python接口自动化(二十二)--unittest执行顺序隐藏的坑(详解)
简介
大多数的初学者在使用 unittest 框架时候,不清楚用例的执行顺序到底是怎样的。对测试类里面的类和方法分不清楚,不知道什么时候执行,什么时候不执行。虽然或许通过代码实现了,也是稀里糊涂的一知半解,这样还好,好歹自己鼓
捣出了,但是时间和效率并不是很高,下次遇到还是老样子。那么本篇通过最简单案例来给给为小伙伴详细讲解、演示一下 unittest 执行顺序。
实例代码
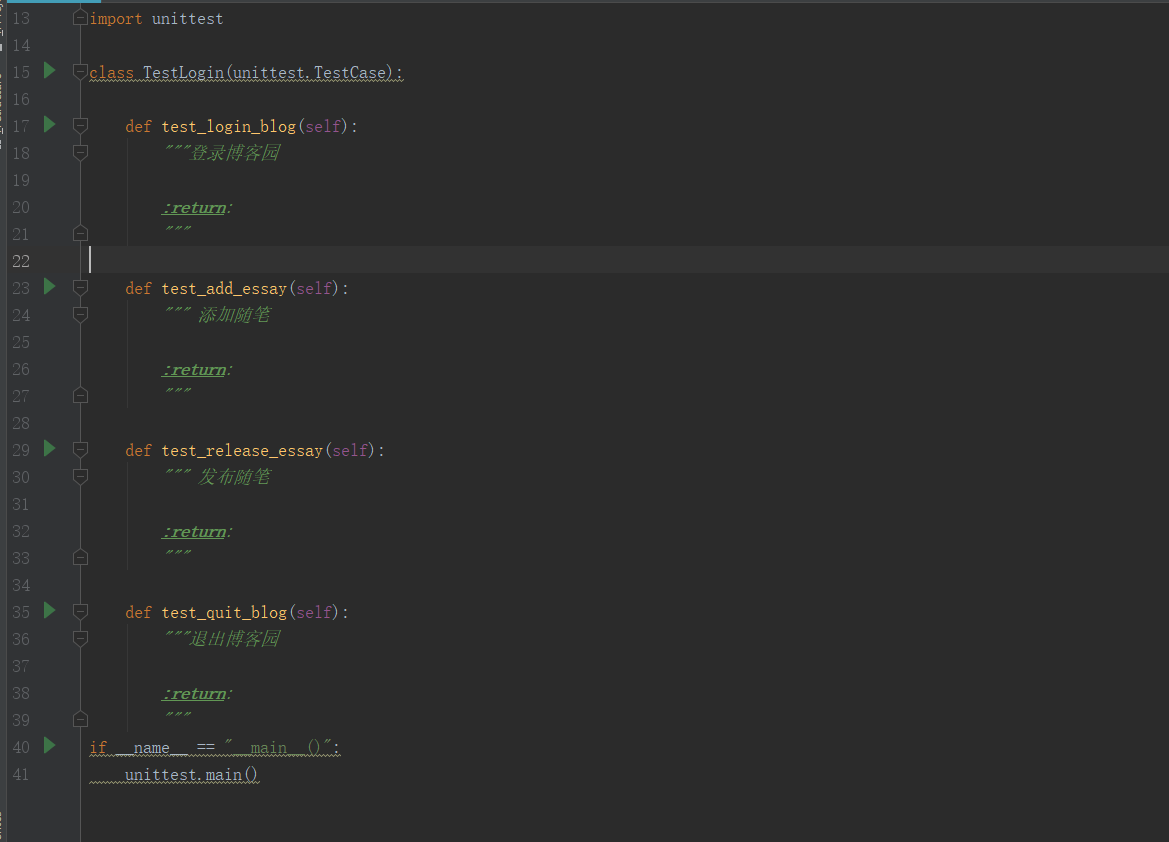
参考代码
# coding=utf-
#.先设置编码,utf-8可支持中英文,如上,一般放在第一行 #.注释:包括记录创建时间,创建人,项目名称。
'''
Created on --
@author: 北京-宏哥
Project:学习和使用unittest框架编写测试用例执行顺序
'''
#.导入unittest模块
import unittest
#.执行顺序和运行测试
import unittest class TestLogin(unittest.TestCase): def test_login_blog(self):
