machine learning 之 Anomaly detection
自Andrew Ng的machine learning课程。
目录:
- Problem Motivation
- Gaussian Distribution
- Algorithm
- Developing and Evaluating an Anomaly Detection System
- Anomaly Detection vs. Supervised Learning
- Choosing What Features to Use
- Multivariate Gaussian Distribution
- Anomaly Detection using the Multivariate Gaussian Distribution
1、Problem Motivation
如同以往的学习问题,我们给定数据集$x^{(1)}, x^{(2)},...,x^{(m)}$
给定一个新的实例,$x_{test}$,我们想知道这个新的实例是否是异常点(abnormal / anomalous)
如下例中,给定飞机发动机的一些特征数据集,如$x_1:heat \ generated, x_2:vibration \ intensity$等,给定一个数据集中未出现过的新的实例$x_{test}$,那么这个新的实例是否是异常点(真实情况中不可能出现具有这样子特征的飞机发动机就称其为异常点);
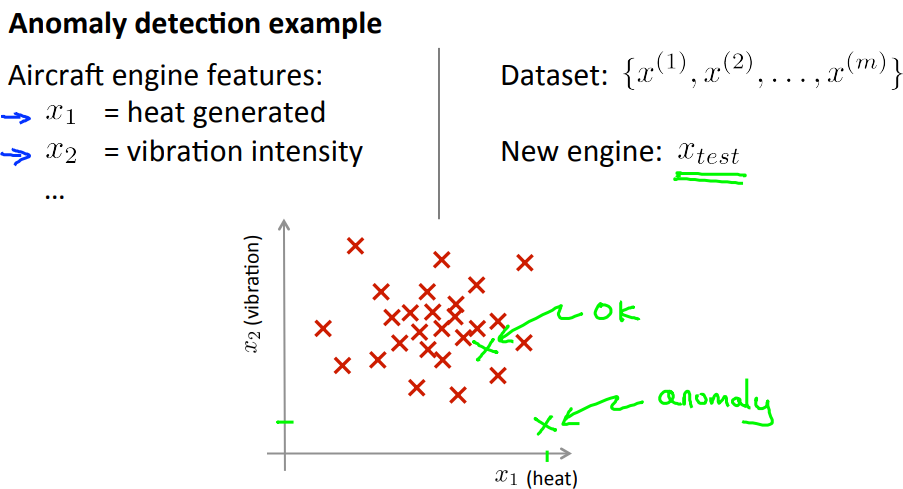
如图中,属于一堆红叉叉中间的绿叉叉就是正常的(ok)飞机发动机,而距离较远的绿叉叉则是异常的(anomaly)飞机发动机。
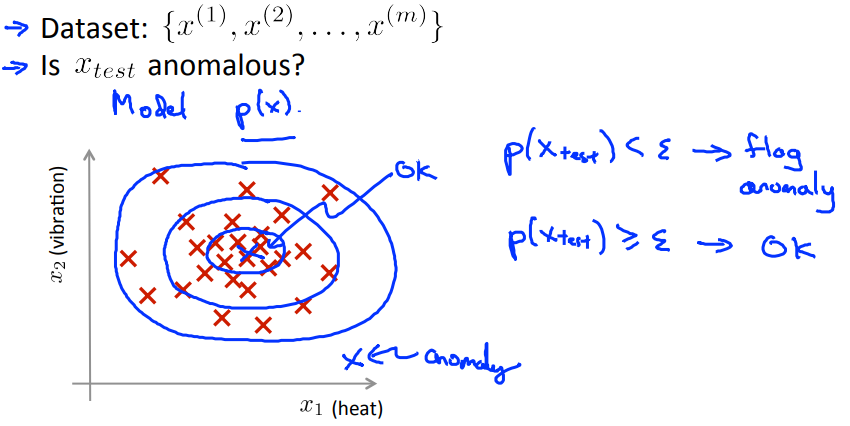
为了监测异常点,我们可以定义一个模型“p(x)”,这个模型用来计算实例不是异常点的概率,然后,我们选择一个阈值$\varepsilon$作为是否为异常点的分割线,当概率小于这个值,那么就认为这个实例是异常点,否则非异常点。
如下图所示,蓝色圈圈以外的就是异常点,选择不同的$\varepsilon$圈子的大小会不一样:
举一些anomaly detection的实例:
- fraud detection(诈骗监测)
- 让$x^{(i)}$作为用户活动的特征(the features of user's activities)
- 从数据中构建模型p(x)
