浅谈分词算法(5)基于字的分词方法(bi-LSTM)
前言
很早便规划的浅谈分词算法,总共分为了五个部分,想聊聊自己在各种场景中使用到的分词方法做个总结,种种事情一直拖到现在,今天抽空赶紧将最后一篇补上。前面几篇博文中我们已经阐述了不论分词、词性标注亦或NER,都可以抽象成一种序列标注模型,seq2seq,就是将一个序列映射到另一个序列,这在NLP领域是非常常见的,因为NLP中语序、上下文是非常重要的,那么判断当前字或词是什么,我们必须回头看看之前说了什么,甚至之后说了什么,这也符合人类在阅读理解时的习惯。由于抽象成了Seq2Seq的模型,那么我们便可以套用相关模型来求解,比如HMM、CRF以及深度中的RNN,本文我们就来聊聊LSTM在分词中的应用,以及使用中的一些trick,比如如何添加字典等。
目录
浅谈分词算法(1)分词中的基本问题
浅谈分词算法(2)基于词典的分词方法
浅谈分词算法(3)基于字的分词方法(HMM)
浅谈分词算法(4)基于字的分词方法(CRF)
浅谈分词算法(5)基于字的分词方法(LSTM)
循环神经网络
在之前的博文马里奥AI实现方式探索 ——神经网络+增强学习,我阐述了关于神经网络的历程,以及最近这波人工智能浪潮的起始CNN,即卷积神经网络的概念。卷积神经网络给图像领域带来了质的飞越,也将之前由李飞飞教授建立的ImageNet比赛提升到了新的高度,图像识别领域,计算机第一次超越了人类,从而引爆了最近两三年来对人工智能、深度学习的持续关注。
当CNN在图像领域火爆之后,自然作为人工智能三大领域之一的NLP,也很快拿来使用,即著名的Text-CNN,大家感兴趣的可以去看看这篇论文Convolutional Neural Networks for Sentence Classification,对NLP领域也具有重要的里程碑意义,现在引用量也达到了3436。
但是CNN有个比较严重的问题是,其没有序列的概念在里面,如果我们将一个句子做好embedding丢到CNN中做分类模型,那么CNN更多的是将这个句子看做一个词袋(bag-of-words bag),这样在NLP领域重要的语序信息就丢失了,那么我们便引出了RNN,即循环神经网络或说递归神经网络(这里值得注意的是,如果是对语句做分类模型,那么用CNN进行不同kernel的卷积,然后拼接是可以提取到一些语序信息,这其中也涉及到各种变种的CNN,大家可以多查查资料)。
对于循环神经网络,其实与CRF、HMM有很多共通之处,对于每一个输入\(x_t\),我们通过网络变换都会得到一个状态\(h_t\),对于一个序列来说,每一个token(可以是字也可以是词,在分词时是字)都会进入网络迭代,注意网络中的参数是共享的。这里不可免俗的放上经典图像吧:
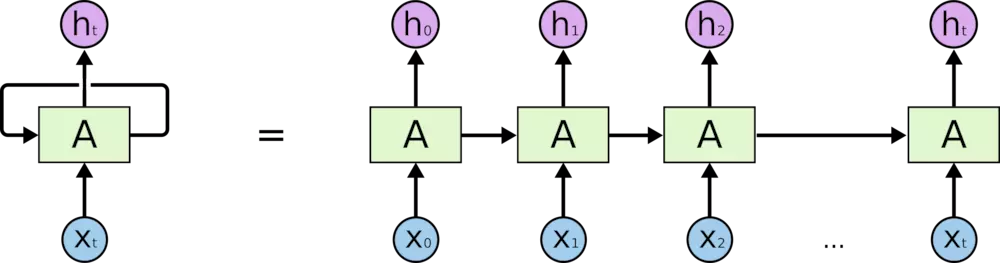
这里将循环神经网络展开,就是后面那样。大家注意下图中的\(A\),在RNN中就是一个比较简单的前馈神经网络,在RNN中会有一个严重的问题,就是当序列很长的时候,BP算法在反馈时,梯度会趋于零,即所谓的梯度消失(vanishing gradient)问题,这便引出了LSTM(Long Short Term Memory)。
LSTM本质上还是循环神经网络,只不过呢它把上面我们提到的\(A\)换了换,加了三个门,其实就是关于向量的几个变换表达式,来规避这种梯度消失问题,使得LSTM的逻辑单元能够更好的保存序列信息,同样不可免俗上下面这张经典的图片:
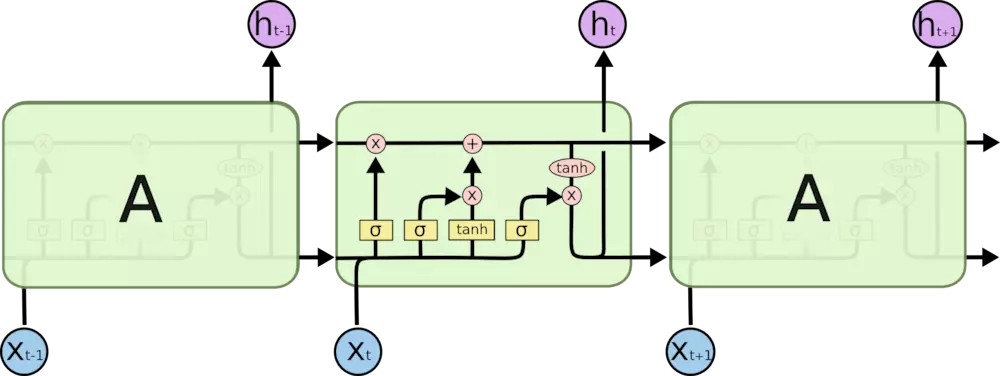
图中对应了四个表达式如下:
遗忘门:
\]
输入门:
\]
\]
状态更新:
\]
输出门:
\]
\]
一般呢LSTM都是一个方向将序列循环输入到网络之中,然而有时候我们需要两头关注序列的信息,这样便引出了Bi-LSTM,即双向LSTM,很简单,就是对于一个序列,我们有两个LSTM网络,一个正向输入序列,一个反向输入序列,然后将输出的state拼接在一起,供后续使用。
到这里我们简单的说了下关于循环神经网络的事情,下面我们看下在分词中应用LSTM
基于LSTM的分词
前文以及之前的系列博文,我们已经熟悉分词转换为Seq2Seq的思路,那么对于LSTM,我们需要做的是将一串句子映射成为Embedding,然后逐个输出到网络中,得到状态输出,进行序列标注。我们采用TensorFlow来开发。
Embedding
关于Embedding,我们可以直接下载网上公开的Wiki数据集训练好的Embedding,一般维度是100,也可以自己根据场景,利用Word2Vec、Fasttext等训练自己的Embedding。
