python --- 字符编码学习小结
上半年的KPI,是用python做一个测试桩系统,现在系统框架基本也差不多定下来了。里面有用到新学的工厂设计模式以及以及常用的大牛写框架的业务逻辑和python小技巧。发现之前自己写的代码还是面向过程思想的多,基本没有面向对象的思想,近半年看的代码给了很大的触动,我需要升级我的技能了,于是也花了挺多时间在这个KPI学习上,现在先总结下在做这个系统时我所面临到的python的字符编码问题。
字符编码问题,如果处理有问题,可能直接就报错了;如果处理不得当,中文就会显示乱码。这是最初接触字符编码遇到问题最简洁的表达。一般都会遇到以下几个问题(逐渐升级的头疼问题):
1. 使用编辑器或者Python IDE直接打印中文,报错或者乱码;
2. 前台传输过来包含中文的字符串在后台打印,报错或者乱码;
3. DB交互,从DB查询或者insert的中文,操作时报错或者乱码;
4. 文件操作,从文件中读取或者写文件时,报错或者乱码;
除了第四个问题,暂时我没遇到过,前面3个问题,我遇到好几次了;遇到字符编码问题,如果想着就解决当前的问题,随便在百度上,狂搜各种方法乱试,可能还真能解决这个问题,但是耗时太长了,下次再遇到一样会头炸开,我觉得学习解决这个问题需要经过以下几个过程:
1. 简单的了解计算机字符编码的发展史,ASCII编码是啥? EASCII是啥?GBK是啥?unicode是啥?UTF-8是啥?UTF-16是啥?如果这些最初级的基本概念不了解,后面学习会很困难。
2. 理解python的字符串的数据类型,str和unicode,两者之间是如何转换的?
3. mysql支持哪些字符?mysql的环境变量跟字符集相关的有七,八个,都是神马意思?最简单的要怎么使用?
第一:字符编码的前世今生
1989年,荷兰人Guido van Rossum发明python语言,第一个公开发行版发行于1991年,当时在那个时代,是不关心编码问题的而且英文字符个数本身也是有限的,26个字母,10个数字,标点符号,键盘上加起来能输入的字符就一百多个,用一个字节来存储已经够了,8个比特位能存256个字符。于是美国人制定了一套字符编码标准ASCII。最开始的ASCII只定义了128个字符,包括96个字符和32个控制符,因此 ASCII 只使用了一个字节的后7位,最高位都为0。
随着时代的进步,计算机开始普及到千家万户,计算机进入中国面临的一个问题就是字符编码,中国的汉字是人类使用频率最多的文字,常见的汉字就有成千上万,大大超出了 ASCII 编码所能表示的字符范围了,于是中国人自己弄了一套编码叫 GB2312,GB2312 编码共收录了6763个汉字,同时他还兼容 ASCII,GB 2312的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率,不过 GB2312 还是不能100%满足中国汉字的需求,对一些罕见的字和繁体字 GB2312 没法处理,后来就在GB2312的基础上创建了一种叫 GBK 的编码,GBK 不仅收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。同样 GBK 也是兼容 ASCII 编码的,对于英文字符用1个字节来表示,汉字用两个字节来标识。
世界语言种类有多少,计算机的字符编码相应就会增加多少。于是统一联盟国际组织提出了Unicode编码,Unicode的学名是”Universal Multiple-Octet Coded Character Set”,简称为UCS。Unicode有两种格式:UCS-2和UCS-4。UCS-2就是用两个字节编码,一共16个比特位,这样理论上最多可以表示65536个字符,不过要表示全世界所有的字符显示65536个数字还远远不过,因为光汉字就有近10万个,因此Unicode4.0规范定义了一组附加的字符编码,UCS-4就是用4个字节(实际上只用了31位,最高位必须为0)。世界上任何一个字符都可以用一个Unicode编码来表示,一旦字符的Unicode编码确定下来后,就不会再改变了。但是Unicode有一定的局限性,一个Unicode字符在网络上传输或者最终存储起来的时候,并不见得每个字符都需要两个字节,比如一字符“A“,用一个字节就可以表示的字符,却使用两个字节,太浪费空间了。UTF-8(8-bit Unicode Transformation Format)就出现了,UTF-8是一种针对Unicode的可变长度字符编码,又称万国码。UTF-8用1到6个字节编码Unicode字符。
