Python基础爬虫
搭建环境:
win10,Python3.6,pycharm,未设虚拟环境
之前写的爬虫并没有架构的思想,且不具备面向对象的特征,现在写一个基础爬虫架构,爬取百度百科,首先介绍一下基础爬虫框架的五大模块功能,包括爬虫调度器,URL管理器,HTML下载器,HTML解析器,数据存储器,功能分析如下:
>>爬虫调度器主要负责统筹其他四个模块的协调工作
>>URL管理器负责管理URL链接,维护已经爬取的URL集合和未爬取的URL集合,提供获取新URL链接的接口
>>HTML下载器用于从URL管理器中获取未爬取的URL链接并下载HTML网页
>>HTML解析器用于从HTML下载器中获取已经下载的HTML网页,并从中解析出新的URL链接交给URL管理器,解析出有效数据交给数据存储器
>>数据存储器用于将HTML解析器解析出来的数据通过文件或者数据库的形式存储起来
URL管理器:
URL管理器主要包括两个变量,一个是已爬取的URL集合,另一个是未爬取的URL集合;链接去重很重要,因为爬取链接重复时容易造成死循环,防止链接重复方法主要有三种,一是内存去重,二是关系数据库去重,三是缓存数据库去重;大型成熟的爬虫基本上采用缓存数据库的去重方案,尽可能避免内存大小的限制,又比关系型数据库去重性能高得多(每爬一个链接之前都要在数据库中查询一遍);由于基础爬虫的爬取数量较小,因此我们使用Python中set这个内存去重方式
在pycharm中新建一个python项目,然后新建一个URLManager.py文件,敲入以下代码:
class UrlManager(object):
def __init__(self):
self.new_urls = set()#未爬取URL集合
self.old_urls = set()#已爬取URL集合 def has_new_url(self):
'''
判断是否有未爬取的url
:return
'''
return self.new_url_size()!= 0 def get_new_url(self):
'''
获取一个未爬取的url
:return:
'''
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url def add_new_url(self,url):
'''
将新的url添加到未爬取的URL集合中
:return:
'''
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url) def add_new_urls(self,urls):
'''
将新的URL添加到未爬取的URL集合中
'''
if urls is None or len(urls)==0:
return
for url in urls:
self.add_new_url(url) def new_url_size(self):
'''
获取未爬取URL集合的大小
'''
return len(self.new_urls) def old_url_size(self):
'''
获取已经爬取URL集合的大小
'''
return len(self.old_urls)
HTML下载器
HTML下载器用来下载网页,这时候需要注意网页的编码,以保证下载的网页没有乱码,同样新建一个HtmlDownloader.py
import requests
class HtmlDownloader(object):
def download(self,url):
if url is None:
return None
