LDA学习小记
看到一段对主题模型的总结,感觉很精辟:
如何找到文本隐含的主题呢?常用的方法一般都是基于统计学的生成方法。即假设以一定的概率选择了一个主题,然后以一定的概率选择当前主题的词。最后这些词组成了我们当前的文本。所有词的统计概率分布可以从语料库获得,具体如何以“一定的概率选择”,这就是各种具体的主题模型算法的任务了。lda也是采取的这种思想。
大部分对LDA的解释都是通过LDA生成文档的思路,而我们一般是给定文档,利用LDA推测该文档的话题分布。我在这里先讲一下生成文档的过程,再讲我们普遍用到的代码中推测话题的过程:
1.文档生成
我比较关注实用性,又不是很喜欢那么多的数学公式,所以主要先把个人感觉最方便理解的解释分享给大家看看~反正我看了下边的解释脑子里可以有LDA原理的整个思路。
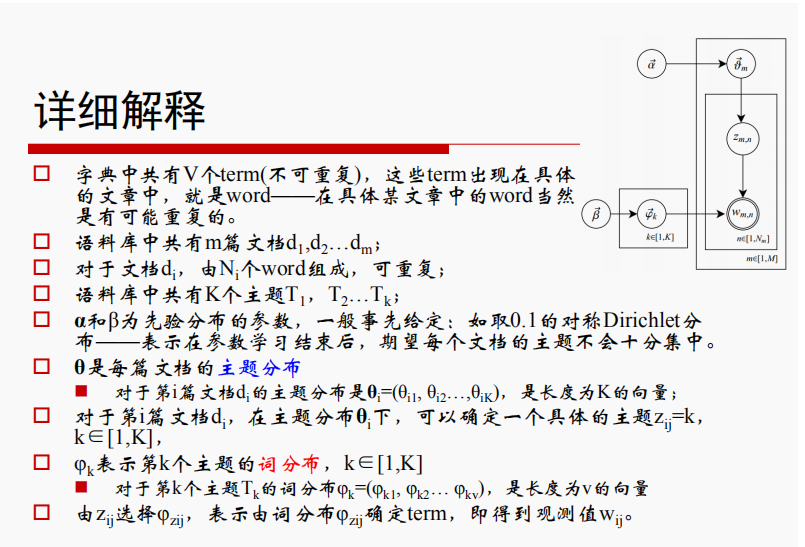
联系右上角给出的图,步骤为从上到下、从左到右,先得到一个主题Zij=k,再得到第k个主题的词分布φk,继而生成文档的词汇w,循环该图流程,生成整篇文档。
过程中涉及到多种分布;
共轭分布:在贝叶斯的理论体系中,如果先验概率分布和后验概率分布满足同样的分布律的话,就说先验分布和后验分布是共轭分布,同时,先验分布又叫做似然函数的共轭先验分布。大白话来说就是:如果一个概率分布Z乘以一个分布Y之后的分布仍然是Z,那么就是共轭分布。二项分布的共轭先验分布是Beta分布,多项分布的共轭先验分布是Dirichlet分布。
LDA中涉及的 多项分布和Dirichlet分布,LDA中词和主题服从多项式分布,两者的参数服从Dirichlet分布。我认为引入共轭分布主要是为了方便计算整个过程中的参数。
2.通过已知文档推测所含话题分布
通过LDA推测话题分布时,
1)初始先随机给文本中的每个词(喂进去的词需要经过分词、通过dictionary每个词对应一个id,再将id与该词对应的tf-idf值或词频关联存储为一个矩阵)分配主题z0(初始设置了要得到的话题个数k,为每个词分配话题id),也给定了α和β,控制了主题分布和词分布;
2)然后统计词t属于主题z的数量以及每个文档m下出现的主题z的数量;通过除了当前词w以外其他所有词所属的主题分布估计当前词分配各个主题的概率,即计算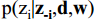 得到词w对应各主题的概率p(1,2,....k)=(p1,p2,.....pk)
得到词w对应各主题的概率p(1,2,....k)=(p1,p2,.....pk)
3)当得到当前词属于所有主题z的概率分布后,根据这个概率分布为该词采样(不是取最大值)一个新的主题。
4)用同样方法更新下一个词的主题,直到发现每个文档的主题分布和每个主题的词分布收敛(应该是文档中出现的所有同一个词计算得到的所属主题分布都一致),算法终止,输出待估计的参数θ和φ,同时每个单词的主题Zmn也可以得到。
实际中应用会设置最大迭代次数,每一次计算 的公式称为Gibbs updating rule
的公式称为Gibbs updating rule
