基于结构化平均感知机的分词器Java实现
基于结构化平均感知机的分词器Java实现
作者:hankcs
最近高产似母猪,写了个基于AP的中文分词器,在Bakeoff-05的MSR语料上F值有96.11%。最重要的是,只训练了5个迭代;包含语料加载等IO操作在内,整个训练一共才花费23秒。应用裁剪算法去掉模型中80%的特征后,F值才下降不到0.1个百分点,体积控制在11兆。如果训练一百个迭代,F值可达到96.31%,训练时间两分多钟。
数据在一台普通的IBM兼容机上得到:

本模块已集成到HanLP 1.6以上版本开源,文档位于项目wiki中,欢迎使用!【hanlp1.7新版本已经发布,可以去新版本查到看使用】
结构化预测
关于结构化预测和非结构化预测的区别一张讲义说明如下:

更多知识请参考Neubig的讲义《The Structured Perceptron》。
本文实现的AP分词器预测是整个句子的BMES标注序列,当然属于结构化预测问题了。
感知机
二分类
感知机的基础形式如《统计学习方法》所述,是定义在一个超平面上的线性二分类模型。作为原著第二章,实在是简单得不能再简单了。然而实际运用中,越简单的模型往往生命力越顽强。
这里唯一需要补充的是,感知机是个在线学习模型,学习一个训练实例后,就可以更新整个模型。
多分类
怎么把二分类拓展到多分类呢?可以用多个分类器,对于BMES这4种分类,就是4个感知机了。每个感知机分别负责分辨“是不是B”“是不是M”“是不是E”“是不是S”这4个二分类问题。在实现中,当然不必傻乎乎地创建4个感知机啦。把它们的权值向量拼接在一起,就可以输出“是B的分数”“是M的分数”“是E的分数”“是S的分数”了。取其最大者,就可以初步实现多分类。但在分词中,还涉及到转移特征和HMM-viterbi搜索算法等,留到下文再说。
平均感知机
平均感知机指的是记录每个特征权值的累计值,最后平均得出最终模型的感知机。为什么要大费周章搞个平均算法出来呢?
前面提到过,感知机是个在线学习模型,学习一个训练实例后,就可以更新整个模型。假设有10000个实例,模型在前9999个实例的学习中都完美地得到正确答案,说明此时的模型接近完美了。可是最后一个实例是个噪音点,朴素感知机模型预测错误后直接修改了模型,导致前面9999个实例预测错误,模型训练前功尽弃。
有什么解决方案呢?一种方案是投票式的,即记录每个模型分类正确的次数,作为它的得票。训练结束时取得票最高的模型作为最终模型。但这种算法是不实际的,如果训练5个迭代,10000个实例,那么就需要储存50000个模型及其票数,太浪费了。
最好用的方法是平均感知机,将这50000个模型的权值向量累加起来,最后除以50000就行了,这样任何时候我们只额外记录了一个累加值,非常高效了。关于平均感知机的详情请参考《200行Python代码实现感知机词性标注器》。虽然那篇文章是讲解词性标注的,但相信作为万物灵长的读者一定拥有举一反三的泛化能力。
语言模型
HMM
我们不是在讲解感知机分词吗?怎么跟HMM扯上关系了?
