python替换残缺的多域名图片网址
在获取网站真是图片的时候,经常遇到图片链接残缺问题。
例如下图所示的情况:
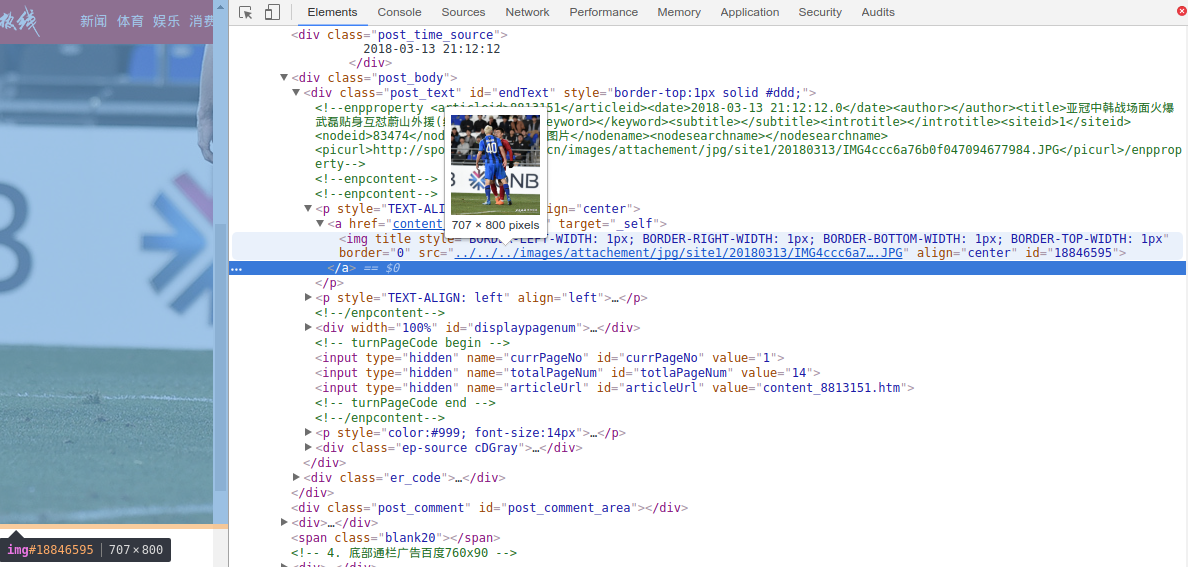
img标签中的图片链接是残缺的,如果这个网站域名又是多种情况的话,比如
http://sports.online.sh.cn/content/2018-03/13/content_8813151.htm
http://sports.online.sh.cn/images/attachement/jpg/site1/20180313/IMG4ccc6a76b0f047094677984.JPG
http://shenhua.online.sh.cn/content/2018-03/13/content_8813187.htm
http://shenhua.online.sh.cn/images/attachement/jpg/site1/20180313/IMGd43d7e5f35354709509383.JPG
这两条新闻是同一个网站的,但是不同的新闻页面,图片的链接又是残缺的,如何获取真正的图片链接呢?
首先,我们需要判断当前页的域名。将鼠标移至图片残缺url上面就会看到完整的url链接。一般残缺图片链接的缺失部分,正是网址栏中的域名部分。
之后,我们就可以在代码中进行判断,如:
def parse_item(self, response, spider):
self.item = self.load_item(response)
if 'sports' in response.url:
self.item['content'] = self.item['content'].replace('../../../images', 'http://sports.online.sh.cn/images')
elif 'shenhua' in response.url:
self.item['content'] = self.item['content'].replace('../../../images', 'http://shenhua.online.sh.cn/images')
yield self.item
~上面使用成员操作符 in来查找相应的域名,是较为实用简单的判断方法,相同的做用判断还可以用以下几种方法来实现:
~使用string模块的index()/rindex()方法
index()/rindex()方法跟find()/rfind()方法一样,只不过找不到子字符串的时候会报一个ValueError异常。
import string
def find_string(s,t):
try:
string.index(s,t)
return True
except(ValueError):
return False
s='nihao,shijie'
t='nihao'
result = find_string(s,t)
print result #True~使用字符串对象的find()/rfind()、index()/rindex()和count()方法
>>> s='nihao,shijie'
>>> t='nihao'
>>> result = s.find(t)>=0
>>> print result
True
>>> result=s.count(t)>0
>>> print result
True
>>> result=s.index(t)>=0
>>> print result
Truepython替换残缺的多域名图片网址的更多相关文章
- python爬取某个网页的图片-如百度贴吧
python爬取某个网页的图片-如百度贴吧 作者:vpoet mail:vpoet_sir@163.com 注:随意copy,不用告诉我 #coding:utf-8 import urllib imp ...