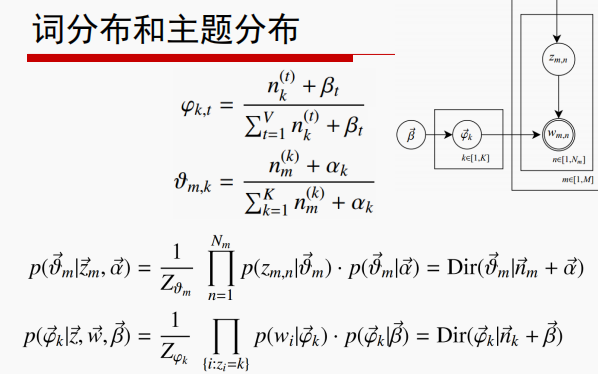
这样就解释了内部推测话题的过程。其中涉及的数学计算过程如下(我比较懒,直接贴了邹博视频的式子啦,如果对大家有用希望能点个赞之类的啦~~~~~~~~~):



另外,想起来在用LDA做实验的过程中还找到了百度开源的一个项目。关于主题模型的项目。文档主题推断工具、语义匹配计算工具以及基于工业级语料训练的三种主题模型:Latent Dirichlet Allocation(LDA)、SentenceLDA 和Topical Word Embedding(TWE) github链接:https://github.com/baidu/Familia
3.通过gensim中LDA可以实现的功能
1)得到该文档的话题分布及相应概率
2)计算各文档相似度
dictionary = corpora.Dictionary.load('dictionary.dict')
corpus = corpora.MmCorpus("corpus.mm")
lda = models.LdaModel.load("model.lda")
index = similarities.MatrixSimilarity(lda[corpus])
index.save("simIndex.index")
docname = "docs/the_doc.txt" doc = open(docname, 'r').read()
vec_bow = dictionary.doc2bow(doc.lower().split())
vec_lda = lda[vec_bow] sims = index[vec_lda]
sims = sorted(enumerate(sims), key=lambda item: -item[1])
参考链接:https://blog.csdn.net/qq_25073545/article/details/79782066
3)通过PYLDAVIS模块将主题可视化
试了一下该项目是可以直接用的,只不过只能在LINUX下使用,可以直接按github上给出的步骤应用,效果还不错~~~
LDA学习小记的更多相关文章
- mongodb入门学习小记
Mongodb 简单入门(个人学习小记) 1.安装并注册成服务:(示例) E:\DevTools\mongodb3.2.6\bin>mongod.exe --bind_ip 127.0.0.1 ...
- javascript学习小记(一)
大四了,课少了许多,突然之间就不知道学什么啦.整天在宿舍混着日子,很想学习就是感觉没有一点头绪,昨天看了电影激战.这种纠结的情绪让我都有点喘不上气啦!一点要找点事情干了,所以决定找个东西开始学习.那就 ...
- js 正则学习小记之匹配字符串
原文:js 正则学习小记之匹配字符串 今天看了第5章几个例子,有点收获,记录下来当作回顾也当作分享. 关于匹配字符串问题,有很多种类型,今天讨论 js 代码里的字符串匹配.(因为我想学完之后写个语法高 ...
