class-k近邻算法kNN
1 k近邻算法
k nearest neighbor,k-NN,是一种基本分类与回归的方法,输入为实例的特征向量——对应空间的点,输出为实例的类别,可取多类。kNN假定一个训练集,实例类别已确定,分类时,对新的实例根据其k个最近邻训练集实例的类别,通过多数表决的方式进行预测。不具有显式学习过程。利用训练集对特征空间划分,并作为其分类的model。三要素是k值的选择,距离度量,分类决策规则。1968年Cover和Hart提出。
算法:

I为指示函数,即当yi=cj时I=1,否则I=0
2 模型
kNN的model对应于特征空间的划分,有三个要素:k选择,距离度量,分类决策。对于每个实例x,当三要素确定后,就能得到其所在的对特征空间的划分单元cell。
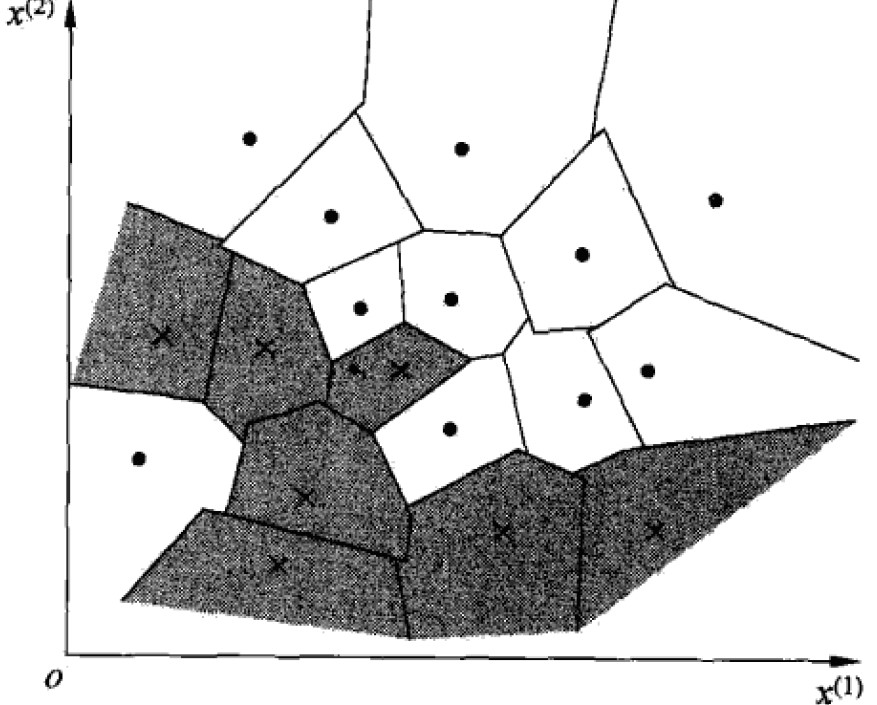
2.1 距离测量
特征空间中,两个实例点的距离其实是相似度的反应,距离越近越相似。一般对于特征空间Rn,常用欧氏距离(Euclidean distance),也可以更一般的Lp距离或Minkowski距离。
几种距离度量方法:



2.2 k值选择
k选择较小的时候,对实例较小的邻域进行预测,近似误差(approximation error)会减小,只有与输入实例较近的训练实例才会起作用。缺点是估计误差(estimation error)会增大,预测结果对近邻的实例点会非常敏感。总之,k值减小,意味着模型复杂度增大,容易发生过拟合。
同样的,较大k值意味着较大邻域训练,近似误差增大,估计误差减少,离实例点较远的点也会对预测起作用,使预测发生错误,意味着模型过于简单。
在实际应用中,常取较小的k值,采用交叉验证来选取最优 k值。
2.3 分类决策规则
kNN采用多数表决规则(majority voting rule):由输入实例的k个近邻的训练实例中,多数类决定输入实例的类别。
多数表决规则数学含义是经验风险最小化:
证明:
若loss function是0-1损失函数,分类函数为:f:Rn——>{c1,c2,…,ck}
误分类率是:P(Y!=f(X)) = 1-P(Y=f(X))

