.NET Core 网络数据采集 -- 使用AngleSharp做html解析
有这么一本Python的书: <<Python 网络数据采集>>

我准备用.NET Core及第三方库实现里面所有的例子.
这是第一部分, 主要使用的是AngleSharp: https://anglesharp.github.io/
(文章的章节书与该书是对应的)
第1章 初见网络爬虫
发送Http请求
在python里面这样发送http请求, 它使用的是python的标准库urllib:

在.NET Core里面, 你可以使用HttpClient, 相应的C#代码如下:
var client = new HttpClient();
HttpResponseMessage response = await client.GetAsync("http://pythonscraping.com/pages/page1.html");
response.EnsureSuccessStatusCode();
var responseBody = await response.Content.ReadAsStringAsync();
Console.WriteLine(responseBody);
return responseBody;
或者可以简写为:
var client = new HttpClient();
var responseBody = await client.GetStringAsync("http://pythonscraping.com/pages/page1.html");
Console.WriteLine(responseBody);
其结果如下:
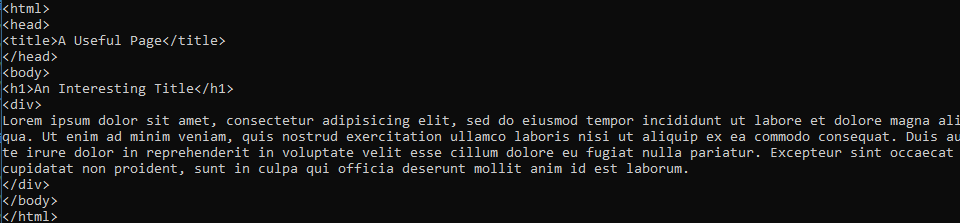
使用AngleSharp解析html源码
python里面可以使用BeautifulSoup或者MechanicalSoup等库对html源码进行解析.
而.NET Core可以使用AngleSharp, Html Agility Pack, DotnetSpider(国产, 也支持元素抽取).等库来操作Html文档.
这里我先使用的是AngleSharp, AngleSharp的解析库可以使用标准的W3C规范来解析HTML, MathML, XML, SVG和CSS. 它支持.NET Standard 1.0.
安装AngleSharp
通过Nuget即可: https://www.nuget.org/packages/AngleSharp/
Install-Package AngleSharp
或者dotnet-cli:
dotnet add package AngleSharp
AngleSharp的一个简单例子
下面这个例子(1.2.2)是把页面中h1元素的内容显示出来.
书中Python的代码:

下面是.NET Core的C#代码:
public static async Task ReadWithAngleSharpAsync()
{
var htmlSourceCode = await SendRequestWithHttpClientAsync();
var parser = new HtmlParser();
var document = await parser.ParseAsync(htmlSourceCode); Console.WriteLine($"Serializing the (original) document: {document.QuerySelector("h1").OuterHtml}");
Console.WriteLine($"Serializing the (original) document: {document.QuerySelector("html > body > h1").OuterHtml}");
}
在这里AngleSharp首先需要创建一个可以循环使用的HtmlParser(Html解析器), 然后使用解析器解析html源码即可: parser.Parse() 或者异步版本 parser.ParseAsync().
解析返回对象的类型是IHtmlDocument, 里面是解析好的DOM. 其中DOM是和AngleSharp里的类这样对应的:
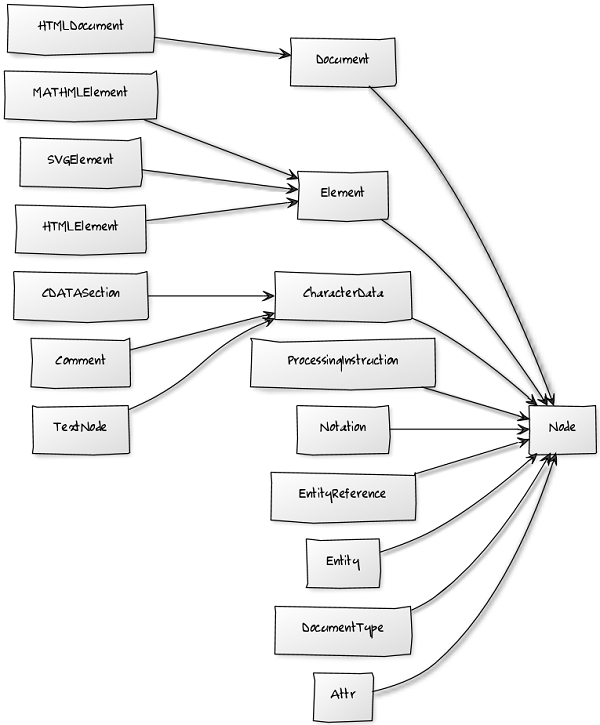
这个图其实是老一点的版本, 新版本的DOM模型是稍微有点不同的, 不过你只要理解这个意思就行...