user_agent = 'Your user_agent'
headers = {'User-Agent': user_agent}
r = requests.get(url,headers=headers)
if r.status_code==200:
r.encoding='utf-8'
return r.text
return None
HTML解析器
在这里HTML解析器使用BeautifulSoup来解析网页源码,其他解析方式还有CSS选择器,xpath,pyquery(大杀器),正则等等,我们需要提取正文标题,摘要以及网页中存在的URL链接,
同样新建一个HtmlParser.py文件
看下网页源码:
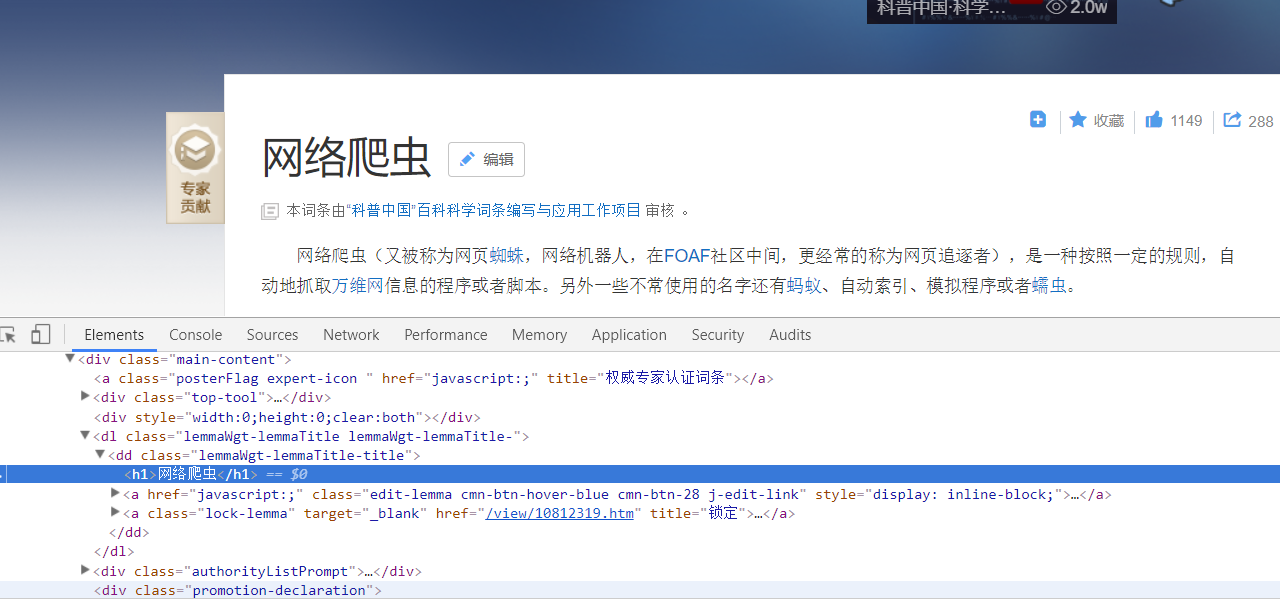
定位到了标题位置,div > h1
所以可以这么写:
title = soup.find('dd',class_='lemmaWgt-lemmaTitle-title').find('h1').get_text()
再看摘要位置:
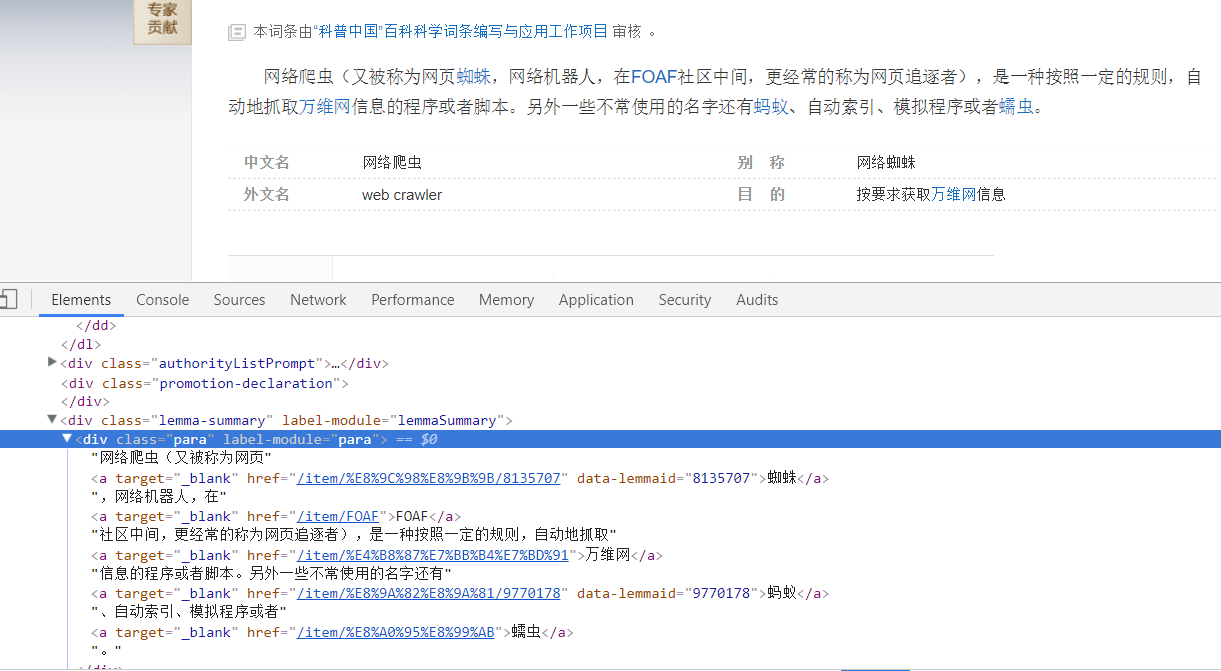
所以可以这么写:
summary = soup.find('div',class_='lemma-summary').get_text().strip()
再看网页中的URL链接:
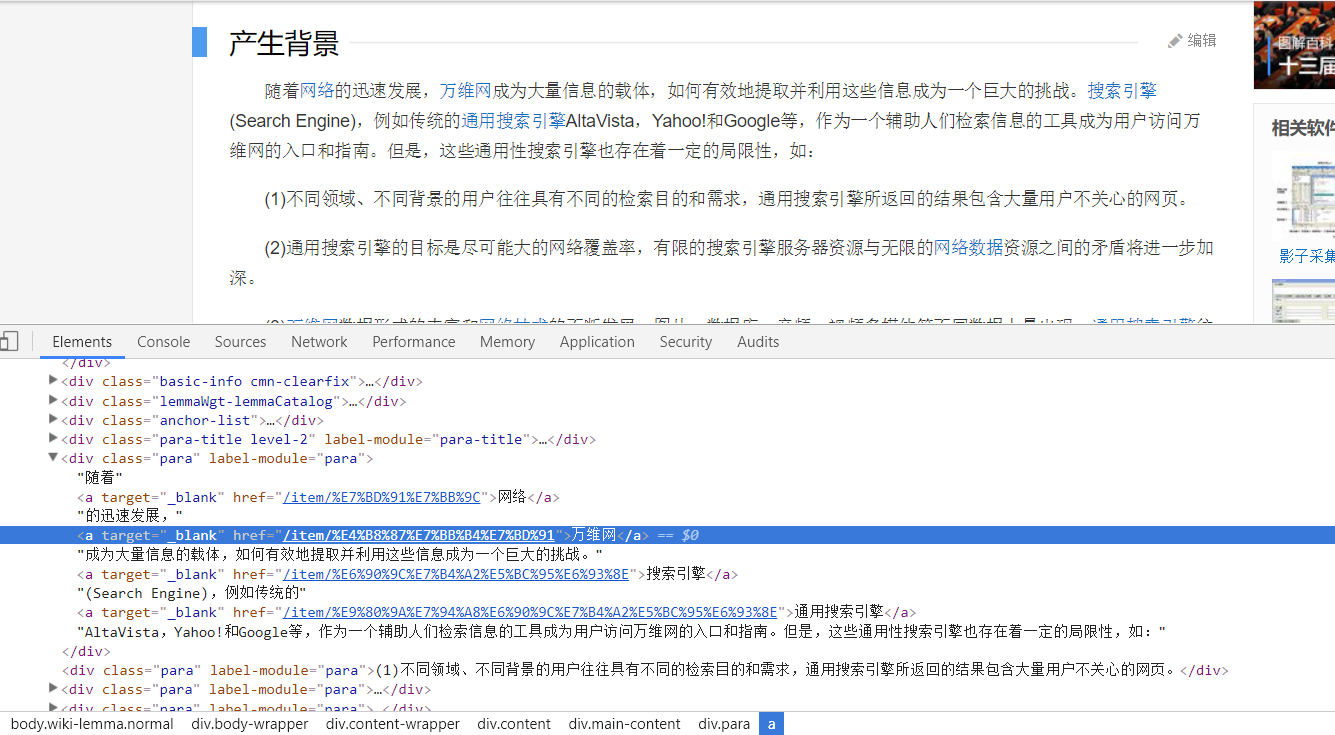
大多数是这种格式:<a target="_blank" href="/item/%E4%B8%87%E7%BB%B4%E7%BD%91">万维网</a>,以及其他格式,因此写一个如下的提取(其实并不能提取以91结尾的URL,正则太久没写忘记了。。):
links = soup.find_all('a',href=re.compile(r'/item/[\w\W]*?91'))
具体代码:
import re
import urllib
from bs4 import BeautifulSoup
import requests class HtmlParser(object): def parser(self,page_url,html_cont):
'''
用于解析网页内容,抽取URL和数据
'''
if page_url is None or html_cont is None:
return
soup = BeautifulSoup(html_cont,'html5lib')
new_urls = self._get_new_urls(page_url,soup)
new_data = self._get_new_data(page_url,soup)
return new_urls,new_data def _get_new_urls(self,page_url,soup):
'''
抽取新的URL集合
'''
new_urls = set()
links = soup.find_all('a',href=re.compile(r'/item/[\w\W]*?91'))
for link in links:
new_url = link['href']
new_full_url= urllib.parse.urljoin(page_url,new_url)
new_urls.add(new_full_url)
return new_urls def _get_new_data(self,page_url,soup):
'''
抽取有效数据
'''
