ElasticSearch(六)底层索引控制
相似度算法
涉及到了ES的底层,首先讲一下ES的底层核心,相似度模型,ES的查询和传统的数据库查询最大的差别就在相似度查询(之前讲过,索引存储的最大差别就是讲非结构化数据转化为结构化),ES里面会给文档的相似度打分。那么这种打分的算法就是ES的查询的核心,默认的算法是TF/IDF,除了这个默认的算法之外还有很多其他的算法,罗列一下,当你发现现在的查询速度以及效率不满足需要的时候,可以考虑一下下面的算法:
Okapi BM25:适用场景是短文档;
Divergence from randomness (DFR):处理自然语言的相似度处理;
Information-based:同上;
LM Dirichlet:自己看吧:https://lucene.apache.org/core/4_9_0/core/org/apache/lucene/search/similarities/LMDirichletSimilarity.
LM Jelinek Mercer:https://lucene.apache.org/core/4_9_0/core/org/apache/lucene/search/similarities/LMJelinekMercerSimilarity.Note
ES的存储类型
下面是ES的存储方式:
Simple:尽是用于兼容,早期的基于bio的存储模式;
Niofs:基于NIO读写,默认;
Mmap:mapping映射,硬盘数据映射到到内存的虚拟地址;而且MMap只是是用于32bit机器,64bit机器不适用。
fs:是默认选项,会自动识别各个操作系统以及位数下应该采用哪种存储模式。早期版本名称是default_fs。
Mem(已经废弃):(es2.x之后已经移除)内存保存,如果数据存活时间不长,或者数据量不是特别的,采用内存放置,提高查询、检索效率;
事务日志和Searcher
介绍一下ES的索引查询的全流程:
创建索引就不讲了,前面都已经介绍了,包括路由策略等;
提交(Post)了一个文档,首先是提交到了事务日志,事务日志将会将此次提交持久化,主要是可追溯,一旦写入ES失败,可以通过事务日志来进行恢复,另外也避免过于频繁写入ES导致了ES所在主机的IO压力过大;然后事务日志将会定时把数据刷新到ES里面;
这个时候,还有一个对象出现就是searcher,这个货主要就是定时获取ES里面的元数据,通过searcher可以定位到查询文档的位置,我们通常使用/_search?pretty的方式进行查询就是通过访问searcher来进行查询的,因为search是定时刷新的(默认1s),所以searcher的数据是有延迟,可能不会瞬间将最新数据查到;不过还有一种方式就是直接通过指定文档ID的方式/index/docmentId?pretty,这种方式的查询不走searcher,而是综合了事务日志以及ES里面的数据;但是因为牵涉到了两部分的数据,所以如果对于实时性要求不高,但是希望快点可以使用search查询,反之则使用search。
发现是不是和HBase非常想,HBase也是client提交后先入WAL,然后刷到memstore中,最后才入HDFS,查询也是会从memstore以及HDFS中进行联合查询。
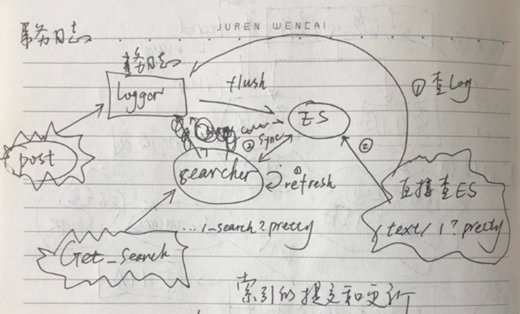
索引合并
索引合并(merge),好处就是加快检索,对于多个小文件的检索是比少量比较大的检索要慢的,所以索引是要合并的,同时还要保证不能合并的太大。当然代价就是I/O操作。合并调度,ES里面的调度分为两种顺序和并发,默认是采用并发,顺序这种模式,你就不用知道了。