"""登录博客园 :return:
""" def test_add_essay(self):
""" 添加随笔 :return:
""" def test_release_essay(self):
""" 发布随笔 :return:
""" def test_quit_blog(self):
"""退出博客园 :return:
"""
if __name__ == "__main__()":
unittest.main()
这是一个标准的使用unittest进行测试的例子,写完后心里美滋滋,嗯,就按照一贯思路代码会按照这个顺序测就可以了。结果一运行。就傻眼了
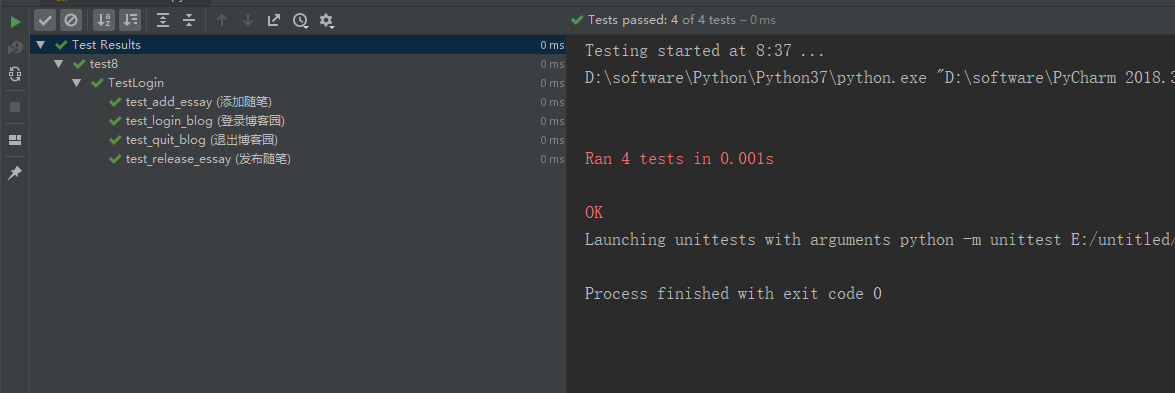
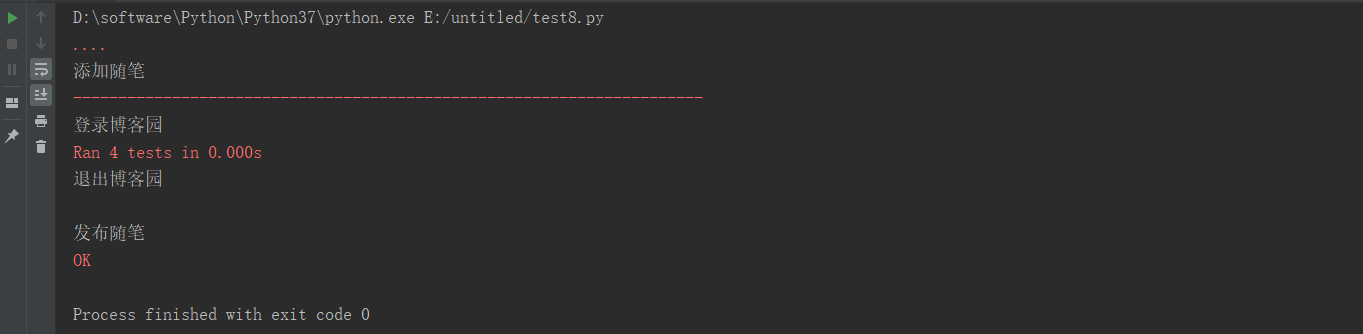
这时候自己心里犯嘀咕,这是什么鬼,怎么回事呢。执行的顺序乱了。第一个执行的测试用例并不是登录博客园,而是添加随笔,此时用户还没登录博客园,进行添加随笔的话会直接报错,导致用例失败。
到这里有些小伙伴可能会说,为什么要让测试用例之间有所依赖呢?
