Hadoop 2.7.3 完全分布式维护-动态增加datanode篇
原有环境
http://www.cnblogs.com/ilifeilong/p/7406944.html
| IP | host | JDK | linux | hadop | role |
| 172.16.101.55 | sht-sgmhadoopnn-01 | 1.8.0_111 | CentOS release 6.5 | hadoop-2.7.3 | NameNode,SecondaryNameNode,ResourceManager |
| 172.16.101.58 | sht-sgmhadoopdn-01 | 1.8.0_111 | CentOS release 6.5 | hadoop-2.7.3 | DataNode,NodeManager |
| 172.16.101.59 | sht-sgmhadoopdn-02 | 1.8.0_111 | CentOS release 6.5 | hadoop-2.7.3 | DataNode,NodeManager |
| 172.16.101.60 | sht-sgmhadoopdn-03 | 1.8.0_111 | CentOS release 6.5 | hadoop-2.7.3 | DataNode,NodeManager |
| 172.16.101.66 | sht-sgmhadoopdn-04 | 1.8.0_111 | CentOS release 6.5 | hadoop-2.7.3 | DataNode,NodeManager |
现计划向集群新增一台datanode,如表格所示
1. 配置系统环境
主机名,ssh互信,环境变量等
2. 修改namenode节点的slave文件,增加新节点信息
$ cat slaves
sht-sgmhadoopdn-
sht-sgmhadoopdn-
sht-sgmhadoopdn-
sht-sgmhadoopdn-
3. 在namenode节点上,将hadoop-2.7.3复制到新节点上,并在新节点上删除data和logs目录中的文件
$ hostname
sht-sgmhadoopnn-
$ rsync -az --progress /usr/local/hadoop-2.7./* hduser@sht-sgmhadoopdn-04:/usr/local/hadoop-2.7.3/ $ hostname
sht-sgmhadoopdn-04
$ rm -rf /usr/local/hadoop-2.7.3/logs/*
$ rm -rf /usr/local/hadoop-2.7.3/data/*
4. 启动新datanode的datanode进程
$ hadoop-daemon.sh start datanode
starting datanode, logging to /usr/local/hadoop-2.7./logs/hadoop-hduser-datanode-sht-sgmhadoopdn-.out
$ jps
Jps
DataNode
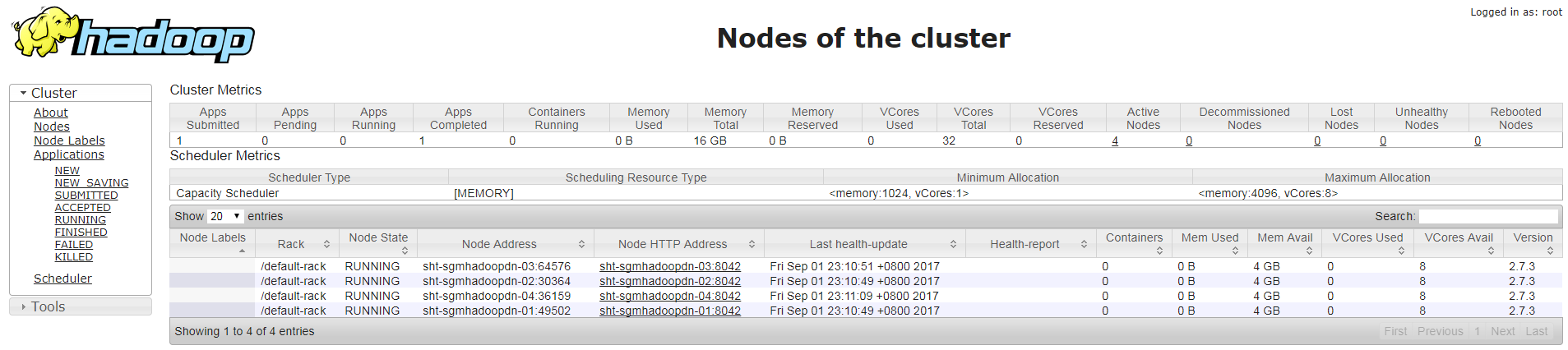
5. 在namenode查看当前集群情况,确认信节点已经正常加入
5.1 以命令行方式
$ hdfs dfsadmin -report
Configured Capacity: (282.49 GB)
Present Capacity: (77.98 GB)
DFS Remaining: (77.38 GB)
DFS Used: (618.02 MB)
DFS Used%: 0.77%
Under replicated blocks:
Blocks with corrupt replicas:
Missing blocks:
Missing blocks (with replication factor ): -------------------------------------------------
Live datanodes (): Name: 172.16.101.66: (sht-sgmhadoopdn-)
Hostname: sht-sgmhadoopdn-
Decommission Status : Normal
Configured Capacity: (70.62 GB)
DFS Used: ( KB)
Non DFS Used: (33.13 GB)
DFS Remaining: (37.49 GB)
DFS Used%: 0.00%
DFS Remaining%: 53.09%
Configured Cache Capacity: ( B)
Cache Used: ( B)