- 通过确定$p(x)<\varepsilon$,来找到异常用户
- manufacturing(制造业,如飞机发动机)
- 在数据中心监测电脑
- $x^{(i)}为电脑的特征,如x^{(1)}:内存使用,x^{(2)}:可获取的磁盘数目,x^{(3)}:CPU \ load......$
注:若异常监测器标记了太多的异常点,那么可以适当的将$\varepsilon$减小。
2、Gaussian Distribution
又称为Normal distribution,如图,若数据的分布满足以下的图像,则说x是满足均值为$\mu$,方差为$\sigma^2$的高斯分布,完整的函数是$p(x;\mu,\sigma^2)=\frac{1}{\sigma \sqrt{(2\pi)}}e^{-\frac{1}{2} {(\frac{x-\mu}{\sigma})}^2}$

以下是高斯分布的几张示例图:
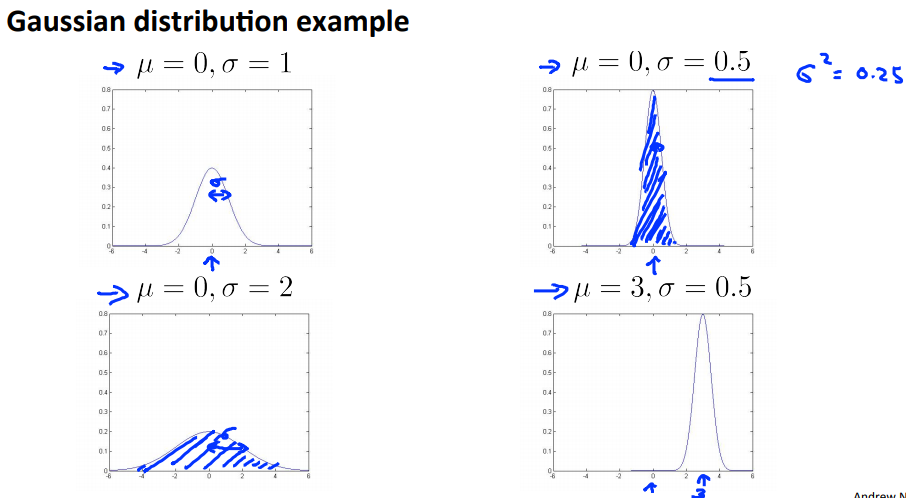
从以上解释和图例中我们可以知道决定高斯分布的参数是均值和方差:
- 均值决定高斯分布中曲线的中心位置
- 方差决定高斯分布中曲线的形状和宽度
那么给定一个数据集,我们如何得到这两个参数呢?
- $\mu = \frac{1}{m} \sum_{i=1}^{m}{x^{(i)}}$
- $\sigma^2=\frac{1}{m} \sum_{i=1}^{m}{(x_{(i)}-\mu)}^2$
3、Algorithm
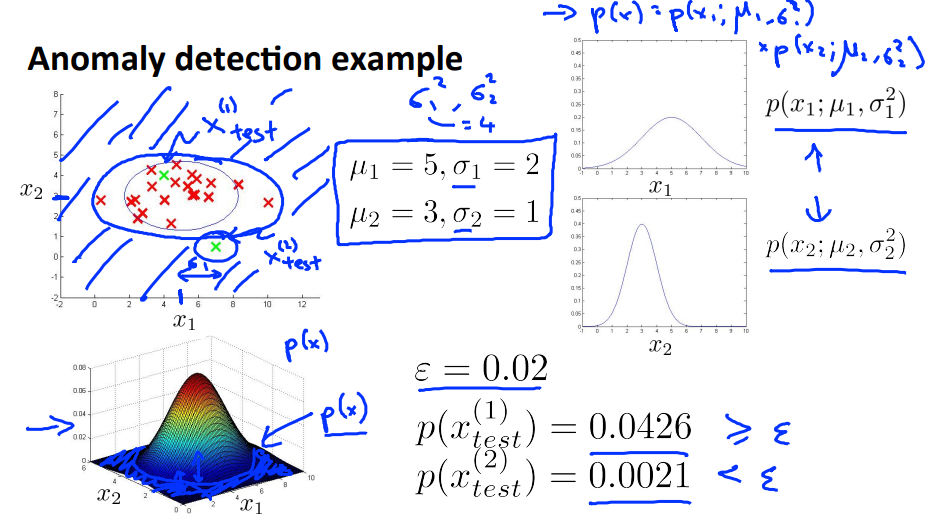
给定训练集${x^{(1)},x^{(2)},...,x^{(m)}}$,这其中的每个实例都是一个向量,$x \in R^n$。(m代表训练集的实例的数目,n代表特征的数目)
$p(x)=p(x_1;\mu_1,\sigma_1^2)p(x_2;\mu_2,\sigma_2^2)...p(x_n;\mu_n,\sigma_n^2)=\prod_{j=1}^{n}p(x_j;\mu_j,\sigma_j^2)$
以上函数公式基于一个独立性假设,有兴趣的可以自己去查一查。
异常值监测算法:
- 选择可以捕捉异常值的特征$x_{(i)}$
- 拟合参数$\mu_1,\mu_2,...,\mu_n,\sigma_1^2,\sigma_2^2,...,\sigma_n^2$
- $\mu_j=\frac{1}{m}\sum_{i=1}^{m}{x_{j}^{(i)}}$