的确,如果完全没依赖,测试用例的执行顺序是不需要关注的。但是这样对于用例的设计和实现,要求就高了许多。而对博客园来说,一个系统内的操作,是有很大的关联性的。以添加随笔为例,随笔内的每个操作都有一个前提,你需要
登录博客园才能添加随笔。所以要实现用例之间的完全解耦,需要每个用例开始之前,检测用户的登录状态。
如果可以控制测试用例的执行顺序,按照功能流程一遍走下来,节省的代码量是非常可观的,阅读测试用例也会清晰明了许多。
如何控制unittest用例执行的顺序呢?
1、带大家先看看源码,unittest是怎么样对用例进行排序的。在loader.py的loadTestsFromTestCase方法里边,调用了getTestCaseNames方法来获取测试用例的名称
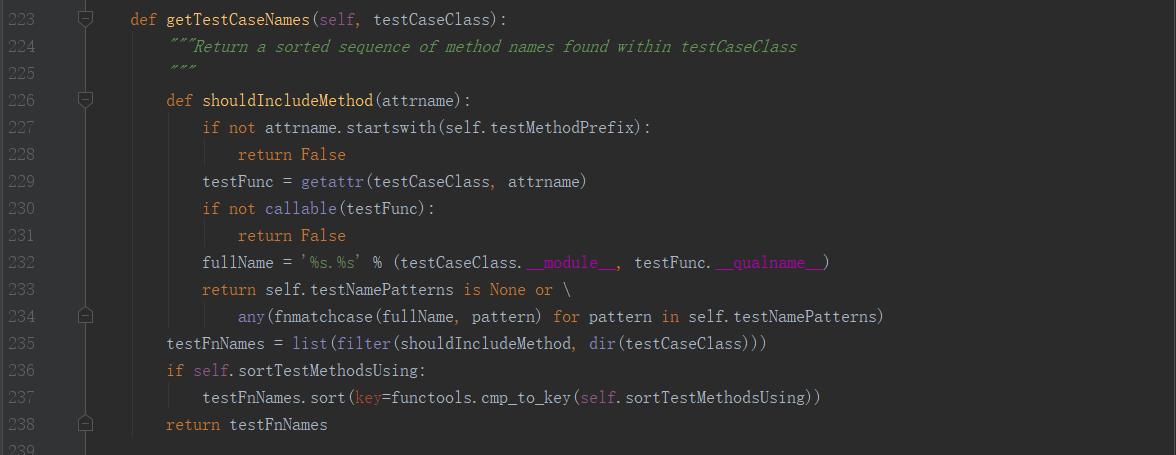
2、从源码可以清楚地看到,getTestCaseNames方法对测试用例的名称进行了排序

3、一步一步跟进去,查看其排序方法

4、根据排序规则,unittest执行测试用例,默认是根据ASCII码的顺序加载测试用例,数字与字母的顺序为:0-9,A-Z,a-z。
5、做个小demo,看看是不是我们所说的那种排序规则
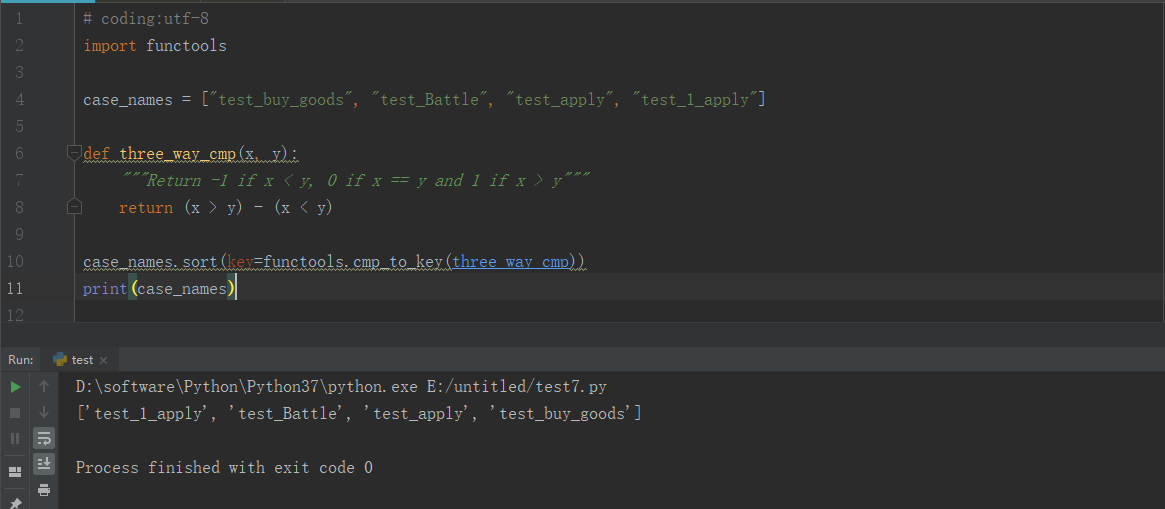
6、从上边的运行结果,我们可以看出是:unittest执行测试用例,默认是根据ASCII码的顺序加载测试用例,数字与字母的顺序为:0-9,A-Z,a-z。
7、基于unittest的机制,如何控制用例执行顺序呢?查了一些网上的资料,主要介绍了两种方式:
方式1,通过TestSuite类的addTest方法,按顺序加载测试用例
参考代码
# coding=utf-
#.先设置编码,utf-8可支持中英文,如上,一般放在第一行 #.注释:包括记录创建时间,创建人,项目名称。
'''
Created on --
