利用python 数据分析入门,详细教程,教小白快速入门
这是一篇的数据的分析的典型案列,本人也是经历一次从无到有的过程,倍感珍惜,所以将其详细的记录下来,用来帮助后来者快速入门,,希望你能看到最后!
需求:对obo文件进行解析,输出为json字典格式
数据的格式如下:
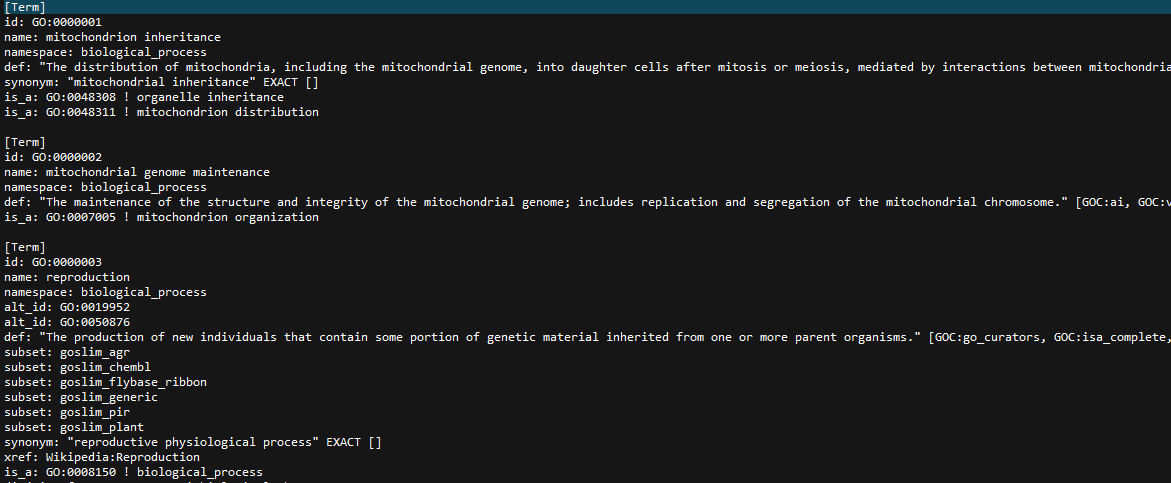
我们设定 一个trem or typedef为一条标签,一行为一条记录或者是键值对,以此为标准!
下面我们来对数据进行分析:
数据集中一共包含两种标签[trem] and [typedef]两种标签,每个标签下边有多个键值对,和唯一的标识符id,每行记录以“/n”结尾,且每条标签下下有多个相同的键值对,for examble: is_a,synonym...
算法设计:
1. 数据集中含有【trem】和【typedef】两种标签,因此,我们将数据分成两个数据集分别来进行处理。
2.循环遍历数据集,将键值对的键去除,并且对每一个键进行计数,并且进行去重操作
(我刚开始的想法是根据id的数量于其他的键的数量进行比较,找出每个标签下存在重复的键值对,进而确定每个标签下存在重复的键值对 :is_a,有点想多了,呵呵~)
3.由于发现每条标签下的记录的顺序都是一定的,id永远排在前面,用字典的形式存储是顺序是乱的,看上去很不舒服,所以我们相办法将他存在list里面,最大限度的还原了原有数据。
4. 处理相同键的键值对,字典中不允许存在一键多值的情况,我们将他存到一个list里面,也就相当于大list里面套小list
5.对数据集进行遍历,
(1)将取出来的键值对的键值存储起来
(2)以“【”作为我们的结束,将键值对的值存储到相对应的键下面,也就是一条标签
(3)将我们所取得值存储到汇总在一起,并且对声明的字典和list进行初始化,方便进行下一次的循环
(4)进行到这里,我们处理仅仅只是处理完了一个标签,还需要一个总的list,将所有的标签都存储进去
(这里的算法还是不完善的,我希望看到这篇博客的人可以提出宝贵的建议)
代码设计以及踩过的坑:
1.打印出所有的键
附引用代码:

- '''
打印出所有的键
'''
with open('go.obo','r',encoding="utf-8") as f: #打开文件- for line in f.readlines(): #对数据进行每一行的循环
list = [] ## 空列表
lable = line.split(":")[0] #读取列表名,
print(lable)
list.append(lable) ## 使用 append() 向list中添加元素
# print(list)- #print(lable)
- # lst2 = list(set(lst1))
# print(lst2)
print(list)
2.但是在做上一步的时候,出现了一个问题,那就是没有区分局部变量和全局变量,问题发现的思路,先观察list输出的值,发现只有最后一个值,这时候就要考虑值是否被覆盖,找到问题,于是把list升级为全局变量
附引用代码:
- with open('go.obo','r',encoding="utf-8") as f: #打开文件
# dict = {}
list = [] ## 空列表- for line in f.readlines(): #对数据进行每一行的循环
total = []
lable = line.split(":")[0] #读取列表名,正确来说读取完列表名之后,还要进行去重的处理
# print(lable)
# list.append(lable) ## 使用 append() 向list中添加元素
# print(list) 这种操作list中每次都只有一个变量
list.append(lable)- #print(lable)
# lst2 = list(set(lst1))
# print(lst2)- # print(list)
dict = {}
for key in list:
dict[key] = dict.get(key, 0) + 1
print(dict)
3.我们将统计的结果输出在txt中,这个时候问题出现了,输出的键值对中只有键没有值,这就搞笑了,接着往下走
附引用代码:
- '''
将dict在txt中输出
'''
with open('go.obo', 'r', encoding="utf-8") as f: # 打开文件
# dict = {}
list = [] ## 空列表- for line in f.readlines(): # 对数据进行每一行的循环
total = []
lable = line.split(":")[0] # 读取列表名,正确来说读取完列表名之后,还要进行去重的处理
# print(lable)
# list.append(lable) ## 使用 append() 向list中添加元素
# print(list) 这种操作list中每次都只有一个变量
list.append(lable)- # print(lable)
print("################################################")
# lst2 = list(set(lst1))
# print(lst2)- # print(list)
dict = {}
for key in list:
dict[key] = dict.get(key, 0) + 1
print(dict)- fileObject = open('sampleList.txt', 'w')
- for ip in dict:
fileObject.write(ip)
fileObject.write('\n')- fileObject.close()
4.由于我平时处理的json文件比较多,主要面向mongo,所以我试着将其转化为json格式,发现问题解决了,这里还是很神奇的,但是不明确问题出在什么地方。
附引用代码:
- import json
with open('go.obo', 'r', encoding="utf-8") as f: # 打开文件
# dict = {}
list = [] ## 空列表- for line in f.readlines(): # 对数据进行每一行的循环
total = []
lable = line.split(":")[0] # 读取列表名,正确来说读取完列表名之后,还要进行去重的处理
