机器学习之决策树三-CART原理与代码实现
决策树系列三—CART原理与代码实现
本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/9482885.html
ID3,C4.5算法缺点
ID3决策树可以有多个分支,但是不能处理特征值为连续的情况。
在ID3中,每次根据“最大信息熵增益”选取当前最佳的特征来分割数据,并按照该特征的所有取值来切分,
也就是说如果一个特征有4种取值,数据将被切分4份,一旦按某特征切分后,该特征在之后的算法执行中,
将不再起作用,所以有观点认为这种切分方式过于迅速。
C4.5中是用信息增益比率(gain ratio)来作为选择分支的准则。和ID3一样,C4.5算法分类结果存在过拟合。
为了解决过拟合问题,这里介绍一种新的算法CART。
CART(classification and regression tree)
CART由特征选择、树的生成及剪枝组成,既可以用于分类也可以用于回归。
分类:如晴天/阴天/雨天、用户性别、邮件是否是垃圾邮件;
回归:预测实数值,如明天的温度、用户的年龄等;
CART决策树的生成就是递归地构建二叉决策树的过程,对分类、以及剪枝采用信息增益最大化准则,这里信息增益采用的基尼指数公式,
当然也可以使用ID3的信息熵公式算法。
基尼指数
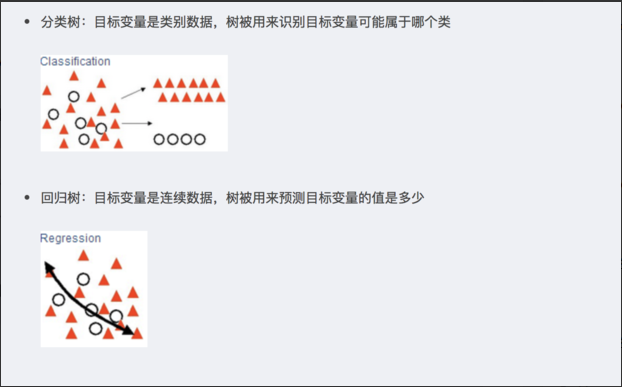
分类问题中,假设有K个类别,样本点属于第类的概率为
,则概率分布的基尼指数定义为
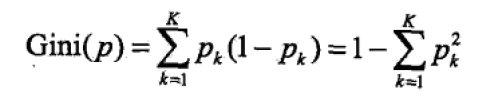
对于给定的样本集合D,其基尼指数为
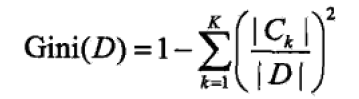
生成的二叉树类似于
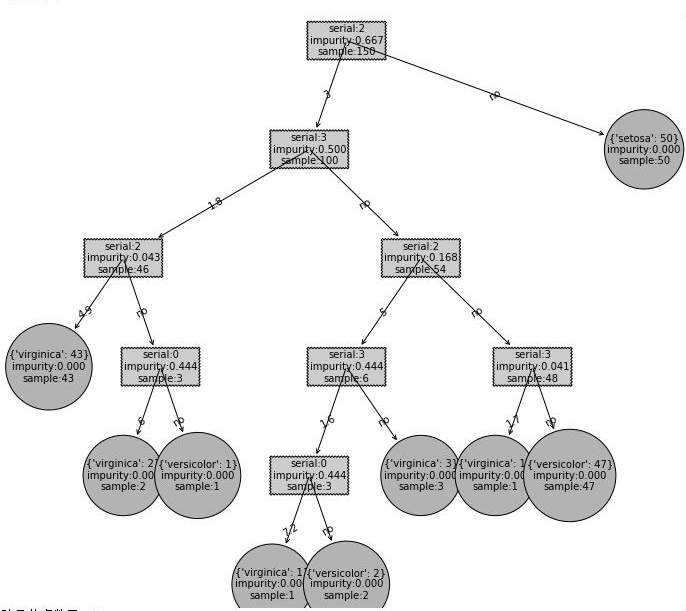
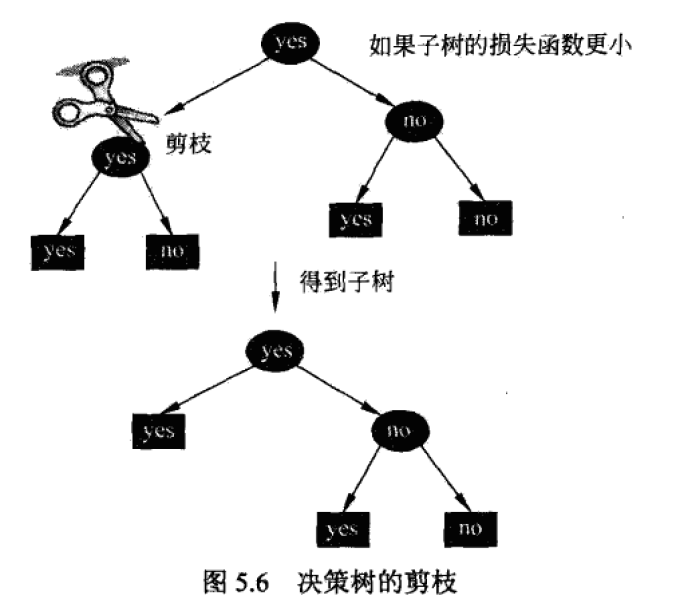
剪枝算法
CART剪枝算法从“完全生长”的决策树的底端减去一些子树,是决策树变小(模型变简单),从而能够对未知数据有更准确的预测,防止过拟合。
后剪枝需要从训练集生成一棵完整的决策树,然后自底向上对非叶子节点进行考察。利用信息增益与给定阈值判断是否将该节点对应的子树替换成叶节点。
代码实现
每个函数算法我基本上都做了较为详细的注释,希望对大家理解算法原理有所帮助。
因为没有上传附件功能,只能用笨办法。将原始数据复制到本地txt文件中,然后将txt格式改成dataSet.csv文件,
放在代码文件所在的路径。
SepalLength,SepalWidth,PetalLength,PetalWidth,Name
5.1,3.5,1.4,0.2,setosa
4.9,3,1.4,0.2,setosa
4.7,3.2,1.3,0.2,setosa
4.6,3.1,1.5,0.2,setosa
5,3.6,1.4,0.2,setosa
5.4,3.9,1.7,0.4,setosa
4.6,3.4,1.4,0.3,setosa
5,3.4,1.5,0.2,setosa
4.4,2.9,1.4,0.2,setosa
4.9,3.1,1.5,0.1,setosa
5.4,3.7,1.5,0.2,setosa
4.8,3.4,1.6,0.2,setosa
4.8,3,1.4,0.1,setosa
4.3,3,1.1,0.1,setosa
5.8,4,1.2,0.2,setosa
5.7,4.4,1.5,0.4,setosa
5.4,3.9,1.3,0.4,setosa
5.1,3.5,1.4,0.3,setosa
5.7,3.8,1.7,0.3,setosa
5.1,3.8,1.5,0.3,setosa
5.4,3.4,1.7,0.2,setosa
5.1,3.7,1.5,0.4,setosa
4.6,3.6,1,0.2,setosa
5.1,3.3,1.7,0.5,setosa
4.8,3.4,1.9,0.2,setosa
5,3,1.6,0.2,setosa
5,3.4,1.6,0.4,setosa
5.2,3.5,1.5,0.2,setosa
5.2,3.4,1.4,0.2,setosa
4.7,3.2,1.6,0.2,setosa
4.8,3.1,1.6,0.2,setosa
5.4,3.4,1.5,0.4,setosa
5.2,4.1,1.5,0.1,setosa
5.5,4.2,1.4,0.2,setosa
4.9,3.1,1.5,0.1,setosa
5,3.2,1.2,0.2,setosa
5.5,3.5,1.3,0.2,setosa
4.9,3.1,1.5,0.1,setosa
4.4,3,1.3,0.2,setosa
5.1,3.4,1.5,0.2,setosa
5,3.5,1.3,0.3,setosa
4.5,2.3,1.3,0.3,setosa
4.4,3.2,1.3,0.2,setosa
5,3.5,1.6,0.6,setosa
5.1,3.8,1.9,0.4,setosa
4.8,3,1.4,0.3,setosa
5.1,3.8,1.6,0.2,setosa
4.6,3.2,1.4,0.2,setosa
5.3,3.7,1.5,0.2,setosa
5,3.3,1.4,0.2,setosa
7,3.2,4.7,1.4,versicolor
6.4,3.2,4.5,1.5,versicolor
6.9,3.1,4.9,1.5,versicolor
5.5,2.3,4,1.3,versicolor
6.5,2.8,4.6,1.5,versicolor
5.7,2.8,4.5,1.3,versicolor
6.3,3.3,4.7,1.6,versicolor
4.9,2.4,3.3,1,versicolor
6.6,2.9,4.6,1.3,versicolor
