ \ \ \ \ \ \ \ \ k = K_1 + l ; l = 1,2,...,K_2 \end{aligned}\right. \end{align}
Wi 的解释:当前节点代价 + 与该节点相连的一条边的代价。
节点之间的转移概率,用矩阵的形式表现如下:
\begin{aligned} M_1(x) &= \begin{bmatrix} M_1(0,0|x) & M_1(0,1|x) &M_1(0,2|x) \\ 0 & 0 &0 \\ 0 & 0 &0 \end{bmatrix} \\ \\ M_2(x) &=\begin{bmatrix} M_2(0,0|x) & M_2(0,1|x) & M_2(0,2|x)\\ M_2(1,0|x) & M_2(1,1|x) & M_2(1,2|x)\\ M_2(2,0|x) & M_2(2,1|x) & M_2(2,2|x) \end{bmatrix} \\ \\ M_i(x) \ &\mathbf{has \ the \ same \ form \ with} \ M_2(X), \ i = 3,...,n\\ \\ M_{n+1}(x) &=\begin{bmatrix} 1 & 0 & 0 \\ 1 & 0 & 0 \\ 1&0&0 \end{bmatrix} \\ \end{aligned}
Mi 的解释:以 \begin{aligned} M_2(2,1|x) \end{aligned} 为例,代表第2个位置(第2个词)label是1,前一个词label是2,计算Wi,再取exp后的值。接下来,我们看一下用矩阵表示的前向-后向算法。
对i = 0, 1, 2, ... n+1, 定义前向向量αi(x),对于起始状态i = 0:
\begin{align} \alpha_0(y|x) = \left \{ \begin{aligned} &1, \ \ y = start \\ &0, \ \ else \end{aligned}\right. \end{align}
对于之后的状态 i=1,2,...,n+1,递推公式为:
\begin{aligned} a_i^T(y_i|x) = a^T_{i-1}(y_{i-1}|x)M_i(y_{i-1},y_i|x) \end{aligned}
假设label个数是m,α是m*1的列向量,Mi(yi-1,yi|x) 是m*m的矩阵,α解释:前一个单词每个节点的α分别乘以(与当前节点相连的边的代价 + 当前节点的代价),再求和 。
同样,后向算法β计算, 对于i = 0, 1, 2, ..., n+1,定义后向向量βi(x):
\begin{align} \beta_{n+1}(y_{n+1}|x) = \left \{ \begin{aligned} &1, \ \ y_{n+1} = stop \\ &0, \ \ else \end{aligned}\right. \end{align}
向前递推公式如下:
\begin{aligned} \beta_i(y_i|x) = M_i(y_i,y_{i+1}|x)\beta_{i+1}(y_{i+1}|x) \end{aligned}
βi是m*1的列向量, Mi(yi,yi+1|x)是m*m的矩阵。β解释:(当前词与下一个词连接的边的代价 + 下一个词的代价) 分别乘以下一个词的β,再相加。
由前向-后向向量定义不难得到:
\begin{aligned} Z(x) = a_n^T(x) \cdot \mathbf{1} = \mathbf{1}^T \cdot \beta_1(x) \end{aligned}
需要注意一下,矩阵表示形式的代价是对特征函数乘以权重加和后再取exp的值, 而上面的CRF++ calcCost函数中并没有取exp值。
接下来继续看下α和β在CRF++中是如何计算的。在gradient函数中调用的forwardbackward函数即是这部分的核心代码,具体如下:
void TaggerImpl::forwardbackward() {
if (x_.empty()) {
return;
}
for (int i = ; i < static_cast<int>(x_.size()); ++i) { //前向算法
for (size_t j = ; j < ysize_; ++j) {
node_[i][j]->calcAlpha();
}
}
for (int i = static_cast<int>(x_.size() - ); i >= ; --i) { //后向算法
for (size_t j = ; j < ysize_; ++j) {
node_[i][j]->calcBeta();
}
}
Z_ = 0.0;
for (size_t j = ; j < ysize_; ++j) { //计算Z(x)
Z_ = logsumexp(Z_, node_[][j]->beta, j == );
}
return;
}
void Node::calcAlpha() {