Cache Remaining: ( B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers:
Last contact: Fri Sep :: CST Name: 172.16.101.60: (sht-sgmhadoopdn-)
Hostname: sht-sgmhadoopdn-
Decommission Status : Normal
Configured Capacity: (70.62 GB)
DFS Used: ( MB)
Non DFS Used: (57.48 GB)
DFS Remaining: (12.95 GB)
DFS Used%: 0.28%
DFS Remaining%: 18.33%
Configured Cache Capacity: ( B)
Cache Used: ( B)
Cache Remaining: ( B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers:
Last contact: Fri Sep :: CST Name: 172.16.101.59: (sht-sgmhadoopdn-)
Hostname: sht-sgmhadoopdn-
Decommission Status : Normal
Configured Capacity: (70.62 GB)
DFS Used: ( MB)
Non DFS Used: (57.80 GB)
DFS Remaining: (12.63 GB)
DFS Used%: 0.28%
DFS Remaining%: 17.88%
Configured Cache Capacity: ( B)
Cache Used: ( B)
Cache Remaining: ( B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers:
Last contact: Fri Sep :: CST Name: 172.16.101.58: (sht-sgmhadoopdn-)
Hostname: sht-sgmhadoopdn-
Decommission Status : Normal
Configured Capacity: (70.62 GB)
DFS Used: ( MB)
Non DFS Used: (56.11 GB)
DFS Remaining: (14.31 GB)
DFS Used%: 0.28%
DFS Remaining%: 20.26%
Configured Cache Capacity: ( B)
Cache Used: ( B)
Cache Remaining: ( B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers:
Last contact: Fri Sep :: CST
5.2 以web方式

6. 在namenoe上设置 hdfs 的负载均衡
$ hdfs dfsadmin -setBalancerBandwidth
Balancer bandwidth is set to
$ start-balancer.sh -threshold
starting balancer, logging to /usr/local/hadoop-2.7./logs/hadoop-hduser-balancer-sht-sgmhadoopnn-.out
7. 查看hdfs负载信息(有时候节点数据量较小,看出来数据量变化,可以上传大文件测试)

8. 启动新节点的nodemanager进程
$ yarn-daemon.sh start nodemanager
starting nodemanager, logging to /usr/local/hadoop-2.7./logs/yarn-hduser-nodemanager-sht-sgmhadoopdn-.out
$ jps
NodeManager
Jps
DataNode
Hadoop 2.7.3 完全分布式维护-动态增加datanode篇的更多相关文章
- Hadoop 2.7.3 完全分布式维护-简单测试篇
1. 测试MapReduce Job 1.1 上传文件到hdfs文件系统 $ jps Jps SecondaryNameNode JobHistoryServer NameNode ResourceM ...
- Hadoop 2.7.3 完全分布式维护-部署篇
测试环境如下 IP host JDK linux hadop role 172.16.101.55 sht-sgmhadoopnn-01 1.8.0_111 CentOS release ...