AngleSharp有很多特点, 但是最重要的特点就是它支持querySelector()和querySelectorAll()方法, 就像DOM的方法一样.
上面这个例子里, 其html的结构大致如下:

所以针对返回的IHtmlDocument对象document, 我们使用document.QuerySelector("h1").OuterHtml, 就可以返回h1的OuterHtml. 而使用document.QuerySelector("html > body > h1").OuterHtml 也是同样的效果, 因为标准的CSS选择器是都支持的.
QuerySelector()返回的是一个/0个元素, 相当于Linq的FirstOrDefault().
其运行结果如下:

异常情况处理
发送Http请求之后, 可能会发生错误, 例如网页不存在(或者请求时出错), 服务器不存在等等.
针对这些情况, .NET Core程序会返回HTTP错误, 可能是404也可能是500等. 但是所有的类型HttpClient都会抛出HttpRequestException, 我们可以这样处理这种异常:
public static async Task ResponseWithErrorsAsync()
{
try
{
var client = new HttpClient();
var responseBody = await client.GetStringAsync("http://notexistwebsite");
Console.WriteLine(responseBody);
}
catch (HttpRequestException e)
{
Console.ForegroundColor = ConsoleColor.Red;
Console.WriteLine("\nException Caught!");
Console.WriteLine("Message :{0} ", e.Message);
}
}

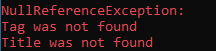
但是即使网页获取成功了, 网页上的内容也并非完全是我们所期待的, 仍可能会抛出异常. 比如说你想要找的标签不存在, 那么就会返回null, 然后再调用改标签的属性, 就会发生NullReferenceException.
所以这种情况可以捕获NullReferenceException, 也可以使用代码判断:
public static async Task ReadNonExistTagAsync()
{
var htmlSourceCode = await SendRequestWithHttpClientAsync();
var parser = new HtmlParser();
var document = await parser.ParseAsync(htmlSourceCode); var nonExistTag = document.QuerySelector("h8");
Console.WriteLine(nonExistTag);
Console.WriteLine($"nonExistTag is null: {nonExistTag is null}"); try
{
Console.WriteLine(nonExistTag.QuerySelector("p").OuterHtml);
}
catch (NullReferenceException)
{
Console.ForegroundColor = ConsoleColor.Red;
Console.WriteLine("Tag was not found");
}
}

完整的例子:
public static async Task RunAllAsync()
{
Console.ForegroundColor = ConsoleColor.Red;
async Task<string> GetTileAsync(string uri)
{
var httpClient = new HttpClient();
try
{
var responseHtml = await httpClient.GetStringAsync(uri);
var parser = new HtmlParser();
var document = await parser.ParseAsync(responseHtml);
var tagContent = document.QuerySelector("body > h8").TextContent;
return tagContent;
}
catch (HttpRequestException e)
{
Console.WriteLine($"{nameof(HttpRequestException)}:");
Console.WriteLine("Message :{0} ", e.Message);
return null;
}
catch (NullReferenceException)
{
Console.WriteLine($"{nameof(NullReferenceException)}:");
Console.WriteLine("Tag was not found");
return null;
}
} var title = await GetTileAsync("http://www.pythonscraping.com/pages/page1.html");
if (string.IsNullOrWhiteSpace(title))
{
Console.WriteLine("Title was not found");
}
else
{
Console.ForegroundColor = ConsoleColor.Green;
Console.WriteLine(title);
}
}
第2章 复杂HTML解析
首先我把请求Http返回HTML代码的那部分封装成了一个方法以便复用:
public static async Task<string> GetHtmlSourceCodeAsync(string uri)
{
var httpClient = new HttpClient();
try
{
var htmlSource = await httpClient.GetStringAsync(uri);
return htmlSource;
}
catch (HttpRequestException e)
{
Console.ForegroundColor = ConsoleColor.Red;
Console.WriteLine($"{nameof(HttpRequestException)}: {e.Message}");
return null;
}
}
CSS是网络爬虫的福音, 下面这两个元素在页面中可能会出现很多次:

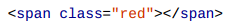
我们可以使用AngleSharp里面的QuerySelectorAll()方法把所有符合条件的元素都找出来, 返回到一个结果集合里.
