Scrapy-多层爬取天堂图片网
1.根据图片分类对爬取的图片进行分类

开发者选项 --> 找到分类地址

爬取每个分类的地址通过回调函数传入下一层
name = 'sky'
start_urls = ['http://ivsky.com/']
def parse(self, response):
selector = Selector(response)
# print(response.text)
types = selector.xpath("//div[@class='kw']/a")
for type in types:
typeUrl = type.xpath("@href").extract()[0] #分类地址
typeName = type.xpath("text()").extract()[0] #分类名称
# print(typeUrl+" "+typeName)
yield Request(self.start_urls[0]+typeUrl,callback=self.parseTotalPage,meta={'typeName':typeName})
2.点击进入一个类型 --> 开发者选项 --> 找到分页代码段

爬取每一个分页的地址也是通过回调函数传入下一层进行处理
def parseTotalPage(self,response):
typeName = response.meta["typeName"]
# print(typeName)
selector = Selector(response)
# print(response.text)
pageList = selector.xpath("//div[@class='pagelist']//a//@href").extract() #每一页的地址
for page in pageList:
yield Request(self.start_urls[0]+page,callback=self.parseGetImg,meta={'typeName':typeName})
3.获取一类图地址 --> 开发者选项 --> 找到相同类图的地址

爬取这类图的地址通过回调函数传入下一层进行处理
def parseGetImg(self,response):
typeName = response.meta["typeName"]
selector = Selector(response)
imgs = selector.xpath("//div[@class='il_img']//a")
for img in imgs:
imgUrl = img.xpath("@href").extract()[0] #一类图的地址
# print(imgUrl+" "+imgName)
yield Request(self.start_urls[0]+imgUrl,callback=self.parseGetMoreImg)
4.查看每张图片的html代码 --> 找到图片的地址
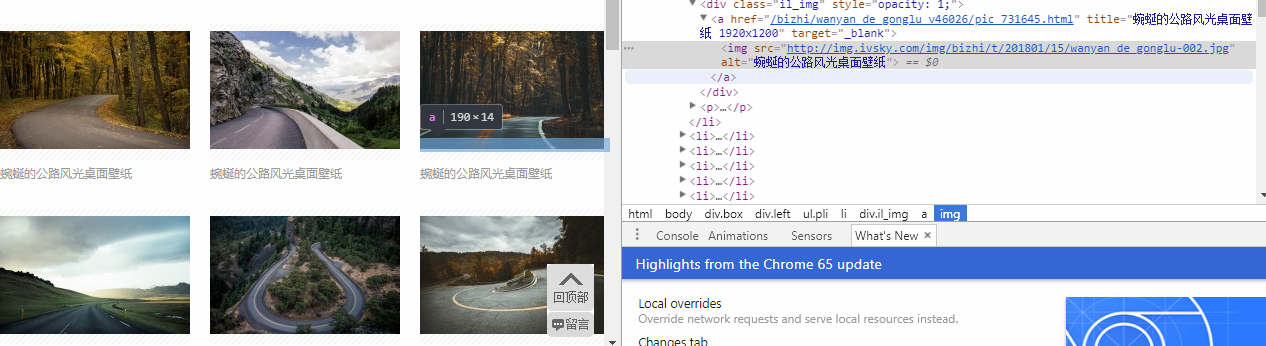
爬取每张图的地址
def parseGetMoreImg(self,response):
# / html / body / div[3] / div[4] / ul / li[3] / div / a / img
selector = Selector(response)
# print(response.text)
items = IvskyItem()
items["imgName"] = response.meta["imgName"]
items["imgUrl"] = selector.xpath("//div[@class='il_img']//a//img//@src").extract()
# print(items)
yield items
最后将图片传入pipelines.py 进行下载处理,要先在setting.py 设置,否则无法进入pipelines.py
ITEM_PIPELINES = {
'ivsky.pipelines.IvskyPipeline': 300,
}
代码地址:https://github.com/WitW/ivsky
Scrapy-多层爬取天堂图片网的更多相关文章
- Python的scrapy之爬取顶点小说网的所有小说
闲来无事用Python的scrapy框架练练手,爬取顶点小说网的所有小说的详细信息. 看一下网页的构造: tr标签里面的 td 使我们所要爬取的信息 下面是我们要爬取的二级页面 小说的简介信息: 下面 ...
- 使用scrapy爬虫,爬取17k小说网的案例-方法一
无意间看到17小说网里面有一些小说小故事,于是决定用爬虫爬取下来自己看着玩,下图这个页面就是要爬取的来源. a 这个页面一共有125个标题,每个标题里面对应一个内容,如下图所示 下面直接看最核心spi ...
- scrapy实例:爬取中国天气网
