关于Python深浅拷贝
拷贝:
说明:原则上就是把数据分离出来,复制其数据,并以后修改互不影响。
何来深浅拷贝的说法?
深浅拷贝的“深”和“浅”可以理解为从变量到硬盘上的物理存储介质之间的层次的多少。
下面用一个示例来解释浅拷贝:
#Author : Kelvin
#Date : 2019/1/5 0:41
import copy
#浅拷贝的第一种方式(使用对象自身的copy方法)
li1=[["bob","alvin"],"kelvin","alex"]
li2=li1.copy() #调用列表自身方法拷贝
li2[1]="kelvin-sb" #修改li2的第二个元素
print("li1: ",li1)
print("li2: ",li2)
#运行结果(只有li2改变了):
#li1: [['bob', 'alvin'], 'kelvin', 'alex']
# li2: [['bob', 'alvin'], 'kelvin-sb', 'alex']
print("-------"*6)
li2[0][0]="bob-sb" #修改li2的第一个元素中的第一个元素
print("li1: ",li1)
print("li2: ",li2)
#运行结果(li1和li2都改变了):
# li1: [['bob-sb', 'alvin'], 'kelvin', 'alex']
# li2: [['bob-sb', 'alvin'], 'kelvin-sb', 'alex'] #浅拷贝的第二种方式(使用copy模块的copy方法)
li1=[["bob","alvin"],"kelvin","alex"]
li2=copy.copy(li1) #调用copy模块方法拷贝
li2[1]="kelvin-sb" #修改li2的第二个元素
print("li1: ",li1)
print("li2: ",li2)
#运行结果(只有li2改变了):
#li1: [['bob', 'alvin'], 'kelvin', 'alex']
# li2: [['bob', 'alvin'], 'kelvin-sb', 'alex']
print("-------"*6)
li2[0][0]="bob-sb" #修改li2的第一个元素中的第一个元素
print("li1: ",li1)
print("li2: ",li2)
#运行结果(li1和li2都改变了):
# li1: [['bob-sb', 'alvin'], 'kelvin', 'alex']
# li2: [['bob-sb', 'alvin'], 'kelvin-sb', 'alex']
对于上面浅拷贝的示例我们可以看到,当浅拷贝之后,修改其中一个不可变类型元素(数字,字符串等),拷贝前后对象之间互不干扰,没有影响,但是当修改了可变类型元素(列表,字典等),拷贝前后对象均发生改变。其中的原因就是因为不可变类型直接存储在物理硬盘上,而可变类型则会包含多个不可变类型而形成一个独立的内存地址,也就是多了一“层”。下面用图示具体说明:
只改变“kelvin”图示:
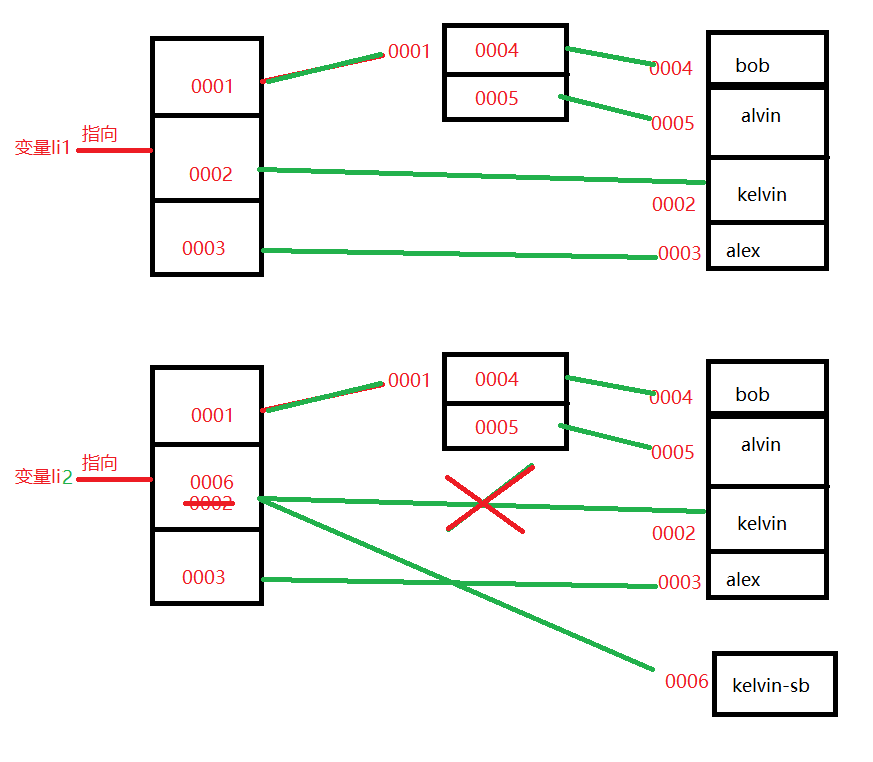
改变li1第一个元素(列表)中的值图示:
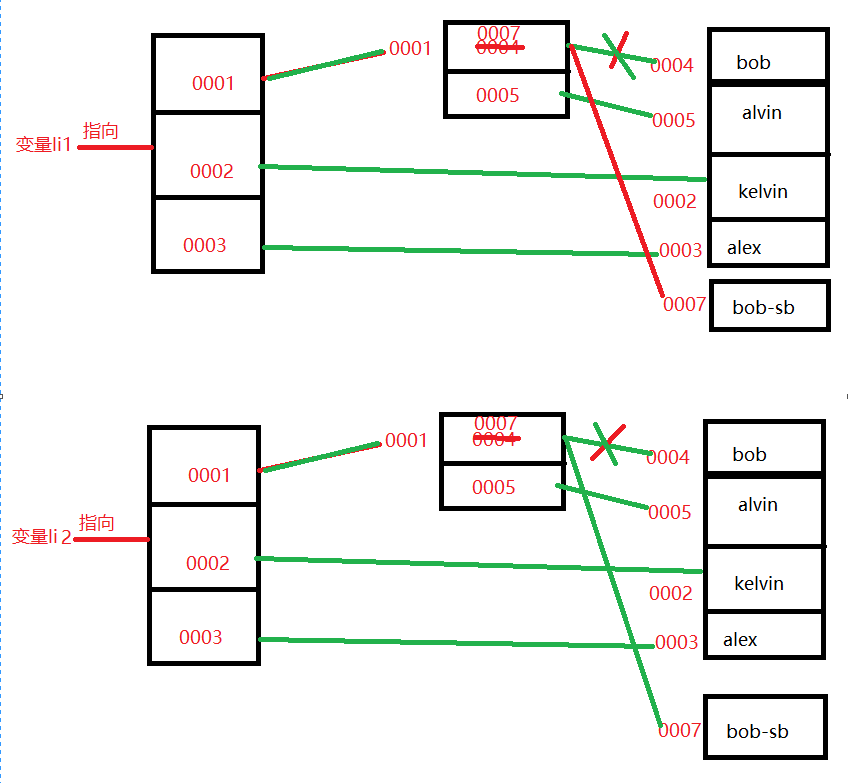
**注:认真理清图示表达的含义,理解好深浅的内涵。
下面再通过一个示例来了解深拷贝:
import copy
#深拷贝只能调用copy模块的deepcopy方法
li1=[["bob","alvin"],"kelvin","alex"]
li2=copy.deepcopy(li1) #调用copy模块方法拷贝
li2[1]="kelvin-sb" #修改li2的第二个元素
print("li1: ",li1)
print("li2: ",li2)
#运行结果(只有li2改变了):
#li1: [['bob', 'alvin'], 'kelvin', 'alex']
# li2: [['bob', 'alvin'], 'kelvin-sb', 'alex']
print("-------"*6)
li2[0][0]="bob-sb" #修改li2的第一个元素中的第一个元素
print("li1: ",li1)
print("li2: ",li2)
#运行结果(只有li2改变了):
# li1: [['bob', 'alvin'], 'kelvin', 'alex']
# li2: [['bob-sb', 'alvin'], 'kelvin-sb', 'alex']
深拷贝相比较浅拷贝就容易理解的多,因为深拷贝就是完完全全的拷贝,拷贝前后的两个对象占有独立的内存空间,不存在共享空间,因此拷贝前后对象相互改变无影响。
最后来一个深浅拷贝的应用实例(随意实例):
#Author : Kelvin
#Date : 2019/1/5 1:37 import copy
kelvin=["kelvin",123,[10000,]] #户主 卡号 余额
wife=kelvin.copy() #给媳妇共享银行卡
wife[1]=234 #设置媳妇卡号
wife[0]="peiqi" #媳妇银行卡户主
wife[2][0]-=2000 #媳妇消费2000元
print(kelvin)
print(wife)
print("------"*6)
# 输出结果(实现共享账户):
# ['kelvin', 123, [8000]]
# ['peiqi', 234, [8000]] #小三账户不能浅拷贝,因为媳妇会发现账户少钱
xiaosan=copy.deepcopy(kelvin)
xiaosan[0]="sanzi" #小三银行卡户主
xiaosan[1]=666 #设置小三卡号
xiaosan[2][0]-=3000 #小三消费3000元
print(kelvin)
print(xiaosan)
# 输出结果(老婆不会发现):
# ['kelvin', 123, [10000]]
# ['sanzi', 666, [7000]]
关于Python深浅拷贝的更多相关文章
- Python开发【第二章】:Python深浅拷贝剖析
Python深浅拷贝剖析 Python中,对象的赋值,拷贝(深/浅拷贝)之间是有差异的,如果使用的时候不注意,就可能产生意外的结果. 下面本文就通过简单的例子介绍一下这些概念之间的差别. 一.对象赋值 ...
