JDK 1.8源码阅读 ArrayList
一,前言
ArrayList是Java开发中使用比较频繁的一个类,通过对源码的解读,可以了解ArrayList的内部结构以及实现方法,清楚它的优缺点,以便我们在编程时灵活运用。
二,ArrayList结构

如上图所示:ArrayList是一种线性数据结构,它的底层是用数组实现的,相当于动态数组。与Java中的数组相比,它的容量能动态增长。类似于C语言中的动态申请内存,动态增长内存。
当创建一个数组的时候,就必须确定它的大小,系统会在内存中开辟一块连续的空间,用来保存数组,因此数组容量固定且无法动态改变。ArrayList在保留数组可以快速查找的优势的基础上,弥补了数组在创建后,要往数组添加元素的弊端。实现的基本方法如下:
1. 快速查找:在物理内存上采用顺序存储结构,因此可根据索引快速的查找元素。
2. 容量动态增长: 当数组容量不够用时,创建一个比原数组容量大的新数组,将数组中的元素“搬”到新数组,再将新的元素也放入新数组,最后将新数组赋给原数组即可。
3. ArrayList插入:。插入一个元素的时候,是耗时是一个常量时间O(1),在插入n个元素的时候,需要的时间就是O(n)。其他的操作中,运行的时间也是一个线性的增长(与数组中的元素个数有关)。
三,ArrayList源码阅读
3.1 ArrayList的继承关系
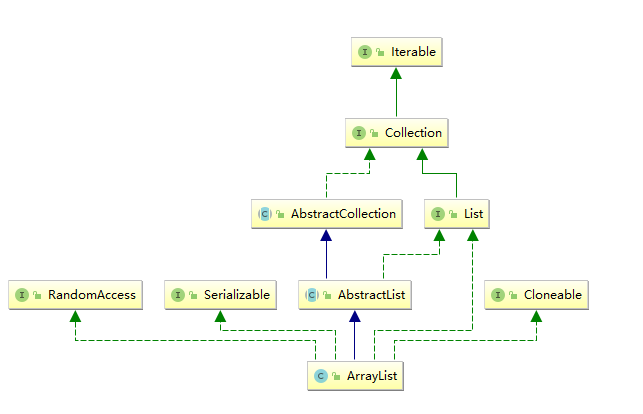
在这提一下RandomAccess接口:
实现所使用的标记接口,用来表明其支持快速(通常是固定时间)随机访问。此接口的主要目的是允许一般的算法更改其行为,从而在将其应用到随机或连续访问列表时能提供良好的性能。
对于顺序访问的list,比如LinkedList,使用Iterator访问会比使用for-i来遍历list更快。这一点其实很好理解,当对于LinkedList使用get(i)的时候,由于是链表结构,所以每次都会从表头开始向下搜索,耗时肯定会多。
对于实现RandomAccess这个接口的类,如ArrayList,我们在遍历的时候,使用for(int i = 0; i < size; i++)来遍历,其速度比使用Iterator快(接口上是这么写的)。但是笔者看源码的时候,Iterator里使用的也是i++,这种遍历,无非是增加了fail-fast判断,估计就是这个导致了性能的差距,但是没有LinkedList这么大。笔者循环了 1000 * 100 次,贴出比较结果,仅供参考.