data = {}
data['url'] =page_url
title = soup.find('dd',class_='lemmaWgt-lemmaTitle-title').find('h1')
data['title'] = title.get_text()
summary = soup.find('div',class_='lemma-summary')
data['summary']=summary.get_text().strip() return data
'''
以下代码是我用来单独测试这个模块的
def download(self,page_url):
if page_url is None:
return None
user_agent = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'
headers = {'User-Agent': user_agent}
r = requests.get(page_url,headers=headers)
if r.status_code==200:
r.encoding='utf-8'
return r.text
return None parser = HtmlParser()
page_url = 'https://baike.baidu.com/item/%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB/5162711'
html_cont = parser.download(page_url)
new_urls,new_data = parser.parser(page_url,html_cont)
print(new_urls,new_data)
'''
数据存储器
包括两个方法,store_data用来将HTML解析模块解析出来的数据存储到内存中(list),out_html用来将存储的数据输出为HTML格式(利于展示),同样新建一个DataOutput.py文件
代码如下:
import codecs
class DataOutput(object):
def __init__(self):
self.datas = []
def store_data(self,data):
if data is None:
return
self.datas.append(data)
def output_html(self):
fout = codecs.open('baike.html','w',encoding='utf-8')
fout.write("<html>")
fout.write("<body>")
fout.write("<table>")
for data in self.datas:
fout.write("<tr>")
fout.write("<td>%s</td>"%data['url'])
fout.write("<td>%s</td>"%data['title'])
fout.write("<td>%s</td>"%data['summary'])
fout.write("</tr>")
self.datas.remove(data)
fout.write("</table>")
fout.write("</body>")
fout.write("</html>")
fout.close()
爬虫调度器
爬虫调度器要做的工作就是初始化各个模块,然后通过一个方法传入入口URL,按照流程运行各个模块,同样新建一个SpiderMan.py文件
