强化学习---TRPO/DPPO/PPO/PPO2
时间线:
OpenAI 发表的 Trust Region Policy Optimization,
Google DeepMind 看过 OpenAI 关于 TRPO后, 2017年7月7号,抢在 OpenAI 前面 把 Distributed PPO给先发布了.
OpenAI 还是在 2017年7月20号 发表了一份拿得出手的 PPO 论文 。(ppo+ppo2)
Proximal Policy Optimization
PPO是off-policy的方法。
跟环境互动的agent与用来学习得agent 不是同一个agent,可以理解为PPO 是一套 Actor-Critic 结构, Actor 想最大化 J_PPO, Critic 想最小化 L_BL.

利用importance sampling


通过KL散度加一个惩罚,使梯度更新的时候幅度不要太大。
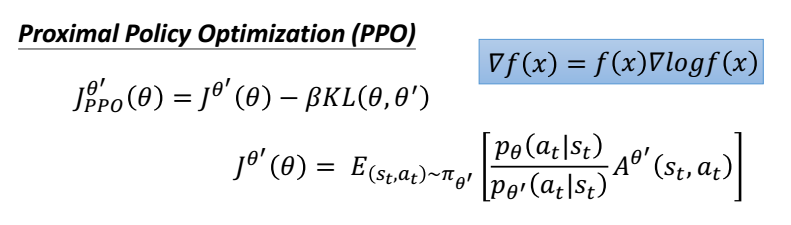
总的来说 PPO 是一套 Actor-Critic 结构, Actor 想最大化 J_PPO, Critic 想最小化 L_BL. Critic 的 loss 好说, 就是减小 TD error. 而 Actor 的就是在 old Policy 上根据 Advantage (TD error) 修改 new Policy, advantage 大的时候, 修改幅度大, 让 new Policy 更可能发生. 而且他们附加了一个 KL Penalty (惩罚项, 不懂的同学搜一下 KL divergence), 简单来说, 如果 new Policy 和 old Policy 差太多, 那 KL divergence 也越大, 我们不希望 new Policy 比 old Policy 差太多, 如果会差太多, 就相当于用了一个大的 Learning rate, 这样是不好的, 难收敛.

Trust Region Policy Optimization
ppo是吧惩罚项放在了目标函数中,而TRPO 是以 constrain的形式。不好求解。

PPO2
看图,横坐标是 ,当A>0时候,奖励是正的,更新的幅度越大越好,但是为了
,当A>0时候,奖励是正的,更新的幅度越大越好,但是为了
加入惩罚,所以更新的幅度在横坐标大于 时候,就不增加同一个幅度,所以是一条横线,不会无限制增大。
时候,就不增加同一个幅度,所以是一条横线,不会无限制增大。
同理,当A<0时候,横坐标是更新的幅度,因为奖励是负数,正常应该 更新是越小越好,但是不能无限小啊,所以假如
惩罚就是不能无限小。