1.创建项目 在你存放项目的目录下,按shift+鼠标右键打开命令行,输入命令创建项目: PS F:\ScrapyProject> scrapy startproject weather # w ...
- scrapy框架爬取妹子图片
首先,建立一个项目#可在github账户下载完整代码:https://github.com/connordb/scrapy-jiandan2 scrapy startproject jiandan2 ...
- Python的scrapy之爬取链家网房价信息并保存到本地
因为有在北京租房的打算,于是上网浏览了一下链家网站的房价,想将他们爬取下来,并保存到本地. 先看链家网的源码..房价信息 都保存在 ul 下的li 里面 爬虫结构: 其中封装了一个数据库处理模 ...
- Python的scrapy之爬取妹子图片
闲来无事,做的一个小爬虫项目 爬虫主程序: import scrapy from ..items import MeiziItem class MztSpider(scrapy.Spider): na ...
- 使用scrapy爬虫,爬取起点小说网的案例
爬取的页面为https://book.qidian.com/info/1010734492#Catalog 爬取的小说为凡人修仙之仙界篇,这边小说很不错. 正文的章节如下图所示 其中下面的章节为加密部 ...
- 使用scrapy爬虫,爬取17k小说网的案例-方法二
楼主准备爬取此页面的小说,此页面一共有125章 我们点击进去第一章和第一百二十五章发现了一个规律 我们看到此链接的 http://www.17k.com/chapter/271047/6336386 ...
- Python爬虫【实战篇】scrapy 框架爬取某招聘网存入mongodb
创建项目 scrapy startproject zhaoping 创建爬虫 cd zhaoping scrapy genspider hr zhaopingwang.com 目录结构 items.p ...
随机推荐
- TCP是什么? 最简单的三次握手说明
TCP是什么? TCP(Transmission Control Protocol 传输控制协议)是一种面向连接(连接导向)的.可靠的. 基于IP的传输层协议.TCP在IP报文的协议号是6.TCP是一 ...
- Linux - ubuntu vMwareTools安装
ubuntu vMwareTools安装 不安装很麻烦,虚拟机中的内容,包括文件.无法复制到pc端.同样的pc端的内容也无法复制到虚拟机中. 1.点击虚拟机,选择安装VMwareTools 这个时候就 ...
- 微信小程序左右滑动切换图片酷炫效果
开门见山,先上效果吧!感觉可以的用的上的再往下看. 心动吗?那就继续往下看! 先上页面结构吧,也就是wxml文件,其实可以理解成微信自己封装过的html,这个不多说了,不懂也没必要往下看了. < ...
- 【故障】MySQL主从同步故障-Slave_SQL_Running: No
转自:http://www.linuxidc.com/Linux/2014-02/96945.htm 故障现象:进入slave服务器,运行:mysql> show slave status\G ...
- CentOS7.3 ARM虚拟机扩容系统磁盘
由于扩容磁盘的操作非同小可,一旦哪一步出现问题,就会导致分区损坏,数据丢失等一系列严重的问题,因此建议:在进行虚拟机分区扩容之前,一定要备份重要数据文件,并且先在测试机上验证以下步骤,再应用于您的生产 ...
- 译-what is cmdlet
A cmdlet (pronounced "command-let") is a lightweight Windows PowerShell script that perfor ...
- junit测试延伸--方法的重复测试
在实际编码测试中,我们有的时候需要对一个方法进行多次测试,那么怎么办呢?这个问题和测试套件解决的方案一样,我们总不能不停的去右键run as,那怎么办呢?还好伟大的junit帮我们想到了. OK,现在 ...
- grails项目数据源配置
grails项目数据源配置 mysql: driverClassName : com.mysql.jdbc.Driver url: jdbc:mysql://127.0.0.1:3306/mysql ...
- LNMP之Nginx
Nginx初探 概念: Nginx是一款免费.开源.高性能的HTTP服务器和反向代理,同时也可作为邮件代理服务器.其因为高性能.稳定.丰富的功能集.配置简单和低系统资源消耗而闻名. Tengine是由 ...
- C#常见问题总结(二)
1.erp系统可以在具有固定ip的拥有多层服务器的局域网中使用吗?如何使用 解决方法: 把ini.配置文件字符串中的服务器名改成服务器的,把debug文件夹拷到其他机器上就行,服务器上的服务器名是默认 ...