可以看到误分类率最小就是经验风险最小,就要 使得右边Sigma(I(yi=cj))最大,即多数表决!
3 kNN的实现——kd树
KNN最简单的实现是线性扫描(linear scan),要求计算输入实例与训练实例的每一个距离,当训练集很大时,这样扫描十分耗时,因此考虑到如何对特征空间和维数大,容量大的训练数据进行快速的搜索,十分必要。可以考虑特殊的存储结构训练数据,以减少计算距离的次数,比如kd树(kd tree)方法。
3.1 构造kd树
kd树是一种对k维空间实例点进行存储以便于快速检索的数据结构。kd树是二叉树,表示对k维空间的一个划分(partition)。构造kd树相当于不断地用垂直于坐标轴的超平面将k维空间划分,构成一系列k维超矩形区域,kd树的每个节点对应于一个k维超矩形区域。
构造方法:首先构造根节点——对应于k维空间中包含所有实例点的超矩形区域;通过递归方法,不断对k维空间进行划分生成子节点,在此超矩形区域上选择一个坐标轴和一个切分点,确定一个超平面,这个超平面通过选定的切分点并垂直于选定的坐标轴,将当前超矩形区域切分为左右两个子区域(子节点),这时实例被分到两个子区域,这个过程持续到区域内没有实例时终止,终止时节点为叶子结点。在此过程中将实例保存在相应的结点上。
通常,依次选择坐标轴对空间切分,选择训练实例点在选定坐标轴的中位数(median)为切分点,得到平衡kd树——但是不一定是搜索效率最优。
平衡kd树算法:


针对高维数据需要对每一维都进行二分,更好的方法是对方差最大的特征进行比较和划分。(具体可看文末的博文推荐)
3.2 kd树搜索
利用kd树进行k近邻搜索
给定一个目标点,搜索其最近邻。首先找到包含该目标点的叶子结点,然后从叶子结点出发,一次回退到父结点;不断查找与目标结点最近邻的结点,当确定不可能存在更近的结点时终止。这样搜索就会限制在空间的局部区域上,效率大为提高。
包含目标结点的叶子结点对应包含目标点的最小超矩形区域,以此叶子结点的实例点当做当前最近点,目标点最近邻一定在以目标点为中心并通过当前最近点的超球体内部。然后返回当前结点的父节点,如果父节点的另一子节点超矩形区域与超球相交,那么就在相交区域寻找与目标点的更近实例点,若存在,就当做当前最近点,算法转到更上一级的父节点,继续迭代上述过程,父节点的另一子节点超矩形区域与超球体不想交,或不存在当前最近点更近的点,则停止搜索。
kd树最近邻搜索算法:


算法复杂度为O(logN),而不是之前的O(N),更适合实例数目远远大于空间维数的情况,当二者接近时效率将降低为线性扫描
推荐读一读这篇博文,比书上写的更通俗一些。
K-D Tree原理及实现
class-k近邻算法kNN的更多相关文章
- k近邻算法(KNN)
k近邻算法(KNN) 定义:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别. from sklearn.model_selection ...
- 机器学习(四) 分类算法--K近邻算法 KNN (上)
一.K近邻算法基础 KNN------- K近邻算法--------K-Nearest Neighbors 思想极度简单 应用数学知识少 (近乎为零) 效果好(缺点?) 可以解释机器学习算法使用过程中 ...
- 一看就懂的K近邻算法(KNN),K-D树,并实现手写数字识别!
1. 什么是KNN 1.1 KNN的通俗解释 何谓K近邻算法,即K-Nearest Neighbor algorithm,简称KNN算法,单从名字来猜想,可以简单粗暴的认为是:K个最近的邻居,当K=1 ...
- 机器学习(四) 机器学习(四) 分类算法--K近邻算法 KNN (下)
六.网格搜索与 K 邻近算法中更多的超参数 七.数据归一化 Feature Scaling 解决方案:将所有的数据映射到同一尺度 八.scikit-learn 中的 Scaler preprocess ...
- k近邻算法(knn)的c语言实现
最近在看knn算法,顺便敲敲代码. knn属于数据挖掘的分类算法.基本思想是在距离空间里,如果一个样本的最接近的k个邻居里,绝大多数属于某个类别,则该样本也属于这个类别.俗话叫,"随大流&q ...
- 《机器学习实战》---第二章 k近邻算法 kNN
下面的代码是在python3中运行, # -*- coding: utf-8 -*- """ Created on Tue Jul 3 17:29:27 2018 @au ...
- 最基础的分类算法-k近邻算法 kNN简介及Jupyter基础实现及Python实现
k-Nearest Neighbors简介 对于该图来说,x轴对应的是肿瘤的大小,y轴对应的是时间,蓝色样本表示恶性肿瘤,红色样本表示良性肿瘤,我们先假设k=3,这个k先不考虑怎么得到,先假设这个k是 ...
- 07.k近邻算法kNN
1.将数据分为测试数据和预测数据 2.数据分为data和target,data是矩阵,target是向量 3.将每条data(向量)绘制在坐标系中,就得到了一系列的点 4.根据每条data的targe ...
- 机器学习随笔01 - k近邻算法
算法名称: k近邻算法 (kNN: k-Nearest Neighbor) 问题提出: 根据已有对象的归类数据,给新对象(事物)归类. 核心思想: 将对象分解为特征,因为对象的特征决定了事对象的分类. ...
- 机器学习(1)——K近邻算法
KNN的函数写法 import numpy as np from math import sqrt from collections import Counter def KNN_classify(k ...
随机推荐
- vue2.0使用slot插槽分发内容
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" ...
- 【SSH框架】之Spring系列(一)
微信公众号:compassblog 欢迎关注.转发,互相学习,共同进步! 有任何问题,请后台留言联系! 1.前言 前面更新过几篇关于 Struts2 框架和 Hibernate 框架的文章,但鉴于这两 ...
- hbuilder ios 打包失败,无法导入p12证书的解决方案
问题描述: 在profile文件和私钥证书通过hbuilder ios 打包成功过的前提下,突然遇到打包失败的问题,问题详情是无法导入p12证书. 探索过程: 本着遇到问题先自省的态度,重复打包了几次 ...
- AnnotationUtils
/** * 查询类中符合指定annotation的属性信息 * @param objCls 实体类 * @param annCls 注解类 * @return HashMap<实体属性名, An ...
- linux shell 执行远程命令
我在本地的shell脚本中,想要直接执行远程服务器的一个shell脚本: ssh -l root 192.168.1.1 "/data/t.sh" 记得提前给远程服务器的 /dat ...
- 用mount挂载远程服务器网络硬盘
环境: 服务器:192.168.20.204 客户端:192.168.20.203 1. 在服务器配置/etc/export 添加可以共享的文件夹和允许的客户端地址 /home/dir 192.16 ...
- CentOS 7 安装 Nginx 反向代理 node
安装 nginx yum install epel-release yum install nginx 配置 nginx sudo vim /etc/nginx/nginx.conf, 改成下面配置: ...
- Docker 中国官方镜像加速
参考:https://www.docker-cn.com/registry-mirror 通过 Docker 官方镜像加速,中国区用户能够快速访问最流行的 Docker 镜像.该镜像托管于中国大陆,本 ...
- 利用Jsonp实现跨域请求,spring MVC+JQuery
1 什么是Jsonp? JSONP(JSON with Padding)是数据格式JSON的一种"使用模式",可以让网页从别的网域要数据.另一个解决这个问题的新方法是跨来源资源共享 ...
- python requests库学习笔记(下)
1.请求异常处理 请求异常类型: 请求超时处理(timeout): 实现代码: import requestsfrom requests import exceptions #引入exc ...