@author: 北京-宏哥
Project:学习和使用unittest框架编写测试用例执行顺序
'''
#.导入unittest模块
import unittest
#.执行顺序和运行测试
import unittest class TestLogin(unittest.TestCase): def setUp(self):
pass
def test_login_blog(self):
"""登录博客园 :return:
"""
print("登录博客园")
def test_add_essay(self):
""" 添加随笔 :return:
"""
print("添加随笔")
def test_release_essay(self):
""" 发布随笔 :return:
"""
print("发布随笔")
def test_quit_blog(self):
"""退出博客园 :return:
"""
print("退出博客园") def tearDown(self):
pass
if __name__ == '__main__':
# 启动单元测试
# unittest.main() # 获取TestSuite的实例对象
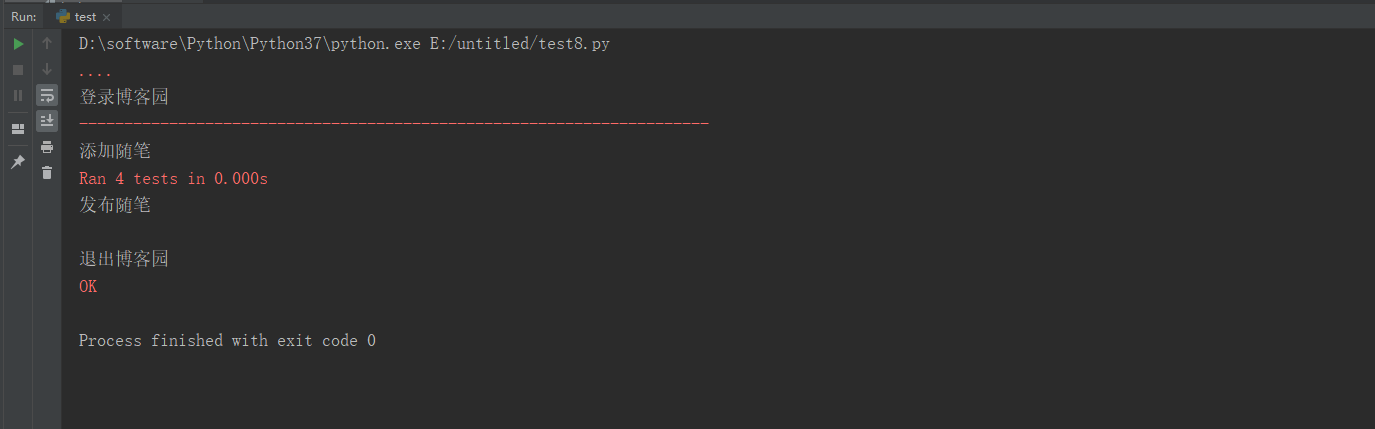
suite = unittest.TestSuite() # 将测试用例添加到测试容器中
suite.addTest(TestLogin('test_login_blog'))
suite.addTest(TestLogin('test_add_essay'))
suite.addTest(TestLogin('test_release_essay'))
suite.addTest(TestLogin('test_quit_blog')) # 创建TextTestRunner类的实例对象
runner = unittest.TextTestRunner()