数据预处理
其实深度的好多模型已经很成熟,最麻烦的是数据的预处理,在数据预处理阶段核心要做的是将序列映射到Embedding文件对应的id序列,并且按照Batch来切分,一般根据数据集的大小会设置64、128、256等不同的batch大小,在向网络输入数据,进行epoch迭代时,注意进行必要的shuffle操作,对于结果提高很有用,shuffle类似如下:
def shuffle(char_data, tag_data, dict_data, len_data):
char_data = np.asarray(char_data)
tag_data = np.asarray(tag_data)
dict_data = np.asarray(dict_data)
len_data = np.asarray(len_data)
idx = np.arange(len(len_data))
np.random.shuffle(idx)
return (char_data[idx], tag_data[idx], dict_data[idx], len_data[idx])
数据预处理我这里不多讲了,读者可以直接看github上开源的代码,有问题随时留言,我有空会来解答~
模型
我们的核心模型结构也很简单,将输入的id序列,通过Tensorflow 的查表操作,映射成对应的Embedding,然后输入到网络中,得到最终结果,进行Decode操作,得到每个字符的标记(BEMS),核心代码如下:
def __init__(self, config, init_embedding = None):
self.batch_size = batch_size = config.batch_size
self.embedding_size = config.embedding_size # column
self.hidden_size = config.hidden_size
self.vocab_size = config.vocab_size # row
# Define input and target tensors
self._input_data = tf.placeholder(tf.int32, [batch_size, None], name="input_data")
self._targets = tf.placeholder(tf.int32, [batch_size, None], name="targets_data")
self._dicts = tf.placeholder(tf.float32, [batch_size, None], name="dict_data")
self._seq_len = tf.placeholder(tf.int32, [batch_size], name="seq_len_data")
with tf.device("/cpu:0"):
if init_embedding is None:
self.embedding = tf.get_variable("embedding", [self.vocab_size, self.embedding_size], dtype=data_type())
else:
self.embedding = tf.Variable(init_embedding, name="embedding", dtype=data_type())
inputs = tf.nn.embedding_lookup(self.embedding, self._input_data)
inputs = tf.nn.dropout(inputs, config.keep_prob)
inputs = tf.reshape(inputs, [batch_size, -1, 9 * self.embedding_size])
d = tf.reshape(self._dicts, [batch_size, -1, 16])
self._loss, self._logits, self._trans = _bilstm_model(inputs, self._targets, d, self._seq_len, config)
# CRF decode
self._viterbi_sequence, _ = crf_model.crf_decode(self._logits, self._trans, self._seq_len)
with tf.variable_scope("train_ops") as scope:
# Gradients and SGD update operation for training the model.
self._lr = tf.Variable(0.0, trainable=False)
tvars = tf.trainable_variables() # all variables need to train
# use clip to avoid gradient explosion or gradients vanishing
grads, _ = tf.clip_by_global_norm(tf.gradients(self._loss, tvars), config.max_grad_norm)
self.optimizer = tf.train.AdamOptimizer(self._lr)
self._train_op = self.optimizer.apply_gradients(
zip(grads, tvars),
global_step=tf.contrib.framework.get_or_create_global_step())
self._new_lr = tf.placeholder(data_type(), shape=[], name="new_learning_rate")
self._lr_update = tf.assign(self._lr, self._new_lr)
self.saver = tf.train.Saver(tf.global_variables())
代码逻辑很清晰,将各种输入得到后,embedding查表结束后,放入Bi-LSTM模型,得到的结果进行Decode,这里注意我们用了一个CRF进行尾部Decode,经过试验效果更好,其实直接上一层Softmax也ok。对于bilstm如下:
def _bilstm_model(inputs, targets, dicts, seq_len, config):
'''
@Use BasicLSTMCell, MultiRNNCell method to build LSTM model
@return logits, cost and others
'''
batch_size = config.batch_size
hidden_size = config.hidden_size
vocab_size = config.vocab_size
target_num = config.target_num # target output number
seq_len = tf.cast(seq_len, tf.int32)
fw_cell = lstm_cell(hidden_size)
bw_cell = lstm_cell(hidden_size)
with tf.variable_scope("seg_bilstm"): # like namespace
# we use only one layer
(forward_output, backward_output), _ = tf.nn.bidirectional_dynamic_rnn(
fw_cell,
bw_cell,
inputs,
dtype=tf.float32,
sequence_length=seq_len,
scope='layer_1'
)
# [batch_size, max_time, cell_fw.output_size]/[batch_size, max_time, cell_bw.output_size]
output = tf.concat(axis=2, values=[forward_output, backward_output]) # fw/bw dimension is 3
if config.stack: # False
(forward_output, backward_output), _ = tf.nn.bidirectional_dynamic_rnn(
fw_cell,
bw_cell,
output,
dtype=tf.float32,
sequence_length=seq_len,
scope='layer_2'
)
output = tf.concat(axis=2, values=[forward_output, backward_output])
output = tf.concat(values=[output, dicts], axis=2) # add dicts to the end
# outputs is a length T list of output vectors, which is [batch_size*maxlen, 2 * hidden_size]
output = tf.reshape(output, [-1, 2 * hidden_size + 16])
softmax_w = tf.get_variable("softmax_w", [hidden_size * 2 + 16, target_num], dtype=data_type())
softmax_b = tf.get_variable("softmax_b", [target_num], dtype=data_type())
logits = tf.matmul(output, softmax_w) + softmax_b
logits = tf.reshape(logits, [batch_size, -1, target_num])
with tf.variable_scope("loss") as scope:
# CRF log likelihood
log_likelihood, transition_params = tf.contrib.crf.crf_log_likelihood(
logits, targets, seq_len)
loss = tf.reduce_mean(-log_likelihood)
return loss, logits, transition_params
注意这里做了两次LSTM,并将结果拼接在一起,而我们的损失函数是关于crf_log_likelihood。
如何添加用户词典
我们可以看到在整个模型训练好后,inference的过程是直接根据网络权重进行的,那么如何添加用户词典呢,这里我们采用的方式是将用户词典作为额外的特征拼接在Bi-LSTM结果的后面,就是在上面代码的output = tf.concat(values=[output, dicts], axis=2) # add dicts to the end这里,这个词典会分成四个部分,head、mid、single、tail,词头、词中、词尾以及单字词,这样对于用户词典是否出现用one-hot形式表达,不过实际使用过程中也还是存在切不出来的问题,读者可以考虑加强这部分特征。
整个代码我放在github上了,感兴趣的读者直接看源代码,有问题欢迎留言~
https://github.com/xlturing/machine-learning-journey/tree/master/seg_bilstm
终于写好这个系列了,之后谢谢最近在弄的Attention、Transformer以及BERT这一套在文本分类中的应用哈,欢迎大家交流。
浅谈分词算法(5)基于字的分词方法(bi-LSTM)的更多相关文章
- 浅谈分词算法(4)基于字的分词方法(CRF)
目录 前言 目录 条件随机场(conditional random field CRF) 核心点 线性链条件随机场 简化形式 CRF分词 CRF VS HMM 代码实现 训练代码 实验结果 参考文献 ...
- 浅谈分词算法(3)基于字的分词方法(HMM)
目录 前言 目录 隐马尔可夫模型(Hidden Markov Model,HMM) HMM分词 两个假设 Viterbi算法 代码实现 实现效果 完整代码 参考文献 前言 在浅谈分词算法(1)分词中的 ...