public static async Task FindGreenClassAsync()
{
const string url = "http://www.pythonscraping.com/pages/warandpeace.html";
var html = await GetHtmlSourceCodeAsync(url);
if (!string.IsNullOrWhiteSpace(html))
{
var parser = new HtmlParser();
var document = await parser.ParseAsync(html);
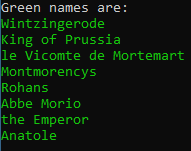
var nameList = document.QuerySelectorAll("span > .green"); Console.WriteLine("Green names are:");
Console.ForegroundColor = ConsoleColor.Green;
foreach (var item in nameList)
{
Console.WriteLine(item.TextContent);
}
}
else
{
Console.WriteLine("No html source code returned.");
}
}
非常简单, 和DOM的标准操作是一样的.
如果只需要元素的文字部分, 那么就是用其TextContent属性即可.
再看个例子
1. 找出页面中所有的h1, h2, h3, h4, h5, h6元素
2. 找出class为green或red的span元素.
public static async Task FindByAttributeAsync()
{
const string url = "http://www.pythonscraping.com/pages/warandpeace.html";
var html = await GetHtmlSourceCodeAsync(url);
if (!string.IsNullOrWhiteSpace(html))
{
var parser = new HtmlParser();
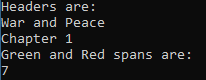
var document = await parser.ParseAsync(html); var headers = document.QuerySelectorAll("*")
.Where(x => new[] { "h1", "h2", "h3", "h4", "h5", "h6" }.Contains(x.TagName.ToLower()));
Console.WriteLine("Headers are:");
PrintItemsText(headers); var greenAndRed = document.All
.Where(x => x.TagName == "span" && (x.ClassList.Contains("green") || x.ClassList.Contains("red")));
Console.WriteLine("Green and Red spans are:");
PrintItemsText(greenAndRed); var thePrinces = document.QuerySelectorAll("*").Where(x => x.TextContent == "the prince");
Console.WriteLine(thePrinces.Count());
}
else
{
Console.WriteLine("No html source code returned.");
} void PrintItemsText(IEnumerable<IElement> elements)
{
foreach (var item in elements)
{
Console.WriteLine(item.TextContent);
}
}
}
这里我们可以看到QuerySelectorAll()的返回结果可以使用Linq的Where方法进行过滤, 这样就很强大了.
TagName属性就是元素的标签名.
此外, 还有一个document.All, All属性是该Document所有元素的集合, 它同样也支持Linq.
(该方法中使用了一个本地方法).
由于同时支持CSS选择器和Linq, 所以抽取元素的工作简单多了.
导航树
一个页面, 它的结构可以是这样的:

这里面有几个概念:
子标签和后代标签.
子标签是父标签的下一级, 而后代标签则是指父标签下面所有级别的标签.
tr是table的子标签, tr, th, td, img都是table的后代标签.
使用AngleSharp, 找出子标签可以使用.Children属性. 而找出后代标签, 可以使用CSS选择器.
兄弟标签
找到前一个兄弟标签使用.PreviousElementSibling属性, 后一个兄弟标签是.NextElementSibling属性.
父标签
.ParentElement属性就是父标签.
public static async Task FindDescendantAsync()
{
const string url = "http://www.pythonscraping.com/pages/page3.html";
var html = await GetHtmlSourceCodeAsync(url);
if (!string.IsNullOrWhiteSpace(html))
{
var parser = new HtmlParser();
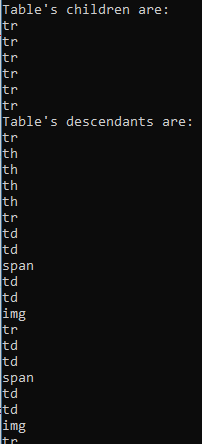
var document = await parser.ParseAsync(html); var tableChildren = document.QuerySelector("table#giftList > tbody").Children;
Console.WriteLine("Table's children are:");
foreach (var child in tableChildren)
{
System.Console.WriteLine(child.LocalName);
} var descendants = document.QuerySelectorAll("table#giftList > tbody *");
Console.WriteLine("Table's descendants are:");
foreach (var item in descendants)
{
Console.WriteLine(item.LocalName);
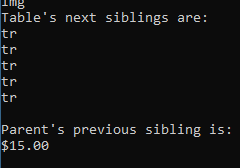
} var siblings = document.QuerySelectorAll("table#giftList > tbody > tr").Select(x => x.NextElementSibling);
Console.WriteLine("Table's descendants are:");
foreach (var item in siblings)
{
Console.WriteLine(item?.LocalName);
} var parentSibling = document.All.SingleOrDefault(x => x.HasAttribute("src") && x.GetAttribute("src") == "../img/gifts/img1.jpg")
?.ParentElement.PreviousElementSibling;
if (parentSibling != null)
{
Console.WriteLine($"Parent's previous sibling is: {parentSibling.TextContent}");
}
}
else
{
Console.WriteLine("No html source code returned.");
}
}
结果:
使用正则表达式
"如果你有一个问题打算使用正则表达式来解决, 那么现在你有两个问题了".