# print(lable)
# list.append(lable) ## 使用 append() 向list中添加元素
# print(list) 这种操作list中每次都只有一个变量
list.append(lable)- # print(lable)
print("################################################")
# lst2 = list(set(lst1))
# print(lst2)- # print(list)
dict = {}
for key in list:
dict[key] = dict.get(key, 0) + 1
print(dict)- fileObject = open('sampleList.txt', 'w')
- # for ip in dict:
# fileObject.write(ip)
# fileObject.write('\n')
#
# fileObject.close()- jsObj = json.dumps(dict)
- fileObject = open('jsonFile.json', 'w')
fileObject.write(jsObj)
fileObject.close()
5.接下来我先实现简单的测试,抽取部分数据,抽取三个标签,然后再取标签里的两个值
附引用代码:
- with open('nitian','r',encoding="utf-8") as f: #打开文件
# dic={} #新建的字典
total = [] #列表
newdic = [] #列表- #在这里进行第一次初始化
#这里的每一个字段都要写两个
id = {} #
id_number = ""#含有一行的为“”\ 含有一行的为字符串
is_a = {}
is_a_list = []#含有多行的为[] 含有多行的为list- for line in f.readlines(): #对数据进行每一行的循环
lable = line.split(":")[0] #读取列表名,正确来说读取完列表名之后,还要进行去重的处理
#print(lable)
#开始判断
if lable == "id": #冒号前的内容 开始判断冒号之前的内容
id_number = line[3:] #id 两个字母+
# 一个冒号
elif lable == "is_a":
is_a_list.append(line[5:].split('\n'))- elif line[0] == "[":
#把数据存入newdic[]中
id["id"] = id_number
newdic.append(id)- is_a["is_a"] = is_a_list
newdic.append(is_a)- #把newdic存入总的里面去
total.append(newdic)
#初始化所有新的标签
id = {} # 含有一个的为“”\
id_number = ""
is_a = {}
is_a_list = []- #初始化小的newdic
newdic = []- total.append(newdic)
- print(total)
6.做到这里我们发现问题出了很多,也就是算法设计出现了问题
数据的开头出现了一系列的空的{id :“ ”} {name:“”} {},{}.....,多了一行初始化,回头检查算法,找到问题:我们用的“[”来判断一个标签的结束
修改方式(1)将符号“[”作为我们判断的开始
(2)修改数据,将数据中的开头的[term]去掉,加在数据集的结尾
7.数据的后面出现了总是出现一些没有意义的“ ”,我们发现是我们没有对每个键值对后面的标签进行处理,所以我们引入了strip()函数,但是strip()函数只能作用于字符串,当你想要作用于list时,要先把list里面的东西拿出来,进而进行操作。
8.键值对的键def 与关键字冲突,我们的解决简单粗暴,直接将其转化为大写
9.完整的代码如下:
附引用代码:
- import json
- class GeneOntology(object):
- def __init__(self, path):
self.path = path
self.total = []- # Use a dictionary to remove extra values to Simplified procedure
# def rebuild_list(self,record_name):
# records = {id,is_a}
#
# list = rebuile_list('HEADER'')
# records.get(record_name)- # Define a function to read and store data
def read_storage_data(self):- id = {} #Use a dictionary to store each keyword
id_number = "" # Store the value of each row as a string- is_obsolete = {}
is_obsolete_number = ""- is_class_level = {}
is_class_level_number = ""- transitive_over = {}
transitive_over_number = ""- # There is a place where the keyword “def” conflicts, so I want to change the name here.
DEF = {}
DEF_number = ""- property_value = {}
property_value_number = ""- namespace = {}
namespace_number = ""- comment = {}
comment_number = ""- intersection_of = {}
intersection_of_number = ""- xref = {}
xref_number = ""- name = {}
name_number = ""- disjoint_from = {}
disjoint_from_number = ""- replaced_by = {}
replaced_by_number = ""- relationship = {}