- 浅谈分词算法基于字的分词方法(HMM)
前言 在浅谈分词算法(1)分词中的基本问题我们讨论过基于词典的分词和基于字的分词两大类,在浅谈分词算法(2)基于词典的分词方法文中我们利用n-gram实现了基于词典的分词方法.在(1)中,我们也讨论了 ...
- 浅谈局域网ARP攻击的危害及防范方法(图)
浅谈局域网ARP攻击的危害及防范方法(图) 作者:冰盾防火墙 网站:www.bingdun.com 日期:2015-03-03 自 去年5月份开始出现的校内局域网频繁掉线等问题,对正常的教育教 ...
- 浅谈Tarjan算法及思想
在有向图G中,如果两个顶点间至少存在一条路径,称两个顶点强连通(strongly connected).如果有向图G的每两个顶点都强连通,称G是一个强连通图.非强连通图有向图的极大强连通子图,称为强连 ...
- 浅谈 Tarjan 算法
目录 简述 作用 Tarjan 算法 原理 出场人物 图示 代码实现 例题 例题一 例题二 例题三 例题四 例题五 总结 简述 对于初学 Tarjan 的你来说,肯定和我一开始学 Tarjan 一样无 ...
- 浅谈Manacher算法与扩展KMP之间的联系
首先,在谈到Manacher算法之前,我们先来看一个小问题:给定一个字符串S,求该字符串的最长回文子串的长度.对于该问题的求解.网上解法颇多.时间复杂度也不尽同样,这里列述几种常见的解法. 解法一 ...
- [Machine Learning] 浅谈LR算法的Cost Function
了解LR的同学们都知道,LR采用了最小化交叉熵或者最大化似然估计函数来作为Cost Function,那有个很有意思的问题来了,为什么我们不用更加简单熟悉的最小化平方误差函数(MSE)呢? 我个人理解 ...
- 浅谈Tarjan算法
从这里开始 预备知识 两个数组 Tarjan 算法的应用 求割点和割边 求点-双连通分量 求边-双连通分量 求强连通分量 预备知识 设无向图$G_{0} = (V_{0}, E_{0})$,其中$V_ ...
随机推荐
- charles代理以及关于其抓取https信息的操作
一直没有写一篇关于charles的文章来记录,但是发现偶尔还是会忘记,所以还是记一下,查起来比较方便. 首先在安装了charles之后默认的本地代理地址是 127.0.0.1:8888这个地址.如果希 ...
- mysql学习笔记五 —— MHA
MySQL_MHA ABB(主从复制)-->MHA(实现mysql高可用.读写分离.脚本控制vip飘逸)-->haproxy(对slave集群实现分发,负载均衡)-->keepali ...
- PostgreSQL、SQL Server数据库中的数据类型的映射关系
PostgreSQL 8.1 轰动发布,我也打算将原来使用 SQL Server 的一些应用迁移到 PostgreSQL 上,首先需要迁移的是表,那么这就必须要先搞清楚这两个数据库中的数据类型的映射关 ...
- js跨域请求jsonp解决方案-最简单的小demo
这里说的js跨域是指通过js在不同的域之间进行数据传输或通信,比如用ajax向一个不同的域请求数据,或者通过js获取页面中不同域的框架中(iframe)的数据.只要协议.域名.端口有任何一个不同,都被 ...
- appium学习记录2
unittest 学习 每执行一次 testcase 就会调用一次 setUP 与teardown 类方法只会执行一次 开始 与结束时候执行 类似反射方法 __init__ 与 __del__ set ...
- Java动态代理、XML、正则
15.1 动态代理 在之后学习Spring框架时,Spring框架有一大核心思想,就是AOP,(Aspact-Oriented-Programming 面向切面编程) 而AOP的原理就 ...
- ansible系列5-开启加速 Ansible 执行速度的功能
SSH pipelining 是一个加速 Ansible 执行速度的简单方法.ssh pipelining 默认是关闭,之所以默认关闭是为了兼容不同的 sudo 配置,主要是 requiretty 选 ...
- BZOJ2157旅游——树链剖分+线段树
题目描述 Ray 乐忠于旅游,这次他来到了T 城.T 城是一个水上城市,一共有 N 个景点,有些景点之间会用一座桥连接.为了方便游客到达每个景点但又为了节约成本,T 城的任意两个景点之间有且只有一条路 ...
- BZOJ2653middle——二分答案+可持久化线段树
题目描述 一个长度为n的序列a,设其排过序之后为b,其中位数定义为b[n/2],其中a,b从0开始标号,除法取下整.给你一个 长度为n的序列s.回答Q个这样的询问:s的左端点在[a,b]之间,右端点在 ...
- ACG图片站\python爬虫\LAMP环境
最近突然对web很感兴趣,碰巧看到阿里云服务器学生价十块钱一个月,果断买了一个自己搭建了一个网站. 网址 这里 LAMP环境就搭建了好久,linux+apache2+mysql+php,都是开源的软件 ...