这里有一个测试正则表达式的网站: https://www.regexpal.com/
目前, AngleSharp支持通过CSS选择器来查找元素, 也可以使用Linq来过滤元素, 当然也可以通过多种方式使用正则表达式进行更复杂的查找动作.
关于正则表达式我就不介绍了. 直接看例子.
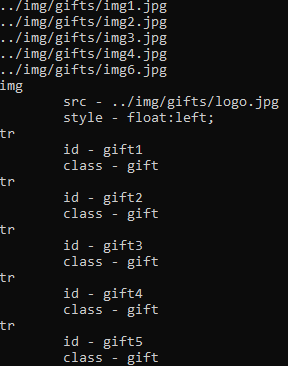
我想找到页面中所有的满足下列要求的图片, 其src的值以../img/gifts/img开头并且随后跟着数字, 然后格式为.jpg的图标.
public static async Task FindByRegexAsync()
{
const string url = "http://www.pythonscraping.com/pages/page3.html";
var html = await GetHtmlSourceCodeAsync(url);
if (!string.IsNullOrWhiteSpace(html))
{
var parser = new HtmlParser();
var document = await parser.ParseAsync(html); var images = document.QuerySelectorAll("img")
.Where(x => x.HasAttribute("src") && Regex.Match(x.Attributes["src"].Value, @"\.\.\/img\/gifts/img.*\.jpg").Success);
foreach (var item in images)
{
Console.WriteLine(item.Attributes["src"].Value);
} var elementsWith2Attributes = document.All.Where(x => x.Attributes.Length == );
foreach (var item in elementsWith2Attributes)
{
Console.WriteLine(item.LocalName);
foreach (var attr in item.Attributes)
{
Console.WriteLine($"\t{attr.Name} - {attr.Value}");
}
}
}
else
{
Console.WriteLine("No html source code returned.");
}
}
这个其实没有任何难度.
但从本例可以看到, 判断元素有没有一个属性可以使用HasAttribute("xxx")方法, 可以通过.Attributes索引来获取属性, 其属性值就是.Attributes["xxx"].Value.
如果不会正则表达式, 我相信多写的Linq的过滤代码也差不多能达到要求.
第3章 开始采集
遍历单个域名
就是几个应用的例子, 直接贴代码吧.
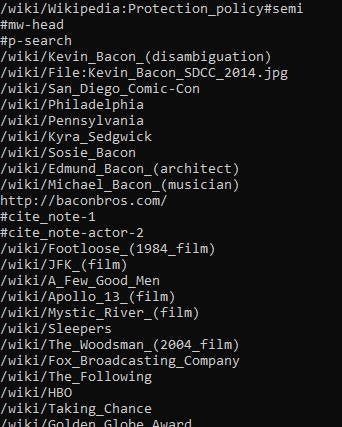
打印出一个页面内所有的超链接地址:
public static async Task TraversingASingleDomainAsync()
{
var httpClient = new HttpClient();
var htmlSource = await httpClient.GetStringAsync("http://en.wikipedia.org/wiki/Kevin_Bacon"); var parser = new HtmlParser();
var document = await parser.ParseAsync(htmlSource);
var links = document.QuerySelectorAll("a");
foreach (var link in links)
{
Console.WriteLine(link.Attributes["href"]?.Value);
}
}
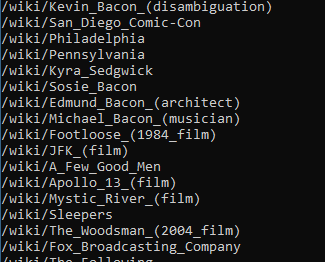
找出满足下列条件的超链接:
- 在id为bodyContent的div里
- url不包括分号
- url以/wiki开头
public static async Task FindSpecificLinksAsync()
{
var httpClient = new HttpClient();
var htmlSource = await httpClient.GetStringAsync("http://en.wikipedia.org/wiki/Kevin_Bacon"); var parser = new HtmlParser();
var document = await parser.ParseAsync(htmlSource);
var links = document.QuerySelector("div#bodyContent").QuerySelectorAll("a")