import java.util.ArrayList;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.ListIterator; public class Main { public static void main(String[] args) { ArrayList al = new ArrayList<Integer>();
for (int i = 1; i < 1000 * 100; i++) {
al.add(i);
}
long tmp_time1 = System.currentTimeMillis();
for (int j = 1; j < al.size(); j++) {
Object ol = al.get(j);
}
long tmp_time2 = System.currentTimeMillis();
System.out.println(tmp_time2-tmp_time1); // Iterator iterator = al.iterator();
for(al.iterator(); iterator.hasNext();){
Object next = iterator.next();
}
long tmp_time3 = System.currentTimeMillis();
System.out.println(tmp_time3-tmp_time2); // LinkedList bl = new LinkedList<Integer>();
for (int i = 1; i < 1000 * 100; i++) {
bl.add(i);
}
long tmp_time4 = System.currentTimeMillis();
for (int j = 1; j < bl.size(); j++) {
Object ol = bl.get(j);
}
long tmp_time5 = System.currentTimeMillis();
System.out.println(tmp_time5-tmp_time4); // Iterator iterator2 = bl.iterator();
for(bl.iterator(); iterator2.hasNext();){
Object next = iterator2.next();
}
long tmp_time6 = System.currentTimeMillis();
System.out.println(tmp_time6-tmp_time5); //
}
} // 分别是1,4,7561,4
不对比不知道,一对比吓一跳,当然也有可能是笔者电脑原因。所以在选择遍历方式时需要谨慎使用。
3.2 ArrayList的成员变量
直接贴出源码,如下所示:
//初始化默认容量
private static final int DEFAULT_CAPACITY = 10;
// 空对象数组
private static final Object[] EMPTY_ELEMENTDATA = {};
// 默认容量的空对象数组
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};// 存储的数量
private int size;
// 数组能申请的最大数量
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
在上面我们说过,ArrayList是一种可变的数组,其实他是有一个初始值的,当超出这个初始值时就会进行扩容,而这个初始值就为10,也就是上面的
DEFAULT_CAPACITY显示的值。
3.3 ArrayList的构造方法
public ArrayList(int initialCapacity) {} // 初始对于大小的ArrayList
public ArrayList() {} // 无参调用
public ArrayList(Collection<? extends E> c) {} // 数组拷贝形式
3.4 ArrayList的常用方法
在这只列举一些常用的方法,若需要更加详细的内容,可以查看源码。
public int size() {} // 返回ArrayList的长度
public boolean isEmpty() {} // 判断是否为空
public boolean contains(Object o) {} // 查看是否包含某个元素
public int indexOf(Object o) {} // 返回元素索引
public int lastIndexOf(Object o) {} // 返回某个元素最后一次出现的索引
public Object clone() {} // 克隆一个ArrayList
public Object[] toArray() {} // 将ArrayList变成数组
public <T> T[] toArray(T[] a) {} // 指定数组的类型
public E get(int index) {} // 返回对应索引的元素
public E set(int index, E element) {} // 将对于索引位置元素替换为指定的元素
public boolean add(E e) {} // 在末尾添加元素
public void add(int index, E element) {} // 在指定位置添加元素
public E remove(int index) {} // 移除对应索引位置的元素
public boolean remove(Object o) {} // 直接移除某个元素, 若没有该元素返回falsepublic void clear() {} // 清空ArrayList
public boolean addAll(Collection<? extends E> c) {} // 在某位添加一个集合到ArrayList
public boolean addAll(int index, Collection<? extends E> c) {} // 在指定位置添加一个集合
protected void removeRange(int fromIndex, int toIndex) {} // 删除一段索引区间的元素public boolean removeAll(Collection<?> c) {} // 删除一个集合
public boolean retainAll(Collection<?> c) {}public ListIterator<E> listIterator(int index) {} // 转换成一个迭代器对象
public ListIterator<E> listIterator() {} //转换成一个List迭代器对象
public Iterator<E> iterator() {} // 转换成一个迭代器对象
public List<E> subList(int fromIndex, int toIndex) {} // 窃取一段ArrayList
@Override
public void forEach(Consumer<? super E> action) {} // 增强for可以使用
@Override
public boolean removeIf(Predicate<? super E> filter) {}
@Override
@SuppressWarnings("unchecked")
public void replaceAll(UnaryOperator<E> operator) {}
@Override
@SuppressWarnings("unchecked")
public void sort(Comparator<? super E> c) {} // 排序 参数是排序方法
四,总结
ArrayList在随机访问的时候,数组的结构导致访问效率比较高,但是在指定位置插入,以及删除的时候,需要移动大量的元素,导致效率低下,在使用的时候要根据场景特点来选择,另外注意循环访问的方式选择。
JDK 1.8源码阅读 ArrayList的更多相关文章
- 【JDK1.8】JDK1.8集合源码阅读——ArrayList
一.前言 在前面几篇,我们已经学习了常见了Map,下面开始阅读实现Collection接口的常见的实现类.在有了之前源码的铺垫之后,我们后面的阅读之路将会变得简单很多,因为很多Collection的结 ...