其实任何基于序列标注的分词器都离不开隐马尔科夫链,即BMES这四个标签之间的Bigram(乃至更高阶的n-gram)转移概率。作为其中一员的AP分词器,也不例外地将前一个字符的标签作为了一个特征。该特征对预测当前的标签毫无疑问是有用的,比如前一个标签是B,当前标签就绝不可能是S。
这种类似于y[i-1]的特征在线性图模型中一般称为转移特征,而那些不涉及y[i-1]的特征通常称为状态特征。
viterbi
由于AP分词器用到了转移特征,所以肯定少不了维特比搜索。从序列全体的准确率考虑,搜索也是必不可少的。给定隐马尔可夫模型的3要素,我用Java写了一段“可运行的伪码”:
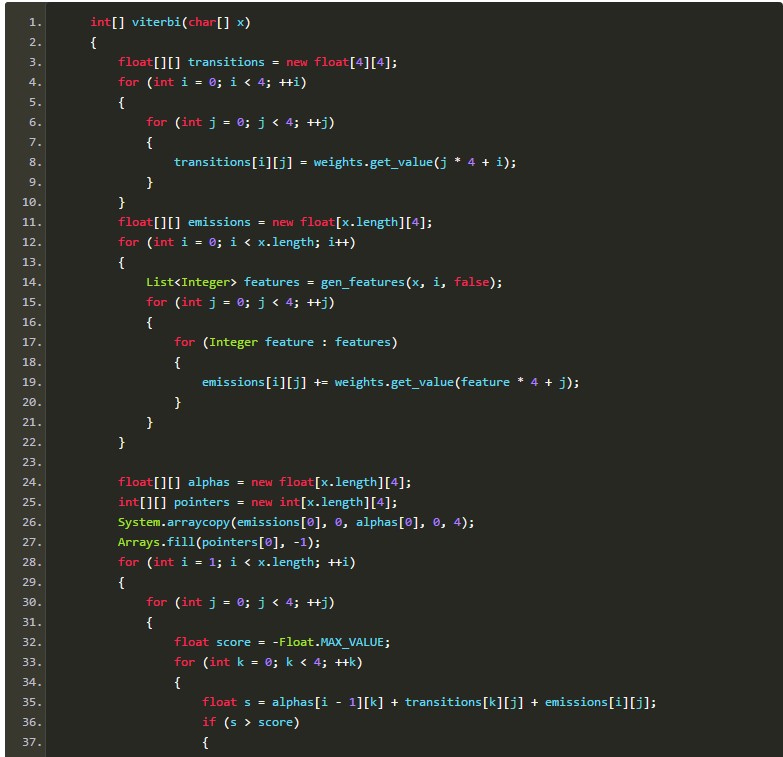
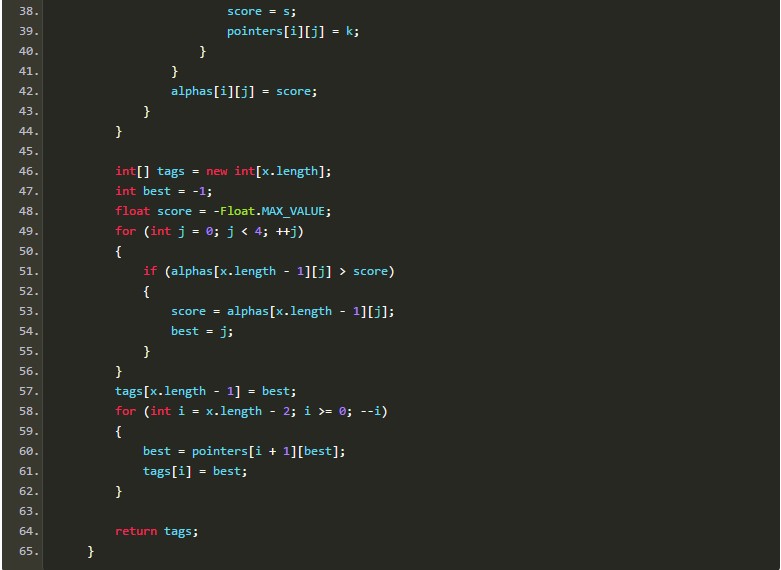
上述实现是个重视条理胜于效率的原型,古人云“过早优化是魔鬼”。相信聪明的读者一定能看懂这里面在干什么。
特征提取
定义字符序列为x,标注序列为y。
转移特征
转移特征就是上面说的y[i-1]。
状态特征
我一共使用了7种状态特征:

在邓知龙的《基于感知器算法的高效中文分词与词性标注系统设计与实现》中提到,要利用更复杂的字符n-gram、字符类别n-gram、叠字、词典等特征。但在我的实践中,除了上述7种特征外,我每减少一个特征,我的AP分词器的准确率就提高一点,也许是语料不同吧,也许是特征提取的实现不同。总之,主打精简、高效。
训练
迭代数目其实不需要太多,在3个迭代内模型基本就收敛了:
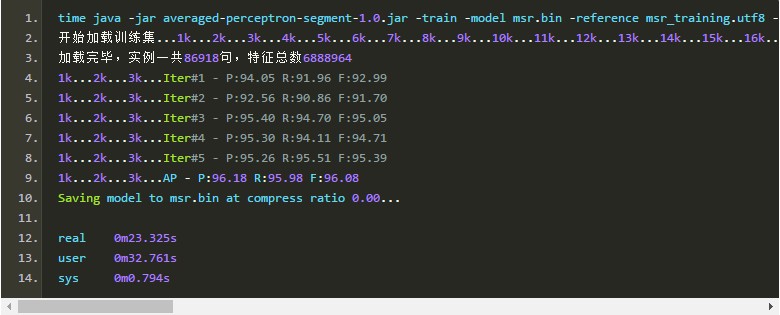