.Where(x => x.HasAttribute("href") && Regex.Match(x.Attributes["href"].Value, @"^(/wiki/)((?!:).)*$").Success);
foreach (var link in links)
{
Console.WriteLine(link.Attributes["href"]?.Value);
}
}
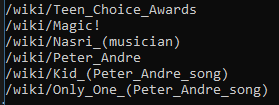
随机找到页面里面一个连接, 然后递归调用自己的方法, 直到主动停止:
private static async Task<IEnumerable<IElement>> GetLinksAsync(string uri)
{
var httpClient = new HttpClient();
var htmlSource = await httpClient.GetStringAsync($"http://en.wikipedia.org{uri}");
var parser = new HtmlParser();
var document = await parser.ParseAsync(htmlSource); var links = document.QuerySelector("div#bodyContent").QuerySelectorAll("a")
.Where(x => x.HasAttribute("href") && Regex.Match(x.Attributes["href"].Value, @"^(/wiki/)((?!:).)*$").Success);
return links;
} public static async Task GetRandomNestedLinksAsync()
{
var random = new Random();
var links = (await GetLinksAsync("/wiki/Kevin_Bacon")).ToList();
while (links.Any())
{
var newArticle = links[random.Next(, links.Count)].Attributes["href"].Value;
Console.WriteLine(newArticle);
links = (await GetLinksAsync(newArticle)).ToList();
}
}
采集整个网站
首先要了解几个概念:
浅网 surface web: 是互联网上搜索引擎可以直接抓取到的那部分网络.
与浅网对立的就是深网 deep web: 互联网中90%都是深网.
暗网Darknet / dark web / dark internet: 它完全是另外一种怪兽. 它们也建立在已有的网络基础上, 但是使用Tor客户端, 带有运行在HTTP之上的新协议, 提供了一个信息交换的安全隧道. 这类网也可以采集, 但是超出了本书的范围.....
深网相对暗网还是比较容易采集的.
采集整个网站的两个好处:
- 生成网站地图
- 收集数据
由于网站的规模和深度, 所以采集到的超链接很多可能是重复的, 这时我们就需要链接去重, 可以使用Set类型的集合:
private static readonly HashSet<string> LinkSet = new HashSet<string>();
private static readonly HttpClient HttpClient = new HttpClient();
private static readonly HtmlParser Parser = new HtmlParser(); public static async Task GetUniqueLinksAsync(string uri = "")
{
var htmlSource = await HttpClient.GetStringAsync($"http://en.wikipedia.org{uri}");
var document = await Parser.ParseAsync(htmlSource); var links = document.QuerySelectorAll("a")
.Where(x => x.HasAttribute("href") && Regex.Match(x.Attributes["href"].Value, @"^(/wiki/)").Success); foreach (var link in links)
{
if (!LinkSet.Contains(link.Attributes["href"].Value))
{
var newPage = link.Attributes["href"].Value;
Console.WriteLine(newPage);
LinkSet.Add(newPage);
await GetUniqueLinksAsync(newPage);
}
}
}
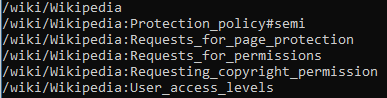
(递归调用的深度需要注意一下, 不然有时候能崩溃).