- js 正则学习小记之左最长规则
原文:js 正则学习小记之左最长规则 昨天我在判断正则引擎用到的方法是用 /nfa|nfa not/ 去匹配 "nfa not",得到的结果是 'nfa'.其实我们的本意是想得到整 ...
- js 正则学习小记之NFA引擎
原文:js 正则学习小记之NFA引擎 之前一直认为自己正则还不错,在看 次碳酸钴,Barret Lee 等大神都把正则玩的出神入化后发现我只是个战五渣. 求抱大腿,求大神调教. 之前大致有个印象,正 ...
- js 正则学习小记之匹配字符串优化篇
原文:js 正则学习小记之匹配字符串优化篇 昨天在<js 正则学习小记之匹配字符串>谈到 个字符,除了第一个 个,只有 个转义( 个字符),所以 次,只有 次成功.这 次匹配失败,需要回溯 ...
- CSS学习小记
搜狗主页页面CSS学习小记 1.边框的处理 要形成上图所示的布局效果,即,点选后,导航下面的边框不显示而其他的边框形成平滑的形状.相对于把导航的下面边框取消然后用空白覆盖掉下面搜索栏的边框比较而言 ...
- Gcd&Exgcd算法学习小记
Preface 对于许多数论问题,都需要涉及到Gcd,求解Gcd,常常使用欧几里得算法,以前也只是背下来,没有真正了解并证明过. 对于许多求解问题,可以列出贝祖方程:ax+by=Gcd(a,b),用E ...
- logstash 学习小记
logstash 学习小记 标签(空格分隔): 日志收集 Introduce Logstash is a tool for managing events and logs. You can use ...
随机推荐
- Git 推送操作
Jerry 修改了他的最后一次提交的修改操作,他已经准备好将更改.推操作的数据永久存储的 Git 仓库.推操作成功后,其他开发人员可以看到Jerry 的变化. 他执行的git日志命令来查看提交的细节. ...
- Intelij U
1.https://link.jianshu.com/?t=http://idea.lanyus.com/,下载JetbrainsCrack-2.6.2.jar,放到bin目录 2.编辑bin目录下面 ...
- Cisco VLAN ACL配置
什么是ACL? ACL全称访问控制列表(Access Control List),主要通过配置一组规则进行过滤路由器或交换机接口进出的数据包, 是控制访问的一种网络技术手段, ACL适用于所有的被路由 ...
- Java SpringBoot中使用sqljdbc4注意事项 java.lang.ClassNotFoundException: com.microsoft.sqlserver.jdbc.SQLServerDriver
因项目需要,需要在Java项目中访问 MSSQLServer 数据库,本地开发的时候,没有问题,可以正常链接数据库,通过Jenkins部署到服务器上时候,报数据库驱动未找到. java.lang.Cl ...
- cookie是如何保存到客户端,又是如何发送到服务端
Cookie相关的Http头 有 两个Http头部和Cookie有关:Set-Cookie和Cookie. Set-Cookie由服务器发送,它包含在响应请求的头部中.它用于在客户端创 ...
- 【algorithm】 二分查找算法
二分查找算法:<维基百科> 在计算机科学中,二分搜索(英语:binary search),也称折半搜索(英语:half-interval search)[1].对数搜索(英语:logari ...
- [UFLDL] Linear Regression & Classification
博客内容取材于:http://www.cnblogs.com/tornadomeet/archive/2012/06/24/2560261.html Deep learning:六(regulariz ...
- CentOS使用virt-what知道虚拟机的虚拟化技术
通常拿到一台vps,提供商可能不会告诉我们具体的虚拟化技术,对于CentOS的系统的vm,可以使用virt-what来知道. 如果提示virt-what命令找不到,则需要安装一下 yum instal ...
- WPF之Menu绑定XML
一.XML文件 <?xml version="1.0" encoding="utf-8" ?> <MenuData xmlns="& ...
- c __cplusplus详解
Code:#ifdef __cplusplusextern "C" { #endif ... #ifdef __cplusplus} #endif 解释:1.c++中定义了__cp ...