- JDK 1.8 源码阅读和理解
根据 一篇文章教会你,如何做到招聘要求中的“要有扎实的Java基础” 的指引,决定开始阅读下JDK源码. 本文将作为源码阅读总纲 一.精读部分 java.io java.lang java.util ...
- JDK 1.8源码阅读 TreeMap
一,前言 TreeMap:基于红黑树实现的,TreeMap是有序的. 二,TreeMap结构 2.1 红黑树结构 红黑树又称红-黑二叉树,它首先是一颗二叉树,它具体二叉树所有的特性.同时红黑树更是一颗 ...
- JDK 1.8源码阅读 HashMap
一,前言 HashMap实现了Map的接口,而Map的类型是成对出现的.每个元素由键与值两部分组成,通过键可以找对所对应的值.Map中的集合不能包含重复的键,值可以重复:每个键只能对应一个值. 存储数 ...
- JDK 1.8源码阅读 HashSet
一,前言 类实现Set接口,由哈希表支持(实际上是一个 HashMap集合).HashSet集合不能保证的迭代顺序与元素存储顺序相同.HashSet集合,采用哈希表结构存储数据,保证元素唯一性的方式依 ...
- JDK 1.8源码阅读 LinkList
一,前言 LinkedList是一个实现了List接口和Deque接口的双端链表.有关索引的操作可能从链表头开始遍历到链表尾部,也可能从尾部遍历到链表头部,这取决于看索引更靠近哪一端. LinkedL ...
- JDK源码阅读——ArrayList
序 如同C语言中字符数组向String过渡一样,作为面向对象语言,自然而然的出现了由Object[]数据形成的集合.本文从JDK源码出发简单探讨一下ArrayList的几个重要方法. Fields / ...
- JDK源码阅读--ArrayList
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess ...
- Java源码阅读ArrayList
1简介 public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAc ...
随机推荐
- Unity3D Shader 模型流光效果
Shader "Custom/FlowColor" { Properties { _MainTex ("Base (RGB)", 2D) = "whi ...
- 百万级数据下的mysql深度解析
首先,数据量大的时候,应尽量避免全表扫描,应考虑在 where 及 order by 涉及的列上建立索引,建索引可以大大加快数据的检索速度.但是,有些情况索引是不会起效的: 1.应尽量避免在 wher ...
- js对象属性两种调用bug
jsobj.url_3[0]=url_3[1];这就错误jsobj.url_3[0]红色看成一个整体的0的属性,这就错了 TypeError: Cannot set property '0' of u ...
- ARM v8中断机制和中断处理(转)
https://blog.csdn.net/firefox_1980/article/details/40113637 https://blog.csdn.net/firefox_1980/artic ...
- Echarts Map 值域为小数的原因
最近做一个项目用到了Echarts Map不知道怎么回事,有时多了一位小时,可这个意义不用小数表示(1.0个人似乎觉得有点奇怪嘞 {boolean}calculable false 是否启用值域漫游, ...
- hdu4300 Clairewd’s message【next数组应用】
Clairewd’s message Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Other ...
- React event
React event 组件: React 自有方法 用户定义方法 一.虚拟事件对象 事件处理器将会传入 虚拟事件对象 的实例,一个对浏览器本地事件的跨浏览器封装.它有和浏览器本地事件相同的属性和方法 ...
- php 之数组
PHP之array数组 PHP中的数组实际上是一个有序映射.映射是一种把values关联到keys的类型.此类型在很多方面做了优化, 因此可以把它当成真正的数组,或列表(向量),散列表(是映射的一种实 ...
- [skill][graphviz] 到底用什么画图: graphviz/inkscape/yed
官方教程文档:http://www.graphviz.org/pdf/dotguide.pdf 一:在文档里抄一个简单的例子 /home/tong/Src/copyright/onescorpion/ ...
- U3d 入门
环境搭建: 1.安装exe; 2.破解 ,百度