收集整个网站数据
这个例子相对网站, 包括收集相关文字和异常处理等:
private static readonly HashSet<string> LinkSet = new HashSet<string>();
private static readonly HttpClient HttpClient = new HttpClient();
private static readonly HtmlParser Parser = new HtmlParser(); public static async Task GetLinksWithInfoAsync(string uri = "")
{
var htmlSource = await HttpClient.GetStringAsync($"http://en.wikipedia.org{uri}");
var document = await Parser.ParseAsync(htmlSource); try
{
var title = document.QuerySelector("h1").TextContent;
Console.ForegroundColor = ConsoleColor.Green;
Console.WriteLine(title); var contentElement = document.QuerySelector("#mw-content-text").QuerySelectorAll("p").FirstOrDefault();
if (contentElement != null)
{
Console.WriteLine(contentElement.TextContent);
} var alink = document.QuerySelector("#ca-edit").QuerySelectorAll("span a").SingleOrDefault(x => x.HasAttribute("href"))?.Attributes["href"].Value;
Console.WriteLine(alink);
}
catch (NullReferenceException)
{
Console.ForegroundColor = ConsoleColor.Red;
Console.WriteLine("Cannot find the tag!");
} var links = document.QuerySelectorAll("a")
.Where(x => x.HasAttribute("href") && Regex.Match(x.Attributes["href"].Value, @"^(/wiki/)").Success).ToList();
foreach (var link in links)
{
if (!LinkSet.Contains(link.Attributes["href"].Value))
{
var newPage = link.Attributes["href"].Value;
Console.WriteLine(newPage);
LinkSet.Add(newPage);
await GetLinksWithInfoAsync(newPage);
}
}
}
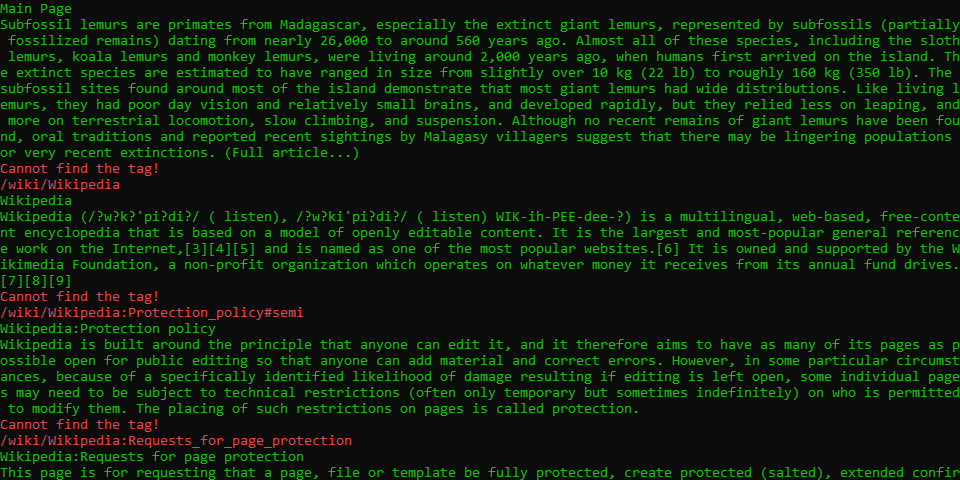
不知前方水深的例子
第一个例子, 寻找随机外链:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Net.Http;
using System.Text.RegularExpressions;
using System.Threading.Tasks;
using AngleSharp.Parser.Html; namespace WebScrapingWithDotNetCore.Chapter03
{
public class CrawlingAcrossInternet
{
private static readonly Random Random = new Random();
private static readonly HttpClient HttpClient = new HttpClient();
private static readonly HashSet<string> InternalLinks = new HashSet<string>();
private static readonly HashSet<string> ExternalLinks = new HashSet<string>();
private static readonly HtmlParser Parser = new HtmlParser(); public static async Task FollowExternalOnlyAsync(string startingSite)
{
var externalLink = await GetRandomExternalLinkAsync(startingSite);
if (externalLink != null)
{
Console.WriteLine($"External Links is: {externalLink}");
await FollowExternalOnlyAsync(externalLink);
}
else
{
Console.WriteLine("Random External link is null, Crawling terminated.");
}
} private static async Task<string> GetRandomExternalLinkAsync(string startingPage)
{
try
{
var htmlSource = await HttpClient.GetStringAsync(startingPage);
var externalLinks = (await GetExternalLinksAsync(htmlSource, SplitAddress(startingPage)[])).ToList();
if (externalLinks.Any())
{
return externalLinks[Random.Next(, externalLinks.Count)];
} var internalLinks = (await GetInternalLinksAsync(htmlSource, startingPage)).ToList();
if (internalLinks.Any())
{