5.2,2.7,3.9,1.4,versicolor
5,2,3.5,1,versicolor
5.9,3,4.2,1.5,versicolor
6,2.2,4,1,versicolor
6.1,2.9,4.7,1.4,versicolor
5.6,2.9,3.6,1.3,versicolor
6.7,3.1,4.4,1.4,versicolor
5.6,3,4.5,1.5,versicolor
5.8,2.7,4.1,1,versicolor
6.2,2.2,4.5,1.5,versicolor
5.6,2.5,3.9,1.1,versicolor
5.9,3.2,4.8,1.8,versicolor
6.1,2.8,4,1.3,versicolor
6.3,2.5,4.9,1.5,versicolor
6.1,2.8,4.7,1.2,versicolor
6.4,2.9,4.3,1.3,versicolor
6.6,3,4.4,1.4,versicolor
6.8,2.8,4.8,1.4,versicolor
6.7,3,5,1.7,versicolor
6,2.9,4.5,1.5,versicolor
5.7,2.6,3.5,1,versicolor
5.5,2.4,3.8,1.1,versicolor
5.5,2.4,3.7,1,versicolor
5.8,2.7,3.9,1.2,versicolor
6,2.7,5.1,1.6,versicolor
5.4,3,4.5,1.5,versicolor
6,3.4,4.5,1.6,versicolor
6.7,3.1,4.7,1.5,versicolor
6.3,2.3,4.4,1.3,versicolor
5.6,3,4.1,1.3,versicolor
5.5,2.5,4,1.3,versicolor
5.5,2.6,4.4,1.2,versicolor
6.1,3,4.6,1.4,versicolor
5.8,2.6,4,1.2,versicolor
5,2.3,3.3,1,versicolor
5.6,2.7,4.2,1.3,versicolor
5.7,3,4.2,1.2,versicolor
5.7,2.9,4.2,1.3,versicolor
6.2,2.9,4.3,1.3,versicolor
5.1,2.5,3,1.1,versicolor
5.7,2.8,4.1,1.3,versicolor
6.3,3.3,6,2.5,virginica
5.8,2.7,5.1,1.9,virginica
7.1,3,5.9,2.1,virginica
6.3,2.9,5.6,1.8,virginica
6.5,3,5.8,2.2,virginica
7.6,3,6.6,2.1,virginica
4.9,2.5,4.5,1.7,virginica
7.3,2.9,6.3,1.8,virginica
6.7,2.5,5.8,1.8,virginica
7.2,3.6,6.1,2.5,virginica
6.5,3.2,5.1,2,virginica
6.4,2.7,5.3,1.9,virginica
6.8,3,5.5,2.1,virginica
5.7,2.5,5,2,virginica
5.8,2.8,5.1,2.4,virginica
6.4,3.2,5.3,2.3,virginica
6.5,3,5.5,1.8,virginica
7.7,3.8,6.7,2.2,virginica
7.7,2.6,6.9,2.3,virginica
6,2.2,5,1.5,virginica
6.9,3.2,5.7,2.3,virginica
5.6,2.8,4.9,2,virginica
7.7,2.8,6.7,2,virginica
6.3,2.7,4.9,1.8,virginica
6.7,3.3,5.7,2.1,virginica
7.2,3.2,6,1.8,virginica
6.2,2.8,4.8,1.8,virginica
6.1,3,4.9,1.8,virginica
6.4,2.8,5.6,2.1,virginica
7.2,3,5.8,1.6,virginica
7.4,2.8,6.1,1.9,virginica
7.9,3.8,6.4,2,virginica
6.4,2.8,5.6,2.2,virginica
6.3,2.8,5.1,1.5,virginica
6.1,2.6,5.6,1.4,virginica
7.7,3,6.1,2.3,virginica
6.3,3.4,5.6,2.4,virginica
6.4,3.1,5.5,1.8,virginica
6,3,4.8,1.8,virginica
6.9,3.1,5.4,2.1,virginica
6.7,3.1,5.6,2.4,virginica
6.9,3.1,5.1,2.3,virginica
5.8,2.7,5.1,1.9,virginica
6.8,3.2,5.9,2.3,virginica
6.7,3.3,5.7,2.5,virginica
6.7,3,5.2,2.3,virginica
6.3,2.5,5,1.9,virginica
6.5,3,5.2,2,virginica
6.2,3.4,5.4,2.3,virginica
5.9,3,5.1,1.8,virginica
原始数据
# -*- coding: utf-8 -*-
"""
Created on Tue Aug 14 17:36:57 2018 @author: weixw
"""
import numpy as np
#定义树结构,采用的二叉树,左子树:条件为true,右子树:条件为false
#leftBranch:左子树结点
#rightBranch:右子树结点
#col:信息增益最大时对应的列索引