alpha = 0.0;
for (const_Path_iterator it = lpath.begin(); it != lpath.end(); ++it) { //这里遍历当前节点的左边(path)的集合, 对应的就是Mi(yi-1,yi|x)矩阵中的某一列
alpha = logsumexp(alpha,
(*it)->cost +(*it)->lnode->alpha,
(it == lpath.begin())); //函数里面回取exp,因此边的代价 + 上一个节点的α,会转化成相乘,取完exp还会再取log,取log为了方式直接exp导致的溢出
}
alpha += cost; //统一加上当前节点的代价, Mi(yi-1,yi|x)每列中每个元素都加了当前节点的代价, 只不过CRF++是在后面统一加上
}
void Node::calcBeta() { //与上面类似
beta = 0.0;
for (const_Path_iterator it = rpath.begin(); it != rpath.end(); ++it) {
beta = logsumexp(beta,
(*it)->cost +(*it)->rnode->beta,
(it == rpath.begin()));
}
beta += cost; //这里需要注意,在矩阵的推导过程中,没有加当前节点的代价,但是CRF++里面加了, 后续我们会看到有一个减当前节点代价的一段代码
}
// log(exp(x) + exp(y));
// this can be used recursivly
// e.g., log(exp(log(exp(x) + exp(y))) + exp(z)) =
// log(exp (x) + exp(y) + exp(z))
// 这部分取log的操作是为了防止直接取exp溢出,具体的解释以及推导参考 计算指数函数的和的对数
inline double logsumexp(double x, double y, bool flg) {
if (flg) return y; // init mode
const double vmin = std::min(x, y);
const double vmax = std::max(x, y);
if (vmax > vmin + MINUS_LOG_EPSILON) {
return vmax;
} else {
return vmax + std::log(std::exp(vmin - vmax) + 1.0);
}
}
阅读完上述代码会发现,这里的α计算除了没有对最终结果取exp以外,跟上面矩阵推导的α计算是一样的。可以利用矩阵方法和CRF++的算法具体算一下α或β的值,对比一下理解的会更深, 这个过程并不复杂。
概率计算
有了α和β,就可以进行条件概率和期望的计算。一个句子在位置i的label是yi的条件概率,以及在位置i-1与位置i标记为yi-1与yi的概率:
\begin{aligned} P(Y_i= y_i|x) &= \frac{a_i^T(y_i|x) \beta_i(y_i|x)}{Z(x)} \\ P(Y_{i-1} = y_{i-1} ,Y_i= y_i|x) &=\frac{a_{i-1}^T(y_{i-1}|x)M_i(y_{i-1},y_i|x)\beta_i(y_i|x)}{Z(x)} \end{aligned}
第一个式子可以说是节点的概率,第二个式子是节点之间边的概率。有了条件概率,就可以计算特征函数fk 关于条件分布 P(Y|X) 的数学期望是:
\begin{aligned} E_{p(Y|X)}[f_k] &= \sum_yP(y|x)f_k(y,x) \\ &=\sum_{i=1}^{n+1}\sum_{y_{i-1}\ y_i}f_k(y_{i-1},y_i,x,i) \frac{a_{i-1}^TM_i(y_{i-1},y_i|x)\beta_i(y_i|x)}{Z(x)} \end{aligned}
计算特征函数的期望是因为后续计算梯度的时候会用到。这里,如果fk是unigram特征(状态特征),对应的条件概率是节点的概率, 如果是bigram特征(转移特征),条件概率就是边的概率。继续看下CRF++中是如何计算条件概率和特征函数的期望的,代码在gradient函数中:
for (size_t i = ; i < x_.size(); ++i) { //遍历每一个节点的,遍历计算每个节点和每条边上的特征函数,计算每个特征函数的期望
for (size_t j = ; j < ysize_; ++j) {
node_[i][j]->calcExpectation(expected, Z_, ysize_);
}
}
void Node::calcExpectation(double *expected, double Z, size_t size) const { //状态特征的期望