runner.run(suite)
#unittest.TextTestRunner(verbosity=).run(suite)
方式2,通过修改函数名的方式
参考代码
# coding=utf-
#.先设置编码,utf-8可支持中英文,如上,一般放在第一行 #.注释:包括记录创建时间,创建人,项目名称。
'''
Created on --
@author: 北京-宏哥
Project:学习和使用unittest框架编写测试用例执行顺序
'''
#.导入unittest模块
import unittest
#.执行顺序和运行测试
import unittest class TestLogin(unittest.TestCase): def setUp(self):
pass
def test_1_login_blog(self):
"""登录博客园 :return:
"""
print("登录博客园")
def test_2_add_essay(self):
""" 添加随笔 :return:
"""
print("添加随笔")
def test_3_release_essay(self):
""" 发布随笔 :return:
"""
print("发布随笔")
def test_4_quit_blog(self):
"""退出博客园 :return:
"""
print("退出博客园") def tearDown(self):
pass
if __name__ == '__main__':
# 启动单元测试
unittest.main()
拓展练习
1、实例
2、运行结果
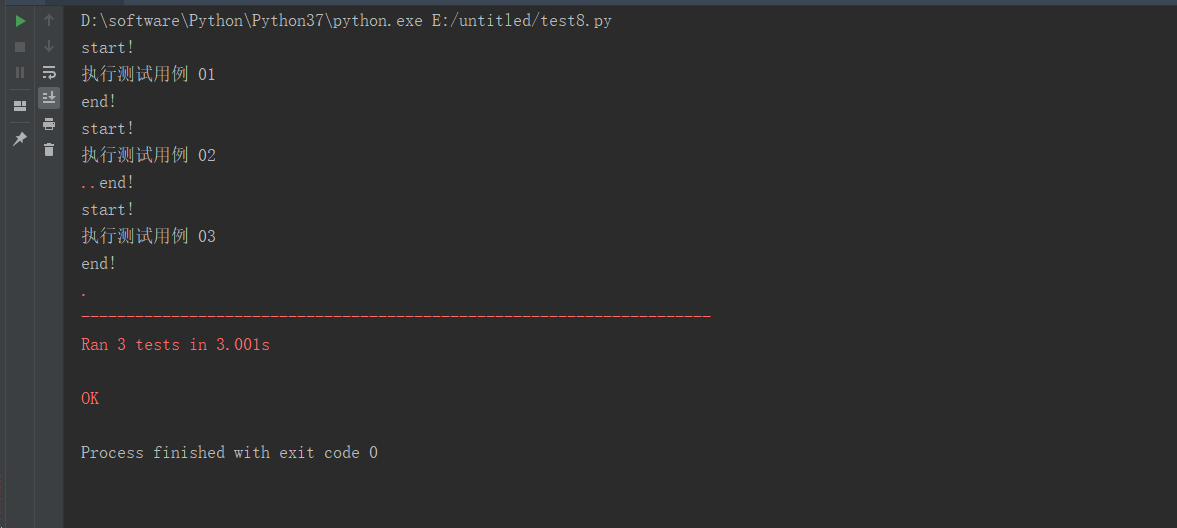
3、运行结果分析
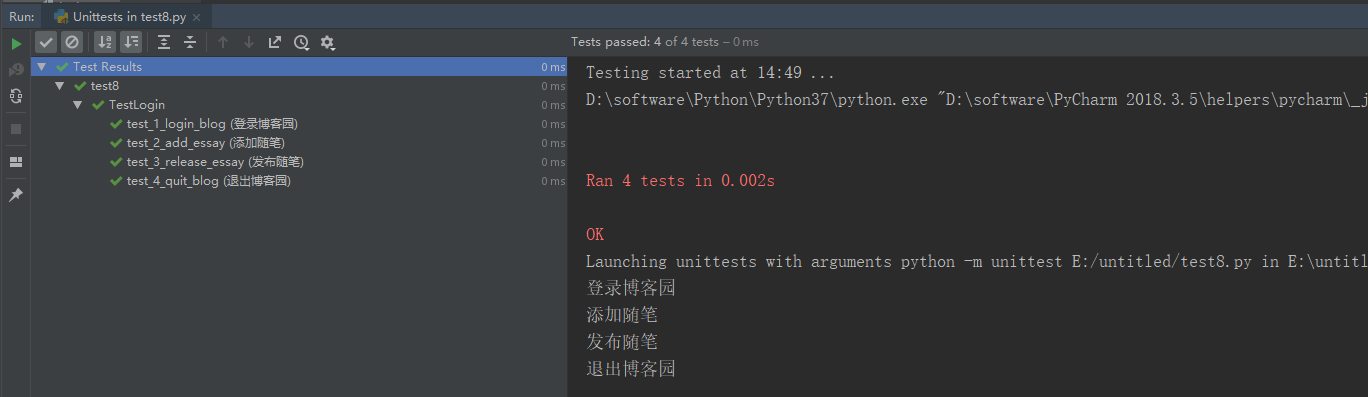
1、从运行结果可以看出执行顺序:
start!-执行测试用例 01-end!