- 测试开发Python培训:实现屌丝的图片收藏愿望(小插曲)
测试开发Python培训:实现屌丝的图片收藏愿望(小插曲) 男学员在学习python的自动化过程中对于爬虫很感兴趣,有些学员就想能收藏一些图片,供自己欣赏.作为讲师只能是满足愿望,帮助大家实现对美的追 ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- 正则表达式,匹配非本站图片网址去掉img标签内容实例
正则表达式,匹配非本站图片网址去掉img标签内容实例 在线正则表达式测试http://tool.oschina.net/regex/# 测试内容: <div><p>eee< ...
- 移动Web—CSS为Retina屏幕替换更高质量的图片
来源:互联网 作者:佚名 时间:12-24 10:37:45 [大 中 小] 点评:Retian似乎是屏幕显示的一种趋势,这也是Web设计师面对的一个新挑战;移动应用程序的设计师们已经学会了如何为Re ...
- 如何获取域名(网址)对应的IP地址
域名(Domain Name),是由一串用点分隔的名字组成的Internet上某一台计算机或计算机组的名称,用于在数据传输时标识计算机的电子方位.通俗点讲,域名就是我们平时进行网络浏览时所用到的网址( ...
- arp协议分析&python编程实现arp欺骗抓图片
arp协议分析&python编程实现arp欺骗抓图片 序 学校tcp/ip协议分析课程老师布置的任务,要求分析一种网络协议并且研究安全问题并编程实现,于是我选择了研究arp协议,并且利用pyt ...
- 替换res\drawable中的图片
现象 在android开发中,经常会需要替换res\drawable中的图片,打开res\layout下的文件预览布局页面发现图片已经被替换,但在模拟器或者真实机器上运行时发现该图片并没有被替换,还是 ...
- python 替换指定目录下,所有文本字符串
网页保存后,会把js文件起名为.下载,html里面的引用也会有,很不美观,解决方案:用python替换字符串 import os import re """将当前目录下所 ...
随机推荐
- 事件驱动的Java框架
事件驱动的三个要素: 事件源:能够接收外部事件的源体. 侦听器:能够接收事件源通知的对象. 事件处理程序:用于处理事件的对象.
- River Hopscotch POJ - 3258
Every year the cows hold an event featuring a peculiar version of hopscotch that involves carefully ...
- PortableApps使用入门
PortableApps使用入门 Software 介绍 添加软件 绿软下载站推荐 介绍 官网:http://portableapps.com/ PortableApps作为一款卓越的绿软管理软件,它 ...
- ASP.NET CSS 小结
1.ASP.NET 引用CSS 1.Site.master里面设置webopt <webopt:bundlereferencerunat="server"path=" ...
- 分类导航菜单的制作(附源码)--HTML
不多说,直接贴代码哈!有疑问,可追加评论哈! demo.html: <!DOCTYPE html><html> <head> <title>分类导航菜单 ...
- PyTorch官方中文文档:torch.optim
torch.optim torch.optim是一个实现了各种优化算法的库.大部分常用的方法得到支持,并且接口具备足够的通用性,使得未来能够集成更加复杂的方法. 如何使用optimizer 为了使用t ...
- 关于margin-top的一些特别问题
当给子元素添加了margin-top的数值,浏览器解析的时候默认添加到父元素上解决的方法: 1 给父元素添加一个上边框border-top. 2 或者给子元素加个浮动. 3 给父元素添加overfl ...
- (右偏树)Bzoj2333: [SCOI2011]棘手的操作
题面 戳我 Sol 右偏树滑稽+并查集 再在全局开一个可删除的堆(priority_queue) 注意细节 # include <bits/stdc++.h> # define RG re ...
- 百度定位一直出现4.9E -324的问题解决方法
问题:华为mate10一直在申请百度定位的时候出现此问题并且定位权限和定位服务都打开的情况也是返回这个参数 明显没有定位成功,其他手机暂时没有出现(只要打开定位权限就会立即定位成功) 解决:在定位之前 ...
- 关系型数据库工作原理-查询优化器之索引(翻译自Coding-Geek文章)
本文翻译自Coding-Geek文章:< How does a relational database work>.原文链接:http://coding-geek.com/how-data ...