代码如下:
from DataOutput import DataOutput
from HtmlDownloader import HtmlDownloader
from HtmlParser import HtmlParser
from UrlManager import UrlManager class SpiderMan(object):
def __init__(self):
self.manager = UrlManager()
self.downloader = HtmlDownloader()
self.parser = HtmlParser()
self.output = DataOutput() def crawl(self,root_url):
#添加入口url
self.manager.add_new_url(root_url)
#判断url管理器中是否有新的url,同时判断抓取了多少个url
while(self.manager.has_new_url() and self.manager.old_url_size() < 100):
try:
#从URL管理器获取新的url
new_url = self.manager.get_new_url()
#HTML下载器下载网页
html = self.downloader.download(new_url)
#print(html)
# #HTML解析器抽取网页数据
new_urls,data = self.parser.parser(new_url,html)
#print(new_urls,data)
# #将抽取的url添加到URL管理器中
self.manager.add_new_urls(new_urls)
# #数据存储器存储文件
self.output.store_data(data)
print("已经抓取%s个链接"%self.manager.old_url_size())
except Exception as e:
print("crawl failed")
self.output.output_html() if __name__ == "__main__":
spider_man = SpiderMan()
spider_man.crawl("https://baike.baidu.com/item/%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB/5162711")
最后输出的HTML文件如下:

并不是很利于展示。。。再接再厉
Python基础爬虫的更多相关文章
- Python基础+爬虫基础
Python基础+爬虫基础 一.python的安装: 1.建议安装Anaconda,会自己安装一些Python的类库以及自动的配置环境变量,比较方便. 二.基础介绍 1.什么是命名空间:x=1,1存在 ...
- 零python基础--爬虫实践总结
网络爬虫,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本. 爬虫主要应对的问题:1.http请求 2.解析html源码 3.应对反爬机制. 觉得爬虫挺有意思的,恰好看到知乎有人分享的一个爬虫 ...
- Python 基础爬虫架构
基础爬虫框架主要包括五大模块,分别为爬虫调度器.url管理器.HTML下载器.HTML解析器.数据存储器. 1:爬虫调度器主要负责统筹其他四个模块的协调工作 2: URL管理器负责管理URL连接,维护 ...