start!-执行测试用例 02-end!
start!-执行测试用例 03-end!
2、从执行结果可以看出几点
--先执行的前置 setUp,然后执行的用例(test*),最后执行的后置 tearDown
--测试用例(test*)的执行顺序是根据 01-02-03 执行的,也就是说根据用例名称来顺序执行的
--addtest(self)这个方法没执行,说明只执行 test 开头的用例
参考代码
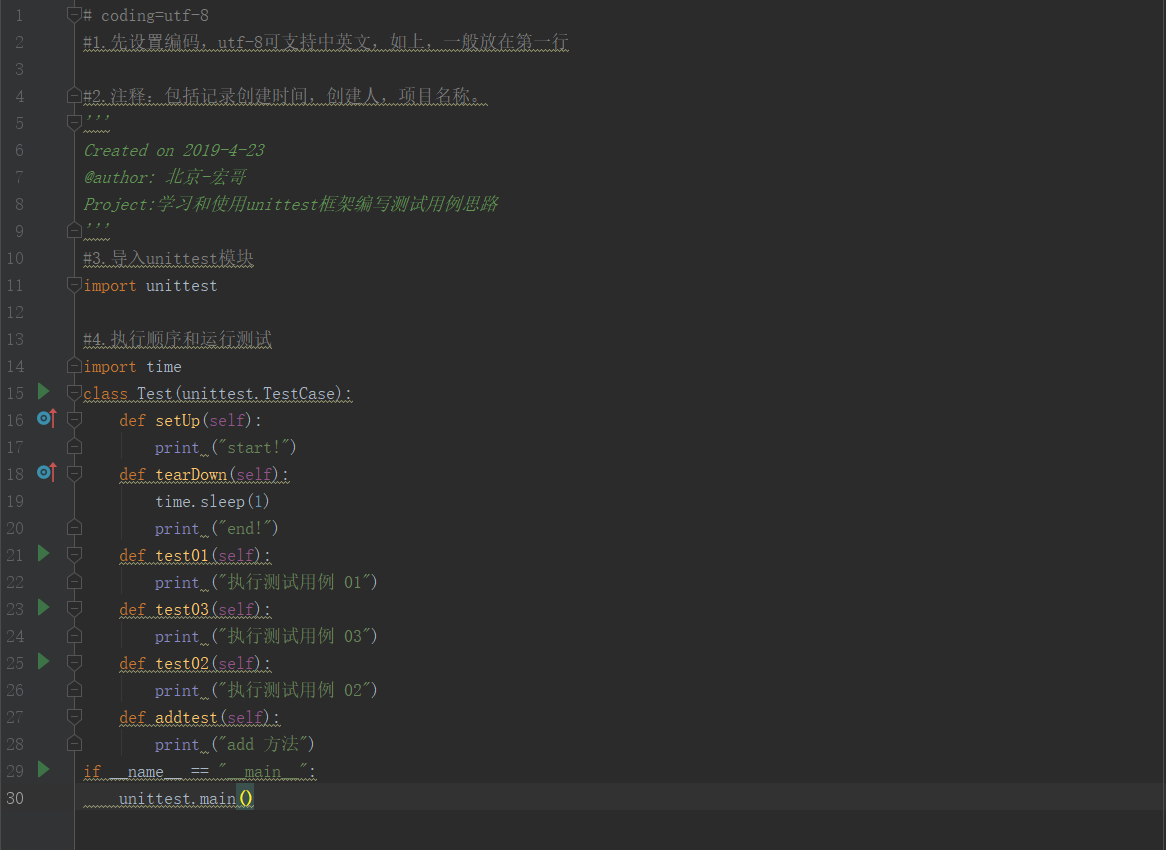
# coding=utf-
#.先设置编码,utf-8可支持中英文,如上,一般放在第一行 #.注释:包括记录创建时间,创建人,项目名称。
'''
Created on --
@author: 北京-宏哥
Project:学习和使用unittest框架编写测试用例思路
'''
#.导入unittest模块
import unittest #.执行顺序和运行测试
import time
class Test(unittest.TestCase):
def setUp(self):
print ("start!")
def tearDown(self):
time.sleep()
print ("end!")
def test01(self):
print ("执行测试用例 01")
def test03(self):
print ("执行测试用例 03")
def test02(self):
print ("执行测试用例 02")
def addtest(self):
print ("add 方法")
if __name__ == "__main__":
unittest.main()
小结
1、这个执行顺序,看似简单,实则不简单,只有掌握最简单的才可以应付最复杂的。