const double c = std::exp(alpha + beta - cost - Z); //这里减去一个多余的cost,剩下的就是上面提到的节点的概率值 P(Yi=yi | x),这里已经取了exp,跟矩阵形式的计算结果一致
for (const int *f = fvector; *f != -; ++f) {
expected[*f + y] += c; //这里会把所有节点的相同状态特征函数对应的节点概率相加,特征函数值*概率再加和便是期望。由于特征函数值为1,所以直接加概率值
}
for (const_Path_iterator it = lpath.begin(); it != lpath.end(); ++it) { //转移特征的期望
(*it)->calcExpectation(expected, Z, size);
}
}
void Path::calcExpectation(double *expected, double Z, size_t size) const {
const double c = std::exp(lnode->alpha + cost + rnode->beta - Z); //这里计算的是上面提到的边的条件概率P(Yi-1=yi-1,Yi=yi|x),这里取了exp,跟矩阵形式的计算结果一致
for (const int *f = fvector; *f != -; ++f) {
expected[*f + lnode->y * size + rnode->y] += c; //这里把所有边上相同的转移特征函数对应的概率相加
}
}
至此,CRF++中前后-后向算法、条件概率计算以及特征函数的期望便介绍完毕,接下来看看如何计算似然函数值和梯度。
计算梯度
条件随机场的训练,我们这里主要看CRF++中应用的LBFGS算法。先做简单的推导, 再结合实际的CRF++源码去理解。条件随机场模型如下:
\begin{aligned} P_w(y|x) = \frac{\exp \left \{ \sum_{k=1}^K w_kf_k(x,y)\right \}}{ \sum_y \left \{ \exp \sum_{i=1}^n w_if_i(x,y)\right \}} \end{aligned}
\begin{aligned} f_k(y,x) = \sum_{i=1}^nf_k(y_{i-1},y_i,x,i), k=1,2,...,K \end{aligned}
训练函数的对数似然如下:
\begin{aligned} L(w) &= \log \prod_{t}P_w(y^t|x^t) \\ &= \sum_{t} \log P_w(y^t|x^t) \\ &= \sum_{t} \left \{ \sum_{k=1}^Kw_kf_k(y^t,x^t)-\log Z_w(x) \right \} \end{aligned}
t代表所有的训练样本, 一般使用m来表示,但是上面已经把m给用了, 为了避免歧义, 我们用t来表示训练样本。我们求似然函数最大值来求解最优参数w,同时也可以对似然函数加负号,通过求解最小值来求最优的w。这里我们与CRF++保持一致,将似然函数取负号,再对wj求导,推导如下:
\begin{aligned} \frac{\partial L(w)}{\partial w_j} &= \sum_{t} \left \{ \frac{\sum_y \left \{ f_i(x^t,y^t)\exp \sum_{i=1}^K w_if_i(x^t,y)\right \}}{Z_w(x)} - f_j(y^t,x^t) \right \} \\ &= \sum_{t} \left \{ \sum_y P(y|x^t)f_j(y, x^t) - f_j(y^t,x^t) \right \} \\ &= \sum_{t} \left \{ E_{P(y|x)}[f_j(y,x)] - f_j(y^t,x^t) \right \} \end{aligned}
对于一个句子来说,特征函数的期望减去特征函数真实值就是我们要计算的梯度,Σt 代表对所有句子求和得到最终的梯度。接下来看下CRF++中是如何实现的,代码还是在gradient函数中:
for (size_t i = ; i < x_.size(); ++i) { //遍历每一个位置(词)
for (const int *f = node_[i][answer_[i]]->fvector; *f != -; ++f) { //answer_[i]代表当前样本的label,遍历每个词当前样本label的特征,进行减1操作,遍历所有节点减1就相当于公式中fj(y,x)
--expected[*f + answer_[i]]; //状态特征函数期望减去真实的状态特征函数值
}
s += node_[i][answer_[i]]->cost; // UNIGRAM cost 节点的损失求和
const std::vector<Path *> &lpath = node_[i][answer_[i]]->lpath;