relationship_number = ""- alt_id = {}
alt_id_number = ""- holds_over_chain = {}
holds_over_chain_number = ""- subset = {}
subset_number = ""- expand_assertion_to = {}
expand_assertion_to_number = ""- is_transitive = {}
is_transitive_number = ""- is_metadata_tag = {}
is_metadata_tag_number = ""- inverse_of = {}
inverse_of_number = ""- created_by = {}
created_by_number = ""- creation_date = {}
creation_date_number = ""- consider = {}
consider_number = ""- is_a = {}
is_a_list = [] # A field name may have multiple values, so it is stored in the form of a “list”.- synonym = {}
synonym_list = []- newdic = []
f = open(self.path, 'r', encoding="utf-8")
for line in f.readlines():
lable = line.split(":")[0] # Read the list ‘name’, starting from the position of '0', ending with ":", reading all field names- # View the name of the list that was read
- # print(lable)
- # Start to judge
- if lable == "id": # Judge the label for storage
id_number = line[3:].strip() # Remove the label and colon, occupy 3 positions, and strip() is used to remove the trailing spaces.- elif lable == "is_obsolete":
is_obsolete_number = line[12:].strip()- elif lable == "is_class_level":
is_class_level_number = line[15:].strip()- elif lable == "transitive_over":
transitive_over_number = line[16:]- elif lable == "def":
DEF_number = line[5:].strip()- elif lable == "property_value":
property_value_number = line[15:].strip()- elif lable == "namespace":
namespace_number = line[10:].strip()- elif lable == "comment":
comment_number = line[8:].strip()- elif lable == "intersection_of":
intersection_of_number = line[16:].strip()- elif lable == "xref":
xref_number = line[5:].strip()- elif lable == "name":
name_number = line[5:].strip()- elif lable == "disjoint_from":
disjoint_from_number = line[14:].strip()- elif lable == "replaced_by":
replaced_by_number = line[12:].strip()- elif lable == "relationship":
relationship_number = line[13:].strip()- elif lable == "alt_id":
alt_id_number = line[7:].strip()- elif lable == "holds_over_chain":
holds_over_chain_number = line[17:].strip()- elif lable == "subset":
subset_number = line[7:].strip()- elif lable == "expand_assertion_to":
expand_assertion_to_number = line[20:].strip()- elif lable == "is_transitive":
is_transitive_number = line[14:].strip()- elif lable == "is_metadata_tag":
is_metadata_tag_number = line[16:].strip()- elif lable == "inverse_of":
inverse_of_number = line[11:].strip()- elif lable == "created_by":
created_by_number = line[11:].strip()- elif lable == "creation_date":
creation_date_number = line[14:].strip()- elif lable == "consider":
consider_number = line[9:].strip()- elif lable == "is_a":
is_a_list.append(line[5:].strip().split('\n'))- elif lable == "synonym":
synonym_list.append(line[8:].strip().split('\n'))- # Put "[" as the end of the store.