Distributed Proximal Policy Optimization
摘自:https://morvanzhou.github.io/tutorials/machine-learning/reinforcement-learning/6-4-DPPO/
Google DeepMind 提出来了一套和 A3C 类似的并行 PPO 算法. paper
取而代之, 我觉得如果采用 OpenAI 的思路, 用他那个 “简陋” 伪代码, 但是弄成并行计算倒是好弄点. 所以我就结合了 DeepMind 和 OpenAI, 取他们的精华, 写下了这份 DPPO 的代码.
总结一下我是怎么写的.
- 用 OpenAI 提出的
Clipped Surrogate Objective - 使用多个线程 (workers) 平行在不同的环境中收集数据
- workers 共享一个 Global PPO
- workers 不会自己算 PPO 的 gradients, 不会像 A3C 那样推送 Gradients 给 Global net
- workers 只推送自己采集的数据给 Global PPO
- Global PPO 拿到多个 workers 一定批量的数据后进行更新 (更新时 worker 停止采集)
- 更新完后, workers 用最新的 Policy 采集数据
强化学习---TRPO/DPPO/PPO/PPO2的更多相关文章
- 深度学习-深度强化学习(DRL)-Policy Gradient与PPO笔记
Policy Gradient 初始学习李宏毅讲的强化学习,听台湾的口音真是费了九牛二虎之力,后来看到有热心博客整理的很细致,于是转载来看,当作笔记留待复习用,原文链接在文末.看完笔记再去听一听李宏毅 ...
- 深度学习课程笔记(十四)深度强化学习 --- Proximal Policy Optimization (PPO)
深度学习课程笔记(十四)深度强化学习 --- Proximal Policy Optimization (PPO) 2018-07-17 16:54:51 Reference: https://b ...
- Ubuntu下常用强化学习实验环境搭建(MuJoCo, OpenAI Gym, rllab, DeepMind Lab, TORCS, PySC2)
http://lib.csdn.net/article/aimachinelearning/68113 原文地址:http://blog.csdn.net/jinzhuojun/article/det ...
- (转) 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文)
本文转自:http://mp.weixin.qq.com/s/aAHbybdbs_GtY8OyU6h5WA 专题 | 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文) 原创 201 ...
- DRL强化学习:
IT博客网 热点推荐 推荐博客 编程语言 数据库 前端 IT博客网 > 域名隐私保护 免费 DRL前沿之:Hierarchical Deep Reinforcement Learning 来源: ...
- ReLeQ:一种自动强化学习的神经网络深度量化方法
ReLeQ:一种自动强化学习的神经网络深度量化方法 ReLeQ:一种自动强化学习的神经网络深度量化方法ReLeQ: An Automatic Reinforcement Learning Ap ...
- 深度强化学习(Deep Reinforcement Learning)入门:RL base & DQN-DDPG-A3C introduction
转自https://zhuanlan.zhihu.com/p/25239682 过去的一段时间在深度强化学习领域投入了不少精力,工作中也在应用DRL解决业务问题.子曰:温故而知新,在进一步深入研究和应 ...
- [强化学习]Part1:强化学习初印象
引入 智能 人工智能 强化学习初印象 强化学习的相关资料 经典书籍推荐:<Reinforcement Learning:An Introduction(强化学习导论)>(强化学习教父Ric ...
- 李宏毅强化学习完整笔记!开源项目《LeeDeepRL-Notes》发布
Datawhale开源 核心贡献者:王琦.杨逸远.江季 提起李宏毅老师,熟悉强化学习的读者朋友一定不会陌生.很多人选择的强化学习入门学习材料都是李宏毅老师的台大公开课视频. 现在,强化学习爱好者有更完 ...
随机推荐
- [development][libhtp] libhtp 启用debug模式
可以使用 ./configure --help 查看帮助. 可以通过参数, 修改配置. 即对应的Makefile内容. 也可以修改 configure.ac 里的内容, help中的部分内容, 也依赖 ...
- DBGridEh使用指南改变边框颜色
DBGridEh使用指南 鹅倌0人评论422人阅读2012-08-06 15:17:59 1.设置表头,是否允许多表头,设置是否只读. dbgrdh1.TitleFont.Color:=clBlu ...
- 《Redis 主从复制》
万念俱灰,说的就是我现在的心情...... 周六下午写了一下午的读书笔记,由于我的 MAC 有点问题,重启了一下...... 灰飞烟灭...... 读 第八章<集群> 总结 1:如何开启主 ...
- Appium入门(5)__ Appium测试用例(1)
步骤为:启动AVD.启动Appium.写用例(python).执行 一.启动Android模拟器 二.启动Appium Server 双击appium图标启动,配置 ...
- idea+maven+springboot+mybatis+springmvc+shiro
springboot就是把创建项目简单化,省去了以往的配置mybatis.springmvc的繁琐过程. 搭建web应用三个主要功能,请求和响应,数据库交互,权限配置. 一.idea创建项目 (1) ...
- idea的基本使用
对于Idea没有workspace的概念,但是它把每个项目都看成是maven的一个模块,在一个idea窗口要想显示多个项目时就和eclipse不太一样,下面会详细介绍. 另外maven的setting ...
- javascript与XML
曾几何时,XML一度成为存储和通过因特网传输结构化数据的标准,之前,浏览器无法解析XML数据时,开发人员都要手动编写自己的XML解析器.而自从DOM出现后,所有浏览器都内置了对XML的原生支持(XML ...
- sdram 裸机程序
硬件平台 :JZ2440 实现功能:将led闪烁代码从2440的2k sram中拷贝到sdram start.s --> 上电初始化,拷贝代码 sdram.c --> ...
- 在Windows Server 2008 R2 Server中,上传视频遇到的问题(一)
在Windows 2008 R2 Server中,上传视频不能播放,以及服务器大小限制问题,这里记录我的解决方法,以免再次遇到,无所适从. 1.上传视频不能播放 打开IIS,找到“MIME类型”,如下 ...
- zabbix agentd安装
一.Linux客户端1.创建zabbix用户 groupadd zabbix useradd -g zabbix -M -s /sbin/nologin zabbix 2.解压agent包 zabbi ...