- 小学生都能学会的python(深浅拷贝)
小学生都能学会的python(深浅拷贝) join() 把列表中的每一项用字符串拼接起来 # lst = ["汪峰", "吴君如", "李嘉欣&quo ...
- 【0806 | Day 9】三张图带你了解数据类型分类和Python深浅拷贝
一.数据类型分类 二.Python深浅拷贝
- 底层剖析Python深浅拷贝
底层剖析Python深浅拷贝 拷贝的用途 拷贝就是copy,目的在于复制出一份一模一样的数据.使用相同的算法对于产生的数据有多种截然不同的用途时就可以使用copy技术,将copy出的各种副本去做各种不 ...
- 关于python深浅拷贝的个人浅见
起初,关于python的深浅拷贝,总是习惯去用传值传址的方式去考虑,发现总是get不到规律,容易记混. python有着高度自治的内存管理,而不可变对象的内存分配,则是能省则省,就是说,无论用什么拷贝 ...
- python深浅拷贝与赋值
初学编程的小伙伴都会对于深浅拷贝的用法有些疑问,今天我们就结合python变量存储的特性从内存的角度来谈一谈赋值和深浅拷贝~~~ 预备知识一——python的变量及其存储 在详细的了解python中赋 ...
- python 深浅拷贝 进阶
主要理解新与旧究竟在哪里 这样也就理解了 深浅拷贝 先说说赋值,事实上python中的赋值事实上是赋值了一个引用.比如: foo1=1.0 foo2=foo1 用操作符is推断时.你能够发现结果是tr ...
- python深浅拷贝&垃圾回收&上下文管理(with语句)
深浅拷贝 在Python中使用copy模块用于对象的拷贝操作. 该模块提供了两个主要的方法:浅拷贝 copy.copy() 深拷贝 copy.deepcopy() 1.浅拷贝(copy) 浅拷贝: 不 ...
- python 深浅拷贝 for循环删除
###########################总结########################### 1. 基础数据类型补充 大多数的基本数据类型的知识.已经学完了 a='aaaa' ls ...
随机推荐
- github代码搜索技巧
github是一个非常丰富的资源,但是面对这丰富的资源很多人不知到怎么使用,更谈不上怎么贡献给他,我们需要使用github就要学习使用他的方法,学会了使用的方法,接受了他的这种观点我们才会慢慢的给他贡 ...
- Win7 系统记事本乱码及cmd闪退解决办法
打开控制面板,点击时钟.语言和区域 中文(简体)改为英语(英国),然后重启电脑,重启电脑之后,继续此操作,在把英语(英国)改为中文(简体),再次重启电脑,就OK了.
- MySQL 慢查询日志总结
慢查询日志概念 MySQL的慢查询日志是MySQL提供的一种日志记录,它用来记录在MySQL中响应时间超过阀值的语句,具体指运行时间超过long_query_time值的SQL,则会被记录到慢查询日志 ...
- bzoj 4501 旅行
01分数规划+最大权闭合子图 倒拓扑序处理每个节点 $$f[x]=\frac{\sum{f[v]}}{n}+1$$ 二分答案$val$ 只需要判断是否存在$\sum{f[v]}+1-val>0$ ...
- ajax封装函数和表单序列化
//表单序列化function iSerialize(form){ var parts={}; for(var i=0;i<form.elements.length;i++){ var file ...
- mysql输入中文出现ERROR 1366
MySQL输入中文出现如下错误: ERROR 1366: 1366: Incorrect string value: '\xE6\xB0\xB4\xE7\x94\xB5...' for column ...
- mysql5.7连接不上可能的问题(针对新安装的mysql5.7可能出现的问题)
"ERROR 2003 (HY000): Can't connect to MySQL server on 'localhost' (10061)" 今天刚刚安装好的mysql5. ...
- OKHttp源码学习--HttpURLConnection HttpClient OKHttp Get and post Demo用法对比
1.HttpURLConnection public class HttpURLConnectionGetAndPost { private String urlAddress = "xxx ...
- 让你分分钟理解 JavaScript 闭包
闭包,是 Javascript 比较重要的一个概念,对于初学者来讲,闭包是一个特别抽象的概念,特别是 ECMAScript 规范给的定义,如果没有实战经验,很难从定义去理解它.因此,本文不会对闭包的概 ...
- javascript正则表达式学习(二)--位置匹配
文章首发于sau交流学习社区 一.前言 正则表达式是匹配模式,要么是匹配字符,要么匹配位置. 其实在开发中很少用到匹配位置,本篇文章主要包含: 二.什么是位置 位置:相邻字符之间的位置. 三.如何匹配 ...