- $\sigma_j^2=\frac{1}{m}\sum_{i=1}^{m}{(x_{j}^{(i)}-\mu_j)}^2$
3. 给定新实例x,计算p(x):
$p(x)=\prod_{j=1}^{n}{p(x_j;\mu_j,\sigma_j^2)}$,若$p(x)<\varepsilon$则新实例为异常点
以下是一个示例,示例中给出了$p(x_1)和p(x_2)$,蓝色圈圈外面的都被定义为异常点;
4、Developing and Evaluating an Anomaly Detection System
当要调试算法时(选择特征),如果此时有一个评价算法的方式,那我们对如何改进算法会有一个方向。(比如加入某个特征之后,算法变得更好了,那么怎样才叫算法变得更好了呢?)
类似与监督分类,我们把数据分为训练集、验证集和测试集,但是注意异常检测算法作用的数据集中通常只有少量的异常数据,大部分的数据都是正常的数据,因此我们的数据集划分和监督分类是有些不同,例如对于一个只包含0.2%的异常数据的数据集,我们可以用以下方式划分数据集:
- 选择大部分的数据作为训练数据集,其中只有非异常数据,不含异常数据(如60%的数据,全部为非异常数据);
- 选择20%的数据作为验证数据集,其中包含0.1%的异常数据;
- 选择剩余的20%作为测试数据集,其中包含总数据集中0.1%的异常数据;
也就是60/20/20的比例划分总数据集为训练、验证和测试数据集,而异常数据又以50/50分配到了验证和测试数据集中。
也有人将验证数据集和测试数据集作为同一个数据集,这样的做法不推荐。
以上只是解决了用哪一部分的数据进行评价,但是如何评价呢?
显然,这属于之前说过的skewed class,也就是说异常数据占据的比例极小,比如只有0.2%,如果简单的是用分类精度这样的指标,那么只要把所有的数据都认为是非异常,就可以得到98%的精度,这样做当然不对。
同前面说过的,我们可以使用以下指标作为评价指标:
- true positive, false positive, true negative, false negative
- Precision / Recall
- F1 score
注意到可以用验证集选择适当的$\varepsilon$。
5、Anomaly Detection vs. Supervised Learning
考虑一个问题,根据以上的解说,其实异常监测算法的做法和监督分类的做法十分的相似,那么为什么不直接用监督分类呢,比如logistic regression?