第二:python 字符串类型
python2.X 系统的默认编码是ASCII,3.X系统就是unicode,所以在2.X系列遇到的编码问题会更多。
|
1
2
3
4
5
|
>>> import sys
>>> sys.getdefaultencoding()
'ascii'
|
现在会遇到第一类问题,在python源代码文件中如果不显示地指定编码的话,将出现语法错误:

这个提示很明显,非ASCII码在源代码中出现了。单纯的出现这类问题,可以采用以下方法解决:
方法一:在 文件前指定编码格式:
#!/usr/bin/env python
#coding:UTF-8
方法二:设置整个系统的字符编码才能解决问题:(结合方法一一起使用)
default_encoding = 'utf-8'
if sys.getdefaultencoding() != default_encoding:
reload(sys)
sys.setdefaultencoding(default_encoding)
方法一和方法二都尝试了还有问题,可能就是你的编辑器的显示问题了,我使用的是pycharm,在file-setting里可以这样的设置:
调试IDE编码和project编码后,终于能打印中文了:
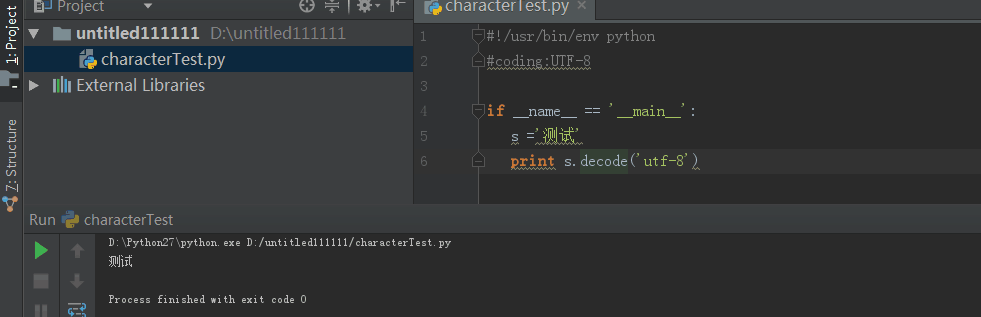
之前,刚学习python的时候,总结的一段:
1. 不设置源文件编码格式,输入中文,后直接打印,会提示存在‘non-ascii’,编译不通过
2. 设置源文件编码格式为gbk,输入中文后,打印乱码
3. 设置源文件编码格式为gbk,输入中文s1 = u'测试'后,打印正常
4. 设置源文件编码格式为gbk,输入中文后,先将字符串解码decode或者unicode方法,后打印正常
5. 设置源文件编码格式为utf-8,输入中文后直接输出正常
6. 设置工具和工程的默认编码为gbk,输入中文后,打印正常。
从python2.0开始,就有一种新的数据类型 Unicode Strings,但是在python3的到来,这个概念已经被弱化了。python2.*的默认编码格式是ASCII码,而python3.*的默认编码格式已经换成了Unicode。在python2中和字符串相关的数据类型,分别是str、unicode两种,他们都是basestring的子类,可见str与unicode是两种不同类型的字符串对象。区分一个
变量是字符还是unicode,可以使用type方法:
>>> a='好'
>>> type(a)
<type 'str'>
>>> a
'\xe5\xa5\xbd' >>> b=u'好'
>>> type(b)
<type 'unicode'>
>>> b
u'\u597d'
Python中str和unicode之间是如何转换的呢?这两种类型的字符串类型之间的转换就是靠这两个方法decode和encode。

这2个函数的具体使用,就不举例了。网上这类文章挺多的。这时就有可能遇到第二个问题,前台传入的中文在后台乱码,无法处理。一般出现这类问题,都是前后台编码格式不一致导致的;
方法一:统一前后台编码格式;
方法二:如果无法统一,那取数据的时候就需要进行转码处理,之前我遇到一个问题,前台传入的是GBK格式的中文,我是做后台处理的,后台全系统都是用utf8编码的,接收到GBK的http请求后,显示的中文是乱码的,导致解析那段GBK的xml都报异常。后面做了调整,再接收到前台的GBK字符串后,首先decode(gbk)再encode(utf8)就成功了。
第三:操作DB,需要了解的mysql字符集。
使用python对DB的操作,随时都有可能出现乱码。网上搜以下2个方法偶尔也能解决问题:
方法一:conn = MySQLdb.connect(self.host,self.username,self.password,self.database,charset='gbk')
方法二:
dāng当 tā它 lí离 kāi开 kè客 hù户 duān端 shí时 de的 yǔ语 jù句 shì是 shén什 me么 zì字 fú符 jí集 ?