# If you want to "[" as the beginning of your storage, you will have to change the storage format of the data.- elif line[0] == "[":
- # Assign values and store the data in newdic[]
- id["id"] = id_number
newdic.append(id)- is_obsolete["is_obsolete"] = is_obsolete_number
newdic.append(is_obsolete)- is_class_level["is_class_level"] = is_class_level_number
newdic.append(is_class_level)- transitive_over["transitive_over"] = transitive_over_number
newdic.append(transitive_over)- DEF["def"] = DEF_number
newdic.append(DEF)- property_value["property_value"] = property_value_number
newdic.append(property_value)- namespace["namespace"] = namespace_number
newdic.append(namespace)- comment["comment"] = comment_number
newdic.append(comment)- intersection_of["intersection_of"] = intersection_of_number
newdic.append(intersection_of)- xref["xref"] = xref_number
newdic.append(xref)- name["name"] = name_number
newdic.append(name)- disjoint_from["disjoint_from"] = disjoint_from_number
newdic.append(disjoint_from)- replaced_by["replaced_by"] = replaced_by_number
newdic.append(replaced_by)- relationship["relationship"] = relationship_number
newdic.append(relationship)- alt_id["alt_id"] = alt_id_number
newdic.append(alt_id)- holds_over_chain["holds_over_chain"] = holds_over_chain_number
newdic.append(holds_over_chain)- subset["subset"] = subset_number
newdic.append(subset)- expand_assertion_to["expand_assertion_to"] = expand_assertion_to_number
newdic.append(expand_assertion_to)- is_transitive["is_transitive"] = is_transitive_number
newdic.append(is_transitive)- is_metadata_tag["is_metadata_tag"] = is_metadata_tag_number
newdic.append(is_metadata_tag)- inverse_of["inverse_of"] = inverse_of_number
newdic.append(inverse_of)- created_by["created_by"] = created_by_number
newdic.append(created_by)- creation_date["creation_date"] = creation_date_number
newdic.append(creation_date)- consider["consider"] = consider_number
newdic.append(consider)- is_a["is_a"] = is_a_list
newdic.append(is_a)- synonym["synonym"] = synonym_list
newdic.append(synonym)- # Save newdic in the total data set
self.total.append(newdic)- # Initialize all new tags
id = {}
id_number = ""- is_obsolete = {}
is_obsolete_number = ""- is_class_level = {}
is_class_level_number = ""- transitive_over = {}
transitive_over_number = ""- DEF = {}
DEF_number = ""- property_value = {}
property_value_number = ""- namespace = {}
namespace_number = ""- comment = {}
comment_number = ""- intersection_of = {}
intersection_of_number = ""- xref = {}
xref_number = ""- name = {}
name_number = ""- disjoint_from = {}
disjoint_from_number = ""- replaced_by = {}
replaced_by_number = ""- relationship = {}
relationship_number = ""- alt_id = {}
alt_id_number = ""- holds_over_chain = {}
holds_over_chain_number = ""- subset = {}
subset_number = ""- expand_assertion_to = {}
expand_assertion_to_number = ""- is_transitive = {}
is_transitive_number = ""- is_metadata_tag = {}
is_metadata_tag_number = ""- inverse_of = {}
inverse_of_number = ""- created_by = {}
created_by_number = ""- creation_date = {}
creation_date_number = ""- is_a = {}
is_a_list = []- synonym = {}
synonym_list = []- # Initialize newdic
newdic = []- # total.append(newdic)
# self.total.append(newdic) #You append an empty newdic, so there is an empty one behind []- if __name__ == "__main__":
class1 = GeneOntology('go (1).obo')
class1.read_storage_data()
print(class1.total)- jsObj = json.dumps(class1.total)
fileObject = open('jsonFile8.json', 'w')
fileObject.write(jsObj)
fileObject.close()
利用python 数据分析入门,详细教程,教小白快速入门的更多相关文章
- Spring入门详细教程(三)
前言 本篇紧接着spring入门详细教程(二),建议阅读本篇前,先阅读第一篇和第二篇.链接如下: Spring入门详细教程(一) https://www.cnblogs.com/jichi/p/101 ...