第4个迭代似乎帮了倒忙,但万幸的是,我们使用的是平均感知机。权值平均之后,模型的性能反而有所提升。
此时模型大小:

模型裁剪
《基于感知器算法的高效中文分词与词性标注系统设计与实现》提到的模型裁剪策略是有效的,我将压缩率设为0.2,即压缩掉20%的特征,模型准确率没有变化:
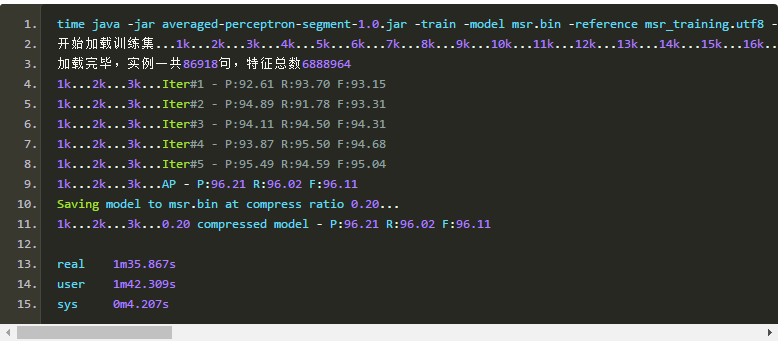
由于我使用了随机shuffle算法,所以每次训练准确率都略有微小的上下波动。此时可以看到模型裁剪过程花了额外的1分钟,裁剪完毕后准确率维持96.11不变。
此时模型大小:

裁减掉50%如何呢?

此时模型大小:
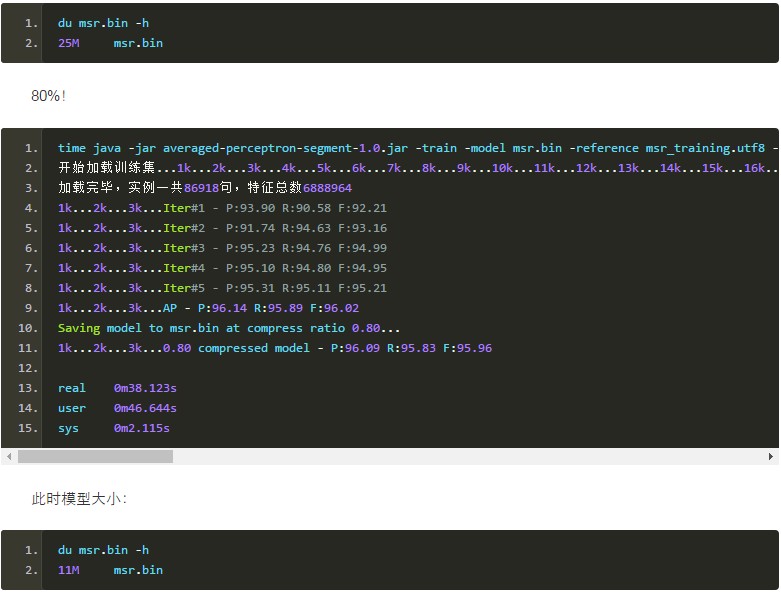
可见裁剪了80%的特征,体积从54M下降到11M,模型的准确率才跌了不到0.1个百分点!这说明大部分特征都是没用的,特征裁剪非常有用、非常好用!
Reference
邓知龙 《基于感知器算法的高效中文分词与词性标注系统设计与实现》
基于结构化平均感知机的分词器Java实现的更多相关文章
- ElasticSearch最全分词器比较及使用方法
介绍:ElasticSearch 是一个基于 Lucene 的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于 RESTful web 接口.Elasticsearch 是用 Java 开 ...
- IK分词器 原理分析 源码解析
IK分词器在是一款 基于词典和规则 的中文分词器.本文讲解的IK分词器是独立于elasticsearch.Lucene.solr,可以直接用在java代码中的部分.关于如何开发es分词插件,后续会有文 ...