return await GetRandomExternalLinkAsync(internalLinks[Random.Next(, internalLinks.Count)]);
} return null;
}
catch (HttpRequestException e)
{
Console.WriteLine($"Error requesting: {e.Message}");
return null;
}
} private static string[] SplitAddress(string address)
{
var addressParts = address.Replace("http://", "").Replace("https://", "").Split("/");
return addressParts;
} private static async Task<IEnumerable<string>> GetInternalLinksAsync(string htmlSource, string includeUrl)
{
var document = await Parser.ParseAsync(htmlSource);
var links = document.QuerySelectorAll("a")
.Where(x => x.HasAttribute("href") && Regex.Match(x.Attributes["href"].Value, $@"^(/|.*{includeUrl})").Success)
.Select(x => x.Attributes["href"].Value);
foreach (var link in links)
{
if (!string.IsNullOrEmpty(link) && !InternalLinks.Contains(link))
{
InternalLinks.Add(link);
}
}
return InternalLinks;
} private static async Task<IEnumerable<string>> GetExternalLinksAsync(string htmlSource, string excludeUrl)
{
var document = await Parser.ParseAsync(htmlSource); var links = document.QuerySelectorAll("a")
.Where(x => x.HasAttribute("href") && Regex.Match(x.Attributes["href"].Value, $@"^(http|www)((?!{excludeUrl}).)*$").Success)
.Select(x => x.Attributes["href"].Value);
foreach (var link in links)
{
if (!string.IsNullOrEmpty(link) && !ExternalLinks.Contains(link))
{
ExternalLinks.Add(link);
}
}
return ExternalLinks;
} private static readonly HashSet<string> AllExternalLinks = new HashSet<string>();
private static readonly HashSet<string> AllInternalLinks = new HashSet<string>(); public static async Task GetAllExternalLinksAsync(string siteUrl)
{
try
{
var htmlSource = await HttpClient.GetStringAsync(siteUrl);
var internalLinks = await GetInternalLinksAsync(htmlSource, SplitAddress(siteUrl)[]);
var externalLinks = await GetExternalLinksAsync(htmlSource, SplitAddress(siteUrl)[]);
foreach (var link in externalLinks)
{
if (!AllExternalLinks.Contains(link))
{
AllExternalLinks.Add(link);
Console.WriteLine(link);
}
} foreach (var link in internalLinks)
{
if (!AllInternalLinks.Contains(link))
{
Console.WriteLine($"The link is: {link}");
AllInternalLinks.Add(link);
await GetAllExternalLinksAsync(link);
}
}
}
catch (HttpRequestException e)
{
Console.WriteLine(e);
Console.WriteLine($"Request error: {e.Message}");
}
}
}
}
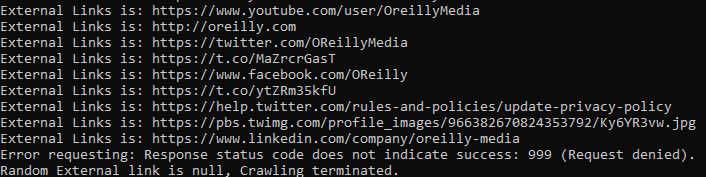
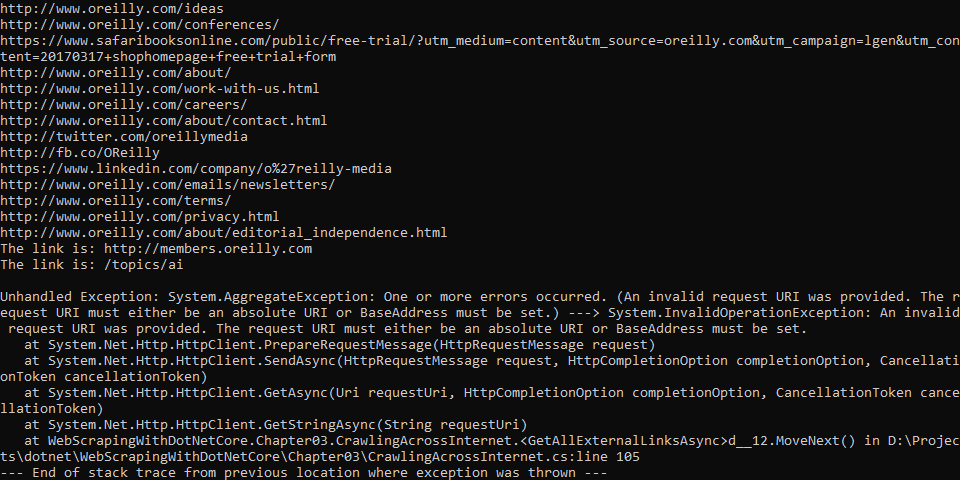
程序有Bug, 您可以给解决下......
第一部分先到这....主要用的是AngleSharp. AngleSharp不止这些功能, 很强大的, 具体请看文档.
由于该书下一部分使用的是Python的Scrapy, 所以下篇文章我也许应该使用DotNetSpider了, 这是一个国产的库....
项目的代码在: https://github.com/solenovex/Web-Scraping-With-.NET-Core
.NET Core 网络数据采集 -- 使用AngleSharp做html解析的更多相关文章
- AngleSharp 网络数据采集 -- 使用AngleSharp做html解析
AngleSharp AngleSharp is a .NET library that gives you the ability to parse angle bracket bas ...
- net core体系-网络数据采集(AngleSharp)-1初探
有这么一本Python的书: <<Python 网络数据采集>> 我准备用.NET Core及第三方库实现里面所有的例子. 这是第一部分, 主要使用的是AngleSharp: ...