The server takes the character_set_client system variable to be the character set in which statements are sent by the client.
1、 客户端和服务器建立连接后,客户端以什么字符编码发送数据?
答:服务器以character_set_client系统变量被设置, conn = MySQLdb.connect(self.host,self.username,self.password,self.database,charset='gbk') 只是设置了客户端发生数据的字符编码格式
fú服 wù务 qì器 yǐ以 c h a r a c t e r _ s e t _ c l i e n t xì系 tǒng统 biàn变 liàng量 bèi被 shè设 zhì置 , bào报 biǎo表 shì是 yóu由 kè客 hù户 duān端 fā发 sòng送 de的 zì字 fú符 。
•
•
What character set should the server translate a statement to after receiving it?
2、服务器在收到语句后将其翻译成什么字符集?
fú服 wù务 qì器 zài在 shōu收 dào到 yǔ语 jù句 hòu后 jiāng将 qí其 fān翻 yì译 chéng成 shén什 me么 zì字 fú符 jí集 ?
For this, the server uses the character_set_connection and collation_connection system variables. It converts statements sent by the client from character_set_client to character_set_connection, xexcept for string literals that have an introducer (for example, _utf8mb4 or _latin2). collation_connection is important for comparisons of literal strings. For comparisons of strings with column values, collation_connection does not matter because columns have their own collation, which has a higher collation precedence.
答:服务器使用character_set_connection和collation_connection系统变量。它将收到的字符集从character_set_client转到character_set_connection,然后再进行处理。
wèi为 cǐ此 , fú服 wù务 qì器 shǐ使 yòng用 c h a r a c t e r _ s e t _ c o n n e c t i o n hé和 c o l l a t i o n _ c o n n e c t i o n xì系 tǒng统 biàn变 liàng量 。 tā它 jiāng将 cóng从 c h a r a c t e r _ s e t _ c l i e n t dào到 c h a r a c t e r _ s e t _ c o n n e c t i o n kè客 hù户 duān端 fā发 sòng送 bào报 biǎo表 , zì字 fú符 chuàn串 zhōng中 yǒu有 jiè介 shào绍 rén人 x e x c e p t ( lì例 rú如 , _ u t f 8 m b 4 huò或 _ l a t i n 2 ) 。 c o l l a t i o n _ c o n n e c t i o n wèi为 zì字 fú符 chuàn串 bǐ比 jiào较 shì是 hěn很 zhòng重 yào要 de的 。 duì对 yú于 bǐ比 jiào较 liè列 zhōng中 zì字 fú符 chuàn串 de的 zhí值 , c o l l a t i o n _ c o n n e c t i o n bìng并 bù不 zhòng重 yào要 , yīn因 wèi为 zhù柱 yǒu有 zì自 jǐ己 de的 zhěng整 lǐ理 , jù具 yǒu有 gèng更 gāo高 de的 yōu优 xiān先 pái排 xù序 。
•
•
What character set should the server translate to before shipping result sets or error messages back to the client?