#value:最优列索引下,划分数据类型的值
#results:分类结果
#summary:信息增益最大时样本信息
#data:信息增益最大时数据集
class Tree:
def __init__(self, leftBranch =None, rightBranch= None, col =-1, value =None, results =None, summary =None, data =None):
self.leftBranch = leftBranch
self.rightBranch = rightBranch
self.col = col
self.value = value
self.results = results
self.summary = summary
self.data = data def __str__(self):
print(u"列号:%d"%self.col)
print(u"列划分值:%s"%self.value)
print(u"样本信息:%s"%self.summary)
return "" #划分数据集
def splitDataSet(dataSet, value, column):
leftList=[]
rightList=[]
#判断value是否是数值型
if(isinstance(value, int) or isinstance(value, float)):
#遍历每一行数据
for rowData in dataSet:
#如果某一行指定列值>=value,则将该行数据保存在leftList中,否则保存在rightList中
if(rowData[column] >= value):
leftList.append(rowData)
else:
rightList.append(rowData)
#value为标称型
else:
#遍历每一行数据
for rowData in dataSet:
#如果某一行指定列值==value,则将该行数据保存在leftList中,否则保存在rightList中
if(rowData[column] == value):
leftList.append(rowData)
else:
rightList.append(rowData)
return leftList, rightList #统计标签类每个样本个数
'''
该函数是计算gini值的辅助函数,假设输入的dataSet为为['A', 'B', 'C', 'A', 'A', 'D'],
则输出为['A':3,' B':1, 'C':1, 'D':1],这样分类统计dataSet中每个类别的数量
'''
def calculateDiffCount(dataSet):
results = {}
for data in dataSet:
# data[-1] 是数据集最后一列,也就是标签类
if data[-1] not in results:
results.setdefault(data[-1], 1)
else:
results[data[-1]] += 1
return results #基尼指数公式实现
def gini(dataSet):
# 计算gini的值(Calculate GINI)
#数据所有行
length = len(dataSet)
#标签列合并后的数据集
results = calculateDiffCount(dataSet)
imp = 0.0
for i in results:
imp += results[i] / length * results[i] / length
return 1 - imp #生成决策树
'''算法步骤'''
'''根据训练数据集,从根结点开始,递归地对每个结点进行以下操作,构建二叉决策树:
1 设结点的训练数据集为D,计算现有特征对该数据集的信息增益。此时,对每一个特征A,对其可能取的
每个值a,根据样本点对A >=a 的测试为“是”或“否”将D分割成D1和D2两部分,利用基尼指数计算信息增益。
2 在所有可能的特征A以及它们所有可能的切分点a中,选择信息增益最大的特征及其对应的切分点作为最优特征
与最优切分点,依据最优特征与最优切分点,从现结点生成两个子结点,将训练数据集依特征分配到两个子结点中去。
3 对两个子结点递归地调用1,2,直至满足停止条件。
4 生成CART决策树。
'''''''''''''''''''''
#evaluationFunc= gini :采用的是基尼指数来衡量信息关注度
def buildDecisionTree(dataSet, evaluationFunc = gini):
#计算基础数据集的基尼指数
baseGain = evaluationFunc(dataSet)
#计算每一行的长度(也就是列总数)
columnLength = len(dataSet[0])
#计算数据项总数
rowLength = len(dataSet)
#初始化
bestGain = 0.0 #信息增益最大值
bestValue = None #信息增益最大时的列索引,以及划分数据集的样本值
bestSet = None # 信息增益最大,听过样本值划分数据集后的数据子集
#标签列除外(最后一列),遍历每一列数据
for col in range(columnLength -1):
#获取指定列数据
colSet = [example[col] for example in dataSet]
#获取指定列样本唯一值
uniqueColSet = set(colSet)
#遍历指定列样本集
for value in uniqueColSet:
#分割数据集
leftDataSet, rightDataSet = splitDataSet(dataSet, value, col)