for (const_Path_iterator it = lpath.begin(); it != lpath.end(); ++it) {//遍历边,对转移特征做类似计算
if ((*it)->lnode->y == answer_[(*it)->lnode->x]) {
for (const int *f = (*it)->fvector; *f != -; ++f) {
--expected[*f +(*it)->lnode->y * ysize_ +(*it)->rnode->y]; //转移特征函数期望减去真实转移特征函数值
}
s += (*it)->cost; // BIGRAM COST 边损失求和
break;
}
}
}
viterbi(); // call for eval() 调用维特比算法做预测,为了计算分类错误的次数,算法详细内容下篇介绍
return Z_ - s ; //返回似然函数值,看L(w)推导的最后一步,大括号内有两项,其中一项是logZw(x),我们知道变量Z_是没有取exp的结果,我们要求这一项需要先对Z_取exp,取exp再取log相当于还是Z_,因此 logZw(x) = Z_
//再看另一项,是对当前样本代价求和,正好这一项是没有取exp的因此该求和项就等于s, 之前说过CRF++是对似然函数取负号,因此返回Z_ - s
至此,一个句子的似然函数值和梯度就计算完成了。公式的Σt 是对所有句子求和,CRF++的求和过程是在run函数调用gradient函数结束后由线程内汇总,然后所有线程结束后再汇总。runCRF函数剩下的代码便是所有线程完成一轮计算后的汇总逻辑,如下:
for (size_t i = ; i < thread_num; ++i) { //汇总每个线程的数据
thread[].obj += thread[i].obj; //似然函数值
thread[].err += thread[i].err;
thread[].zeroone += thread[i].zeroone;
}
for (size_t i = ; i < thread_num; ++i) {
for (size_t k = ; k < feature_index->size(); ++k) {
thread[].expected[k] += thread[i].expected[k]; //梯度值求和
}
}
size_t num_nonzero = ;
if (orthant) { // L1 根据L1或L2正则化,更新似然函数值
for (size_t k = ; k < feature_index->size(); ++k) {
thread[].obj += std::abs(alpha[k] / C);
if (alpha[k] != 0.0) {
++num_nonzero;
}
}
} else { //L2
num_nonzero = feature_index->size();
for (size_t k = ; k < feature_index->size(); ++k) {
thread[].obj += (alpha[k] * alpha[k] /(2.0 * C));
thread[].expected[k] += alpha[k] / C;
}
}
...省略代码
if (lbfgs.optimize(feature_index->size(),
&alpha[],
thread[].obj,
&thread[].expected[], orthant, C) <= ) { //传入似然函数值和梯度等参数,调用LBFGS算法
return false;
}
最终调用LBFGS算法更新w,CRF++中的LBFGS算法最终是调用的Fortran语言编译后的C代码,可读性比较差,本篇文章暂时不深入介绍。至此,一次迭代的计算过程便介绍完毕。
总结
通过这篇文章的介绍,已经了解到了CRF++如何构建无向图、如何计算代价、如何进行前向-后向算法、如何计算特征函数的期望以及如何计算梯度。写这篇文章耗时最长,花了整整一天的时间。力求这篇文章通俗易懂,理论结合实践。希望能够把条件随机场这个比较枯燥的算法诠释好。文中有可能仍然有表达不通顺或者表达不通俗的地方,甚至可能会有表达错误的地方,如果存在上述问题欢迎评论区留言,我将第一时间更新。
条件随机场之CRF++源码详解-训练的更多相关文章
- 条件随机场之CRF++源码详解-预测
这篇文章主要讲解CRF++实现预测的过程,预测的算法以及代码实现相对来说比较简单,所以这篇文章理解起来也会比上一篇条件随机场训练的内容要容易. 预测 上一篇条件随机场训练的源码详解中,有一个地方并没有 ...
- 条件随机场之CRF++源码详解-特征
我在学习条件随机场的时候经常有这样的疑问,crf预测当前节点label如何利用其他节点的信息.crf的训练样本与其他的分类器有什么不同.crf的公式中特征函数是什么以及这些特征函数是如何表示的.在这一 ...