这两个算法的不同在于,异常监测是针对非异常数据的建模,模型建立时不考虑异常数据,而监督分类是对正例和负例分别建模,同时考虑了两个类别。
这里列出了两者的不同:
| Anomaly Detection | Supervised Learning |
| 异常数据非常少(常见数目为0-20),具有大量的非异常数据 | 正例和负例数据都很多 |
| 异常的种类是非常多的,各种各样形式的异常,但是我们的异常数据非常少,所以没办法捕捉所有的异常情况,经常可能出现的情况是,出现了训练集中没有出现过的新的异常类别,那么如果想通过对异常数据建模,则可能会漏掉对很多异常数据的识别。 | 有大量的正例数据,可以捕捉不同形式的正例,所以可以直接对正例或者负例进行建模,都可以得到比较好出结果。未来可能出现的正例或者负例的形式基本上应该都在训练集中出现过。 |
| 诈骗监测,手工业,检测电脑状况 | 垃圾邮件分类,天气预报,癌症分类 |
6、Choosing What Features to Use
特征的选择会非常大的程度上影响异常监测器的性能。
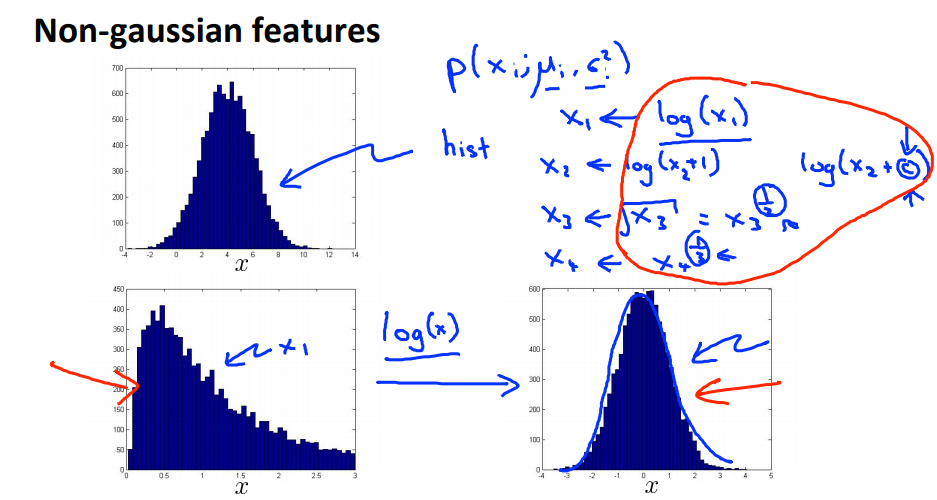
通过画出数据的直方图可以监测数据是否是符合高斯分布的,对于不符合高斯分布的数据,可以通过进行一些转换使数据更加接近高斯分布,如$log(x), log(x+c), x^{\frac12}, x^{\frac13}$等。
异常监测的误差分析:
我们希望模型可以使得异常值的p(x)非常的小,而非异常值的p(x)较大,但是发生的情况往往如下左图所示,异常值(蓝色叉叉)和非异常值(红色叉叉)计算出来的p(x)差不多大,这样就没有办法找出异常值了
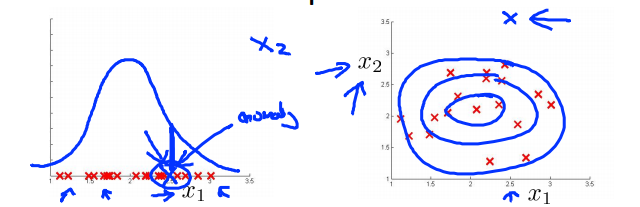
而当我们增加一个特征$x_2$时,见上右图,异常值(蓝色叉叉)就被明显的分离出来了,因此找到可以显著区分异常点和非异常点的特征是很重要的。
7、Multivariate Gaussian Distribution
多元高斯分布是异常监测的延伸情况,可能会(也可能不会)捕捉到更多的异常。