#计算子数据集概率,python3 "/"除号结果为小数
prop = len(leftDataSet)/rowLength
#计算信息增益
infoGain = baseGain - prop*evaluationFunc(leftDataSet) - (1 - prop)*evaluationFunc(rightDataSet)
#找出信息增益最大时的列索引,value,数据子集
if(infoGain > bestGain):
bestGain = infoGain
bestValue = (col, value)
bestSet = (leftDataSet, rightDataSet)
#结点信息
# nodeDescription = {'impurity:%.3f'%baseGain,'sample:%d'%rowLength}
nodeDescription = {'impurity': '%.3f' % baseGain, 'sample': '%d' % rowLength}
#数据行标签类别不一致,可以继续分类
#递归必须有终止条件
if bestGain > 0:
#递归,生成左子树结点,右子树结点
leftBranch = buildDecisionTree(bestSet[0], evaluationFunc)
rightBranch = buildDecisionTree(bestSet[1], evaluationFunc)
return Tree(leftBranch = leftBranch, rightBranch = rightBranch, col = bestValue[0]
, value = bestValue[1], summary = nodeDescription, data = bestSet)
else:
#数据行标签类别都相同,分类终止
return Tree(results = calculateDiffCount(dataSet), summary = nodeDescription, data = dataSet) def createTree(dataSet, evaluationFunc=gini):
# 递归建立决策树, 当gain=0,时停止回归
#计算基础数据集的基尼指数
baseGain = evaluationFunc(dataSet)
#计算每一行的长度(也就是列总数)
columnLength = len(dataSet[0])
#计算数据项总数
rowLength = len(dataSet)
#初始化
bestGain = 0.0 #信息增益最大值
bestValue = None #信息增益最大时的列索引,以及划分数据集的样本值
bestSet = None # 信息增益最大,听过样本值划分数据集后的数据子集
#标签列除外(最后一列),遍历每一列数据
for col in range(columnLength -1):
#获取指定列数据
colSet = [example[col] for example in dataSet]
#获取指定列样本唯一值
uniqueColSet = set(colSet)
#遍历指定列样本集
for value in uniqueColSet:
#分割数据集
leftDataSet, rightDataSet = splitDataSet(dataSet, value, col)
#计算子数据集概率,python3 "/"除号结果为小数
prop = len(leftDataSet)/rowLength
#计算信息增益
infoGain = baseGain - prop*evaluationFunc(leftDataSet) - (1 - prop)*evaluationFunc(rightDataSet)
#找出信息增益最大时的列索引,value,数据子集
if(infoGain > bestGain):
bestGain = infoGain
bestValue = (col, value)
bestSet = (leftDataSet, rightDataSet) impurity = u'%.3f' % baseGain
sample = '%d' % rowLength if bestGain > 0:
bestFeatLabel =u'serial:%s\nimpurity:%s\nsample:%s'%(bestValue[0], impurity,sample)
myTree = {bestFeatLabel:{}}
myTree[bestFeatLabel][bestValue[1]] = createTree(bestSet[0], evaluationFunc)
myTree[bestFeatLabel]['no'] = createTree(bestSet[1], evaluationFunc)
return myTree
else:#递归需要返回值
bestFeatValue =u'%s\nimpurity:%s\nsample:%s'%(str(calculateDiffCount(dataSet)), impurity,sample)
return bestFeatValue #分类测试:
'''根据给定测试数据遍历二叉树,找到符合条件的叶子结点'''
'''例如测试数据为[5.9,3,4.2,1.75],按照训练数据生成的决策树分类的顺序为
第2列对应测试数据4.2 =>与决策树根结点(2)的value(3)比较,>=3则遍历左子树,否则遍历右子树,
叶子结点就是结果'''
def classify(data, tree):
#判断是否是叶子结点,是就返回叶子结点相关信息,否就继续遍历
if tree.results != None:
return u"%s\n%s"%(tree.results, tree.summary)