2、setUp()和tearDown()方法有什么用呢?设想你的测试需要启动一个数据库,这时,就可以在setUp()方法中连接数据库,在tearDown()方法中关闭数据库,这样,不必在每个测试方法中重复相同的代码。
python接口自动化(二十二)--unittest执行顺序隐藏的坑(详解)的更多相关文章
- python接口自动化(十八)--重定向(Location)(详解)
简介 在实际工作中,有些接口请求完以后会重定向到别的url,而你却需要重定向前的url.URL主要是针对虚拟空间而言,因为不是自己独立管理的服务器,所以无法正常进行常规的操作.但是自己又不希望通过主域 ...
- python接口自动化(十二)--https请求(SSL)(详解)
简介 本来最新的requests库V2.13.0是支持https请求的,但是一般写脚本时候,我们会用抓包工具fiddler,这时候会 报:requests.exceptions.SSLError: [ ...
- python接口自动化(十一)--发送post【data】(详解)
简介 前面登录博客园的是传 json 参数,由于其登录机制的改变没办法演示,然而在工作中有些登录不是传 json 的,如 jenkins 的登录,这里小编就以jenkins 登录为案例,传 data ...
- python接口自动化(十)--post请求四种传送正文方式(详解)
简介 post请求我在python接口自动化(八)--发送post请求的接口(详解)已经讲过一部分了,主要是发送一些较长的数据,还有就是数据比较安全等.我们要知道post请求四种传送正文方式首先需要先 ...
- 【pytest官方文档】解读fixtures - 11. fixture的执行顺序,3要素详解(长文预警)
当pytest要执行一个测试函数,这个测试函数还请求了fixture函数,那么这时候pytest就要先确定fixture的执行顺序了. 影响因素有三: scope,就是fixture函数的作用范围,比 ...