- 条件随机场之CRF++源码详解-开篇
介绍 最近在用条件随机场做切分标注相关的工作,系统学习了下条件随机场模型.能够理解推导过程,但还是比较抽象.因此想研究下模型实现的具体过程,比如:1) 状态特征和转移特征具体是什么以及如何构造 2)前 ...
- Spark Streaming揭秘 Day25 StreamingContext和JobScheduler启动源码详解
Spark Streaming揭秘 Day25 StreamingContext和JobScheduler启动源码详解 今天主要理一下StreamingContext的启动过程,其中最为重要的就是Jo ...
- [转]Linux内核源码详解--iostat
Linux内核源码详解——命令篇之iostat 转自:http://www.cnblogs.com/york-hust/p/4846497.html 本文主要分析了Linux的iostat命令的源码, ...
- saltstack源码详解一
目录 初识源码流程 入口 1.grains.items 2.pillar.items 2/3: 是否可以用python脚本实现 总结pillar源码分析: @(python之路)[saltstack源 ...
- Activiti架构分析及源码详解
目录 Activiti架构分析及源码详解 引言 一.Activiti设计解析-架构&领域模型 1.1 架构 1.2 领域模型 二.Activiti设计解析-PVM执行树 2.1 核心理念 2. ...
- 源码详解系列(六) ------ 全面讲解druid的使用和源码
简介 druid是用于创建和管理连接,利用"池"的方式复用连接减少资源开销,和其他数据源一样,也具有连接数控制.连接可靠性测试.连接泄露控制.缓存语句等功能,另外,druid还扩展 ...
- Mybatis源码详解系列(四)--你不知道的Mybatis用法和细节
简介 这是 Mybatis 系列博客的第四篇,我本来打算详细讲解 mybatis 的配置.映射器.动态 sql 等,但Mybatis官方中文文档对这部分内容的介绍已经足够详细了,有需要的可以直接参考. ...
随机推荐
- strong、weak、copy、assign 在命名属性时候怎么用
一直都在疑惑属性定义中在什么情况下用strong.在什么情况下用weak? 总结大致如下: 1.weak 是用来修饰代理(delegate)和UI控件. 2.strong 是用来修饰除了代理(dele ...
- rsync同步(winxdows到linux/linux到linxu同步)
1.什么是rsync? -rsync是类unix系统下的数据镜像备份工具——remote sync.一款快速增量备份工具 Remote Sync,远程同步 支持本地复制,或者与其他SSH.rsync主 ...
- C++:__stdcall详解
原文地址:http://www.cnblogs.com/songfeixiang/p/3733661.html 对_stdcall 的理解(上)在C语言中,假设我们有这样的一个函数:int funct ...
- win10 安装硕正
提示权限不够,解决方法:根据提示路径手动在路径下建立文件夹
- (并发编程)进程IPC,生产者消费者模型,守护进程补充
一.IPC(进程间通信)机制进程之间通信必须找到一种介质,该介质必须满足1.是所有进程共享的2.必须是内存空间附加:帮我们自动处理好锁的问题 a.from multiprocessing import ...
- Android: SlidingDrawer(滑动式抽屉)
Android控件之SlidingDrawer(滑动式抽屉)详解与实例 一.简介 SlidingDrawer隐藏屏外的内容,并允许用户通过handle以显示隐藏内容.它可以垂直或水平滑动,它有俩个V ...
- Oracle数据库操作基本语法
创建表 SQL>create table classes( classId number(2), cname varchar2(40), birthda ...
- GitHub上README.md的简单介绍
1.编辑README文件 大标题(一级标题):在文本下面加等于号,那么上方的文字就变成了大标题,等于号的个数无限制,但一定要大于0 大标题 ==== 中标题(二级标题):在文本下面加下划线,那么上方的 ...
- 今天刚用asp.net做的导出Eecel
protected void daochu_Click(object sender, EventArgs e) { string hql = "s ...
- Android 颜色透明度换算
每次开发的时候,UI在设计图中标注的颜色都是类似于#FF0000(红色),这倒没什么,但是呢后面却标注了30%的透明度,这下抓狂了,透明度怎么计算?不用着急,不用你算,收藏我这篇文章即可. 颜色简介 ...