Centos7中hadoop配置
Centos7中hadoop配置
1.下载centos7安装教程:
http://jingyan.baidu.com/article/a3aad71aa180e7b1fa009676.html
(注意,到如下图这一步的时候,要注意,选择图形界面安装,并且勾选如图2两个选项,才会有自带的浏览器。)


2.修改主机名
2.1CentOS7以下的版本修改主机名的方法
CentOS7以下的系统(包括CentOS6~CentOS6.5),我们通过修改HOSTNAME的方式即可得到想要的效果。如下所示,localhost是当前主机名,将其修改成了cjh141304092
|
[root@localhost ~]# vim /etc/sysconfig/network 1 # Created by anaconda 2 NETWORKING_IPV6=no 3 PEERNTP=no 4 GATEWAY=115.29.207.247 5 HOSTNAME=typecodes [root@localhost ~]# hostname cjh141304092 [root@cjh141304092 ~]# |
2 .2CentOS7以及CentOS7.1版本修改主机名的方法
目前CentOS的最高版本是CentOS7.1,有较多CentOS6系列能使用的命令都不能使用或者做了有些改动。例如,在CentOS7或者CentOS7.1系统中,直接使用上面的方法修改主机名,最后都是没有效果的。它已经被简化为下面这条命令:
|
[root@localhost ~]# hostnamectl set-hostname cjh141304092 [root@cjh141304092 ~]# |
此方法无需重启直接生效。如果没有,关掉终端然后在打开即可。
2.3域名映射
进入root模式,然后用命令:vi /etc/hosts修改域名映射地址。
如:192.168.0.53是主机cmaster的ip地址,那么就要在hosts文件中添加,格式为:
ip地址(空格隔开)主机名
|
192.168.0.53 cmster |
然后保存并退出,注意,每台子节点的主机都要配置主节点的域名映射
3关闭防火墙
在root权限下执行以下两条指令,关闭防火墙并阻止其开机启动。
systemctl stop firewalld.service#停止firewall
systemctl disable firewalld.service#禁止firewall开机启动

4.安装jdk
将之前下载好的jdk复制到虚拟机中的/home/hadoop/目录下,(也就是用户根目录下)
使用命令rpm –ivh /home/joe/jdk-8u101-linux-x64.rpm解压安装
安装完成后使用javac命令测试jdk是否安装成功,如果出现了如下图提示,说明安装jdk成功。(jdk可以在windows下下载好后用u盘传入到虚拟机中,然后执行安装)
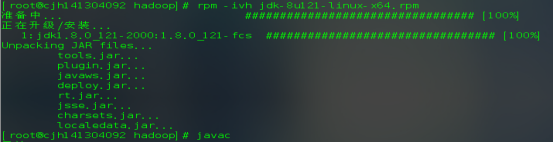
验证:

5.ssh免密登录
|
exit # 退出刚才的 ssh localhost cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost ssh-keygen -t rsa # 会有提示,都按回车就可以 cat ./id_rsa.pub >> ./authorized_keys # 加入授权 |
ssh-keygen -t rsa生成注册码,然后根目录下就会产生一个.ssh文件,用ls -a命令可查看。


将.ssh目录下生成的id_rsa.pub文件最追加生产到authorized_keys文件中。(此文件原来没有,执行命令后会自动生成,如下图)

验证是否可以免密登录:出现如下情况则表示成功

以上步骤只是允许本机免密登录。但是要从另外一台机器上登录的话,还需要将另外台机器的id_rsa.pub公钥发送到要登录的那台机器上。例如A机器要ssh免密登录B机器的话,就要将上述生成的A本机器的id_rsa.pub公钥,发送到B机器用户根目录下。
用命令:scp ~/.ssh/id_rsa.pub hadoop@192.168.0.53:~/

命令格式如下:
|
scp 要发送的文件路径 目的机用户名@目的主机名(或者主机ip地址):目的机存放路径 |
发送成功后会发现目的主机用户目录下就会出现相应文件,如下图。

然后用cat ~/id_rsa.pub >> ~/.ssh/authorized_keys命令将文件追加到authorized_keys文件的内容后面。文件内容如下:
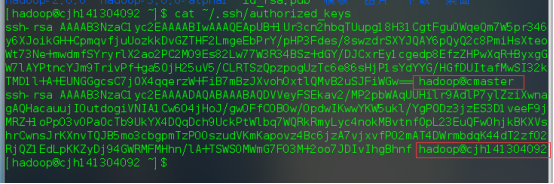
authorized_keys内容变成这样表示成功了。
然后用同样的步骤,将B机器的id_rsa.pub公钥传到A机器上。如果有三台机器,要互相访问的话,那么三台机器两两要配置,然后每台机器都执行以下命令,修改authorized_keys权限,这很重要,如果出现奇怪的错误表示,权限问题。

chmod 700 ~/.ssh
公钥复制完成后,将目的每台机器的sshd_config文件做如下配置:

进入root权限才能修改:做如下修改:只需找到这三句话,然后将前面的#号去掉即可。然后保存退出。
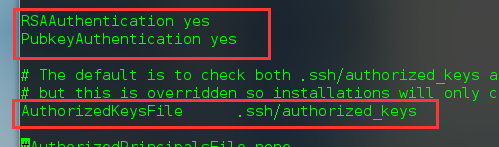
然后用exit退出root用户,用普通用户重启ssh服务,尝试ssh localhost登录,没让输入密码即表示成功了:

在另外一台机器上尝试登录,无需密码直接登录则表示成功了。

6.解压hadoop并做配置
将下载好的 hadoop-3.0.0-alpha1.tar.gz,放到/home/hadoop目录下,然后用tar -zxvf hadoop-3.0.0-alpha1.tar.gz命令解压到当前目录下。(下载的时候注意不要下载成hadoop-3.0.0-alpha1.src.tar.gz这个是资源文件并不是我们要的配置文件压缩包)
下载链接:
解压:

解压完成后出现如下目录

我们需要配置的文件如下:
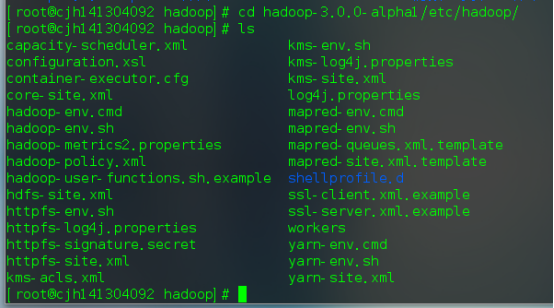
6.1hadoop文件配置
这是配置的主节点,其余子节点的配置要和主节点配置一模一样,否则可能会出现主节点启动了所有子节点的datanode,但是在浏览器查看节点信息的时候只有主节点一个,其余节点启动了却看不到信息。所以只要把这些配置文件复制到每个子节点即可。
6.1.1.配置hadoop-env.sh
原来前面有#号,将#号注释去掉,可以通过图形界面编辑,也可以通过vi编辑器编辑。

6.1.2.配置core-site.xml文件
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hdfs/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cjh141304092:9000</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://cjh141304092:9000</value>
</property>
<property>
<name>hadoop.native.lib</name>
<value>true</value>
<description>Should native hadoop libraries, if present, be used.</description>
</property>
</configuration>
6.1.3.配置hdfs-site.xml文件
<configuration>
<property>
<name>dfs.http.address</name>
<value>cjh141304092:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>cjh141304092:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hdfs/data</value>
</property>
</configuration>
6.1.4.配置mapred-site.xml
文件中没有mapred.xml文件,所以将mapred-site.xml.template重命名成mapred-site.xml,
编辑etc/hadoop/mapred-site.xml:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>cjh141304092:9001</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>cjh141304092:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>cjh141304092:19888</value>
</property>
</configuration>
6.1.5.配置yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>cjh141304092:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>cjh141304092:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>cjh141304092:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>cjh141304092:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>cjh141304092:8033</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>cjh141304092</value>
</property>
</configuration>
6.2配置hadoop环境变量
|
etc/profile: 此文件为系统的每个用户设置环境信息。当用户登录时,该文件被执行一次,并从 /etc/profile.d 目录的配置文件中搜集shell 的设置。一般用于设置所有用户使用的全局变量。 /etc/bashrc: 当 bash shell 被打开时,该文件被读取。也就是说,每次新打开一个终端 shell,该文件就会被读取。 接着是与上述两个文件对应,但只对单个用户生效: ~/.bash_profile 或 ~/.profile: 只对单个用户生效,当用户登录时该文件仅执行一次。用户可使用该文件添加自己使用的 shell 变量信息。另外在不同的LINUX操作系统下,这个文件可能是不同的,可能是 ~/.bash_profile, ~/.bash_login 或 ~/.profile 其中的一种或几种,如果存在几种的话,那么执行的顺序便是:~/.bash_profile、 ~/.bash_login、 ~/.profile。比如 Ubuntu 系统一般是 ~/.profile 文件。 ~/.bashrc: 只对单个用户生效,当登录以及每次打开新的 shell 时,该文件被读取。 此外,修改 /etc/environment 这个文件也能实现环境变量的设置。/etc/environment 设置的也是全局变量,从文件本身的作用上来说, /etc/environment 设置的是整个系统的环境,而/etc/profile是设置所有用户的环境。有几点需注意: 系统先读取 etc/profile 再读取 /etc/environment(还是反过来?) /etc/environment 中不能包含命令,即直接通过 VAR="..." 的方式设置,不使用 export 。 使用 source /etc/environment 可以使变量设置在当前窗口立即生效,需注销/重启之后,才能对每个新终端窗口都生效。 |
通过以下两条命令在系统中添加环境变量:其中HADOOP_HOME的路径为hadoop解压文件目录路径。
[root@cjh1413040 hadoop]# export HADOOP_HOME=/home/hadoop/hadoop-3.0.0-alpha1
[root@cjh1413040 hadoop]# export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
[root@cjh141304092 hadoop]# . /etc/profile #使环境变量立即生效。
操作如下图:

红框中的是验证hadoop是否安装成功,当出现如上信息的时候就是成功了。
注意:
以上两条环境变量的语句如果是以命令的形式执行的话,环境变量的有效期是有限的,当命令终端关闭之后,有效期结束,下次还得继续配置,为了永久有效,我们就要将其写入/etc/profile文件中和~/.bashrc文件中。如下图:

因为这个文件需要root权限才能更改所以我们切换到root模式去修改文件。

|
进入vi编辑界面,按i开始输入,输入完成后按esc键,然后输入“:wq”保存并退出,输入的“:wq”在界面左下角。 |

当写入~/.bashrc的时候要在hadoop用户模式下,因为这个文件是只有用户才能读取的。每个用户独立
6.3hdfs格式化
通过命令:hdfs namenode -format
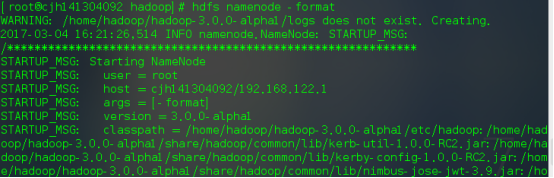
当出现如下successfully formatted表示格式化成功了

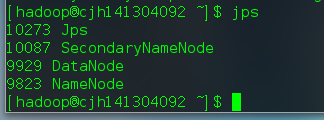
6.4启动start-dfs.sh

用jps查看启动的任务如下:
6.5启动start-yarn.sh

start-yarn.sh又启动了两个任务节点,然后用jps查看
6.6浏览器验证
当成功启动以上的任务之后,就能打开如下网页了,
路径格式为:http://主机名:8080


这是第二个网页,端口号为50070
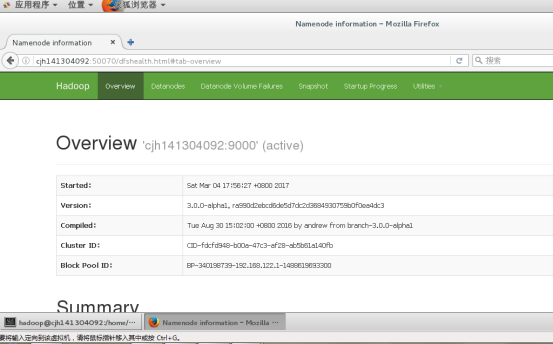
50070可以看到HDFS的相关信息,8088可以看到Yarn的相关信息。
至此。hadoop环境搭建完成。其余节点配置一样。
7.测试案例:wordcount
7.1创建数据源文件
我们在hadoop-2.6.0根目录下创建一个file文件,然后在文件中写入任意内容:我在此处新建了两个:

7.2将文件上传到hdfs.
首先创建input文件夹,

将刚才的两个mytest文件上传到input文件夹中,然后查看是否上传成功

要查看hdfs文件也可登录50070的网页查看:

7.3运行hadoop自带的example示例:

命令格式为:
hadoop jar 要执行的jar包 要执行的函数 数据文件目录 输出结果目录
执行进度可以在8088页面查看:

查看统计结果:

8.windows向linux发送文件
PuTTY小巧方便。但若需要向网络中的Linux系统上传文件,则可以使用PuTTY官方提供的PSCP工具来实现上传。PSCP基于ssh协议实现,其用法与SCP命令非常类似。
下载pscp后运行:

也可以将他添加到环境变量中,
然后向linux服务器上传文件:

命令格式为:
pscp 本地文件路径 目的主机用户@目的主机ip或者主机名(有做域名映射的话主机名才有效) :要存放的目录
Centos7中hadoop配置的更多相关文章
- CentOS7中DHCP配置
因为需要网络引导系统的安装,所以需要安装和配置DHCP服务器.DHCP(Dynamic Host Configuration Protocol) 动态主机配置协议,它提供了一种动态指定IP地址和配置参 ...
- Windows环境中Hadoop配置
我们之前已经在Windows中安装好了Hadoop,并且配置了环境变量.如果要在本地上运行的,还需要这两个文件,可以去找一下,放到Hadoop的bin目录下面.这样我们写好的mr程序就可以直接在Win ...
- CentOS7中yum配置
1.打开centos的yum文件夹 输入命令cd /etc/yum.repos.d/ 2.用wget下载repo文件 输入命令wget http://mirrors.aliyun.com/repo ...
- CentOS7 中防火墙配置
systemctl stop firewalld.service #停止firewall systemctl disable firewalld.service #禁止firewall开机启动 开 ...
- Centos7中网络及设备相关配置
centos7中,不再赞成使用ifconfig工具,取而代之的是nmcli工具,服务管理也是以systemctl工具取代了service,这些之前版本的工具虽然在centos7中还可以继续使用,只是出 ...
- CentOS7中使用阿里云镜像
之前因为下载Docker镜像很慢所以用了一家国内的镜像DaoCloud,今天要用的是阿里云的镜像库. 首先要开通了阿里云开发者帐号,地址 : https://dev.aliyun.com/search ...
- Hadoop在eclipse中的配置
在安装完linux下的hadoop框架,实现完所现有的wordCount程序,能够完美输出结果之后,我们开始来搭建在window下的eclipse的环境,进行相关程序的编写. 在网上有很多未编译版本, ...
- Hadoop(一)Centos7虚拟机网络配置
Centos7虚拟机网络配置(桥接模式) 一 VirtualBox提供了三种工作模式,它们是bridged(桥接模式).NAT(网络地址转换模式)和host-only(主机模式). 1 桥接模式(br ...
- centos7中安装、配置、验证、卸载redis
本文介绍在centos7中安装.配置.验证.卸载redis等操作,以及在使用redis中的一些注意事项. 一 安装redis 1 创建redis的安装目录 利用以下命令,切换到/usr/local路径 ...
随机推荐
- C控制语句:分支和跳转
小技巧:程序return前加个getchar();可以让程序停住.%%可以打印使printf()中打印出%号 #include<stdio.h>#define SPACE ''int ma ...
- phpstorm及webstorm密钥
选用 server 方式,输入地址:http://idea.iteblog.com/key.php http://idea.lanyus.com/
- Java中的volatile的作用和synchronized作用
volatile该关键字是主要使用的场合是字啊多个线程中可以感知实例的变量被更改了并且可以获取到最新的值进行使用,也就是用多线程读取共享变量的时候可以获取到最新的值使用.不能保障原子性 如果你在jvm ...
- JAVA浮点数计算精度损失底层原理与解决方案
浮点数会有精度损失这个在上大学的时候就已经被告知,但是至今完全没有想明白其中的原由,老师讲的时候也是一笔带过的,自己也没有好好琢磨.终于在工作的时候碰到了,于是google了一番. 问题: 对两个do ...
- UVA - 1371 Period 二分+dp
思路:设字符串x的长度为n,y的长度为m,那么答案一定在[0, m]之间,那么可以二分求答案. d(i, j)表示第一个串前i个字符至少需要经过多少次才能的到第二个串的前j个字符,转移方程d(i, j ...
- Spring 代理对象,cglib,jdk的问题思考,AOP 配置注解拦截 的一些问题.为什么不要注解在接口,以及抽象方法.
可以被继承 首先注解在类上是可以被继承的 在注解上用@Inherited /** * Created by laizhenwei on 17:49 2017-10-14 */ @Target({Ele ...
- Linux中文件夹的文件按照时间倒序或者升序排列
1.按照时间升序 命令:ls -lrt 详细解释: -l use a long listing format 以长列表方式显示(详细信息方式) -t sort by modification time ...
- nginx新的站点的配置
每一次配置新的站点的时候,要记得重新启动nginx: sudo -s; nginx -s reload; 配置文件,有涉及到 每一个站点都有一个.conf文件. 域名重定向:Gas Mask的软件的使 ...
- HashMap并发导致死循环 CurrentHashMap
为何出现死循环简要说明 HashMap闭环的详细原因 cocurrentHashMap的底层机制 为何出现死循环简要说明 HashMap是非线程安全的,在并发场景中如果不保持足够的同步,就有可能在执行 ...
- SSE推送数据
SSE(Server-Sent Event,服务端推送事件)是一种允许服务端向客户端推送新数据的HTML5技术.与由客户端每隔几秒从服务端轮询拉取新数据相比,这是一种更优的解决方案. WebSocke ...