else:
branch = None
v = data[tree.col]
#数值型数据
if isinstance(v, int) or isinstance(v, float):
if v >= tree.value:
branch = tree.leftBranch
else:
branch = tree.rightBranch
else:#标称型数据
if v == tree.value:
branch = tree.leftBranch
else:
branch = tree.rightBranch
return classify(data, branch) def loadCSV(fileName):
def convertTypes(s):
s = s.strip()
try:
return float(s) if '.' in s else int(s)
except ValueError:
return s
data = np.loadtxt(fileName, dtype='str', delimiter=',')
data = data[1:, :]
dataSet =([[convertTypes(item) for item in row] for row in data])
return dataSet #多数表决器
#列中相同值数量最多为结果
def majorityCnt(classList):
import operator
classCounts = {}
for value in classList:
if(value not in classCounts.keys()):
classCounts[value] = 0
classCounts[value] +=1
sortedClassCount = sorted(classCounts.items(),key = operator.itemgetter(1),reverse =True)
return sortedClassCount[0][0] #剪枝算法(前序遍历方式:根=>左子树=>右子树)
'''算法步骤
1. 从二叉树的根结点出发,递归调用剪枝算法,直至左、右结点都是叶子结点
2. 计算父节点(子结点为叶子结点)的信息增益infoGain
3. 如果infoGain < miniGain,则选取样本多的叶子结点来取代父节点
4. 循环1,2,3,直至遍历完整棵树
'''''''''
def prune(tree, miniGain, evaluationFunc = gini):
print(u"当前结点信息:")
print(str(tree))
#如果当前结点的左子树不是叶子结点,遍历左子树
if(tree.leftBranch.results == None):
print(u"左子树结点信息:")
print(str(tree.leftBranch))
prune(tree.leftBranch, miniGain, evaluationFunc)
#如果当前结点的右子树不是叶子结点,遍历右子树
if(tree.rightBranch.results == None):
print(u"右子树结点信息:")
print(str(tree.rightBranch))
prune(tree.rightBranch, miniGain, evaluationFunc)
#左子树和右子树都是叶子结点
if(tree.leftBranch.results != None and tree.rightBranch.results != None):
#计算左叶子结点数据长度
leftLen = len(tree.leftBranch.data)
#计算右叶子结点数据长度
rightLen = len(tree.rightBranch.data)
#计算左叶子结点概率
leftProp = leftLen/(leftLen + rightLen)
#计算该结点的信息增益(子类是叶子结点)
infoGain = (evaluationFunc(tree.leftBranch.data + tree.rightBranch.data) -
leftProp*evaluationFunc(tree.leftBranch.data) - (1 - leftProp)*evaluationFunc(tree.rightBranch.data))
#信息增益 < 给定阈值,则说明叶子结点与其父结点特征差别不大,可以剪枝
if(infoGain < miniGain):
#合并左右叶子结点数据
dataSet = tree.leftBranch.data + tree.rightBranch.data
#获取标签列
classLabels = [example[-1] for example in dataSet]
#找到样本最多的标签值
keyLabel = majorityCnt(classLabels)
#判断标签值是左右叶子结点哪一个
if keyLabel in tree.leftBranch.results:
#左叶子结点取代父结点
tree.data = tree.leftBranch.data
tree.results = tree.leftBranch.results
tree.summary = tree.leftBranch.summary
else:
#右叶子结点取代父结点
tree.data = tree.rightBranch.data
tree.results = tree.rightBranch.results
tree.summary = tree.rightBranch.summary
tree.leftBranch = None
tree.rightBranch = None