- python接口自动化(二十八)--html测试 报告——下(详解)
简介 五一小长假已经结束了,想必大家都吃饱喝足玩好了,那就继续学习吧.一天不学习,自己知道:两天不学习,对手知道:三天不学习,大家知道:一周不学习,智商输给猪.好了开个玩笑都逗大家一乐,但是想想还是有 ...
- python接口自动化(十六)--参数关联接口后传(详解)
简介 大家对前边的自动化新建任务之后,接着对这个新建任务操作了解之后,希望带小伙伴进一步巩固胜利的果实,夯实基础.因此再在沙场实例演练一下博客园的相关接口.我们用自动化发随笔之后,要想接着对这篇随笔操 ...
- python接口自动化(十五)--参数关联接口(详解)
简介 我们用自动化新建任务之后,要想接着对这个新建任务操作,那就需要用参数关联了,新建任务之后会有一个任务的Jenkins-Crumb,获取到这个Jenkins-Crumb,就可以通过传这个任务Jen ...
- python接口自动化(十四)--session关联接口(详解)
简介 上一篇cookie绕过验证码模拟登录博客园,但这只是第一步,一般登录后,还会有其它的操作,如发帖,评论等等,这时候如何保持会话呢?这里我以jenkins平台为例,给小伙伴们在沙场演练一下. se ...
随机推荐
- 一些Gym三星单刷的比赛总结
RDC 2013, Samara SAU ACM ICPC Quarterfinal Qualification Contest G 思路卡成智障呀! Round 1:对着这个魔法阵找了半天规律,效果 ...
- 帧同步(LockStep)该如何反外挂
在中国的游戏环境下,反挂已经成为了游戏开发的重中之重,甚至能决定一款游戏的生死,吃鸡就是一个典型的案例.目前参与了了一款动作射击的MOBA类游戏的开发,同步方案上选择了帧同步技术(LockStep而非 ...
- 安装RabbitMQ编译erlang时,checking for c compiler default output file name... configure:error:C compiler cannot create executables See 'config.log' for more details.
checking for c compiler default output file name... configure:error:C compiler cannot create executa ...
- mac终端命令及pycharm常用快捷键记录
mac终端命令: 1.root权限 $sudo su - 2.定位到指定文件夹位置 $cd /Users/计算机名称/Desktop (定位到桌面) 3.新建文件夹 $mkdir 文件夹名称 ...
- restrict关键字(暗示编译器,某个指针指向的空间,只能从该指针访问)
我们希望某个对象(内存空间)不被修改的通常做法是什么?声明该空间的const类型,但是这样真的可以吗?是不是的,由于const空间对象的指针是可以付给一个非const值指针的.所以这仍然无法不让该空间 ...
- PAT1107:Social Clusters
1107. Social Clusters (30) 时间限制 1000 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 CHEN, Yue When ...
- 网络编程之套接字(udp)
Socket的英文原义是“孔”或“插座”.作为BSD UNIX的进程通信机制,取后一种意思.通常也称作"套接字",用于描述IP地址和端口,是一个通信链的句柄,可以用来实现不同虚拟机 ...
- UISegmentedControl在Swift中的使用
UISegmentedControl控件是分段显示控件,用户可以选择它上展示的任一段部分,每一个部分都像是一个按钮,如果被按下也会像UIButton一样执行相应的方法.在这篇文章中我们将创建一个UIS ...
- Linux时间子系统之二:Alarm Timer
一.前言 严格来讲Alarm Timer也算POSIX Timer一部分,包含两种类型CLOCK_REALTIME_ALARM和CLOCK_BOOTTIME_ALARM.分别是在CLOCK_REALT ...
- 关于二叉查找树的一些事儿(bst详解,平衡树入门)
最近刚学了平衡树,然后突发奇想写几篇博客纪念一下,可能由于是刚学的缘故,还有点儿生疏,望大家海涵 说到平衡树,就不得不从基础说起,而基础,正是二叉查找树 什么是二叉查找树?? 大家观察一下下面的这棵二 ...