之前的模型是对每一个特征都构建一个模型$p(x_1),p(x_2),....,p(x_n)$,利用多元高斯分布可以对所有的特征构建一个模型$p(x_1,x_2,...,x_n)$,模型的参数$\mu \in R^{n}, \Sigma \in R^{n*n}$
$p(x;\mu, \Sigma)=\frac{1}{(2\pi)^{n/2}\,|\Sigma|^{1/2}}\,exp{(-1/2(x-\mu)\Sigma^{-1}(x-\mu))}$
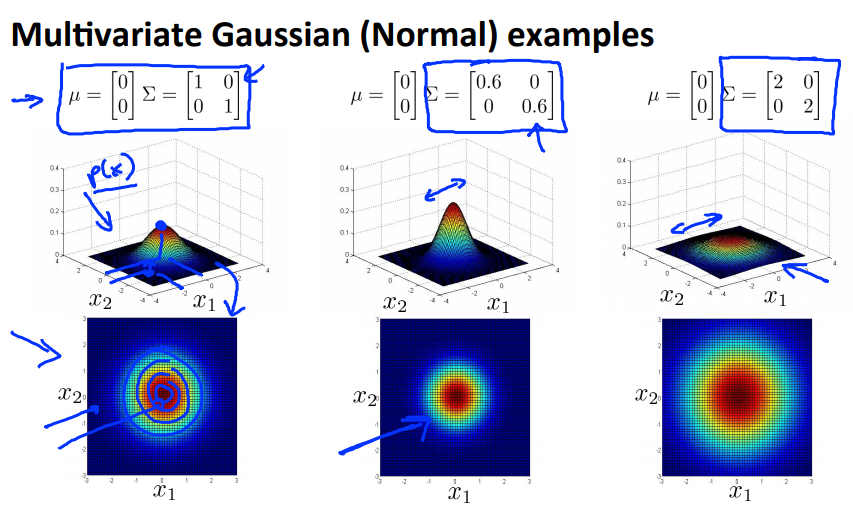
这个模型的好处是它可以拟合椭圆高斯轮廓,不仅仅限于正圆
- $\Sigma$:可以控制椭圆的形状、宽度和角度
- $\mu$:可以控制椭圆的中心位置
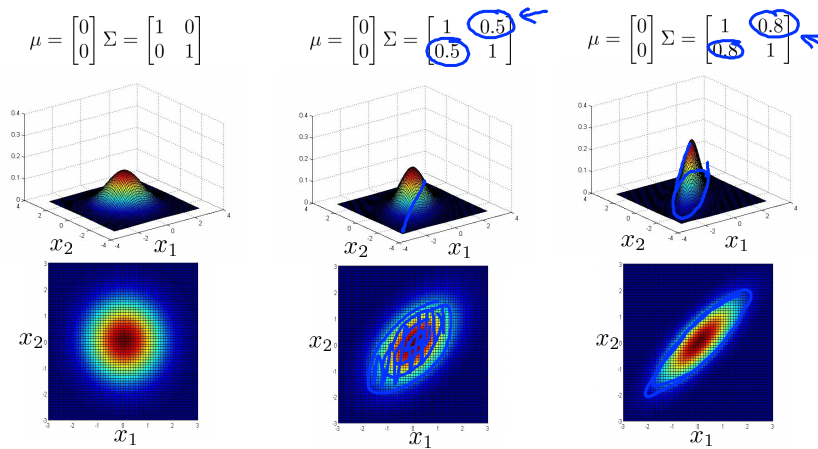
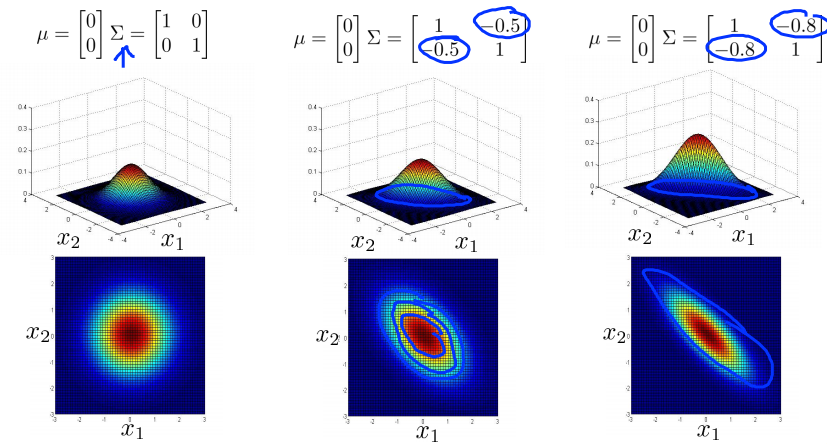
如下面一系列图所示:
- 当$\Sigma$是对角矩阵(除对角线上元素全部为0),且对角线上的元素是一样的大小时,图像是正圆,对角线上的元素的大小控制了圆的半径的大小,对角线上的元素越大,圆的半径越大;
- 当$\Sigma$是对角矩阵(除对角线上元素全部为0),但对角线上的元素大小不一样时,图像是沿着轴线方向的椭圆,轴线上的元素的大小决定了轴线上的直径的长度;
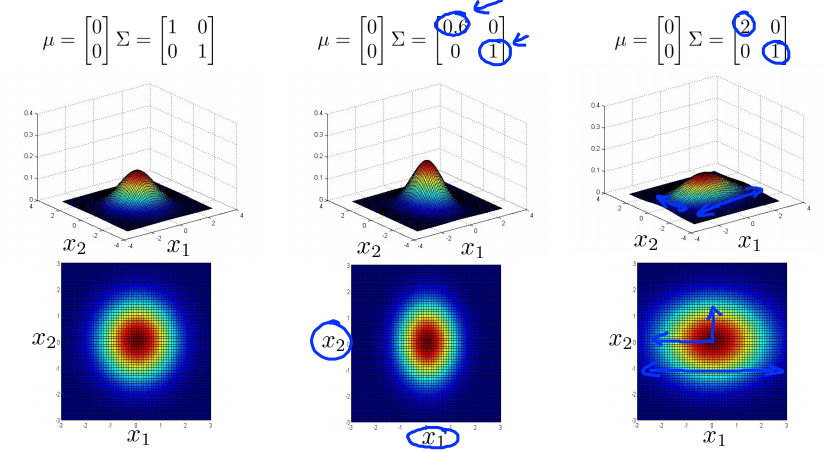
- 当$\Sigma$不是对角矩阵时,斜对角(东北-西南向)的数代表圆旋转的角度,整数代表顺时针旋转,负数代表逆时针旋转;
8、Anomaly Detection using the Multivariate Gaussian Distribution
对于多元正态分布,当参数确定时,模型如下:
$p(x;\mu, \Sigma)=\frac{1}{(2\pi)^{n/2}\, |\Sigma|^{1/2}}\,exp{(-1/2(x-\mu)\Sigma^{-1}(x-\mu))}$
参数拟合:给定数据集${x^(1),...,x^(n)}$
- $\mu=\frac{1}{m}\sum_{i=1}^{m}{x^{(i)}}$