- Python基础——爬虫以及简单的数据分析
目标:使用Python编写爬虫,获取链家青岛站的房产信息,然后对爬取的房产信息进行分析. 环境:win10+python3.8+pycharm Python库: import requests imp ...
- python基础爬虫,翻译爬虫,小说爬虫
基础爬虫: # -*- coding: utf-8 -*- import requests url = 'https://www.baidu.com' # 注释1 headers = { # 注释2 ...
- python 基础-爬虫-数据处理,全部方法
生成时间戳 1. time.time() 输出 1515137389.69163 ===================== 生成格式化的时间字符串 1. time.ctime() 输出 Fri Ja ...
- python基础-爬虫
爬虫引入 爬虫: 1 百度:搜索引擎 爬虫:spider 种子网站开始爬,下载网页,分析链接,作为待抓取的网页 分词 index:词--->某个结果 Page rank(1 网站很大(互链) ...
- python爬虫主要就是五个模块:爬虫启动入口模块,URL管理器存放已经爬虫的URL和待爬虫URL列表,html下载器,html解析器,html输出器 同时可以掌握到urllib2的使用、bs4(BeautifulSoup)页面解析器、re正则表达式、urlparse、python基础知识回顾(set集合操作)等相关内容。
本次python爬虫百步百科,里面详细分析了爬虫的步骤,对每一步代码都有详细的注释说明,可通过本案例掌握python爬虫的特点: 1.爬虫调度入口(crawler_main.py) # coding: ...
- python 爬虫与数据可视化--python基础知识
摘要:偶然机会接触到python语音,感觉语法简单.功能强大,刚好朋友分享了一个网课<python 爬虫与数据可视化>,于是在工作与闲暇时间学习起来,并做如下课程笔记整理,整体大概分为4个 ...
随机推荐
- [Canvas]Bombman v1.04
Bombman是我仿造红白机上经典游戏爆破小人,用Canvas制作的一款网页版单机游戏, 自我感觉还是有一定的可玩性. 本游戏的胜利条件是用雷消灭所有怪物,但被怪物即使是擦边碰到或是炸弹火焰炸到就算失 ...
- How to make an IntelliJ IDEA plugin in less than 30 minutes
Sometimes it is a nice thing to extend an editor to have it do some new stuff, like being able to re ...
- Java字节码 小结
Reference javap 基本使用方法 深入理解java字节码 从Java代码到字节码 Java字节码.class文件案例分析 字节码 核心概念 Class文件是8位字节流,按字节对齐.之所以称 ...
- Certificate Formats | Converting Certificates between different Formats
Different Platforms & Devices requires SSL certificates in different formatseg:- A Windows Serve ...
- 深入理解JS执行细节(写的很精辟)
来源于:http://www.cnblogs.com/onepixel/p/5090799.html javascript从定义到执行,JS引擎在实现层做了很多初始化工作,因此在学习JS引擎工作机制之 ...
- Socket网络编程--网络爬虫(3)
上一小节我们实现了从博客园的首页获取一些用户的用户名,并保存起来.接下来的这一小节我将对每个用户名构建一个用户的博客主页,然后从这个主页获取所有能获取到的网页,网页的格式现在是http://www.c ...
- 【转】Django中使用POST方法获取POST数据
1.获取POST中表单键值数据 如果要在django的POST方法中获取表单数据,则在客户端使用JavaScript发送POST数据前,定义post请求头中的请求数据类型: xmlhttp.setRe ...
- IBM CE 错误集之(FNRCS0005E)
// 通过ObjectStore获取所有的StorageArea对象,CEUtil是我封装的一个获取ObjectStore 的工具类 ObjectStore os = CEUtil.getStore( ...
- 【GMT43智能液晶模块】例程三:CAN通信实验
实验原理: STM32F429自带有CAN通信接口,本例程通过CAN1与芯片SN65HVD230相连 实现CAN通信,通过回环测试以验证CAN通信功能. 实验现象: 源代码下载链接: 链接:http: ...
- Mysql系列二:Mysql 开发标准规范
原文链接:http://www.cnblogs.com/liulei-LL/p/7729983.html 一.表设计 1. 库名.表名.字段名使用小写字母,“_”分割. 2. 库名.表名.字段名不超过 ...