3、服务器处理完后,将结果集或错误消息返回给客户端之前,服务器应该翻译什么字符集?
zài在 jiāng将 jié结 guǒ果 jí集 huò或 cuò错 wù误 xiāo消 xi息 fǎn返 huí回 gěi给 kè客 hù户 duān端 zhī之 qián前 , fú服 wù务 qì器 yīng应 gāi该 fān翻 yì译 shén什 me么 zì字 fú符 jí集 ?
The character_set_results system variable indicates the character set in which the server returns query results to the client. This includes result data such as column values, and result metadata such as column names and error messages.
答:character_set_results系统变量指定的服务器返回查询结果给客户端的字符。这包括结果数据,如列值,以及结果元数据,如列名和错误消息。
character_set_client系统变量的详细介绍:
SET NAMES 'charset_name' [COLLATE 'collation_name']A
SET NAMES 'statement is equivalent to these three statements:charset_name'Press CTRL+C to copySET character_set_client = charset_name;
SET character_set_results = charset_name;
SET character_set_connection = charset_name;SET CHARACTER SET ''charset_nameA
SET CHARACTER SETstatement is equivalent to these three statements:charset_namePress CTRL+C to copySET character_set_client = charset_name;
SET character_set_results = charset_name;
SET collation_connection = @@collation_database;
jǐ几 gè个 zì字 fú符 jí集 hé和 pái排 xù序 xì系 tǒng统 biàn变 liàng量 shè涉 jí及 dào到 kè客 hù户 duān端 yǔ与 fú服 wù务 qì器 de的 jiāo交 hù互 。 qí其 zhōng中 yī一 xiē些 yǐ已 jīng经 zài在 qián前 miàn面 dī的 zhāng章 jié节 zhōng中 tí提 dào到 guò过 :
•
这时看看百度经常给的解决方法2,嘿嘿,后面2个操作多余了吧。
在实际操作的过程中,遇到过乱码的问题,了解原理后,明白是因为客户端在发送数据给DB时,SET character_set_connection=gbk;实际上我的DB的编码格式是Latin1的;在连接的时候,修改charset='latin1',就可以了。
还有遇到DB返回SQL Error: 1366: Incorrect string value: "\xE8\xAF\xA6\xE7\xBB\x86…" for column "address" at row 1 问题
这时,需要确定数据的字符集,表的字符集,列的字符集;如果列的字符集是指定的,就会直接使用列的字符集,这个优先级最高。后面我修改了列的字符集成utf8,就解决了。
以上提到的这些问题,其实在mysql的官网这些原理都有详细的说明。这块我就没仔细看了;后面还真可以好好自学下,部分有些问题遇到后,没来得及截图,导致现在写总结没啥实例,之后会注意下这个问题。学习真的不是一蹴而就的事情,是一件需要持续不停的事情,鹅厂呆了半年,终于差不多可以把气喘匀了,又可以继续我的学习之路了。
python --- 字符编码学习小结的更多相关文章
- python --- 字符编码学习小结(二)
距离上一篇的python --- 字符编码学习小结(一)已经过去2年了,2年的时间里,确实也遇到了各种各样的字符编码问题,也能解决,但是每次都是把所有的方法都试一遍,然后终于正常.这种方法显然是不科学 ...
- 【Todo】Python字符编码学习
Python中经常出现字符编码问题,在这里统一整理吧. 参考这篇文章:http://www.cnblogs.com/huxi/archive/2010/12/05/1897271.html 另外这个人 ...
- Python字符编码补充
字符编码: Python字符编码贯穿Python学习的始终,现在应用的是Python2中字符编码的问题是很多的. 这次是要彻底解决Python字符编码的问题!!! 1 字符编码的发展过程: 1 .AS ...