- $\Sigma=\frac{1}{m}\sum_{i=1}^{m}{(x^{(i)}-\mu)}{(x^{(i)}-\mu)}^T$
用多元正态分布做异常监测的算法:
- 根据给定的数据拟合模型p(x),主要是利用上式确定$\mu$和$\Sigma$;
- 给定一个新的实例,计算p(x),若$p(x)<\varepsilon$,则认为是异常值;
那么使用多元正态分布的异常检测算法和传统的异常监测算法有什么区别呢?
| original model | multivariate gaussian |
|
$p(x_1)$*p(x_2)*...*p(x_n) 相当于在多元高斯模型中$\Sigma$是一个对角矩阵,图像是沿着轴线方向的圆 |
$p(x;\mu, \Sigma)=\frac{1}{(2\pi)^{n/2}\, |\Sigma|^{1/2}}\,exp{(-1/2(x-\mu)\Sigma^{-1}(x-\mu))}$ |
|
需要手动的捕捉那些能使得异常值的概率显著不同的特征之间的组合, 如$x_3=\frac{x_1}{x_2}$ |
可以自动捕捉不同的特征之间的联系 |
| 计算的耗费更低,更适用于大型的数据,比如n=100,000 |
计算的耗费相对更大,因为这里有个$\Sigma$需要求逆,且只有当m>n时$\Sigma$才可以求逆 经验性的会在m>10n时才用这个方法 |
machine learning 之 Anomaly detection的更多相关文章
- Machine Learning - XV. Anomaly Detection异常检測 (Week 9)
http://blog.csdn.net/pipisorry/article/details/44783647 机器学习Machine Learning - Andrew NG courses学习笔记 ...
- Machine Learning and Data Mining(机器学习与数据挖掘)
Problems[show] Classification Clustering Regression Anomaly detection Association rules Reinforcemen ...