- .NET Core使用AngleSharp网络数据采集
环境: vs2019 .net core 3.1 angleSharp winform 安装:angleSharp 有这么一本Python的书: <<Python 网络数据采集>&g ...
- 笔记之Python网络数据采集
笔记之Python网络数据采集 非原创即采集 一念清净, 烈焰成池, 一念觉醒, 方登彼岸 网络数据采集, 无非就是写一个自动化程序向网络服务器请求数据, 再对数据进行解析, 提取需要的信息 通常, ...
- 游戏引擎网络开发者的64做与不做(二A):协议与API
[编者按]在这个系列之前的文章"游戏引擎网络开发者的64做与不做(一):客户端方面"中,Sergey介绍了游戏引擎添加网络支持时在客户端方面的注意点.本文,Sergey则将结合实战 ...
- Python网络数据采集PDF
Python网络数据采集(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/16c4GjoAL_uKzdGPjG47S4Q 提取码:febb 复制这段内容后打开百度网盘手 ...
- python 网络数据采集1
python3 网络数据采集1 第一部分: 一.可靠的网络连接: 使用库: python标准库: urllib python第三方库:BeautifulSoup 安装:pip3 install be ...
- (数据科学学习手札47)基于Python的网络数据采集实战(2)
一.简介 马上大四了,最近在暑期实习,在数据挖掘的主业之外,也帮助同事做了很多网络数据采集的内容,接下来的数篇文章就将一一罗列出来,来续写几个月前开的这个网络数据采集实战的坑. 二.马蜂窝评论数据采集 ...
- (数据科学学习手札33)基于Python的网络数据采集实战(1)
一.简介 前面两篇文章我们围绕利用Python进行网络数据采集铺垫了很多内容,但光说不练是不行的,于是乎,本篇就将基于笔者最近的一项数据需求进行一次网络数据采集的实战: 二.网易财经股票数据爬虫实战 ...
随机推荐
- 将Tomcat添加进服务启动
tomcat有解压版和安装版2种版本,安装版已经做好了将tomcat添加进服务的操作,而解压版需要我们自己来实现,应用场景主要是在服务器端需要在服务器启动时就启动tomcat. 1.首先需要配置好jd ...
- 1.2WEB API 跨域
详细请参考http://www.cnblogs.com/landeanfen/p/5177176.html 在项目上面使用Nuget安装 microsoft.aspnet.webapi.cors 在w ...
- Collection集合框架详解
[Java的集合框架] 接口: collection map list set 实现类: ArryList HashSet HashMap LinkList LinkHash ...
- Linux OpenGL 实践篇-6 光照
经典光照模型 经典光照模型通过单独计算光源成分得到综合光照效果,然后添加到物体表面特定点,这些成分包括:环境光.漫反射光.镜面光. 环境光:是指不是来特定方向的光,在经典光照模型中基本是个常量. 漫反 ...
- 常见web安全隐患及解决方案
Abstract 有关于WEB服务以及web应用的一些安全隐患总结资料. 1. 常见web安全隐患 1.1. 完全信赖用户提交内容 开发人员决不能相信一个来自外部的数据.不管它来自用户提交 ...
- PHPCMS v9.5.8-设计缺陷可重置前台任意用户密码
验证.参考漏洞:http://wooyun.jozxing.cc/static/bugs/wooyun-2015-0152291.html 漏洞出现在/phpcms/modules/member/in ...
- [SDOI 2011]染色
Description 题库链接 给定一棵有 \(n\) 个节点的无根树和 \(m\) 个操作,操作有 \(2\) 类: 将节点 \(a\) 到节点 \(b\) 路径上所有点都染成颜色 \(c\) : ...
- [SDOI2014]重建
题目描述 T国有N个城市,用若干双向道路连接.一对城市之间至多存在一条道路. 在一次洪水之后,一些道路受损无法通行.虽然已经有人开始调查道路的损毁情况,但直到现在几乎没有消息传回. 辛运的是,此前T国 ...
- [SDOI2017]新生舞会
Description 学校组织了一次新生舞会,Cathy作为经验丰富的老学姐,负责为同学们安排舞伴.有n个男生和n个女生参加舞会 买一个男生和一个女生一起跳舞,互为舞伴.Cathy收集了这些同学之间 ...
- [JSOI2008]最大数
题目描述 现在请求你维护一个数列,要求提供以下两种操作: 1. 查询操作. 语法:Q L 功能:查询当前数列中末尾L个数中的最大的数,并输出这个数的值. 限制:L不超过当前数列的长度. 2. 插入操作 ...