- ES-自然语言处理之中文分词器
前言 中文分词是中文文本处理的一个基础步骤,也是中文人机自然语言交互的基础模块.不同于英文的是,中文句子中没有词的界限,因此在进行中文自然语言处理时,通常需要先进行分词,分词效果将直接影响词性.句法树 ...
- elasticsearch教程--中文分词器作用和使用
概述 本文都是基于elasticsearch安装教程 中的elasticsearch安装目录(/opt/environment/elasticsearch-6.4.0)为范例 环境准备 ·全新最小 ...
- ELK技术-IK-中文分词器
1.背景 1.1 简介 ES默认的分词器对中文分词并不友好,所以一般会安装中文分词插件,以便能更好的支持中文分词检索. 本例参考文档:<一文教你掌握IK中文分词> 1.2 IK分词器 IK ...
- 【中文分词】结构化感知器SP
结构化感知器(Structured Perceptron, SP)是由Collins [1]在EMNLP'02上提出来的,用于解决序列标注的问题:中文分词工具THULAC.LTP所采用的理论模型便是基 ...
- lucene全文搜索之二:创建索引器(创建IKAnalyzer分词器和索引目录管理)基于lucene5.5.3
前言: lucene全文搜索之一中讲解了lucene开发搜索服务的基本结构,本章将会讲解如何创建索引器.管理索引目录和中文分词器的使用. 包括标准分词器,IKAnalyzer分词器以及两种索引目录的创 ...
- Solr中的概念:分析器(analyzer)、字符过滤器(character filter)、分词器(Tokenizer)、词元过滤器(Token Filter)、 词干化(Stemming)
文本中包含许多文本处理步骤,比如:分词,大写转小写,词干化,同义词转化和许多的文本处理. 文本分析既用于索引时对一文本域的处理,也用于查询时查询字符串的文本处理.文本处理对搜索引擎的搜索结果有着重要的 ...
- 自制基于HMM的中文分词器
不像英文那样单词之间有空格作为天然的分界线, 中文词语之间没有明显界限.必须采用一些方法将中文语句划分为单词序列才能进一步处理, 这一划分步骤即是所谓的中文分词. 主流中文分词方法包括基于规则的分词, ...
随机推荐
- ubuntu安装scrapy方法
sudo apt-get install python-dev [默认安装python2] sudo apt-get install python3-dev [指定安装python3最新的] ...
- :after和:before伪元素的解释
:after 是清除浮动 让其高度和内容高度相同 :before 是防止上边塌陷 关注微信小程序
- 某些浏览器没有canvas.toBlob 方法的解决方案
var dataURLtoBlob = require('blueimp-canvas-to-blob'); // 80x60px GIF image (color black, base64 dat ...
- 解决vi编辑器不能使用方向键和退格键
1.使用vi命令时,不能正常编辑文件,使用方向键时老是出现很多字母 这个问题主要是新系统直装了vi,没有装vim.因为vi是不能直接按退格键删除字符的,所以当你使用退格键删除字符,只有在按下esc时, ...
- 微软Power BI 每月功能更新系列——10月Power BI 新功能学习
Power BI Desktop10月产品功能摘要 本月Power Plus Desktop的更新充满了整个产品的小型和大型改进.一个巨大的更新是Power BI服务支持我们的复合模型和聚合预览.这实 ...
- 安装最新nginx
另外:http://nginx.org/en/linux_packages.html#mainline https://blog.csdn.net/hiram/article/details/5178 ...
- JS书写规范
1.js代码是由语句组成的,每一条语句以分号结尾: 语句是有关键字,元素符,表达式组成的:2.js代码严格区分大小写3.所有的标点符号都是英文的4.//表示单行注释,/* */表示多行注释
- Gym-101673 :East Central North America Regional Contest (ECNA 2017)(寒假自训第8场)
A .Abstract Art 题意:求多个多边形的面积并. 思路:模板题. #include<bits/stdc++.h> using namespace std; typedef lo ...
- 2017java文本文件操作(读写操作)
java的读写操作是学java开发的必经之路,下面就来总结下java的读写操作. 从上图可以开出,java的读写操作(输入输出)可以用“流”这个概念来表示,总体而言,java的读写操作又分为两种:字符 ...
- 数据类型int、float、str、list、dict、set定义及常用方法汇总
数据类型int:记录整数事物状态 可变不可变:值不可变类型,改变变量值实则是改变了变量的指向 int():功能:1.工厂函数, i = 5 <==> i = int(5) 2.强制类型转换 ...