- 100 Most Popular Machine Learning Video Talks
100 Most Popular Machine Learning Video Talks 26971 views, 1:00:45, Gaussian Process Basics, David ...
- Time Series Anomaly Detection
这里有个2015年的综述文章,概括的比较好,各种技术的适用场景. https://iwringer.wordpress.com/2015/11/17/anomaly-detection-concep ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 9) Anomaly Detection&Recommender Systems
这部分内容来源于Andrew NG老师讲解的 machine learning课程,包括异常检测算法以及推荐系统设计.异常检测是一个非监督学习算法,用于发现系统中的异常数据.推荐系统在生活中也是随处可 ...
- Machine Learning No.10: Anomaly detection
1. Algorithm 2. evaluating an anomaly detection system 3. anomaly detection vs supervised learning 4 ...
- Anomaly Detection for Time Series Data with Deep Learning——本质分类正常和异常的行为,对于检测异常行为,采用预测正常行为方式来做
A sample network anomaly detection project Suppose we wanted to detect network anomalies with the un ...
- 【机器学习Machine Learning】资料大全
昨天总结了深度学习的资料,今天把机器学习的资料也总结一下(友情提示:有些网站需要"科学上网"^_^) 推荐几本好书: 1.Pattern Recognition and Machi ...
- (转)8 Tactics to Combat Imbalanced Classes in Your Machine Learning Dataset
8 Tactics to Combat Imbalanced Classes in Your Machine Learning Dataset by Jason Brownlee on August ...
随机推荐
- android decorView详解
摘要 一.DecorView为整个Window界面的最顶层View. 二.DecorView只有一个子元素为LinearLayout.代表整个Window界面,包含通知栏,标题栏,内容显示栏三块区域. ...
- Docker 基础技术之 Linux cgroups 详解
PS:欢迎大家关注我的公众号:aCloudDeveloper,专注技术分享,努力打造干货分享平台,二维码在文末可以扫,谢谢大家. 推荐大家到公众号阅读,那里阅读体验更好,也沉淀了很多篇干货. 前面两篇 ...
- Android 应用内直接跳转酷市场
不确定酷市场后期是否还会该包名或者路径,目前的7.9 版本测试通过. private void gotoCoolapkMarket() { try { Intent intent = new Inte ...
- log4j日志的配置
在项目开发中,记录错误日志方便调试.便于发现系统运行过程中的错误.便于后期分析, 在java中,记录日志有很多种方式,比如说log4j log4j需要导入的包: commons-loggin.jar ...
- winform 写App.config配置文件——IT轮子系列(八)
前言 在winform项目中,常常需要读app.config文件.如: var version = System.Configuration.ConfigurationManager.AppSetti ...
- SpringMVC:数据绑定入门(二)
1.为了实现所输入的数据格式与所需要的匹配该如何做到?例如:http://localhost:8080/date1.do?date1=2018-01-01,其中输入的date1的数据类型为一个格式为& ...
- 发现DELL笔记本一个很弱智的问题
以前用联想的笔记本,最近联想笔记本坏了,用的是公司的DELL笔记本,发现DELL笔记本一个很弱智的问题. 关于禁用触摸板的问题. 起因: 由于要经常写程序,我配置的有有线鼠标,但是打字时经常碰到触摸板 ...
- C#高级编程笔记之第二章:核心C#
变量的初始化和作用域 C#的预定义数据类型 流控制 枚举 名称空间 预处理命令 C#编程的推荐规则和约定 变量的初始化和作用域 初始化 C#有两个方法可以一确保变量在使用前进行了初始化: 变量是字段, ...
- HTML学习笔记6:列表标签
列表标签 什么是列表标签呢? 以平台区分有什么游戏? 手游 pc游戏 家用机游戏 掌机游戏 以游戏类型区分有什么游戏? RPG ARPG MMORPG ACT FPS 以上两种就是一种列表标签 ...
- What is RandomCharacter.getRandomLowerCaseLetter() ?????
今天在看书顺便打打书上的代码时,看到这么一个方法的调用RandomCharacter.getRandomLowerCaseLetter()! 年轻的我看到这一大串单词时还以为是JDK自带类里面方法Or ...