CART算法实现
'''
Created on Oct 14, 2010 @author: Peter Harrington
'''
import matplotlib.pyplot as plt decisionNode = dict(boxstyle="sawtooth", fc="0.8")
leafNode = dict(boxstyle="circle", fc="0.7")
arrow_args = dict(arrowstyle="<-") #获取树的叶子节点
def getNumLeafs(myTree):
numLeafs = 0
#dict转化为list
firstSides = list(myTree.keys())
firstStr = firstSides[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
#判断是否是叶子节点(通过类型判断,子类不存在,则类型为str;子类存在,则为dict)
if type(secondDict[key]).__name__=='dict':#test to see if the nodes are dictonaires, if not they are leaf nodes
numLeafs += getNumLeafs(secondDict[key])
else: numLeafs +=1
return numLeafs #获取树的层数
def getTreeDepth(myTree):
maxDepth = 0
#dict转化为list
firstSides = list(myTree.keys())
firstStr = firstSides[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':#test to see if the nodes are dictonaires, if not they are leaf nodes
thisDepth = 1 + getTreeDepth(secondDict[key])
else: thisDepth = 1
if thisDepth > maxDepth: maxDepth = thisDepth
return maxDepth def plotNode(nodeTxt, centerPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction',
xytext=centerPt, textcoords='axes fraction',
va="center", ha="center", bbox=nodeType, arrowprops=arrow_args ) def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0]-cntrPt[0])/2.0 + cntrPt[0]
yMid = (parentPt[1]-cntrPt[1])/2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30) def plotTree(myTree, parentPt, nodeTxt):#if the first key tells you what feat was split on
numLeafs = getNumLeafs(myTree) #this determines the x width of this tree
depth = getTreeDepth(myTree)
firstSides = list(myTree.keys())
firstStr = firstSides[0] #the text label for this node should be this
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff)
plotMidText(cntrPt, parentPt, nodeTxt)
plotNode(firstStr, cntrPt, parentPt, decisionNode)
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':#test to see if the nodes are dictonaires, if not they are leaf nodes
plotTree(secondDict[key],cntrPt,str(key)) #recursion
else: #it's a leaf node print the leaf node
plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD
#if you do get a dictonary you know it's a tree, and the first element will be another dict
#绘制决策树 样例1
def createPlot(inTree):
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) #no ticks
#createPlot.ax1 = plt.subplot(111, frameon=False) #ticks for demo puropses
#宽,高间距
plotTree.totalW = float(getNumLeafs(inTree))-3
plotTree.totalD = float(getTreeDepth(inTree))-2