- Hadoop 2.6.3动态增加/删除DataNode节点
假设集群操作系统均为:CentOS 6.7 x64 Hadoop版本为:2.6.3 一.动态增加DataNode 1.准备新的DataNode节点机器,配置SSH互信,可以直接复制已有DataNode ...
- 安装部署Apache Hadoop (本地模式和伪分布式)
本节内容: Hadoop版本 安装部署Hadoop 一.Hadoop版本 1. Hadoop版本种类 目前Hadoop发行版非常多,有华为发行版.Intel发行版.Cloudera发行版(CDH)等, ...
- Hadoop、Zookeeper、Hbase分布式安装教程
参考: Hadoop安装教程_伪分布式配置_CentOS6.4/Hadoop2.6.0 Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS ZooKeeper-3.3 ...
- Hadoop 在windows 上伪分布式的安装过程
第一部分:Hadoop 在windows 上伪分布式的安装过程 安装JDK 1.下载JDK http://www.oracle.com/technetwork/java/javaee/d ...
- centos中-hadoop单机安装及伪分布式运行实例
创建用户并加入授权 1,创建hadoop用户 sudo useradd -m hadoop -s /bin/bash 2,修改sudo的配置文件,位于/etc/sudoers,需要root权限才可以读 ...
- Apache Hadoop 2.9.2 完全分布式部署
Apache Hadoop 2.9.2 完全分布式部署(HDFS) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.环境准备 1>.操作平台 [root@node101.y ...
- centos6.8系统安装 Hadoop 2.7.3伪分布式集群
安装 Hadoop 2.7.3 配置ssh免密码登陆 cd ~/.ssh # 若没有该目录,请先执行一次ssh localhost ssh-keygen - ...
随机推荐
- 良品铺子:“新零售”先锋的IT必经之路
良品铺子:“新零售”先锋的IT必经之路 云计算 大数据 CIO班 CIO 互联网+ 物联网 电子政务 2017-12-29 09:25:34 来源:互联网抢沙发 摘要:2017年被称为“新零售”元年 ...
- 完美解决百度网盘、浏览器下载限速问题proxyee-down(附带win破解版云盘)
win版破解云盘 下载: <PanDownload> 使用文档: <PanDownload使用> Mac方法 限速.限速! 平时下载东西限速倒无所谓,遇到急一点的.盯着80km ...
- 【转】构造自己的DIB类
ZC: 搜索"DIB_HEADER_MARKER"时,看到的这个文章 http://blog.csdn.net/yyyuhan/article/details/2026652 ...
- Android SDK开发
目前我们的应用内使用了 ArcFace 的人脸检测功能,其他的我们并不了解,所以这里就和大家分享一下我们的集成过程和一些使用心得 集成 ArcFace FD 的集成过程非常简单 在 ArcFace F ...
- variable_scope
1. with tf.variable_scope("a"): b=tf.get_variable(name="g",initializer=12) print ...
- Cocos Creator 智能提示 for WebStorm
0.首先下载安装Node.js,否则下面将找不到关于Node.js的设置选项. 1.智能提示设置File->Settings ①设置为最新的ECMAScript版本 ②Enable Node.j ...
- Semana i 2018
Semana i 2018 A Giga-Kilo-Gigabyte 思路: dp水题 代码: #pragma GCC optimize(2) #pragma GCC optimize(3) #pra ...
- java 数据导入xls
@RequestMapping("admin/doorDesign/getexcel.do") public void getExcel(String name,String ph ...
- 响应式图片 (responsive image)
更新 : 2019-02-21 除了写 srcset sizes 还有一种 x1, x2, x3, x4 的写法. 我们对比一下 假设 pc 希望是 1000w mobile 希望是 300w siz ...
- 质控工具之cutadapt的使用方法
cutadapt 参考:用cutadapt软件来对双端测序数据去除接头 fastqc可以用于检测,检测出来了怎么办? 看了几篇高水平文章,有不少再用cutadapt,虽然有时候数据真的不错,但是还是要 ...