IO控制
IO控制,ES是读写高频的应用,所以ES里面有对于IO限流一些配置,首先是指定限流配置应用范围,none(无限制),merge(只有索引合并限制),all(所有的操作都限制);之后ES里面可以针对最大吞吐量之类的属性进行限制。
ES缓存策略
接下来讲一下ES的缓存策略,ES高效海量数据查询一直是它的一个亮点,其中一个原因是因为ES的缓存机制很好。
过滤缓存,就是filtered的缓存,这个就不多说了,只要指定了filter,就可以对其进行缓存;过滤缓存也是有两个级别,索引级别的缓存以及节点级别缓存,一般推荐使用节点缓存;因为数据的落点不可知或者说不定(比如文档保存索引的分片和副本多是不可预知的);不过看了ES master 5.X的版本,已经不再提及索引级别的缓存,只提到了节点级别的缓存。
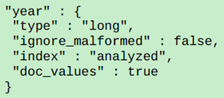
字段数据缓存(基本废弃),这类缓存只是针对非倒排索引的查询,比如聚合,脚本计算以及排序等,可以通过指定缓存字段来减少换存量,可以通过核定eager来对数据进行提前加载,即只要探测到有数据变化,就提前加载查询数据,保持数据新鲜度。但是要知道,docValue的处理效率已经和字段数据缓存很接近,而且不占用内存(仅需要少量的堆内存);另外到了ES5.0之后,你基本可以忽略字段数据缓存,因为ES会为每一个not_ analyzed字段(keyword type)指定docValues;如果想要对于非string的字段使用docValues,如下:
查询分片缓存,这个则是对于倒排索引数据进行缓存,前面两类都是基于非倒排索引,分片缓存则是基于倒排索引(需要对文档进行评分)的查询的缓存。
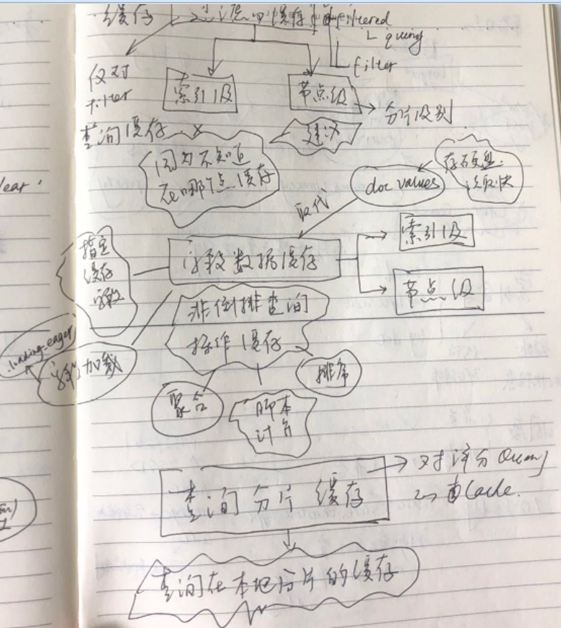
字段回路器,就是预判,如果某次查询使用内存量大于预设的阈值,将会拒绝此次此次查询,默认是达到70%的JVM堆内存。
缓存缓存最后一点就是清楚缓存,可以指定全部清空:
curl -XPOST 'localhost:9200/_cache/clear'
也可以指定索引进行清空:
curl -XPOST 'localhost:9200/mastering/_cache/clear'
curl -XPOST 'localhost:9200/mastering,books/_cache/clear'
还可以指定某类缓存清空:
curl -XPOST 'localhost:9200/mastering/_cache/clear?field_data=true&filter=false&query_cache=false'
ElasticSearch(六)底层索引控制的更多相关文章
- ElasticSearch优化系列六:索引过程
大家可能会遇到索引数据比较慢的过程.其实明白索引的原理就可以有针对性的进行优化.ES索引的过程到相对Lucene的索引过程多了分布式数据的扩展,而这ES主要是用tranlog进行各节点之间的数据平衡. ...
- Elasticsearch 关键字:索引,类型,字段,索引状态,mapping,文档
1. 索引(_index)索引:说的就是数据库的名字.我这个说法是对应到咱经常使用的数据库. 结合es的插件 head 来看. 可以看到,我这个地方,就有这么几个索引,索引就是数据库,后面是这个数据库 ...