# plotTree.totalW = float(getNumLeafs(inTree))
# plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -0.5/plotTree.totalW; plotTree.yOff = 1.0;
plotTree(inTree, (0.95,1.0), '')
plt.show() #绘制决策树 样例2
def createPlot1(inTree):
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) #no ticks
#createPlot.ax1 = plt.subplot(111, frameon=False) #ticks for demo puropses
#宽,高间距
plotTree.totalW = float(getNumLeafs(inTree))-4.5
plotTree.totalD = float(getTreeDepth(inTree)) -3
plotTree.xOff = -0.5/plotTree.totalW; plotTree.yOff = 1.0;
plotTree(inTree, (1.0,1.0), '')
plt.show() #绘制树的根节点和叶子节点(根节点形状:长方形,叶子节点:椭圆形)
#def createPlot():
# fig = plt.figure(1, facecolor='white')
# fig.clf()
# createPlot.ax1 = plt.subplot(111, frameon=False) #ticks for demo puropses
# plotNode('a decision node', (0.5, 0.1), (0.1, 0.5), decisionNode)
# plotNode('a leaf node', (0.8, 0.1), (0.3, 0.8), leafNode)
# plt.show() def retrieveTree(i):
listOfTrees =[{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}},
{'no surfacing': {0: 'no', 1: {'flippers': {0: {'head': {0: 'no', 1: 'yes'}}, 1: 'no'}}}}
]
return listOfTrees[i] #thisTree = retrieveTree(0)
#createPlot(thisTree)
#createPlot()
#myTree = retrieveTree(0)
#numLeafs =getNumLeafs(myTree)
#treeDepth =getTreeDepth(myTree)
#print(u"叶子节点数目:%d"% numLeafs)
#print(u"树深度:%d"%treeDepth)
绘制决策树
# -*- coding: utf-8 -*-
"""
Created on Wed Aug 15 14:16:59 2018 @author: weixw
"""
import myCart as mc
if __name__ == '__main__':
import treePlotter as tp
dataSet = mc.loadCSV("dataSet.csv")
myTree = mc.createTree(dataSet, evaluationFunc=gini)
print(u"myTree:%s"%myTree)
#绘制决策树
print(u"绘制决策树:")
tp.createPlot1(myTree)
decisionTree = mc.buildDecisionTree(dataSet, evaluationFunc=gini)
testData = [5.9,3,4.2,1.75]
r = mc.classify(testData, decisionTree)
print(u"分类后测试结果:")
print(r)
print()
mc.prune(decisionTree, 0.4)
r1 = mc.classify(testData, decisionTree)
print(u"剪枝后测试结果:")
print(r1)
测试代码
运行结果
为什么我要再写个createTree(dataSet, evaluationFunc=gini)函数,是因为绘制决策树createPlot1(myTree)输入参数需要是json结构数据。

将生成的决策树变为可视图形,这样更直观。
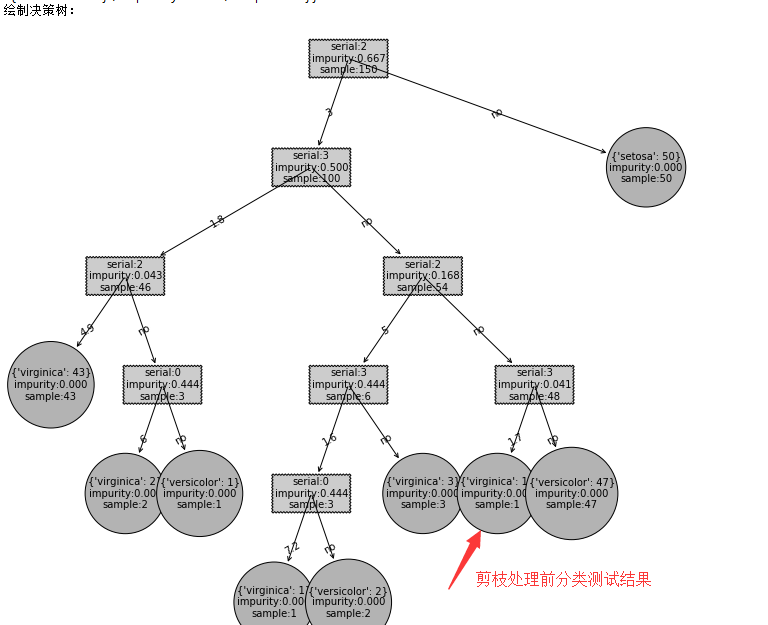
当然,也可以将自定义树对象信息打印出来,我在代码里已加入打印语句。
打印结果如下,因为屏幕的原因,没有全部粘贴出来,大家可以对照决策树绘制图,这样可以相互印证,加深理解。

在未做剪枝处理时的分类测试结果如下:
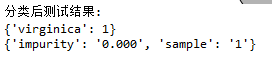
剪枝处理后的分类测试结果:
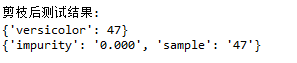
可以看出,{'versicolor': 47}取代了父结点serial:3,成为新的叶子结点。

参考文献
《统计学习方法》
《机器学习实战》
不要让懒惰占据你的大脑,不要让妥协拖垮你的人生。青春就是一张票,能不能赶上时代的快车,你的步伐掌握在你的脚下。
机器学习之决策树三-CART原理与代码实现的更多相关文章
- 机器学习之决策树一-ID3原理与代码实现
决策树之系列一ID3原理与代码实现 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/9429257.html 应用实 ...