- python 字符编码练习
通过下面的练习,加深对python字符编码的认识 # \x00 - \xff 256个字符 >>> a = range(256)>>> b = bytes(a) # ...
- Python字符编码讲解
声明:本文参考 Python字符编码详解 在计算机中我们不管用什么语言和程序,最终数据在计算机中的都是字节码(也就是01形式)的形式存在的,如果 计算机直接把字节码显示在屏幕上,很明显一般人看不懂字节 ...
- 深入理解Python字符编码--转
http://blog.51cto.com/9478652/2057896 不论你是有着多年经验的 Python 老司机还是刚入门 Python 不久,你一定遇到过UnicodeEncodeError ...
- 深入理解Python字符编码
不论你是有着多年经验的 Python 老司机还是刚入门 Python 不久,你一定遇到过UnicodeEncodeError.UnicodeDecodeError 错误,每当遇到错误我们就拿着 enc ...
- Python字符编码详解,str,bytes
什么是明文 “明文”是可以是文本,音乐,可以编码成mp3文件.明文可以是图像的,可以编码为gif.png或jpg文件.明文是电影的,可以编码成wmv文件.不一而足. 什么是编码?把明文变成计算机语言 ...
- 转1:Python字符编码详解
Python27字符编码详解 声明 一 字符编码基础 1 抽象字符清单ACR 2 已编码字符集CCS 3 字符编码格式CEF 31 ASCII初创 311 ASCII 312 EASCII 32 MB ...
随机推荐
- Mysql 性能优化教程
Mysql 性能优化教程 目录 目录 1 背景及目标 2 Mysql 执行优化 2 认识数据索引 2 为什么使用数据索引能提高效率 2 如何理解数据索引的结构 2 优化实战范例 3 认识影响结果集 4 ...
- [daily][archlinux][pacman] 删除所有孤立包(orphan)
[:] <tong> sudo pacman -Rsun `pacman -Qdt |cut -d` [:] <tong> 我每次都这么删, 有没有高级点的 ...
- [skill][debug][gdb] 使用core dump 进行GDB
core dump 扫盲:https://wiki.archlinux.org/index.php/Core_dump 1. 人为制作 core dump 1.1 实时在线生成core dump. ...
- Js_protoType_原型
1.什么是原型? 之前在网上看了好多,各种说法的都有,说的很晦涩,很难理解,我觉得用的多了就会慢慢理解它的意思,总之来说,每个对象都有一个指向它原型,也就是每个对象都有原型. 2.原型有什么用? 原型 ...
- 洛谷P3224 永无乡 [HNOI2012] 线段树/splay/treap
正解:线段树合并 解题报告: 传送门! 这题也是有很多解法,eg:splay,treap,... 然而我都不会我会学的QAQ! 反正今天就只讲下线段树合并怎么做QAQ 首先看到这样子的说第k重要的是什 ...
- kali蓝牙连接
http://blog.csdn.net/hailangnet/article/details/47723181 http://www.aiuxian.com/article/p-3012084.ht ...
- 接口测试工具-Jmeter使用笔记(五:正则表达式提取器)
(正则表达式提取器是Jmeter关联中的一种)使用场景: 有两个HTTP请求,请求A的返回数据中有一个字段“ABCD”,该字段要作为请求B的入参. 1.添加方式 请求A上右键-->后置处理器-& ...
- CentOS安装Yarn只需两步就搞定
Yarn 是一个依赖管理工具.它能够管理你的代码,并与全世界的开发者分享代码.Yarn 是高效.安全和可靠的,你完全可以安心使用.代码是通过包(有时也被称为组件). 在每一个包中会定义一个 packa ...
- kafka6 编写使用自定义分区的生产者
一 客户端 在上一篇博客创建的简单生产者的基础上,进行两个修改操作: 1.新建SimplePartitioner.java,修改返回分区为1. SimplePartitioner.java代码如下 p ...
- padStart()方法,padEnd()方法
https://blog.csdn.net/ixygj197875/article/details/79090578