- elasticsearch查询篇索引映射文档数据准备
elasticsearch查询篇索引映射文档数据准备 我们后面要讲elasticsearch查询,先来准备下索引,映射以及文档: 我们先用Head插件建立索引film,然后建立映射 POST http ...
- MySQL事务概念与流程和索引控制
MySQL事务概念与流程和索引控制 视图 1.什么是视图 我们在执行SQL语句其实就是对表进行操作,所得到的其实也是一张表,而我们需要经常对这些表进行操作,拼接什么的都会产生一张虚拟表,我们可以基于该 ...
- Elasticsearch 之 数据索引
对于提供全文检索的工具来说,索引时一个关键的过程——只有通过索引操作,才能对数据进行分析存储.创建倒排索引,从而让使用者查询到相关的信息. 本篇就ES的数据索引操作相关的内容展开: 更多内容参考:El ...
- iOS开发Swift篇—(六)流程控制
iOS开发Swift篇—(六)流程控制 一.swift中的流程控制 Swift支持的流程结构如下: 循环结构:for.for-in.while.do-while 选择结构:if.switch 注意:这 ...
- mysql进阶(二十六)MySQL 索引类型(初学者必看)
mysql进阶(二十六)MySQL 索引类型(初学者必看) 索引是快速搜索的关键.MySQL 索引的建立对于 MySQL 的高效运行是很重要的.下面介绍几种常见的 MySQL 索引类型. 在数 ...
- ElasticSearch创建动态索引
ElasticSearch创建动态索引 需求:某实例需要按照月份来维护,所以之前的“写死”索引的方式当然不行了.通过百度和看SpringDataElasticSearch官方文档,最后解决了这个问题. ...
- elasticsearch 内部对象结构数据索引
内部对象 经常用于 嵌入一个实体或对象到其它对象中.例如,与其在 tweet 文档中包含 user_name 和 user_id 域,我们也可以这样写: { "tweet": &q ...
随机推荐
- python-函数参数不固定
默认参数的应用场景: 1.默认安装 2.数据库连接,默认端口号 参数不固定的情况: 参数组: args:将接收的位置参数转换成元组 def test(*args): print(args) ...
- 2017年3月1日09:45:39 css选择器,session数据取不到
昨天碰到了一个问题,通过输入指定的url进行登录在服务端将url存在session中但是登陆之后因为页面提交的登录请求是ajax请求,在后端提取session时获取不当之前存的url,老司机说不是同一 ...
- 安装vue-cookie
// 安装cookie的命令// npm install vue-cookie --save// 为项目配置全局vue-cookieimport VueCookie from 'vue-cookie' ...
- Java学习笔记8(面向对象3:接口)
接口的概念: 接口是功能的集合,同样可以看最做事一种数据类型,是比抽象类更为抽象的"类”. 接口之描述所应该具备的方法,并没有具体实现,具体的实现有接口的实现类(相当于接口的子类)来完成.这 ...
- 区分IE版本的js代码
function IEVersion() { var userAgent = navigator.userAgent; //取得浏览器的userAgent字符串 var isIE = userAgen ...
- Spring Boot 揭秘与实战(八) 发布与部署 - 远程调试
文章目录 1. 依赖 2. 部署 3. 调试 4. 源代码 设置远程调试,可以在正式环境上随时跟踪与调试生产故障. 依赖 在 pom.xml 中增加远程调试依赖. <plugins> &l ...
- [转]Skynet之斗转星移 - 将控制权交给Lua
Skynet之斗转星移 - 将控制权交给Lua http://www.outsky.org/code/skynet-lua.html Sep 7, 2014 在我看来,Skynet的一个重要优势是 ...
- idea 中新建Servlet
本文转载自 :itellij idea创建javaWeb以及Servlet简单实现 一.创建并设置javaweb工程 1.创建javaweb工程File --> New --> Proj ...
- Python网络爬虫第二弹《http和https协议》
一.HTTP协议 1.官方概念: HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文 ...
- 【letcode】5-LongestPalindromicSubstring
回文串 回文串(palindromic string)是指这个字符串无论从左读还是从右读,所读的顺序是一样的:简而言之,回文串是左右对称的.一般求解一个字符串的最长回文子串问题. problem:Lo ...