- 图机器学习(GML)&图神经网络(GNN)原理和代码实现(前置学习系列二)
项目链接:https://aistudio.baidu.com/aistudio/projectdetail/4990947?contributionType=1 欢迎fork欢迎三连!文章篇幅有限, ...
- 机器学习技法-决策树和CART分类回归树构建算法
课程地址:https://class.coursera.org/ntumltwo-002/lecture 重要!重要!重要~ 一.决策树(Decision Tree).口袋(Bagging),自适应增 ...
- 机器学习:决策树(CART 、决策树中的超参数)
老师:非参数学习的算法都容易产生过拟合: 一.决策树模型的创建方式.时间复杂度 1)创建方式 决策树算法 既可以解决分类问题,又可以解决回归问题: CART 创建决策树的方式:根据某一维度 d 和某一 ...
- 机器学习之决策树二-C4.5原理与代码实现
决策树之系列二—C4.5原理与代码实现 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/9435712.html I ...
- 机器学习实战---决策树CART回归树实现
机器学习实战---决策树CART简介及分类树实现 一:对比分类树 CART回归树和CART分类树的建立算法大部分是类似的,所以这里我们只讨论CART回归树和CART分类树的建立算法不同的地方.首先,我 ...
- 机器学习之KNN原理与代码实现
KNN原理与代码实现 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/9670187.html 1. KNN原理 K ...
- 机器学习之AdaBoost原理与代码实现
AdaBoost原理与代码实现 本文系作者原创,转载请注明出处: https://www.cnblogs.com/further-further-further/p/9642899.html 基本思路 ...
- 机器学习之决策树(ID3)算法与Python实现
机器学习之决策树(ID3)算法与Python实现 机器学习中,决策树是一个预测模型:他代表的是对象属性与对象值之间的一种映射关系.树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每 ...
随机推荐
- Python数据结构应用6——树
数据结构中的树的结点和机器学习中决策树的结点有一个很大的不同就是,数据结构中的树的每个叶结点都是独立的. 树的高度(Height)指叶结点的最大层树(不包含根结点) 一.树的建立 树可以这样定义:一棵 ...
- 你可能忽略的js类型转换
前言 相信刚开始了解js的时候,都会遇到 2 == '2',但 1+2 == 1+'2'为false的情况.这时候应该会是一脸懵逼的状态,不得不感慨js弱类型的灵活让人发指,隐式类型转换就是这么猝不及 ...
- UR机械臂运动学正逆解方法
最近几个月因为工作接触到了机械臂的项目,突然对机械臂运动方法产生了兴趣,也就是如何控制机械臂的位置和姿态.借用一张网上的图片,应该是ur5的尺寸.我用到的是ur3机械臂,除了尺寸不一样,各关节结构和初 ...
- Robot Framework源码解析(2) - 执行测试的入口点
我们再来看 src/robot/run.py 的工作原理.摘录部分代码: from robot.conf import RobotSettings from robot.model import Mo ...
- koa+mysql+vue+socket.io全栈开发之前端篇
React 与 Vue 之间的对比,是前端的一大热门话题. vue 简易上手的脚手架,以及官方提供必备的基础组件,比如 vuex,vue-router,对新手真的比较友好:react 则把这些都交给社 ...
- [日志分析] Access Log 日志分析
0x00.前言: 如何知道自己所在的公司或单位是否被入侵了?是没人来“黑”,还是因自身感知能力不足,暂时还没发现?入侵检测是每个安全运维人员都要面临的严峻挑战.安全无小事,一旦入侵成功,后果不堪设想. ...
- Hadoop大数据部署
Hadoop大数据部署 一. 系统环境配置: 1. 关闭防火墙,selinux 关闭防火墙: systemctl stop firewalld systemctl disable firewalld ...
- windows粘贴板操作-自己的应用和windows右键互动
一.粘贴板操作函数 BOOL OpenClipboard(HWND hWnd);参数 hWnd 是打开剪贴板的窗口句柄,成功返回TRUE,失败返回FALSE BOOL CloseClipboard() ...
- 补习系列(16)-springboot mongodb 数据库应用技巧
目录 一.关于 MongoDB 二.Spring-Data-Mongo 三.整合 MongoDB CRUD A. 引入框架 B. 数据库配置 C. 数据模型 D. 数据操作 E. 自定义操作 四.高级 ...
- DSAPI 提取中间文本(字符串)
提取中间文本(源文本 As String, 前导文本 As String, 结束文本 As String, Optional 移除文本 As String = "", Option ...