- Spring入门详细教程(二)
前言 本篇紧接着spring入门详细教程(一),建议阅读本篇前,先阅读第一篇.链接如下: Spring入门详细教程(一) https://www.cnblogs.com/jichi/p/1016553 ...
- ThinkJS框架入门详细教程(二)新手入门项目
一.准备工作 参考前一篇:ThinkJS框架入门详细教程(一)开发环境 安装thinkJS命令 npm install -g think-cli 监测是否安装成功 thinkjs -v 二.创建项目 ...
- spring入门详细教程(五)
前言 本篇紧接着spring入门详细教程(三),建议阅读本篇前,先阅读第一篇,第二篇以及第三篇.链接如下: Spring入门详细教程(一) https://www.cnblogs.com/jichi/ ...
- Spring入门详细教程(四)
前言 本篇紧接着spring入门详细教程(三),建议阅读本篇前,先阅读第一篇,第二篇以及第三篇.链接如下: Spring入门详细教程(一) https://www.cnblogs.com/jichi/ ...
- 第三个视频作品《小白快速入门greenplum》上线了
1.场景描述 第三个视频作品出炉了,<小白快速入门greenplum>上线了,有需要的朋友可以直接点击链接观看.(如需购买,请通过本文链接购买) 2. 课程内容 课程地址:https:// ...
- JasperReports入门教程(一):快速入门
JasperReports入门教程(一):快速入门 背景 现在公司的项目需要实现一个可以配置的报表,以便快速的适应客户的需求变化.后来在网上查资料发现可以使用JasperReports + Jaspe ...
- 3个月零基础入门Python+数据分析,详细时间表+计划表分享
大家好,我是白云. 今天想给大家分享的是三个月零基础入门数据分析学习计划.有小伙伴可能会说,英语好像有点不太好,要怎么办?所以今天我给大家分享的资源呢就是对国内的小伙伴很友好,还附赠大家一份三个月学 ...
- 利用python数据分析与挖掘相关资料总结
小生今年研二,目前主要从事软件工程数据挖掘与分析.之前一直苦于找不到一个从数据预处理.数据分析.数据可视化和软件建模的统一平台.因此,小生辗转反辙学习了java,R语言,python,scala等等. ...
随机推荐
- Java如何对List集合的操作方法(一)
目录: list中添加,获取,删除元素: list中是否包含某个元素: list中根据索引将元素数值改变(替换): list中查看(判断)元素的索引: 根据元素索引位置进行的判断: 利用list中索引 ...
- Linux内核如何装载和启动一个可执行程序(转)
原文:http://www.cnblogs.com/petede/p/5351696.html 实验七:Linux内核如何装载和启动一个可执行程序 姓名:李冬辉 学号:20133201 注: 原创作品 ...
- tomcat安装apr优化
APR是apache的一个linux操作系统级优化库,可以在tomcat中使用操作系统级native调用大大提高并发处理效率 先安装前置依赖: yum install -y apr-devel ope ...
- weblogic学习教程(一)
一.简介 WebLogic是美国Oracle公司出品的一个application server,确切的说是一个基于JAVAEE架构的中间件,WebLogic是用于开发.集成.部署和管理大型分布式Web ...
- 注意:WordPress栏目别名slug不要设为p
这几天ytkah接了一个WordPress项目,没用多少时间就搞定了,交付给甲方使用,刚开始还算顺利,突然有一天其中一个栏目及栏目下是文章都无法访问了,出现404页面,其他页面都可以.询问他们最近改动 ...
- react native获取屏幕的宽度和高度
var Dimensions = require('Dimensions'); var {width,height} = Dimensions.get("window");//第一 ...
- linux 修改文件内容 vi命令
vi编辑器是所有Unix及Linux系统下标准的编辑器,介绍一下它的用法和一小部分指令.由于对Unix及Linux系统的任何版本,vi编辑器是完全相同的,因此您可以在其他任何介绍vi的地方进一步了解它 ...
- element
<el-table-column label="地址" prop="address"> <template slot-scope=" ...
- vant - 弹框 【Popup 弹出层】【DatetimePicker 时间选择】
[HelloWorld.vue] <template> <div class="hello"> <van-row class="m-head ...
- 万恶之源 - Python装饰器及内置函数
装饰器 听名字应该知道这是一个装饰的东西,我们今天就来讲解一下装饰器,有的铁子们应该听说,有的没有听说过.没有关系我告诉你们这是一个很神奇的东西 这个有多神奇呢? 我们先来复习一下闭包 def fun ...